Paper Card
论文标题:Video as the New Language for Real-World Decision Making
论文作者:Sherry Yang, Jacob Walker, Jack Parker-Holder, Yilun Du, Jake Bruce, Andre Barreto, Pieter Abbeel, Dale Schuurmans
作者单位:Google DeepMind, UC Berkeley, MIT
论文原文:https://arxiv.org/abs/2402.17139
论文出处:–
论文被引:–(03/03/2024)
项目主页:–
论文代码:–
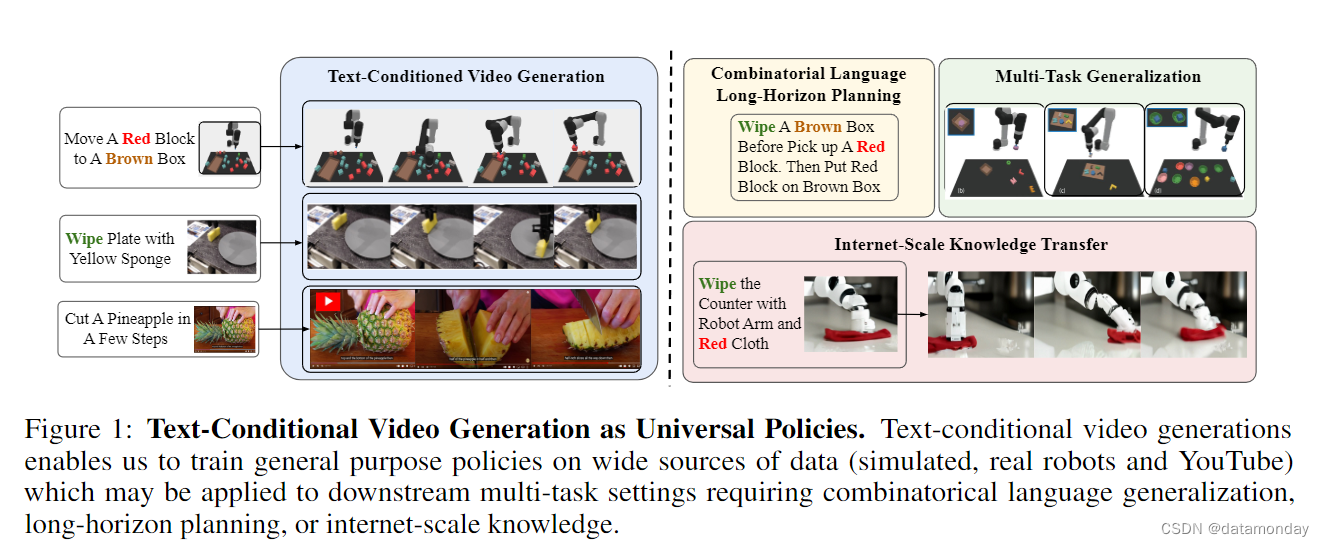
研究问题:扩展视频生成功能以解决现实世界中的任务。能否将视频生成模型提升到与语言模型类似的自主Agent、模拟环境和计算引擎的水平,从而使机器人、自动驾驶和科学等需要视觉模式的应用能够更直接地受益于互联网视觉知识和预训练视频模型。
面临挑战:
- 虽然互联网文本数据通过大型语言模型为数字/知识世界提供了很多价值,但与物理世界的低层次细节(low-level details)相比,文本更适合捕捉高层次的抽象(high-level abstractions)概念。而视频数据包含了许多丰富的文本模态无法获取的信息。
- 具身人工智能面临的挑战之一是数据碎片化(data fragmentation),即一个机器人在执行一组任务时收集的数据集对另一个机器人或另一组任务的学习几乎毫无用处 [39]。跨机器人和跨任务知识共享的主要困难在于,每种类型的机器人和任务都有不同的状态-行动空间。
主要贡献:为了进一步说明视频生成如何对现实世界的应用产生深远影响,我们深入分析了最近的一些工作,这些工作通过指令调整、上下文学习、规划和强化学习等技术,在游戏、机器人、自动驾驶和科学等环境中利用视频生成作为任务求解器、问答、策略/Agent和环境模拟器。最后,我们指出了视频生成的主要困难,并提出了应对这些挑战的可行解决方案,以充分释放视频生成在现实世界中的潜力。
方法概述:
- 除了能够吸收广泛信息的统一表征(unified representation)外,还需要一个统一的任务接口,通过它可以使用单一目标(如下一个标记预测)来表达不同的任务;此外,正是信息表征(如文本)和任务接口(如文本生成)之间的一致性,使得广泛的知识能够转移到特定任务的决策中。
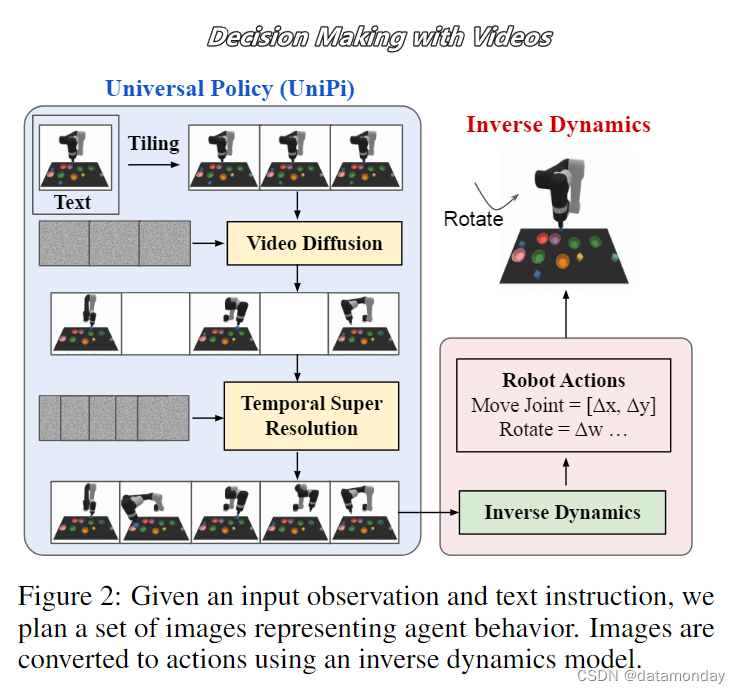
- 使用像素空间作为跨任务和环境的统一状态行动空间。在这一框架下,可以将具身规划视为条件视频生成问题,从而受益于互联网预训练视频生成模型。然后就可以使用额外的模块,如反动力学模型[40],目标条件策略 [41] [33],光流网络 [42] 或密集网格点 [43],从高层次视频规划中恢复低层次机器人控制。
主要结论:
- 视频生成作为一种预训练任务,可能会引发类似于语言模型的推理行为,从而揭示了利用视频生成解决复杂推理和算法任务的机会。
- 尽管视频生成模型具有很强的通用性,但当涉及规划时,世界模型也许并不一定非得是视频模型,潜态空间模型以前常常受到青睐 [48] [49]。
- 可以利用无标签的互联网规模游戏数据来学习潜在动作,然后训练一个可控制动作的视频模型 Genie [35]。这样,就有可能从提示图像中生成无限可能的各种互动环境。
- 高分辨率图像/视频中包含了太多人眼不可见的高频信息,对这些信息的关注会导致缺乏泛化能力。
- 视频生成模型仍有潜力成为自主Agent、规划器、环境模拟器和计算引擎,并最终成为在物理世界中思考和行动的人工大脑。
Abstract
互联网上有大量的文本和视频数据,通过对下一个标记(token)或帧(frame)的预测,可支持大规模的自监督学习(self-supervised learning)。然而,它们并没有得到同等的利用:语言模型对现实世界产生了重大影响,而视频生成在很大程度上仍局限于媒体娱乐。然而,视频数据捕捉到了难以用语言表达的物理世界的重要信息。为了弥补这一不足,我们讨论了一个被忽视的机会,即扩展视频生成功能以解决现实世界中的任务。我们观察到,与语言类似,视频可以作为一个统一的接口(unified interface),吸收互联网知识并表现不同的任务。此外,我们还展示了视频生成如何像语言模型一样,通过上下文学习、规划和强化学习等技术充当规划器、Agent(智能体)、计算引擎和环境模拟器。我们确定了机器人、自动驾驶和科学等领域的主要影响机会,并通过近期工作证明了视频生成中的这些先进功能是如何触手可及的。最后,我们指出了视频生成中阻碍进步的关键挑战。应对这些挑战将使视频生成模型与语言模型一起,在更广泛的人工智能应用中展现出独特的价值。
1 Introduction
过去几年,从互联网文本数据集训练大型语言模型(LLMs)的工作取得了巨大进展(Gemini;GPT-4)。LLMs 在各种任务上的出色表现让人不禁想把人工智能的议程缩减为扩大这些系统的规模。然而,这还不够。首先,公开文本数据的数量正在成为进一步扩展的瓶颈。其次,也许更重要的是,仅靠自然语言可能不足以描述所有智能行为,也无法捕捉到我们所处物理世界的所有信息(例如,想象一下仅用文字教人如何打结)。虽然语言是描述高层次抽象概念的强大工具,但它并不总是足以捕捉物理世界的所有细节。
值得庆幸的是,互联网上有丰富的视频数据(例如,仅YouTube上的连续视频观看时间就超过了一万年),其中蕴含着丰富的世界知识信息。然而,今天在互联网文本或视频数据上训练出来的机器学习模型却表现出了截然不同的能力。LLMs 已经能够处理需要复杂推理 (Huang & Chang, 2022)、工具使用 (Mialon et al., 2023) 和决策制定 的复杂任务。相比之下,视频生成模型的探索较少,主要集中在创建供人类消费的娱乐视频 (Ho et al., 2022a; Singer et al., 2022; Bar-Tal et al., 2024)。鉴于语言建模领域正在发生的范式转变,我们有必要提出这样一个问题:我们能否将视频生成模型提升到与语言模型类似的自主Agent、模拟环境和计算引擎的水平,从而使机器人、自动驾驶和科学等需要视觉模式的应用能够更直接地受益于互联网视觉知识和预训练视频模型。
在本文中,我们认为视频生成对于物理世界的意义就如同语言建模对于数字世界的意义。为了得出这一观点,我们首先确定了使语言模型能够解决许多现实世界任务的关键要素:
- (1) 能够从互联网吸收广泛信息的统一表示法(即文本)。
- (2) 统一接口(即文本生成),通过该接口可以将各种任务表示为生成模型。
- (3) 语言模型能够与外部环境(如人类、工具和其他模型)交互,根据外部反馈采取行动和优化决策,具体技术包括从人类反馈中强化学习,规划,搜索和优化。
从语言模型的这三个方面出发,我们发现:
- (1) 视频可以作为一种统一的表征,吸收物理世界的广泛信息;
- (2) 视频生成模型可以表达或支持计算机视觉、具身人工智能和科学领域的各种任务;
- (3) 视频生成作为一种预训练目标,为大型视觉模型、行为模型和世界模型引入了互联网规模的监督,从而可以提取动作、模拟环境交互并优化决策。
为了进一步说明视频生成如何对现实世界的应用产生深远影响,我们深入分析了最近的一些工作,这些工作通过指令调整、上下文学习、规划和强化学习等技术,在游戏、机器人、自动驾驶和科学等环境中利用视频生成作为任务求解器、问答、策略/Agent和环境模拟器。最后,我们指出了视频生成的主要困难,并提出了应对这些挑战的可行解决方案,以充分释放视频生成在现实世界中的潜力。
2 Preliminaries
我们将简要介绍视频生成模型,以及如何通过条件生成将这些模型用于特定领域。
2.1 Conditional Video Generation
我们将视频片段(video clip)表示为一系列图像帧 x ˉ = ( x 0 , . . . , x t ) \mathbf{\bar{x}} = (x_0, ... , x_t) xˉ=(x0,...,xt)。图像本身可被视为具有单帧 x ˉ = ( x 0 , ) \mathbf{\bar{x}} = (x_0, ) xˉ=(x0,) 的特殊视频。条件视频生成模型是条件概率 p ( x ˉ ∣ c ) p(\mathbf{\bar{x}}|c) p(xˉ∣c),其中 c 是条件变量。条件概率 p ( x ˉ ∣ c ) p(\mathbf{\bar{x}}|c) p(xˉ∣c) 通常由自回归模型 [1],扩散模型或 masked Transformer 模型 [3] 进行因子化。根据不同的因式分解, p ( x ˉ ∣ c ) p(\mathbf{\bar{x}}|c) p(xˉ∣c) 的采样对应于连续预测图像(patches)或迭代预测所有帧 ( x 0 , . . . , x t ) (x_0, ... , x_t) (x0,...,xt)。
[1] Generating Diverse High-Fidelity Images with VQ-VAE-2
[2] Imagen Video: High Definition Video Generation with Diffusion Models, 2023
[3] MaskGIT: Masked Generative Image Transformer, 2023
2.2 Task-Specific Specialization
根据条件变量 c 中的内容,条件视频生成可以达到不同的目的。下面,我们将列举 c 的常见示例及其用例。
p ( x ∣ c = t e x t ) p(\mathbf{x}|c = text) p(x∣c=text)
这与生成式媒体常用的文本到视频模型相对应 [4] [5],文本通常是对所需视频的一些创造性描述(例如,[6] 中的 “A teddy bear painting a portrait”)。文本到视频主要应用于生成电影 [7] 和动画 [8] [9]。
[4] VideoPoet: A Large Language Model for Zero-Shot Video Generation
[5] Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
[6] Make-A-Video: Text-to-Video Generation without Text-Video Data
[7] MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
[8] Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
[9] AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
p ( x ∣ c = { x 0 , t e x t } ) p(\mathbf{x}|c = \{x_0, text\}) p(x∣c={x0,text})
这相当于从给定图像 x 0 x_0 x0 同时结合文本描述,开始生成视频滚动(rollouts)。这种类型的调节(conditioning)已被应用于生成特定场景的视觉交互 [10] 和机器人执行的视觉规划 [11]。当 x \mathbf{x} x 只包含未来图像 x t x_t xt 时, p ( x t ∣ c = x 0 , t e x t ) p(x_t | c = {x_0, text}) p(xt∣c=x0,text) 可以预测机器人操作的视觉目标 [12] [13]。这种目标合成方法的灵感主要来自于大量关于风格化图像生成和涂色的文献 [14] [15]。
[10] Learning Interactive Real-World Simulators
[11] Learning Universal Policies via Text-Guided Video Generation
[12] Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
[13] Scaling Robot Learning with Semantically Imagined Experience
[14] Image quilting for texture synthesis and transfer
[15] Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
p ( x ∣ c = { x ˉ , t e x t } ) p(\mathbf{x}|c = \{\mathbf{\bar{x}}, text\}) p(x∣c={xˉ,text})
当 x \mathbf{x} x 和 x ˉ \mathbf{\bar{x}} xˉ 具有相同的基本内容时,这相当于文本引导的视频编辑和风格化 [16] [17],已被应用于生成不同天气条件下的自驾车视频 [18]。请注意, x ˉ \mathbf{\bar{x}} xˉ 也可以与 x \mathbf{x} x 完全不同,在这种情况下, x ˉ \mathbf{\bar{x}} xˉ 可以作为视觉提示,在输出视频中引出某些模式 [19]。
[16] Interactive Language: Talking to Robots in Real Time
[17] Probabilistic Adaptation of Text-to-Video Models
[18] GAIA-1: A Generative World Model for Autonomous Driving
[19] Sequential Modeling Enables Scalable Learning for Large Vision Models
p ( x i + 1 ∣ c = { x i , a c t i o n } ) p(x_{i+1} | c = \{x_i, action\}) p(xi+1∣c={xi,action})
这相当于学习一个视觉动力学模型,其中的动作可以是机器人控制 [10],键盘输入 [21] 或其他导致视觉空间变化的运动信息 [22]。如果我们在某个 t > 1 的条件下用 xi+t 替换 xi+1,我们就得到了一个时间抽象动力学模型 [23]。在这种情况下,我们也可以将 xi 替换为 (xi, xi+1, … , xi+t-1) 的任意子序列。
[21] Mastering Atari with Discrete World Models
[22] Generative Image Dynamics
[23] Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning
条件视频生成的这些特殊化表明,可能存在一个通用框架,在此框架下,可以吸收广泛的视频数据,并使用视频生成来表达不同的任务。
3 Unified Representation and Task Interface
在本节中,我们将首先介绍视频是如何作为一种统一的表征(unified representation),从互联网中捕捉各种类型的信息,从而形成广泛的知识。然后,我们将讨论如何将计算机视觉和人工智能中的各种任务表述为条件视频生成问题,从而为现实世界中的视频生成决策提供基础。用于生成示例的模型详情见附录 A。其他生成的视频见附录 B。
3.1 Video as a Unified Representation of Information
虽然互联网文本数据通过大型语言模型为数字/知识世界提供了很多价值,但与物理世界的低层次细节(low-level details)相比,文本更适合捕捉高层次的抽象(high-level abstractions)概念。下面,我们列举了几类难以用文本表达,但可以通过视频轻松捕捉的信息。
Visual and Spatial Information
这包括色彩、形状、纹理、灯光效果等视觉细节,以及物体在空间中的排列方式、相对位置、距离、方向和 3D 信息等空间细节。相对于文本格式,这些信息自然以图像/视频格式存在。
Physics and Dynamics
这包括物体和环境之间如何进行物理交互的细节,如碰撞、操纵和其他受物理定律影响的运动。虽然文字可以描述高层次的运动(如 “a car driving down the street”),但往往不足以捕捉到低层次的细节,如施加在车辆上的扭矩和摩擦力。视频可以隐含地捕捉这些信息。
Behavior and Action Information
这包括人类行为和Agent行动等信息,描述了执行任务(如如何组装一件家具)的低层次细节。与精确的动作和运动等详细信息相比,文本大多能捕捉到如何执行任务的高层次描述。
Why Video?
有人可能会问,即使文本不足以捕捉上述信息,为什么还要用视频呢?为了回答这个问题,我们认为视频除了存在于互联网规模之外,还可以为人类所解释(类似于文本),因此可以轻松地进行调试、交互和安全推测。此外,视频是一种灵活的表征方式,可以表征不同空间和时间分辨率的信息,例如以 angstrom scale ( 1 0 − 10 m 10^{−10} \ m 10−10 m) 运动的原子 [24] 和以每秒万亿帧速度运动的光 [25]。
[24] Neural Network Analysis of Electron Microscopy Video Data Reveals the Temperature‐Driven Microphase Dynamics in the Ions/Water System
[25] A trillion frames per second: the techniques and applications of light-in-flight photography
3.2 Video Generation as a Unified Task Interface
除了能够吸收广泛信息的统一表征(unified representation)外,我们还从语言建模中看到,我们需要一个统一的任务接口,通过它可以使用单一目标(如下一个标记预测)来表达不同的任务;此外,正是信息表征(如文本)和任务接口(如文本生成)之间的一致性,使得广泛的知识能够转移到特定任务的决策中。在本节中,我们将展示各种视觉任务以及更广泛的问题解答、推理和问题解决任务如何都能以视频生成任务的形式表达。
Classical Computer Vision Tasks.

(Prompts 都是成对的)
在自然语言处理领域,许多任务(如机器翻译、文本摘要、问题解答、情感分析、命名实体识别、语音部分标记、文本分类、对话系统)传统上被视为不同的任务,但现在都统一在语言建模的范畴内。这使得不同任务之间的通用性和知识共享得以加强。同样,计算机视觉也有一系列广泛的任务,包括语义分割、深度估计、表面法线估计、姿态估计、边缘检测和物体跟踪。最近的研究表明,可以将不同的视觉任务转换成图 1 所示的视频生成任务 [26-28],而且这种解决视觉任务的统一方法可以随着模型大小、数据大小和上下文长度的增加而扩展 [29]。
[26] Sequential Modeling Enables Scalable Learning for Large Vision Models
[27] Visual Prompting via Image Inpainting
[28] Images Speak in Images: A Generalist Painter for In-Context Visual Learning
[29] Sequential Modeling Enables Scalable Learning for Large Vision Models
将视觉任务转换为视频生成任务一般涉及以下步骤:
- (1) 将任务的输入和输出(如分割图、深度图)结构化到统一的图像/视频空间中;
- (2) 对图像帧重新排序,使输入图像后跟有特定任务的预期输出图像(如常规输入图像后跟有深度图);
- (3) 利用上下文学习,提供示例输入-输出对作为条件视频生成模型的输入,以指定所需的任务。
Video as Answers.

在传统的视觉问题解答(VQA)中,预期答案在文本中。随着视频生成技术的发展,一个新颖的任务是将视频作为答案,例如,针对 “how to make an origami airplane” 生成视频 [30] [10]。与语言模型可以对文本中的人类询问生成定制回复类似,视频模型也可以对具有大量低层次细节的如何操作问题生成定制回复。这种视频回答比文本回答更受人类欢迎 [31]。在图 2 中,我们展示了由文本到视频模型生成的视频,这些视频是对一组 “如何做” 问题的回答。此外,我们还可以考虑以初始帧为条件生成视频,以合成用户特定场景中的视频答案。
[30] GenHowTo: Learning to Generate Actions and State Transformations from Instructional Videos
[31] If a picture is worth a thousand words is video worth a million? Differences in affective and cognitive processing of video and text cases
尽管有如此宏伟的承诺,但当今文本到视频模型合成的视频一般都太短/太简单,没有足够的信息来全面回答用户的问题。
合成视频帧以回答用户问题的问题与使用语言模型 [32] 进行规划有相似之处,除了状态空间和低级动作空间现在都是像素而不是文本。人们可以利用语言模型或视觉语言模型将高层次目标(如 “how to make sushi”)分解为具体的子目标(如 “first, put rice on rolling mat”),并为每个子目标合成规划,同时验证合成规划的合理性 [33]。
[32] PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change
[33] Video Language Planning
Visual Reasoning and Chain-of-Thought.

有了统一的信息表征和统一的任务接口,语言建模中就出现了推理,在语言建模中,模型可以诱导出相关信息,作为解决更复杂问题的中间步骤 [34]。同样,以视频作为统一的表示和任务接口,视频生成也通过预测图像的掩码区域显示出视觉推理的早期迹象,如图 3 所示 [35]。与 [36] 类似,通过生成具有正确辅助线集合(set of auxiliary lines)的视频,下一帧预测是否可用于解决更复杂的几何问题,这将是一个有趣的研究课题。

基于利用下一帧预测进行视觉推理和解决几何问题的想法,我们可以利用视频进一步描述推理过程 [37] 和算法 [38]。具体来说,[38] 利用视频描述了广度优先搜索(BFS)算法的执行状态。在这种情况下,学习生成视频与学习搜索相对应,如图 4 所示。虽然图 3 和图 4 中的示例可能看起来有些矫揉造作,但它们作为早期指标表明,视频生成作为一种预训练任务,可能会引发类似于语言模型的推理行为,从而揭示了利用视频生成解决复杂推理和算法任务的机会。
[34] Chain of Thought Prompting Elicits Reasoning in Large Language Models
[35] Genie: Generative interactive environments
[36] Solving olympiad geometry without human demonstrations
[37] Let’s think frame by frame with vip: A video infilling and prediction dataset for evaluating video chain-of-thought
[38] Chain of thought imitation with procedure cloning
3.3 Video as a Unified State-Action Space
我们已经看到,视频生成可以吸收广泛的知识,并描述不同的视觉任务。在本节中,我们将通过提供具身人工智能中使用视频作为统一表征和任务接口的具体实例,进一步支持这一观点。

长期以来,具身人工智能面临的挑战之一是数据碎片化(data fragmentation),即一个机器人在执行一组任务时收集的数据集对另一个机器人或另一组任务的学习几乎毫无用处 [39]。跨机器人和跨任务知识共享的主要困难在于,每种类型的机器人和任务都有不同的状态-行动空间。为了解决这一难题,[40] 主张使用像素空间作为跨任务和环境的统一状态行动空间。在这一框架下,可以将具身规划视为条件视频生成问题,从而受益于互联网预训练视频生成模型。然后就可以使用额外的模块,如反动力学模型[40],目标条件策略 [41] [33],光流网络 [42] 或密集网格点 [43],从高层次视频规划中恢复低层次机器人控制。我们在图 5(上)中展示了以往工作生成的视频规划。大多数现有工作都是为每个机器人训练一个视频生成模型,这削弱了将视频作为统一的状态-动作空间用于具身学习的潜在优势。我们在图 5(下),我们通过在Open X-Embodiment 数据集上使用一组不同的机器人和任务训练视频生成模型,提供了额外生成的视频计划。以前和新生成的视频计划看起来都非常逼真,并成功地完成了指定的任务。
[39] Open X-Embodiment: Robotic Learning Datasets and RT-X Models
[40] Learning Universal Policies via Text-Guided Video Generation
[41] Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
[42] Learning to Act from Actionless Videos through Dense Correspondences
[43] Any-point Trajectory Modeling for Policy Learning
[40] 中的图:
4 Video Generation as Simulation
虽然视频生成本身已经可以解决上一节所述的许多任务,但视频生成的另一个重要机会是模拟对各种系统和过程的视觉观察,以便根据模拟结果优化系统的控制输入。这对于可以收集大量视频数据,但难以明确表达基本动态(如云的移动、与软物体的交互)的应用尤其有用。在本节中,我们将首先研究游戏环境中的视觉生成模拟器,在游戏环境中,我们可以使用Ground Truth游戏引擎来验证所学模拟器的质量,并迭代有效生成新体验的模拟器。然后,我们将举例说明模拟真实世界的过程,如机器人交互、自动驾驶和原子级交互。用于生成示例的生成模型详情见附录 A。其他生成模拟结果见附录 B。
4.1 Generative Game Environments
几十年来,游戏一直被用作人工智能算法的试验平台 [44]。例如,街机学习环境 [45] 促成了 deep Q-learning 的开发,这是第一个在玩 Atari 游戏中达到人类水平的人工智能 Agent [46]。同样,我们也可以将游戏视为一种手段,通过与游戏引擎的 Ground Truth 模拟进行比较,来测试生成式模拟器的质量。未来,我们甚至有可能利用生成模型来超越现有人类设计的模拟环境。在本节中,我们将讨论从模拟单一复杂环境到生成全新环境的各种可能性。
[44] Artificial Intelligence for Games
[45] The arcade learning environment: an evaluation platform for general agents
[46] Human-level control through deep reinforcement learning
Simulating Complex Games.
以行动为条件的视频生成可以模拟复杂计算机游戏(如 Minecraft)的环境动态。作为概念验证,我们训练了一个基于 Transformer 的架构,该架构在时间上具有自回归性,可预测未来Agent的行动,并以历史事件为条件进行观察。我们使用了 [47] 的 “contractor data”,该数据由人类与游戏互动时收集的轨迹(trajectories)组成。观察和行动都是量化标记(quantized tokens),从而减少了基于模型的下一个标记预测的滚动(rollout)。在这种情况下,模型既是世界模型(World Model),也是策略:给定一个以行动结束的观察和行动交替序列,模型就能推断出下一个观察结果(世界模型);给定一个以观察结束的类似序列,模型就能推断出下一个行动(策略)。图 6 显示了该模型生成的一些轨迹。该模型能够生成与复杂策略相对应的行动和转换(例如,using a pickaxe to break a stone block)。

有了这样的策略和动力学骨干,基于模型的强化学习算法——如 Dyna (Sutton, 1991),Dreamer (Hafner et al., 2020) 和 MuZero (Schrittwieser et al., 2019; Antonoglou et al., 2022)——就可以用来改进策略。这需要从动态模型中进行大量采样,反过来又要求生成模型的计算效率高。需要注意的是,尽管视频生成模型具有很强的通用性,但当涉及规划时,世界模型也许并不一定非得是视频模型,潜态空间模型以前常常受到青睐 [48] [49]。
[47] Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
[48] Robot Motion Planning in Learned Latent Spaces, 2019
[49] Mastering Atari with Discrete World Models, 2020
Generating Novel Game Environments.
程序化生成新颖的游戏内容和关卡是游戏人工智能界一个活跃的研究领域 (Summerville et al., 2018),这已被证明对 RL Agent的训练和评估都很有用 (Risi & Togelius, 2020; Justesen et al., 2018; Cobbe et al., 2020)。有人尝试利用生成模型进行游戏设计,方法是直接预测帧 (Bamford & Lucas, 2020) 或修改背景以生成新的游戏关卡 (Kim et al., 2020)。然而,这些工作依赖于特权模拟数据,而且只在小范围内进行过尝试,限制了生成全新游戏环境的潜力。
最近的研究表明,可以利用无标签的互联网规模游戏数据来学习潜在动作,然后训练一个可控制动作的视频模型 Genie [35]。这样,就有可能从提示图像中生成无限可能的各种互动环境。图 7 显示了在两个新颖的起始帧中,由人类玩家选择潜在动作控制生成的游戏轨迹。虽然这项工作仍处于探索阶段,但我们可以想象,未来也有可能整合所学奖励模型 [50-52],在完全生成的游戏环境中训练 RL Agent。
[50] Vision-Language Models as a Source of Rewards
[51] Vision-Language Models as Success Detectors
[52] Video Prediction Models as Rewards for Reinforcement Learning

4.2 Robotics and Self-Driving.
Simulating the SE(3) Action Space
机器人学习的长期挑战之一是模拟到真实的转移 (Rusu et al., 2017),在模拟器中训练的策略无法迁移到真实机器人上执行。[10] 证明,可以在 Language Table environment [54] 中的真实机器人视频数据上,利用简单的 Cartesion 动作空间,学习以动作为条件的下一帧预测模型。在图 8 中,我们展示了下一帧预测可以预测 SE(3) space (Blanco-Claraco, 2021) 中更一般的末端执行器动作的视觉效果。

生成式 SE(3) 模拟器的一个直接用例是评估机器人策略,考虑到与真实机器人评估相关的安全因素,这一点尤其有用。除了评估之外,[10] 还在语言表环境中使用生成式模拟器的滚动(rollout)功能训练了 RL 策略。有趣的下一步是使用 Dyna 式算法 (Sutton, 1991) 从模拟滚动和真实环境中学习策略。在这种情况下,将在执行策略时收集真实世界的视频,作为生成式模拟器的额外演示和反馈。最后,生成式模拟器可以通过在不同环境中播放视频,对多任务和多环境策略进行有效训练。这在以前是不可能实现的,因为策略通常一次只能进入一个真实环境。
[54] Interactive language: Talking to robots in real time
Domain Randomization.
广泛适用于机器人、导航和自动驾驶的生成式模拟器的另一个优点是,它们能够为训练环境引入自然随机性,从而提高在模拟中训练的策略在现实世界中的迁移能力。如果没有生成式模型,就只能通过硬编码渲染规则来实现域随机化 [55],这不仅繁琐,而且会导致有限的环境变化和不切实际的渲染效果。最近的研究表明,利用生成式模拟器,可以在模拟器中引入不同的驾驶条件(如晴天、雾天、雪天、雨天、夜间)[18]。此外,结合互联网规模的知识,我们还可以模拟特定地点的驾驶条件,例如模拟在金门大桥上的雨中驾驶,如图 9 所示,这样就可以训练具有不同地点和天气条件的自动驾驶策略。

[55] Domain randomization for transferring deep neural networks from simulation to the real world, 2017
4.3 Science and Engineering
视频可以在广泛的科学和工程领域中作为一种统一表示(unified representation),对医学成像、计算机图像处理和计算流体动力学等研究领域产生影响 (Steinman, 2002)。在视觉信息容易被摄像机捕捉,但底层动态系统难以识别的情况下(如云层运动、电子显微镜下的原子运动),以控制输入为条件的视频生成模型可以成为有效的视觉模拟器,进而用于推导出更好的控制输入。在图 10 中,我们利用 [56] 收集的 STEM 数据,展示了单层碳原子上的硅原子在扫描透射电子显微镜(STEM)的电子束刺激下的过渡动态。我们可以看到,生成式模拟器能够描述硅原子在像素空间中的运动。
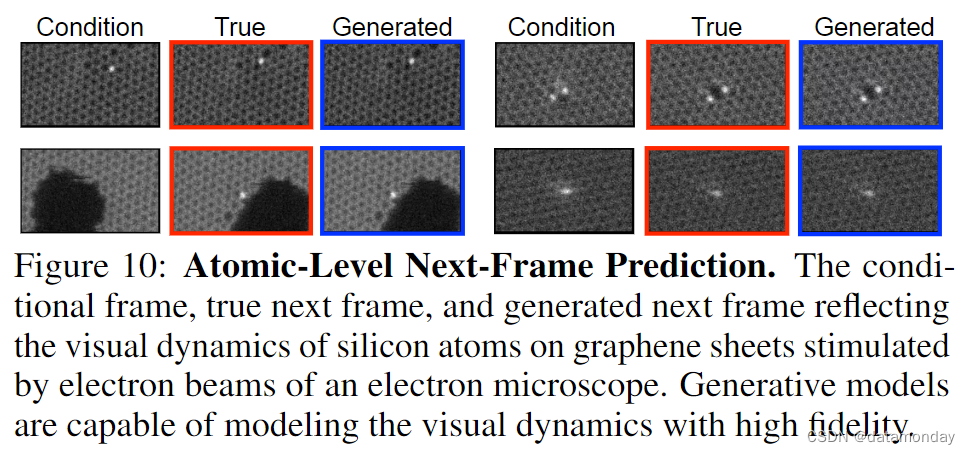
在需要操作电子显微镜等专业设备的科研工作中,采用高度逼真的视觉模拟器来响应控制输入可以缓解硬件访问受限的问题。不过,利用视觉生成模拟器优化控制输入还需要进一步研究,以确保其有效性和有效性。
除了缩小模拟科学过程中模拟与真实之间的差距外,生成式模拟器的另一个好处是它们有固定的计算开销,这在传统计算方法难以解决的情况下是有益的。例如,模拟热量计阵雨需要计算电子之间的成对相互作用,当电子数量较多时,这种计算的复杂性很快就会变得不切实际 [57]。另一方面,电子阵列视频的计算量与阵列建模的分辨率成正比。
[56] Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy
[57] Score-based Generative Models for Calorimeter Shower Simulation
5 Challenges
虽然视频生成技术潜力巨大,但其应用仍面临一些重大挑战。我们将在本节中概述这些挑战和潜在的解决方案。
5.1 Dataset Limitations
Limited Coverage.
在语言建模中,用于解决特定下游任务的语言数据的分布一般都在互联网文本数据的分布范围内。然而,视频的情况并非如此。在互联网上发布的视频都是以人类兴趣为导向的,并不一定是对下游任务有用的视频数据。例如,计算流体动力学模型可能需要许多以水等流体运动为主题的长视频;这种持续数小时的视频对人类来说并不十分有趣,因此在互联网上很少见。同样,在互联网上找到执行特定任务(如叠衣服)的特定类型机器人(如 Franka Emika Panda 机器人)也很罕见。这就需要更好地促进特定领域视频数据的收集和传播。用于机器人技术的 Open-X Embodiment 数据集就是这样一个例子。
Limited Labels.
视频建模的另一个挑战是缺乏带注释的视频。例如,MineDojo 数据集 [58] 有超过 300 万小时的人类玩 Minecraft,但数据集只有语言转录但没有游戏动作标签,因此很难使用该数据集训练策略或环境模型。同样,在最大的开源机器人数据集 Open-X Embodiment 中,许多机器人轨迹对正在执行的任务没有语言注释,或者只有通用标签,例如 “interact with any object”。
为了标注更多的视频数据,先前的工作利用图像/视频描述模型提供额外的文本标签,这些标签可进一步用于训练文本到图像/视频模型 [60] [59]。这与视频预训练(VPT)[47] 类似,只不过 VPT 是用动作数据而不是文本数据来标记视频。另一种可能性是利用从视频中推断出的潜在动作/技能 [61] [62] [63],其中规模最大的例子是 Genie [35]。在附录 B 的图 13 中,我们展示了潜动作的示例。尽管学习到的潜在行动具有一致性,但这种方法能否扩展到更复杂、更多样的动态中,仍是一个未决问题。
[58] MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge, 2022
[59] Improving Image Generation with Better Captions, 2023
[60] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
[61] Imitating Latent Policies from Observation
[62] Learning what you can do before doing anything
[63] Become a Proficient Player with Limited Data through Watching Pure Videos
5.2 Model Heterogeneity
与语言模型趋同于自回归架构的情况不同,视频生成还没有找到最佳方法。自回归模型、扩散模型和掩码模型各有利弊。
Diffusion Models.
扩散模型 [2] [64](如第 3.3 节中使用的模型)有两大优势。首先,它们可以轻松地为连续的输出空间建模,而无需标记化(tokenization),这可以提高生成质量。其次,可以并行对多个帧进行采样。然而,扩散模型的采样速度仍然相当慢,限制了其在实时模拟中的应用。此外,目前还不清楚如何利用扩散模型生成长视频序列。众所周知,扩散模型对噪声调度等超参数很敏感,这使得训练和缩放变得困难 [65]。
[64] Deep Unsupervised Learning using Nonequilibrium Thermodynamics, 2015
[65] Diffusion Models in Vision: A Survey, 2023
Autoregressive Models.
具有标记化输出空间的自回归模型(如第 4.1 节中提到的模型)比扩散模型更容易训练。标记化还允许视频生成与文本或离散动作生成相结合,从而开辟了更多需要多模态生成的应用领域 [66]。此外,自回归模型能很好地扩展上下文长度,从而有可能为很长的帧序列建模。不过,自回归解码的计算成本较高,因为每个标记都必须按顺序进行预测。此外,自回归引导视频可能会受到漂移效应的影响 [67]。
[66] Gemini: A Family of Highly Capable Multimodal Models. 2023
[67] ART • V: Auto-Regressive Text-to-Video Generation with Diffusion Models, 2023
Masked Models.
基于掩码重构的模型(如第 4.1 节中用于生成新奇游戏环境的模型)可以通过并行采样成批图像标记来利用扩散的某些优点,并减轻标记自回归建模的某些问题 [3]。这样就能像 Genie[35] 的研究那样,只需调用几十次模型,就能对由数千个标记组成的图像进行采样。然而,这种方法也带来了一些挑战,例如单个采样步骤中的独立性假设所带来的采样偏差。
Better Future Models.
解决模型异质性的潜在方法可能需要结合不同模型的优势,如结合自回归模型和掩蔽模型 [68] 或结合自回归模型和扩散模型 [67]。此外,视频数据可能包含空间和时间上的冗余信息。未来的模型可以考虑学习潜在空间来减少冗余。更好的视频生成模型还应解决目前在生成速度和现有模型长期一致性方面的挑战。
[68] Temporally Consistent Transformers for Video Generation
5.3 Hallucination
视频生成中的幻觉在不同类型的模型中都很常见。
- 例如,物体会随机出现或消失(见图 8 底行和附录 B.5)。这可能是由于物体的损失权重往往没有背景的损失权重高,因为物体通常很小。
- 另一种常见幻觉涉及难以置信的动态效果,例如,杯子 “跳” 到机器人手上,而不是机器人抓住杯子。这可能是由于时间频率较低的视频没有捕捉到准确的运动关键帧。
- 此外,同时为行为和动态建模的生成模型可能无法区分由动作或动态引起的视觉变化。当用户的输入在特定场景下不切实际时,也会产生幻觉,例如,向桌面机器人发出 “洗手” 的指令。尽管如此,我们已经看到,如图 11 所示,视频生成模型试图通过利用第一视角的运动来实现不切实际的用户输入,从而生成逼真的视频。外部反馈强化学习等方法可用于进一步减少视频生成模型中的幻觉。

5.4 Limited Generalization
从任意图像和文本输入生成视频一直是个难题。这对于训练数据没有很好体现的领域来说尤其如此,由于第 5.1 节中讨论的有限数据覆盖挑战,这种情况在实践中很常见。以扩散模型为例,通常先在低分辨率视频上进行训练,然后再进行空间超分辨率训练,以防止过拟合。我们的假设是,高分辨率图像/视频中包含了太多人眼不可见的高频信息,对这些信息的关注会导致缺乏泛化能力。
6 Conclusion
我们的立场是,视频生成对于物理世界就像语言建模对于数字世界一样。为了支持这一观点,我们展示了视频如何与语言模型相似,能够代表广泛的信息和任务。我们进一步介绍了视频生成与推理、上下文学习、搜索、规划和强化学习相结合以解决现实世界任务的应用方面的前期工作和新观点。尽管存在幻觉和泛化等挑战,视频生成模型仍有潜力成为自主Agent、规划器、环境模拟器和计算引擎,并最终成为在物理世界中思考和行动的人工大脑。
Appendix
A Details of Models Used to Generate Examples in the Main Text
A.1 Autoregressive Model
第 4.1 节中的模型在时间上是自回归的,但在每一帧中使用了与 TECO 类似的掩码模型 (Chang et al., 2022)。对于具有相应动作 at 的给定像素观测轨迹 xt,我们对交错序列 z0, a0, z1, a1, … 进行建模,其中我们通过 VQVAE 结合 Vision Transformer 将像素观测 xt 编码为标记 zt。我们根据 VPT 对动作进行标记化。我们利用 Transformer-XL 来编码时间轨迹 z0, a0, z1, a1, … 与时间对齐的输出 hz0 , ha0 , hz1 , ha1 , …。对于最后一次输入是观察结果的步骤(即 hzt),我们利用上下文 hzt 作为自回归Transformer头的条件输入来预测 at。如果最后一次输入是一个动作,则上下文 ha0 将作为一个屏蔽变换头的条件输入,以对 zt 进行建模。我们的 MaskGIT 实现采用了 8 步余弦屏蔽规划。为了进一步提高交错Transformer的性能,我们使用过去的编码器对内存进行初始化,即使用交错序列 …, x-2, a-2, x-1, a-1 分别训练一个相同的Transformer,不对输入进行任何离散化。
A.2 Diffusion Model
用于生成图 2、图 5、图 8、图 9 和图 10 中示例的扩散模型采用了与 Ho et al. (2022b;a) 相同的3D U-Net 架构,在空间下采样通路和空间上采样通路中具有交错的3D注意层和卷积层。跳转连接应用于下采样通路激活。该模型使用像素空间扩散,而非潜伏空间扩散。按照第 5 节所述的视频扩散惯例,低分辨率视频生成模型在分辨率[24, 40]下运行,随后是两个空间超分辨率模型,目标分辨率分别为[48, 80]和[192, 320]。文本或动作调节采用无分类器引导 (Ho & Salimans, 2022)。对于帧调节,我们将调节帧输入用于无分类器引导的条件模型和非条件模型。为了模拟图 8 所示的 SE(3) 动力学,我们采用了类似于 Yang et al. (2023b) 和 Padalkar et al. (2023) 的动作离散化方法。
A.3 Masked Model
Genie (Bruce et al., 2024) 中的掩码动力学模型生成了第 4.1 节中的新奇游戏环境,它是一个可控的视频延续模型,在帧级别上产生自回归输出,条件是代表转换的无监督潜变量。潜变量由一组离散的 VQ-VAE 代码 a1:T -1 组成,这些代码以帧 x1:T 为条件,并通过因果Transformer进行优化,以帮助预测 ˆx2:T。动态模型是一个具有交错时间和空间注意力的Transformer,按照 MaskGIT (Chang et al., 2022) 使用掩码重构目标进行训练。视频标记以平均 75% 的比率用独立随机伯努利掩码进行掩码,动态模型通过最小化交叉熵目标进行训练,以预测丢失的标记。
在推理过程中,标记会按照 MaskGIT 的方法并行生成。从画面 x1:t-1 的未屏蔽上下文标记和完全屏蔽的画面 xt 开始,会执行一系列迭代步骤,其中每一步都会计算以 x1:t 和 a1:t 为条件的所有标记的对数,对每个剩余屏蔽位置的候选标记进行采样,并锁定概率最高的采样用于未来的步骤。在 Genie 中,每幅图像由 920 个标记组成,最终在 25 个 MaskGIT 步骤中对所有标记进行采样。
该模型完全是在大型视频数据集上进行无监督训练的;10.7B 参数模型的轨迹示例见 13,表明无监督潜动作目标可在各种视觉提示中产生一致的控制变量。
B Additional Generated Videos
B.1 Additional Game Simulations

B.2 Additional Generation for How-to Videos


B.3 Additional Self-Driving Simulations

B.4 Additional Robot SE(3) Simulations

B.5 Examples of Hallucination

![Sqli-labs靶场第16关详解[Sqli-labs-less-16]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/20749ba7b3164afc86bf6a7f549c095a.png)




![BUUCTF---[极客大挑战 2019]Http1](https://img-blog.csdnimg.cn/direct/e5dbb05113344d178bdcce4ee79df072.png)