1、Eureka 简介
Eureka是Spring Cloud Netflix 微服务套件中的一个服务发现组件,本质上是一个基于REST的服务,主要用于AWS云来定位服务以实现中间层服务的负载均衡和故障转移,它的设计理念就是“注册中心”。
你可以认为它是一个存储服务地址信息的大本营,微服务启动时,会把自己的信息告诉Eureka,这个过程叫做注册。
当别的服务想要调用这些服务时,就会去问Eureka需要的服务地址在哪里,这个过程叫做发现。
1.1 Eureka 组件
Eureka由两个组件组成:Eureka Server和Eureka Client。
1.1.1 Eureka Server
Eureka的服务端,提供服务注册和发现的功能。服务实例启动后,会向Eureka Server注册自己的信息,比如主机名、端口号等。然后Eureka Server会保存这些信息,供其他服务查询使用。
@EnableEurekaServer // 启用Eureka Server
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
1.1.2 Eureka Client
Eureka的客户端,它是一个Java客户端,用于简化与服务端的交流,可以很轻松地集成到Spring Cloud应用之中。
@EnableEurekaClient // 启用Eureka Client
@SpringBootApplication
public class EurekaClientApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaClientApplication.class, args);
}
}

2、Eureka 和 Zookeeper 对比
在微服务架构中,服务发现是一个核心的问题。服务发现让服务消费者能够找到网络中运行的服务提供者的实例。
Eureka和Zookeeper都是流行的服务发现解决方案,但它们的设计理念和实现细节有所不同。
2.1 什么是 CAP 定理
CAP定理是分布式计算领域的一个重要概念,由加州大学伯克利分校的Eric Brewer教授提出。它指出,一个分布式系统不可能同时满足以下三点:
- Consistency(一致性):在分布式系统中的所有数据副本,在同一时间内是否具有相同的值。
- Availability(可用性):保证每个请求不管成功或者失败都有响应。
- Partition tolerance(分区容错性):系统中任意信息的丢失或失败不会影响系统的继续运作。
在实际的分布式环境中,网络分区是不可避免的,因此分区容错性是必须要实现的,这就意味着,在CAP的三个特性中,我们只能在一致性和可用性之间进行权衡。
2.2 基于 CAP 定理比对 Eureka 和 Zookeeper
根据CAP定理,我们来看看Eureka和Zookeeper是如何做权衡的。
-
Zookeeper
Zookeeper是一个中心化的服务协调系统,广泛用于名称服务、配置管理、节点同步等。它保证了强一致性(Consistency)和分区容错性(Partition tolerance),但不保证可用性(Availability)。这意味着如果Zookeeper集群中的过半节点不可用,整个Zookeeper服务就不可用了。这样做可以保证所有读取操作返回的都是最新的数据。在Zookeeper中,领导选举算法保证了服务的一致性。举个例子,如果在Zookeeper集群中出现网络分区,那么集群将会分裂成多个部分,每一部分都会尝试进行新的领导选举。只有当某一部分节点数量超过半数时,它才能选出新的领导,并继续对外提供服务。
-
Eureka
与此相反,Eureka则是设计成高可用性(Availability)优先。Eureka可以很好地处理网络分区问题,它的设计哲学是即便在服务之间出现严重的网络故障,每个服务实例仍然能够被客户端发现并使用。Eureka的自我保护模式使得在网络分区问题发生时,不会立即注销服务列表中的节点,而是等待一段时间,直到网络稳定。这样做虽然能增加可用性,但却可能因为没有及时剔除失效的服务实例而返回过时的信息。一个具体的例子是,如果Eureka Server与Eureka Client通信出现问题(如网络延迟),Server不会立即从注册表中移除这个Client,而是等待Client恢复并发送心跳。这样做的好处是,即使有少量的服务器或客户端无法进行通信,整个系统仍然是可用的。
出Zookeeper保证的是CP,而Eureka则是AP。在选择使用Zookeeper还是Eureka时,需要根据实际业务需求和架构特点做出决策。如果你的服务对一致性要求极高,而且可以接受因网络分区导致的服务不可用,那么Zookeeper可能是更好的选择。如果你需要的是高可用的服务发现机制,并且可以容忍服务状态的短暂不一致,那么Eureka是更合适的选项。
3、搭建 Eureka 注册中心
Eureka Server作为服务发现的关键组件,负责存储服务信息和处理服务注册与发现。下面我们将详细介绍如何从零开始搭建Eureka Server。
3.1 POM 文件
首先需要创建一个Spring Boot工程并在pom.xml文件中添加Eureka Server的依赖。你可以使用Spring Initializr来快速生成项目结构。
<dependencies>
<!-- Eureka Server -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<!-- Spring Boot Starter Web,用于搭建基于Web的应用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 测试依赖,可以根据需要选择添加 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
此外,你还需要在pom.xml中指定Spring Cloud的版本,通过spring-cloud-dependencies来保证各个组件版本的兼容性:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<properties>
<spring-cloud.version>Greenwich.SR1</spring-cloud.version>
</properties>
这里${spring-cloud.version}要替换为当前稳定的Spring Cloud版本号。
3.2 配置文件 application.yml
在src/main/resources/目录下创建或编辑application.yml配置文件,添加Eureka Server的基础配置:
server:
port: 8761 # Eureka服务端口
eureka:
client:
registerWithEureka: false # 表示不向注册中心注册自己
fetchRegistry: false # 表示自己就是注册中心,我的职责就是维护服务实例,不需要去检索服务
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ # 设置与Eureka Server交互的地址
instance:
hostname: localhost # 可以是其他的域名或者IP
3.3 启动类
在你的Spring Boot应用中创建一个主类,使用@EnableEurekaServer注解来启动一个服务注册中心。
package com.example.eurekaserver;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer // 启用Eureka Server功能
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
这段代码会启用一个Eureka Server实例,允许其他服务向它注册。
3.4 访问 Eureka Server WEB 服务管理平台
一旦启动了Eureka Server,你可以在浏览器中输入http://localhost:8761来访问Eureka的管理界面。在这个界面,你能看到所有注册的服务实例,以及它们的状态信息。
Eureka的Web界面提供了实时的服务注册监控,你可以看到哪些服务已经注册进来,以及它们的健康状态。
以上步骤是搭建一个单节点的Eureka Server的基本过程。
在生产环境中,为了确保高可用性,通常会搭建Eureka Server集群,我们会在后续的小节中讨论如何搭建和配置Eureka Server集群。
接下来我们将深入了解Eureka Server的服务管理平台,以及如何通过它来监控服务实例的状态。
4、Eureka 服务管理平台介绍
Eureka服务管理平台是Eureka Server自带的一个Web界面,它提供了实时的服务注册情况和服务健康状况的监控。
4.1 Eureka Server 服务管理平台访问预览
一旦Eureka Server启动,你可以通过在浏览器地址栏输入http://localhost:8761(这里的地址和端口根据你实际的配置决定)来访问Eureka服务管理平台。这个界面简洁直观,提供了关于当前Eureka实例所有必要信息的概览。
由于我这里不能直接上传图片,你可以通过项目运行后自行查看界面,或者在网络上搜索Eureka Server界面的相关截图,这将有助于你获得一个直观的感受。
4.2 System Status
在管理平台的主页上,你可以看到"System Status"区域,这通常位于页面的顶部。这里会显示Eureka自身的状态,包括:
- Current time:服务器的当前时间。
- Uptime:服务器运行时间。
- Environment:服务器环境信息,如配置的profile。
- Number of CPUs:服务器的CPU数量。
- Total memory:服务器的总内存。
- General runtime info:包括JVM版本等运行时信息。
4.3 DS Replicas
如果你配置了Eureka Server集群,"DS Replicas"部分将会显示所有的Eureka Server节点。这些副本节点之间会相互注册,保证服务注册信息在整个Eureka集群中是一致的。在这个区域,你可以看到其它Eureka Server节点的状态,这对于确保高可用性是非常关键的。
4.4 Instances currently registered with Eureka
这个区域显示了所有已注册到Eureka的服务实例,以及它们的状态。每个服务下面会列出所有的注册实例,包括它们的应用名、IP地址、端口号、运行状态等信息。点击具体的实例,你还可以看到更多的细节,例如服务的metadata、租约信息等。
4.5 General Info
在"General Info"部分,你可以找到Eureka Server自身的一些信息,包括:
- Eureka version:显示Eureka Server的版本号。
- Started at:Eureka Server启动的时间。
4.6 Instance Info
"Eureka Server Dashboard"还有"Instance Info"部分,这里提供了每个注册服务实例的详细信息。这些信息有助于管理员了解服务实例的健康状况,以及进行问题排查。
Eureka服务管理平台提供了丰富的信息和操作界面,管理员可以利用这些信息来监控服务的健康状态,确保系统的稳定运行。
在实际的生产环境中,还可以结合额外的监控工具,比如Spring Boot Admin等,来更全面地监控系统状态。
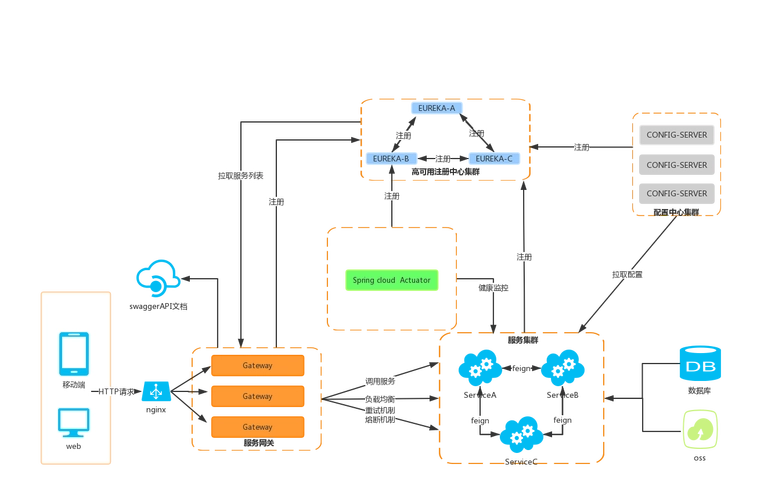
5、搭建高可用集群
在实际生产环境中,为了保证Eureka服务的稳定性和可用性,通常会部署Eureka Server集群。这样即使某个Eureka Server节点故障,其他节点仍能提供服务注册和发现的功能,从而实现高可用。
5.1 在 Eureka 应用中定义多环境配置
为了构建Eureka集群,需要为每个Eureka Server节点指定一个独立的配置文件。
5.1.1 application-eureka1.yml
定义第一个Eureka Server实例的配置文件。例如:
server:
port: 8761
eureka:
instance:
hostname: eureka1.feiz.com
client:
service-url:
defaultZone: http://eureka2.feiz.com:8762/eureka/
fetch-registry: true
register-with-eureka: true
5.1.2 application-eureka2.yml
定义第二个Eureka Server实例的配置文件。例如:
server:
port: 8762
eureka:
instance:
hostname: eureka2.feiz.com
client:
service-url:
defaultZone: http://eureka1.feiz.com:8761/eureka/
fetch-registry: true
register-with-eureka: true
这两个配置文件中的defaultZone属性指向了对方的服务注册中心,从而形成一个互相注册的关系。
5.2 打包工程
我们需要将Eureka Server项目打包成jar包,以便可以在服务器上运行。
5.2.1 POM 依赖
在pom.xml文件中,Spring Boot已经帮我们定义好了打包的插件,所以一般不需要额外定义。
5.2.2 打包
在项目根目录下,运行Maven命令进行打包:
mvn clean package
5.2.3 打包结果
打包完成后,在target目录下会生成对应的jar文件,例如eureka-server-0.0.1-SNAPSHOT.jar。
5.3 上传打包后的 jar 文件到 Linux 系统
使用FTP或SCP等工具,将打包好的jar文件上传到两台Linux服务器上。
5.4 设置 Linux 主机域名
在/etc/hosts文件中,为两台Linux服务器设置域名解析,方便通过域名访问:
# Example /etc/hosts entries
192.168.1.10 eureka1.feiz.com
192.168.1.11 eureka2.feiz.com
5.5 启动 Eureka
有了jar文件和配置文件,我们就可以在服务器上启动Eureka Server的实例了。
5.5.1 使用 java 命令启动
在Linux服务器上,通过指定配置文件的方式启动Eureka Server实例:
java -jar eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=eureka1
java -jar eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=eureka2
这里的--spring.profiles.active参数用来指定活动的配置文件。
5.5.2 脚本启动
为了方便管理,我们可以编写启动脚本来控制Eureka Server的启动、关闭等操作。例如创建一个start-eureka-server.sh的脚本,内容如下:
#!/bin/bash
nohup java -jar eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=$1 > eureka-server.log 2>&1 &
然后就可以用这个脚本来启动Eureka Server:
./start-eureka-server.sh eureka1
./start-eureka-server.sh eureka2
搭建Eureka高可用集群的步骤就是这样的,有了Eureka集群,即使某个节点宕机,其他节点还能继续提供服务,从而确保了整个微服务架构的高可用性。
接下来,我们可以通过在客户端配置这些Eureka Server地址,将客户端注册到集群,这样客户端就能享受到高可用服务发现的好处了。
推荐几个 Spring Cloud 学习的文章
- 01、Feign的核心概念及入门案例
- 02、Feign原生注解
- 03、Spring Cloud 2020.x 集成Open Feign
- 04、集成OkHttp及连接池配置详解
- 05、集成Ribbion实现客户端负载均衡
- 06、Ribbion配置类源码分析
- 07、Ribbion负载均衡策略源码分析
- 08、Feign超时配置详解及源码分析
- 09、Fegin 开启日志打印、Gzip压缩
- 10、Feign 、Ribbon 重试机制源码分析
- …
6、集群原理
6.1 服务注册
当一个微服务实例启动时,它会向Eureka Server注册自己的信息,比如IP地址、端口号、健康指标等。这些信息会存储在Eureka Server的内存中。
6.2 服务同步
在集群环境下,每个Eureka Server节点都会存有一份服务实例的注册信息。为了保持这些信息的一致性,Eureka Server节点之间会相互复制(replicate)这些信息:
- 当一个服务实例在Eureka Server A上注册时,Server A会将这个信息同步给其他的Eureka Server节点(比如Server B)。
- 这个同步过程是通过复制一个注册操作的请求到集群中的其它节点来完成的。
- 通过这样的方式,每个节点都有机会获取最新的注册信息,保证了服务注册的一致性。
6.3 心跳检测
服务实例会定期向Eureka Server发送“心跳”(即续约),默认情况下每30秒一次,以告知Eureka Server它还活着。
- 如果Eureka Server在一定时间内没有接收到某个服务实例的心跳,它会在其注册表中将这个实例剔除。
- 但在自我保护模式下,为了应对因网络问题导致的心跳失败,Eureka Server不会立即剔除实例,会有一个宽限期。
6.4 自我保护模式
Eureka Server能够进入自我保护模式。在这种模式下,Eureka Server会保护注册表中的信息,不会删除未发送心跳的服务实例:
- 这种做法可以在网络分区故障发生时阻止Eureka Server错误地剔除大量服务实例。
- 当网络稳定时,Eureka Server会自动退出自我保护模式。
6.5 故障转移
当一个Eureka Server节点宕机后,由于服务注册信息已经同步到了其他节点,微服务实例可以自动将注册请求转移到其他健康的Eureka Server节点上:
- 这实现了故障转移和服务的高可用。
- 客户端通常会有一个Eureka Server的地址列表,当尝试与一个节点通信失败时,它会尝试联系列表中的下一个节点。
当然可以。针对第四点(6.6 读写操作的分离)的内容,我们可以展开解释,使其更加详尽和容易理解:
6.6 读写操作的分离
在Eureka Server集群中,读写分离的概念对于维护整个系统的高性能和高可用性至关重要。这里的“读”主要指客户端从Eureka获取注册服务列表的操作,而“写”则指服务实例注册和续约的操作。
-
写操作:对于注册和续约这样的写操作,它们必须在集群中的每个节点上进行复制。当一个服务实例向Eureka Server注册时,这个注册信息会被同步到集群中的所有其他节点。这种复制确保了即使某个节点发生故障,服务实例的注册信息仍然可以在其他节点上被访问到,从而保持系统的一致性。
-
读操作:相比之下,读操作则可以从任何一个Eureka Server节点获取,无需跨节点复制。这意味着任何时候当客户端需要获取服务列表时,它都可以快速地从任一可用的节点获得数据,而不需要等待跨节点之间的信息同步。这减少了单个节点的负担,并显著提高了系统的响应速度。
重要性:
- 性能提升:读写分离可以显著减少因写操作复制而产生的网络负载,因此提升了整个集群的性能。
- 减少瓶颈:通过允许读操作在任一节点上执行,它避免了所有请求都集中在单个节点上,这样可以有效分散流量,减少了单点瓶颈的风险。
- 弹性扩展:读写分离使得Eureka Server集群能够更加弹性地扩展。根据读写负载的变化,可以灵活地增加或减少节点数量,以实现最优的资源利用。
注意事项:
- 数据一致性:虽然读操作可以从任一节点获得,但Eureka Server会通过复制机制确保每个节点的数据最终一致。
- 故障转移策略:集群中的节点必须要有故障转移机制,确保当一个节点不可用时,其它节点能够接管它的职责,保持服务的连续性。
通过上面这些机制,Eureka集群确保了即使在某个Eureka Server节点出现故障的情况下,整个服务发现框架也能够继续正常工作,不会影响到微服务的正常运行。
这就是为什么即使在分布式系统中常常出现的网络分区、通信故障、服务故障等问题发生时,Eureka仍然能够提供稳定的服务发现功能。
7、Eureka 优雅停服
在微服务架构中,服务的可用性至关重要。但有时候也需要对服务进行升级或者维护,这时候如果能够优雅地停止服务,就可以避免对用户造成过多的影响,同时也能保护服务不受损害。
7.1 自我保护模式
Eureka Server的自我保护模式是为了应对网络不稳定的情况。在网络状况不佳时,Eureka Client可能无法及时地向Server发送心跳。如果Eureka Server在这种情况下仍按常规流程剔除没有发送心跳的Client,那么可能会导致大量服务实例被错误移除,造成“脑裂”问题。
所以在自我保护模式下,Eureka Server宁可保留所有服务实例,也不去主动剔除任何一个,即使它们已经很长时间没有发送心跳了。
7.2 为什么要自我保护
这个模式能保证在网络不稳定导致Eureka Client和Server之间的通信出现问题时,服务注册信息不会被轻易丢掉。这样就可以防止因为临时的网络问题而导致整个微服务架构不稳定。自我保护模式保证了在不可靠的网络环境下,服务注册表的稳定性和可靠性。
7.3 关闭自我保护
有些情况下,我们可能希望关闭自我保护模式,特别是在测试环境中,以确保当一个服务实例真的宕机时,它能够被及时从注册表中移除。
要关闭自我保护模式,可以在Eureka Server的配置文件中设置:
eureka:
server:
enable-self-preservation: false
关闭自我保护模式后,如果Eureka Client在配置的时间内没有向Server发送心跳,那么这个实例将会被Server从注册列表中剔除。这确实会提高注册表的准确性,但同时也增加了在网络不稳定时误剔除服务实例的风险。
优雅停服是微服务管理中的一个重要环节,它能确保服务的升级和维护对用户的影响降到最低。
在实际应用自我保护模式时,我们需要根据具体的业务需求和网络环境来权衡是否开启此模式。
通常在生产环境下建议开启自我保护模式,以提高微服务架构的稳定性和健壮性。而在开发和测试环境中,可以考虑关闭它,以便更快地发现并处理服务实例的故障。
我们继续深入讲讲如何进行Eureka的优雅停服以及在整个过程中可能遇到的一些注意事项。
7.4 优雅停服的流程
优雅停服意味着服务在停止之前会完成当前处理的请求,并且不再接受新的请求。具体到Eureka Client,需要做到以下几点:
7.4.1 停止流量转发
在停服之前,首先要确保不再有新的流量进入该服务实例。这可以通过在负载均衡器中摘除实例来实现。
7.4.2 服务下线
然后,服务实例需要主动向Eureka Server发送下线请求,告知注册中心自己将停止服务。
7.4.3 等待处理请求完成
在服务实际停止之前,需要等待服务实例完成当前正在处理的所有请求。
7.4.4 停止服务实例
最后,当所有请求都处理完成后,可以安全地停止服务实例。
在Spring Cloud中,可以通过Spring Boot的Actuator来实现优雅停服。Actuator暴露了一个/actuator/shutdown端点,可以通过调用这个端点来优雅地关闭服务。为了能够使用这个特性,需要在application.yml或application.properties文件中添加以下配置:
management:
endpoints:
web:
exposure:
include: shutdown
endpoint:
shutdown:
enabled: true
在应用程序准备停止时,可以发出一个HTTP POST请求到/actuator/shutdown端点。这将触发上述流程,优雅地关闭服务实例。
7.5 处理停服时遇到的问题
在进行优雅停服时,可能会遇到一些问题,例如:
- 服务调用链中断:如果服务实例在处理请求时依赖于其他服务,需要确保这些依赖服务在停服过程中仍然可用。
- 超时设置:停服过程中需要合理设置超时时间,以确保服务实例有足够的时间完成正在处理的请求。
- 数据一致性:如果服务实例在处理事务请求,需要确保事务能够正确提交或回滚,避免数据不一致。
在实际操作中,通常需要先在测试环境中模拟停服流程,确保各个环节都能够正确执行,然后再在生产环境中实施。这样做可以最大限度地减少停服给用户带来的影响,并确保服务的稳定性和数据的一致性。
在微服务架构中,优雅停服是一项重要的技能。正确地执行优雅停服不仅能够保护正在运行的业务流程,也是保障服务质量和用户体验的关键。 实践中需要结合具体的业务特点和技术环境来制定详细的停服策略,以确保服务平稳过渡到新的状态。
7.6 服务恢复策略
搞定优雅停机之后,咱们看看停机后的服务恢复策略,以及在服务停机期间如何保持业务连续性,这个是挺重要的,毕竟服务总得起来,业务也不能停。
当服务需要重新上线时,有以下几个步骤可以确保服务的平稳恢复:
7.6.1 服务实例重启
将服务实例重新启动,并确保所有的配置项都是最新的。
7.6.2 注册到Eureka
启动时,服务实例会自动注册到Eureka Server。确保服务实例的健康检查是通过的,服务实例能够正常提供服务。
7.6.3 服务同步
Eureka Client会定期从Server拉取服务注册列表,确保本地的信息是最新的。
7.6.4 流量逐步切换
在确保服务实例稳定运行后,可以通过负载均衡器逐步将流量切换到新的服务实例上,避免流量突增对新实例造成冲击。
7.7 业务连续性策略
在服务停机期间,为了保持业务的连续性,可以采取以下措施:
7.7.1 服务降级
在服务无法正常提供时,可以启用服务降级策略,比如返回一个默认值或者从缓存中获取数据。
7.7.2 流量切换
如果是计划内的停机,可以提前将流量切换到其他地理位置的服务实例,或者是切换到备份服务上。
7.7.3 用户通知
对于长时间的停机,合理的用户通知也是很必要的。提前通知用户,减少用户的困扰。
7.7.4 监控和报警
确保有监控系统持续监控服务的状态,一旦服务恢复或出现异常,及时报告。
推荐几个 Spring Cloud 学习的文章
- 01、Feign的核心概念及入门案例
- 02、Feign原生注解
- 03、Spring Cloud 2020.x 集成Open Feign
- 04、集成OkHttp及连接池配置详解
- 05、集成Ribbion实现客户端负载均衡
- 06、Ribbion配置类源码分析
- 07、Ribbion负载均衡策略源码分析
- 08、Feign超时配置详解及源码分析
- 09、Fegin 开启日志打印、Gzip压缩
- 10、Feign 、Ribbon 重试机制源码分析
- …
搞定了这些,就算服务需要停机升级或者维护,对用户的影响也能降到最低。重点是,不管停不停机,服务质量和用户体验始终是咱们要维护的。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记和面经,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的阿里大佬写的刷题笔记,让我offer拿到手软
本文已收录于,我的技术网站 小郑说编程,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!@小郑说编程