转载请注明出处。作者:archimekai
核心参考文献: Dremel: Interactive Analysis of Web-Scale Datasets
文章目录
- 引言
- 复杂嵌套数据结构的无损表征问题
- Dremel论文中提出的表征方法
- parquet
- 备注
引言
Dremel是Google的交互式分析系统。Google大量采用protobuf格式,因此Dremel必须支持protobuf这种复杂嵌套格式的分析。众多工作已经论证了列式存储格式对分析系统(AP, analytical processing)的重要性,因此Dremel需要把复杂嵌套格式存储为列存。本文接下来重点分析Dremel是如何把复杂嵌套格式转换为每一列单独存储的。
我们的目标是:没有蛀牙(划掉)把相同字段的所有值连续存储。因此需要设计一种能够适用于任意protobuf/json格式的,无损的数据表征方式。
复杂嵌套数据结构的无损表征问题
不同的数据,其表征难度是不同的。最简单的是完全没有嵌套,平铺直叙的数据。这种数据只要将每一个字段的名称取出,放在数据库中作为一列即可。
数据样例如下:
{"Code": "en-us", "Country": "us"}
一种表征方式如下:
| Code | Country |
|---|---|
| en-us | us |
如果数据中有嵌套,但是没有列表,也比较简单。只需要用某个分隔符(例如 . )把嵌套的字段名称连接起来即可。以下面的数据为例:
{"DocId": 10, "Links": {"Forward": 20}}
其一种表征方式如下:
| DocId | Links.Forward |
|---|---|
| 10 | 20 |
如果数据中存在列表,就比较复杂了。这里的难点在于,列表的长度无法提前预知,所以一般不能把列表中的每一个元素都作为一列存储。例如
{"Links": {"Backward": [10,30], "Forward": [80]}}
不能表征为
| Links.Backward[0] | Links.Backward[1] | Links.Forward[0] |
|---|---|---|
| 10 | 30 | 80 |
如果将来Backward中有10000个元素就很难处理。
这个问题其实有一个简单场景,即列表中的元素都是相同的基本数据类型。这里的基本数据类型可以简单理解为数据库有原生数组类型支持的数据类型,例如 int ( int[] ),float ( float[] )等,因此,上述数据可以表征为下表。Hologres就是采用了这样的方案。
| Links.Backward | Links.Forward |
|---|---|
| [10.30] | [80] |
通过上面的方案,笔者认为已经可以搞定80%以上的场景了。但是如果列表中的元素不是基本数据类型,上面的的方案就又搞不定了。考虑下面的数据:
{"Name": [{"url": "http://C", "long_data": "data"}]}
在这个例子中,数组里面的元素是{"url": "http://C"},并不是一种基本数据类型,如何存储才能支撑对Name.url的高效查询呢?。除了上面的例子,还有更为复杂的数组套数组的例子:
{"Name": [{"Language":[{"Code": "en-us", "Country": "us"}, {"Code": "en"}]}]}
那么,有没有一种方法可以一劳永逸地搞定所有protobuf/强类型json(强类型json指每个字段的类型是确定的)能够表达的所有数据呢?还真有,这就是Google的天才工程师们在Dremel论文中提出的方案。下面笔者重点介绍这个方案。
Dremel论文中提出的表征方法
还是看上面数组套数组的例子,主要的困难点是,读取数据时如何确定内层元素(例如{"Code": "en"})的位置?这需要准确表达内层元素在当前数组(也即Language)和父数组(也即Name)中的位置,才能在读取时把数据结构还原回来。这提示我们,至少需要增加两个位置信息才行。
Google的工程师们也是这么想的,他们定义了两个变量来表示上述信息,这两个变量也是理解Dremel数据表征算法的关键:
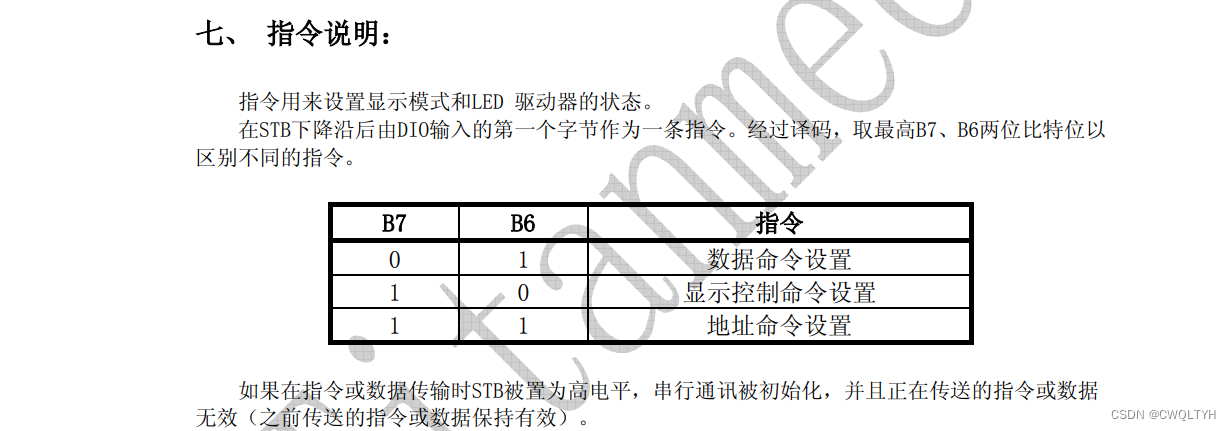
- 第一个变量是repetition level,简称r,其表示对于给定的字段,其当前在哪一个级别重复。这个概念比较抽象,请结合下面的例子仔细阅读备注进行理解。
- 第二个变量是definition level,简称d,其表示对于给定的字段,其前面有多少个字段是存在的。例如,r3中的DocId,d=0,也即DocId更上层没有字段了,r3中的Links.Forward字段,d=1,也即Links这个字段是存在的。
可以看到,r和d并非直接表示当前数组和父数组的位置,而是以一种类似增量(在当前级别重复还是在哪个级别重复)的方式进行编码。
一个加料版的例子(r3,基于论文中的r1修改而来)。数据schema如下
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward; }
repeated group Name {
repeated group Language {
required string Code;
optional string Country; }
optional string Url; }}
数据如下(简称r3)
{
"DocId": 10,
"Links": {"Forward": [20,40,60]},
"Name": [
{
"Language": [
{"Code": "en-us", "Country": "us"},
{"Code": "en"},
{"Code": "zh-cn", "Country": "cn"}]
"Url": "http://A"
},
{"Url": "http://B"},
{"Language": [{"Code": "en-us", "Country": "gb"}]}
]
}
数据r3中的Name.Language.Country字段编码后如下。
| value | r | d | 备注 |
|---|---|---|---|
| us | 0 | 2 | r=0表示r3这篇文档的第一个Country字段,d=2表示Name, Language两个字段都是存在的 |
| null | 2 | 2 | r=2表示Language字段在第二级,也即Language数组这一级重复,null表示Country字段实际上未在Language这个数组的第二个元素{"Code": "en"}中出现。注意null在dremel的编码方式中是必须的 |
| cn | 2 | 2 | r=2表示Language字段在第二级,也即Language数组这一级重复,出现在Language这个数组的第三个元素 |
| null | 1 | 1 | r=1表示Language字段在第一级,也即Name数组这一级重复,null表示Country字段实际上为在Name这个数组的第二个元素{"Url": "http://B"}中出现。结合d=1可知,Name.Language.Country中只有头一个字段,也即Name存在,Language字段不存在。 |
| gb | 1 | 2 | r=1表示Language字段在第一级,也即Name数组这一级重复,出现在Name数组的第三个元素 |
到了这里,相信读者已基本理解了r和d的含义。笔者将Dremel论文中的原图贴在这里,大家应该可以看懂了。

parquet
parquet中对于嵌套数据的数据和Google Dremel基本一致。本篇文章不详细展开
备注
- 为了方便理解,上述描述中省略了一些不重要的细节,感兴趣的读者可自行阅读论文原文。
- 本篇文章只介绍了最核心的数据结构表征方式,Dremel论文中还有关于如何将各个字段拆分为列,如何使用有限状态自动机真正生成r和d值的描述,以后有机会再介绍。