摘要
我们研究根据室内路线捕获的 360° 图像自动生成导航指令。现有的生成器视觉基础较差,导致它们依赖语言先验并对物体产生幻觉。我们的 MARKY-MT5 系统通过关注视觉地标来解决这个问题;它包括第一级地标检测器和第二级生成器——多模式、多语言、多任务编码器-解码器。为了训练它,我们在 Room-across-Room (RxR) 数据集之上引导接地地标注释。使用文本解析器、RxR 姿势轨迹的弱监督以及在 1.8b 图像上训练的多语言图像文本编码器,我们识别了 971k 英语、印地语和泰卢固语地标描述,并将它们定位到全景图中的特定区域。在 Room-to-Room 中,人类寻路器按照 MARKYMT5 的指令获得了 71% 的成功率 (SR),略低于遵循人类指令的 75% SR,并且远高于其他生成器的 SR。对 RxR 更长、多样化路径的评估在三种语言上获得了 6164% 的 SR。在新环境中生成如此高质量的导航指令是迈向对话式导航工具的一步,并且可以促进指令跟随代理的大规模训练。
介绍
寻路——导航到目的地——是一项日常任务。我们研究自动生成有效引导人们的导航指令。使用基本方向和街道名称的基于模板的语言生成器通常用于户外测绘应用,一些更灵活的生成方法依赖于包含地图、道路和地标信息的数据库[16,50,51]。相比之下,室内寻路指令需要以自我为中心的运动指导和对视觉环境(例如值得注意的物体)的参考。
用于生成室内寻路指令的系统假设可以访问预先存在的平面图和地标数据库[41],但最近的工作试图直接从视觉输入生成新颖的指令[21,38,59]。实现这一目标的进展将使导航辅助工具成为对话式的而不是基于地图的,并且它可以为训练遵循指令的机器人提供几乎无限的高质量合成导航指令。描述导航路径也是人类机器人通信的一项关键能力,让机器人能够回答诸如“你去了哪里?”等问题。或者我应该在哪里见到你?
我们寻求直接从视觉表示和穿越路径的动作生成准确、流畅的多种语言的导航指令。之前的工作假设指令生成器的输入是在路径上每隔一段时间捕获的 360° 全景(以下称为全景)图像序列,通常使用 Matterport3D 环境对来自 Room-to-Room (R2R) [5] 的指令进行训练 [ 9]。事实证明,这些模型的指令作为视觉和语言导航(VLN)代理的附加训练数据很有价值[21]。然而,人们很难跟随它们[66]:在未见过的环境中,Speaker-Follower [21] 的 R2R 人类寻路成功率为 36%,EnvDrop [59] 的成功率为 42%。生成的文本在风格上是正确的,但经常引用不存在的对象并混淆空间术语,例如左和右。
面向视觉的指令生成器面临的挑战是处理不相关的视觉输入。在许多其他图像到文本生成任务(例如图像字幕)中,输入中的许多视觉信息都反映在输出文本中。生成导航指令时情况并非如此。人类注释者查看的环境不到 30% [35],并且指令仅引用了他们查看的对象的一小部分。这使得学习视觉输入和文本输出之间的精确映射变得更加困难。相反,获取更多信息可能会降低性能[14],因为模型很乐意学习虚假相关性,从而在推理过程中引起幻觉。
为了解决这个问题,我们利用 Room-across-Room (RxR) 数据集 [35] 中的时空基础。 RxR 注释器不是编写指令,而是在遍历路径时说话。因此,每条 RxR 指令都带有姿势轨迹,将所说的(以及后来转录的)单词与注释者所看到的内容对齐。我们使用这些姿势轨迹和指令来派生一个新的silver注释数据集,其中包含视觉地标上的边界框及其多语言描述(英语、印地语和泰卢固语)。具体来说,我们使用文本解析器引导地标注释来识别指令中的地标短语。然后,我们使用强大的图像文本共嵌入模型 [31] 结合姿势轨迹的弱监督来将环境中的这些地标接地。
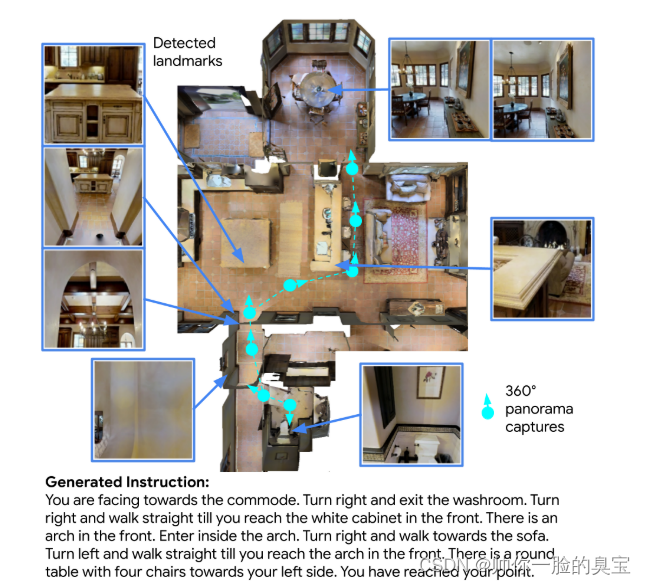
在 R2R 路径上的人类寻路实验中,使用silver地标(来自整个环境的视觉输入的子集)进行训练的 MARKY-MT5 几乎消除了模型生成的指令与人类编写的指令之间的差距 – 实现了 71% 的成功率 (SR)相比之下,人工指令为 75%,之前的模型为 42%,我们在完整 360° 全景上训练的模型为 58%。在为生成器选择视觉输入时,少即是多。在更具挑战性的 RxR 路径上,人类寻路者使用 MARKY-MT5 获得 62% 的 SR,而使用人类指令获得 78%。我们发布了silver地标数据和 MARKY-MT5 生成的超过一百万条导航指令,作为训练 VLN 代理的数据增强。
相关工作
wayfinding with landmarks
我们希望制定人们可以遵循的指示,并受到地标对人类导航重要性的研究的启发 [8,17,20,65]。地标不仅仅是空间特征——它们编码了特征(例如物体)本身、其附近环境和寻路者的视角之间的关系[7]。我们的地标检测器根据 RxR 的人类参考地标引导的数据进行训练。这使得我们的方法能够利用这些具有里程碑意义的特征,而无需明确地对其进行设计(如[18, 26]中所示)。
洪等人。 [28]表明场景、物体和方向线索之间的建模关系对于提高 VLN 寻路性能是有效的。这表明寻路代理和引导代理之间存在潜在的良性循环,或者更好的是,对单个代理的这两种功能使用这种具有里程碑意义的理解。
navigation instruction generation
先前生成合成 VLN 指令的工作采用了SpeakerFollower 框架 [22, 59]:Speaker 模型从 R2R 注释(仅限英文)中学习,以生成以路径全景序列为条件的指令,而 Follower 模型则学习寻路(即构造路径)以人类指令和相同的视觉输入为条件。Speaker的输出可以用作训练Follower的增强数据,并且Speaker用于在推理(实用推理的一种形式)期间对追随者生成的路径进行重新排序。这些模型不加区别地使用整个全景作为视觉上下文,而我们从每个全景中选择关键视觉地标供生成器讨论。我们建立在多任务、多语言 T5 模型架构 [48, 64] 的基础上,这是一个统一的文本到文本框架,可以通过同时混合许多 NLP 任务来实现迁移学习。这还使我们能够探索预训练任务,包括图像字幕等多模式任务,以提高对未见环境的泛化能力。
阿加瓦尔等人[1] 之前提出了一种基于地标的生成器,但依靠 RL 训练而不是silver数据来诱导地标接地。帕舍维奇等人[44] 使用合成指令(如上床拾取手机)作为训练 VLN 代理以达到 ALFRED 基准的额外来源 [55]。这些类似于我们在多模态编码器中使用的简单方向表达式,但它们既用于数据增强又用作额外的解码任务。他们寻求优化 VLN 代理的性能,而我们寻求提供人们可以遵循的指令。
小岛等人[34] 探索 CEREALBAR 游戏中的协作式人类代理指令生成 [58]。他们定义了一个人机循环指令生成框架,其中生成器通过与人交互时收集的信号进行迭代改进。这些说明涵盖了导航和游戏策略。
他们的多模态→文本生成器是一个黑盒,而我们的方法包括基于选定的视觉地标的可解释的中间表示(与正式抽象相比,例如[13])。这项工作补充了我们的工作(仅使用静态人类注释),并提出了未来的交互设置,可以让我们的指令生成器适应人类寻路器。
multimodal generation
我们对地标以及语言和视觉元素之间的细粒度连接的使用与图像字幕有相似之处。特别是,Pont-Tuset 等人[45]表明使用鼠标轨迹的受控图像字幕可以产生更好的图像描述。周等人[68]使用预先训练的文本图像匹配器来学习关键字-bbox对齐,这用于调节其标题生成器(类似于我们的视觉地标的检测和使用)。胡贝尔等人[29]提供了一个两阶段的基于图像的对话模型,该模型从图像中提取情感信息,将情感注入生成的文本中。类似于我们的银地标数据的专业数据集用于训练图像特征提取器,以提高场景理解以及情绪和面部特征的处理。
我们的生成器本身属于不断增长的对多模式输入进行编码并解码为文本的方法集合,包括 VL-T5 [12]、MAnTiS [56] 和 SimVLM [62],通常在多任务设置中。我们的输入有所不同,因为我们对多个相互连接的图像进行编码,这些图像与动作描述交织在一起。我们的模型输出是使用人工评估者针对下游任务性能进行评估的,而不是基于学习到的表示的自动指标和下游任务。




![Sqli-labs靶场第16关详解[Sqli-labs-less-16]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/20749ba7b3164afc86bf6a7f549c095a.png)