目录
- 前言
- 一、 单机模式
- 二、 伪分布式模式
- 三、 完全分布式模式(重点)
- 3.1 准备工作
- 3.2 配置集群
- 3.2.1 配置core-site.xml 文件
- 3.2.2 配置hdfs-site.xml 文件
- 3.2.3 配置yarn-site.xml 文件
- 3.2.4 配置mapred-site.xml 文件
- 3.3 启动集群
- 3.3.1 配置workers
- 3.3.2 启动集群
- 3.3.3 集群测试
- 总结
前言
Hadoop作为一种强大的大数据处理框架,有多种运行模式,每种模式都适用于不同的使用场景。本文将介绍Hadoop的三种常见运行模式:单机模式、伪分布式模式和完全分布式模式。
一、 单机模式
单机模式是Hadoop最简单的运行模式。在单机模式下,所有Hadoop组件都运行在单个机器上,包括HDFS、MapReduce等。由于只有一个节点参与计算,单机模式适用于开发和测试阶段,不适用于处理大规模数据。在单机模式下,Hadoop的所有组件运行在同一进程中,能够快速展示整个处理流程,方便开发人员进行调试和验证。
我们这里就拿官方的WordCount做一个简单的演示:
- 在hadoop-3.2.4文件下面创建一个input文件夹
[amo@hadoop102 hadoop-3.2.4]$ mkdir input - 在input文件下创建一个word.txt文件
[amo@hadoop102 hadoop-3.2.4]$ cd input - 编辑word.txt文件
[amo@hadoop102 hadoop-3.2.4]$ vim word.txt
- 在文件中输入如下内容
hadoop hello
hdfs mapreduce yarn
amoxilin amoxilin
- 保存退出::wq
- 回到Hadoop目录/opt/module/hadoop-3.2.4
- 执行程序
[amo@hadoop102 hadoop-3.2.4]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount input output
- 查看结果
[amo@hadoop102 hadoop-3.2.4]$ cat output/part-r-00000
看到如下结果:
amoxilin 2
hadoop 1
hello 1
hdfs 1
mapreduce 1
yarn 1
二、 伪分布式模式
伪分布式模式是Hadoop的中级运行模式。在伪分布式模式下,Hadoop的各个组件运行在单台计算机上,但每个组件都是独立运行的。这意味着可以模拟一个小规模的分布式环境,包括一个主节点Namenode和多个工作节点Datanode。伪分布式模式适用于在本地环境中进行开发和测试,并且能够模拟数据分片和分布式计算的过程,从而更真实地了解Hadoop的工作原理。
以下是配置 Hadoop 伪分布式模式的一般步骤:
-
安装 Hadoop:按照 Hadoop 的官方文档,下载并安装合适版本的 Hadoop。
-
配置 HDFS:编辑 Hadoop 配置文件 core-site.xml 和 hdfs-site.xml ,设置适当的配置参数。例如,指定本地文件系统作为 HDFS 的存储路径,并设置副本数。
-
配置 YARN:编辑 YARN 配置文件 yarn-site.xml ,设置适当的参数,如指定本地资源管理器地址和可用的计算资源。
-
设置环境变量:将 Hadoop 的 bin 目录路径添加到系统的 PATH 环境变量中。
-
配置 SSH:启用 SSH,并配置免密登录以设置 Hadoop 的分布式通信。
-
启动 Hadoop:运行启动脚本,启动 HDFS 和 YARN。可以通过浏览器访问相应的管理控制台,如 NameNode 页面、ResourceManager 页面等。
-
执行任务和作业:提交 MapReduce 任务或其他计算任务到 Hadoop 集群,并通过 Hadoop 提供的 API 或命令行工具进行操作。
需要注意的是,伪分布式模式仅适用于开发和测试目的,因为只有一个物理/虚拟机器负责运行所有的组件,所以它并不能提供真正的分布式性能和容错能力。
总之,Hadoop 伪分布式模式是用于在单台计算机上模拟分布式环境的配置方式,可用于本地开发、调试和验证大数据应用程序。这里只做简单的介绍,感兴趣的可以自己搭一下玩玩,重点是下面的完全分布式模式。
三、 完全分布式模式(重点)
完全分布式模式是Hadoop的最常用运行模式。在完全分布式模式下,Hadoop集群由多台计算机组成,每个节点扮演着不同的角色。集群中包含一个主节点Namenode和多个工作节点Datanode,每个节点负责存储和处理数据。完全分布式模式可以处理大规模的数据集,并且具有高可靠性和容错性。Hadoop集群通过分布式存储和计算的方式,实现了大规模数据的快速处理和分析。
3.1 准备工作
1) 准备三台服务器,安装并配置jdk和hadoop
2)集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode / DateNode | DataNode | SecondaryNameNode / DataNode |
| YARN | NodeManager | ResourceManager / NodeManager | NodeManager |
注意:NameNode和SecondaryNameNode不要安装在同一台服务器,ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上
3)配置文件说明
Hadoop配置文件分为两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
-
配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在$HADOOP_HOME/etc/hadoop 这个路径下面,用户可以根据项目需求重新进行修改配置。
-
core-site.xml:这个文件包含了Hadoop核心配置的相关属性,比如文件系统的默认URI (fs.defaultFS)、临时文件目录 (hadoop.tmp.dir)等。 -
hdfs-site.xml:这个文件包含了HDFS(Hadoop分布式文件系统)的相关配置属性,比如副本数 (dfs.replication)、数据块大小 (dfs.blocksize)等。 -
mapred-site.xml:这个文件包含了MapReduce框架的相关配置属性,比如MapReduce作业历史服务器地址 (mapreduce.jobhistory.address)、任务并行度 (mapreduce.job.running.map.limit)等。在较新的Hadoop版本中,这个文件被废弃,相关配置已经移动到yarn-site.xml中。 -
yarn-site.xml:这个文件包含了YARN(Yet Another Resource Negotiator)的相关配置属性,比如NodeManager的内存限制 (yarn.nodemanager.resource.memory-mb)、ApplicationMaster的内存限制 (yarn.app.mapreduce.am.resource.mb)等。
-
3.2 配置集群
3.2.1 配置core-site.xml 文件
<configuration>
<!-- 指定NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定Hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为amo-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>amo</value>
</property>
</configuration>
3.2.2 配置hdfs-site.xml 文件
<configuration>
<!-- nn web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
3.2.3 配置yarn-site.xml 文件
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
3.2.4 配置mapred-site.xml 文件
<configuration>
<!-- 指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置完成之后,在集群上分发配置好的Hadoop配置文件,然后去hadoop103和hadoop104查看配置文件分发情况
3.3 启动集群
3.3.1 配置workers
vim /opt/module/hadoop-3.2.4/etc/hadoop/workers
hadoop102
hadoop103
hadoop104
注意:该文件添加的内容结尾不允许有空格,文件中不允许有空行
同步所有节点xsync /opt/module/hadoop-3.2.4/etc/hadoop/workers
前提是你已经为每个节点进行了hostname的命名。而且每个节点的hosts文件你修改了本地dns的指向,让这些主机指向约定好的IP。然后每个节点的hosts文件保持同步。
3.3.2 启动集群
# 格式化NameNode 如果集群是第一次启动,需要在hadoop102节点格式化NameNode
[amo@hadoop102 hadoop-3.2.4]$ hdfs namenode -format
# 启动hdfs
[amo@hadoop102 hadoop-3.2.4]$ sbin/start-dfs.sh
# 启动yarn 在配置了resourceManager的节点(hadoop103)启动yarn
[amo@hadoop102 hadoop-3.2.4]$ sbin/start-yarn.sh
(注意:格式化 NameNode,会产生新的集群id,导致 NameNode 和 DataNode 的集群id不一致,集群找不到以往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 NameNode 和 DataNode 进程,并且删除所有机器的data和logs目录,然后再进行格式化)
jps可以查看各个节点的配置是否和我们的集群规划避暑一致

Web端查看hdfs的NameNode
- 浏览器中输入
hadoop102:9870 - 查看hdfs上的存储信息
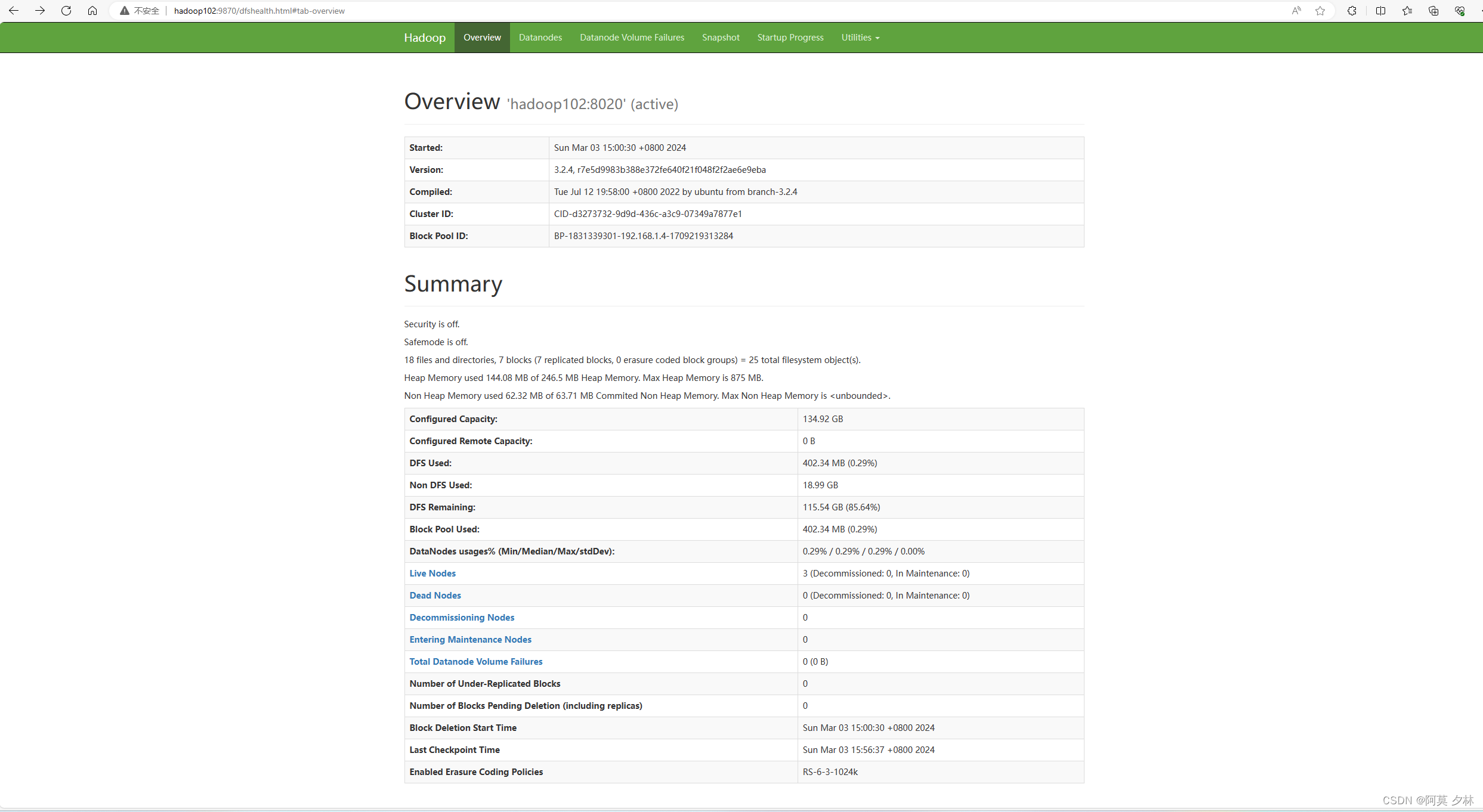
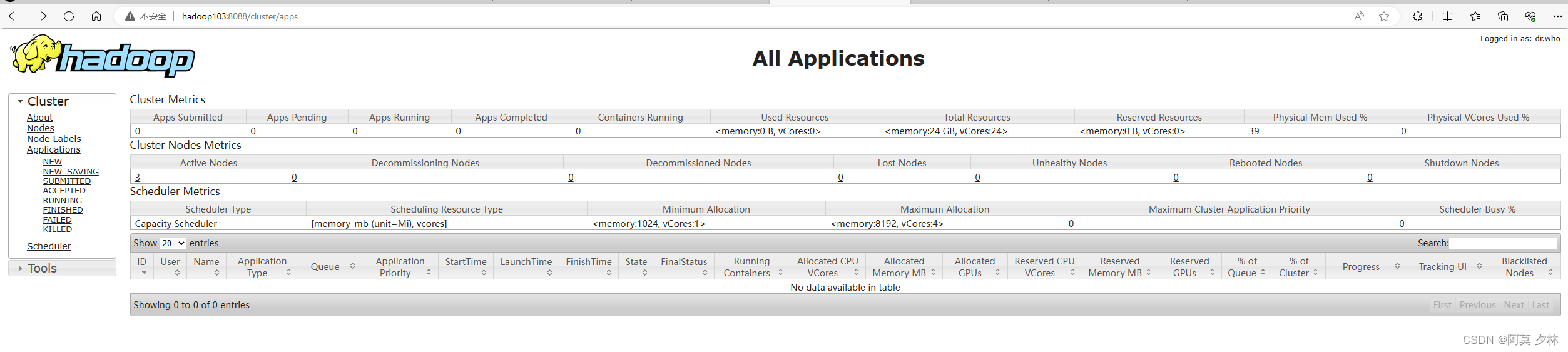
Web查看yarn的ResourceManager
- 浏览器输入:
hadoop103:8088 - 查看yarn上运行的Job信息
3.3.3 集群测试
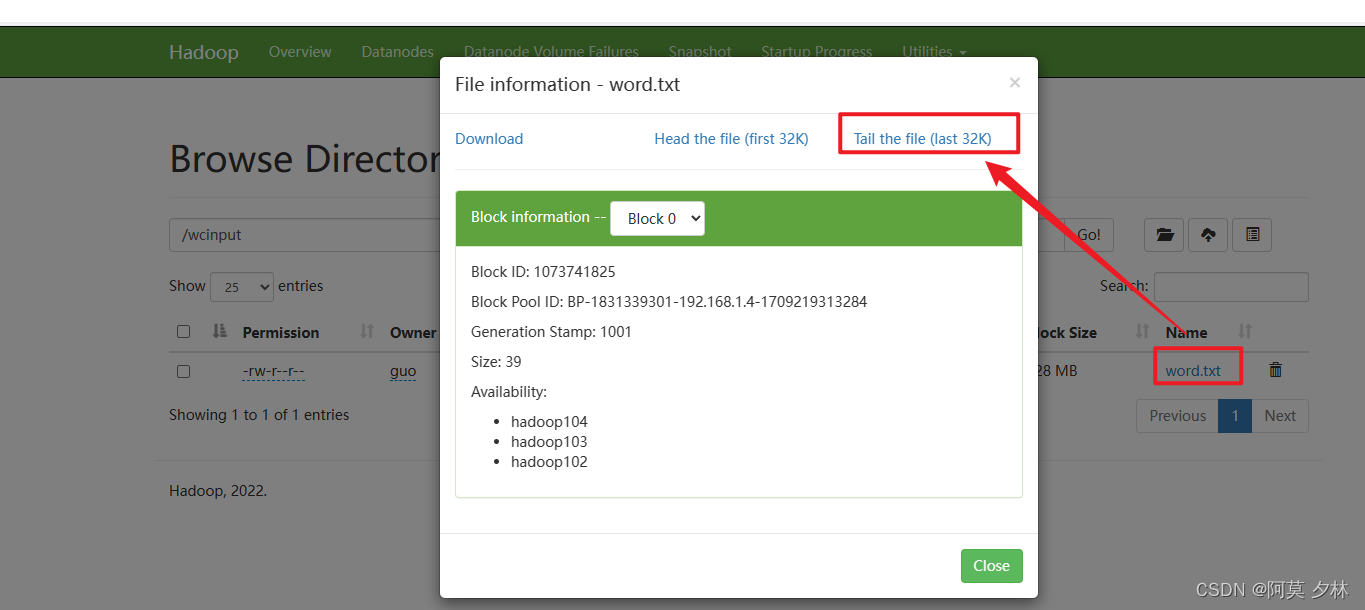
- 上传文件到集群
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -mkdir /wcinput # 创建文件夹
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -put wcinput/word.txt /wcinput # 将word.txt文件上传到集群
上传成功之后,查看hdfs上的存储信息就可以看到文件上传到集群了,如下图所示:

想查看文件的具体内容,点击文件名称,再点 Tail the file (last 32K) 就可查看啦,当然左边的 Download 也是支持下载的。
那么,文件上传到集群了,这里只是做一个展示而已,并不是文件存储的位置,文件具体存储的位置是在hdfs里面
$HADOOP_HOME/data/dfs/data/current/BP-1831339301-192.168.1.4-1709219313284/current/finalized/subdir0/subdir0
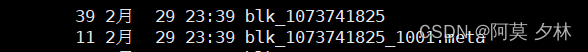
这里的 $HADOOP_HOME 其实就是你hadoop在服务器安装的位置,然后可以通过cat 文件名查看文件内容和上面做一个对比,确认文件上传以及存储的位置是没问题就好了。
=== 到这里完全分布式模式就初步搭好了===
总结
总结起来,Hadoop的三种运行模式:单机模式、伪分布式模式和完全分布式模式,分别适用于不同的场景和需求。单机模式适用于开发和测试,伪分布式模式适用于模拟小规模分布式环境,而完全分布式模式则是处理大规模数据的最佳选择。根据具体的需求,选择合适的运行模式,可以充分发挥Hadoop的强大功能和性能。

![[设计模式Java实现附plantuml源码~行为型]定义算法的框架——模板方法模式](https://img-blog.csdnimg.cn/direct/aa8cd1b033ad46fc89d3d05568ff6386.png)