1、背景
项目中使用easyExcel3.1.1版本实现上传下载功能,相关数据DTO以
@ExcelProperty(value = "dealer_gssn_id")
形式规定其每一列的名称,这样的话easyExcel会完全匹配对应的列名,即用户上传文件时,列名写成Dealer_gssn_id,那么对应的DTO不会给对应字段赋值。
现在客户需要实现此项需求,忽略列名大小写,延伸出来以下内容。
2、调研
最开始以为easyExcel有现成的一些方法或者重写类能实现此项功能,但是后来查看源码,发现没办法重写。具体的debug流程不再此细说,主要看一下DefaultAnalysisEventProcessor类:
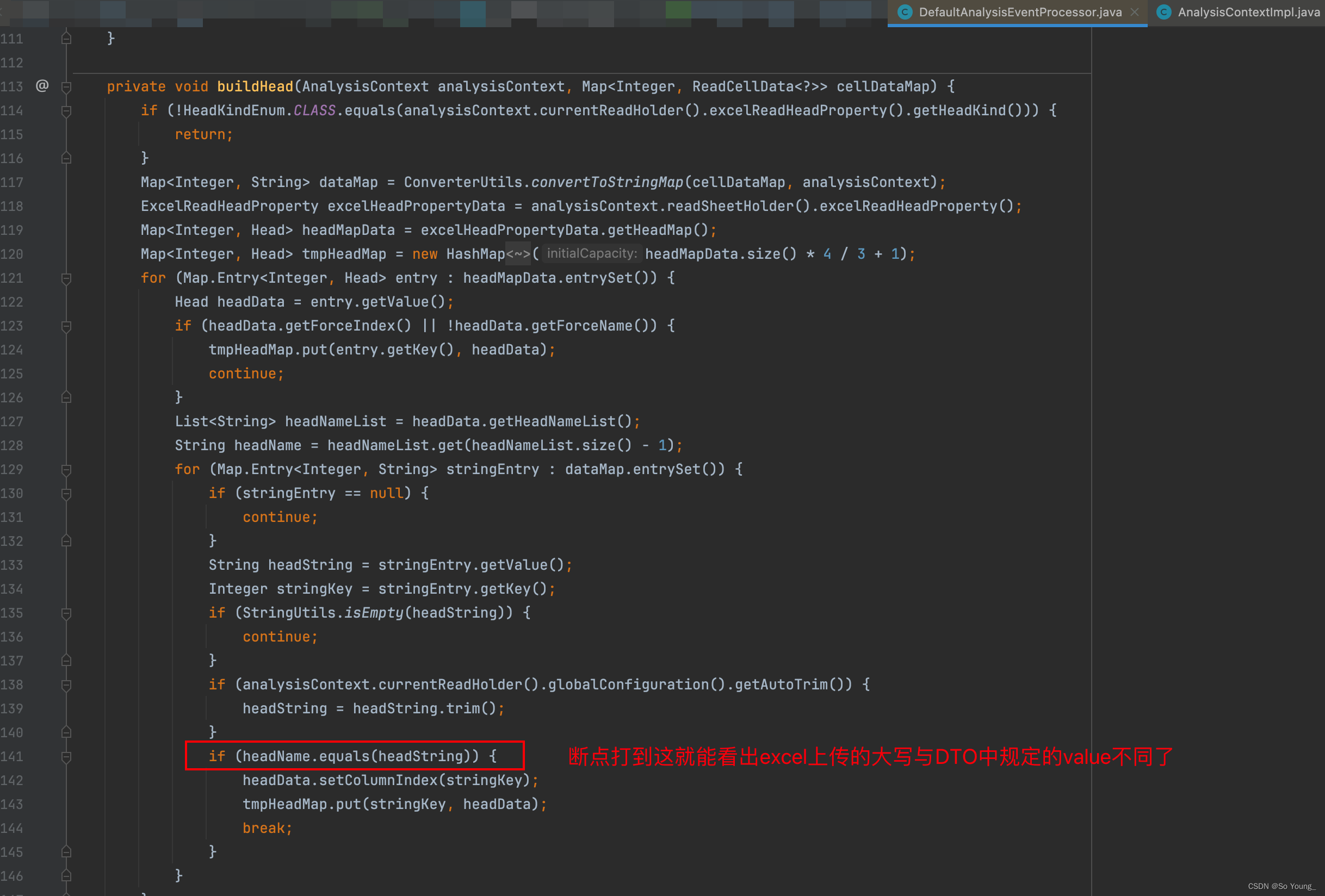
该类中dealData方法,调用buildHead方法,在该方法中141行使用的equals方法用来比较DTO中value名字与excel上传的列名是否匹配,然而这个类的调用方式是new出来的,这就代表即使我们重写了DefaultAnalysisEventProcessor 类,也没办法执行到我们重写的方法,所以这条路走不通了。
除此之外就只能靠我们自己发散思维去想想该怎么做了。
通过打断点看数据,我们其实能在重写AnalysisEventListener的类中看到invokeHeadMap类中是所有的列头数据,invoke方法中既有列头数据,也有具体的值信息,但是怎么和我们定义的DTO做绑定,这也是个麻烦的事情,可以做,但是想想就比较复杂,可能需要写一大堆的if else,代码也不美观,特别是DTO中字段六七十个,而且不止这一个文件要改,这样做起来麻烦且费时。
那就接着想想其他可能性。
比如在我们上传文件时,在处理数据之前写个公共的util呢?这个util功能会把excel列头拿出来都转化为小写,再重新生成一个MultipartFile文件对象呢?这样,每个上传excel功能我们手动调用一下是不是代码侵入量小一些呢?
所以接下来开始硬刚这部分操作,修修补补,起码能实现上述需求:
这个util可以直接使用,但是每个人场景不同可能需要略微修改,这个util只针对sheet 1中简单的区分列头与数据,比较复杂的excel还需要按实际情况修改:
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWriter;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.excel.write.metadata.WriteSheet;
import org.springframework.mock.web.MockMultipartFile;
import org.springframework.util.ObjectUtils;
import org.springframework.web.multipart.MultipartFile;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class FileUtils {
public static MultipartFile convertToLowerCase(MultipartFile file) throws Exception {
// 临时存储读取到的数据
List<List<String>> headerData = new ArrayList<>();
List<List<String>> rowData = new ArrayList<>();
// 读取原始文件内容
try (InputStream inputStream = file.getInputStream()) {
// 使用EasyExcel读取原始文件数据
EasyExcel.read(inputStream, new AnalysisEventListener<>() {
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
// 转换为小写并存储列头
List<String> headers = new ArrayList<>();
headMap.forEach((k, v) -> headers.add(ObjectUtils.isEmpty(v) ? "" : v.toLowerCase()));
headerData.add(headers);
}
@Override
public void invoke(Object data1, AnalysisContext context) {
Map<Integer, String> stringData = (Map<Integer, String>) data1;
List<String> list = new ArrayList<>();
stringData.forEach((key, value) -> list.add(ObjectUtils.isEmpty(value) ? "" : value));
rowData.add(list);
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 所有数据解析完成后调用此方法,这里不做什么
}
}).sheet().doRead();
// 创建一个字节数组输出流来存储Excel内容
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
// 使用EasyExcel创建ExcelWriter
try (ExcelWriter excelWriter = EasyExcel.write(byteArrayOutputStream).build()) {
// 创建写入的sheet页
WriteSheet writeSheet = EasyExcel.writerSheet().build();
// 写入表头
if (!headerData.isEmpty()) {
excelWriter.write(headerData, writeSheet);
}
// 写入数据
if (!rowData.isEmpty()) {
excelWriter.write(rowData, writeSheet);
}
}
// 将字节数组输出流转换为输入流
InputStream newInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
// 使用转换后的输入流创建一个新的MultipartFile
return new MockMultipartFile(
"file",
file.getOriginalFilename(),
file.getContentType(),
newInputStream
);
}
}
}