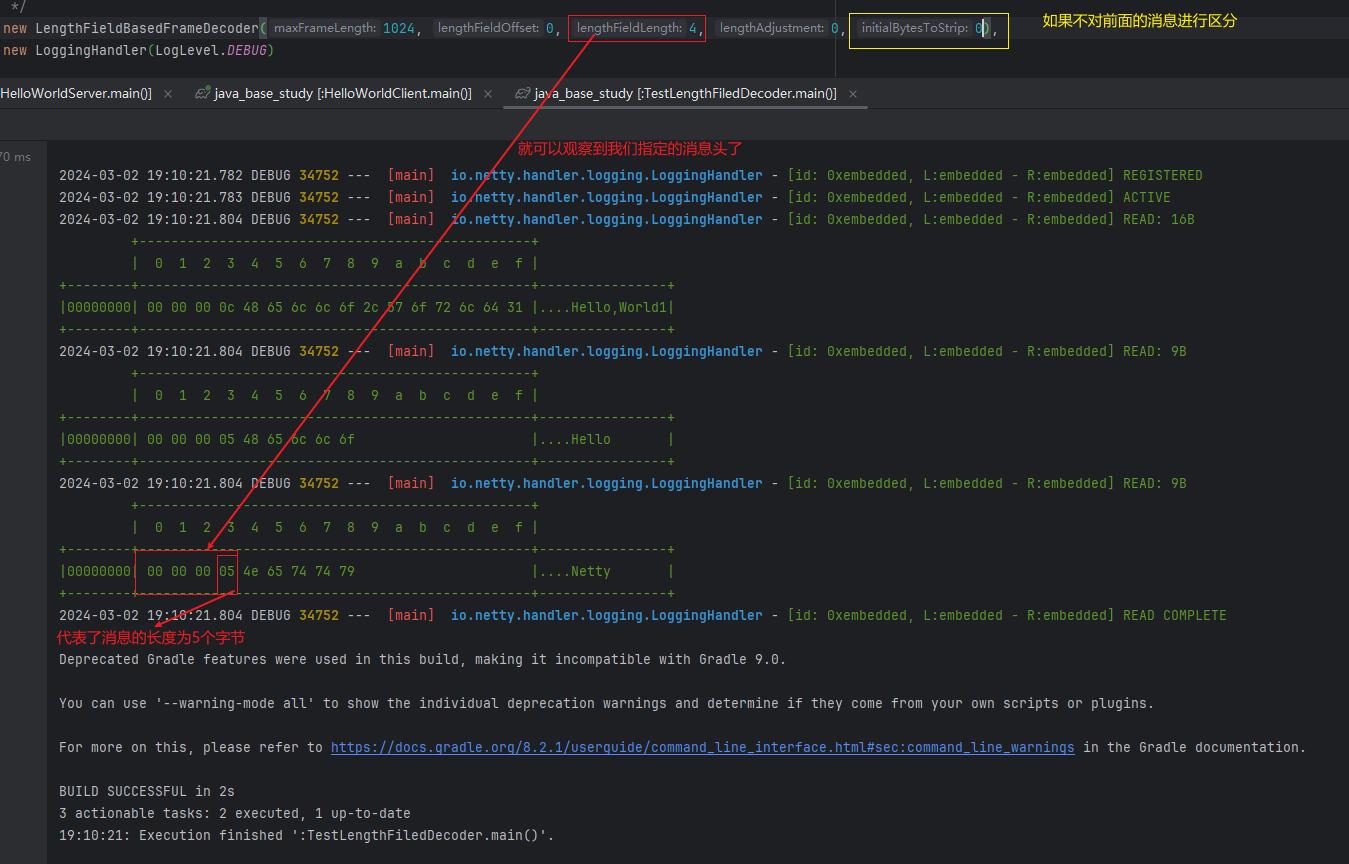
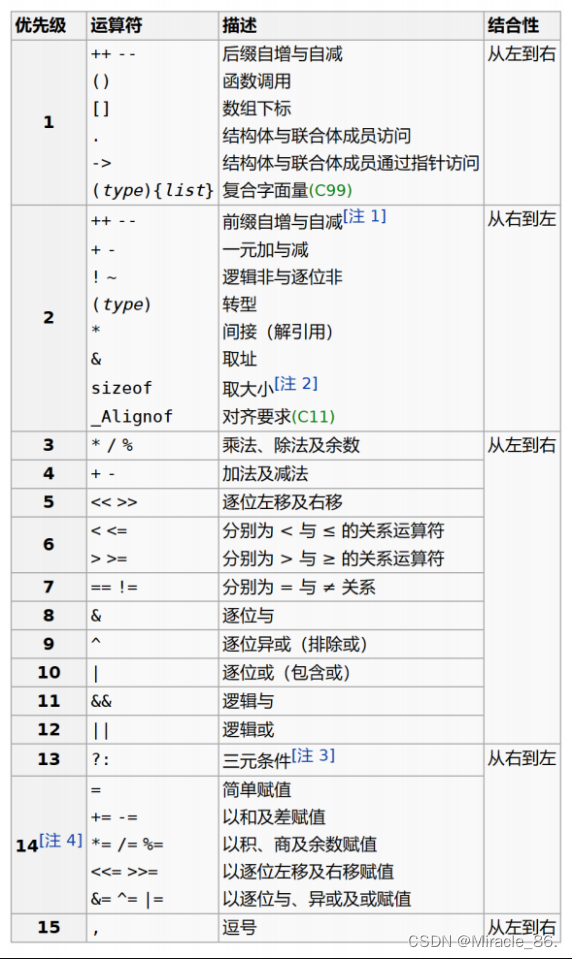
什么是深度学习
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个研究方向。
深度学习通过对样本数据的内在规律和特征的提取与抽象,在不同维度和层次上进行处理,让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。
相比于初期的机器学习,深度学习是更加复杂的算法,但是同时因为深度学习算法的普适性,以及在语音和图像识别方面取得的惊人效果,他的发展速度远远超过先前相关技术。
入门深度学习时的困惑
很多同学刚入门的时候,会对代码中的网络主体在哪里,是怎么训练的,以及训练完如何保存,保存后如何使用等问题产生疑惑。这些问题会随着阅览的代码增多而自然化解。我们先从简单的开始:如何跑起来一个神经网络。
典型的入门案例——CNN实现的MNIST手写数字识别
废话不多说,直接通过MNIST手写识别快速入门深度学习。对于手写识别任务,目前已经能够被很轻松的解决。
虚拟环境的创建
创建虚拟环境
为了不使python环境变的混乱,我们使用conda工具创建虚拟python环境,每个虚拟环境之间是隔离的。具体的conda环境安装网上已经有很多教程,很多博主都写的很详细,这里就不展开了。我们直接使用conda工具创建一个新的python环境
conda create -n mnist_pytorch python=3.8
这句创建一个名字为mnist_pytorch,python版本为3.8的虚拟环境,使用如下命令激活环境
conda activate mnist_pytorch
配置需求的依赖包
conda install pytorch==2.0
conda install torchvision==0.15.1
除了会安装pytorch意外,还会自动配置相关的依赖包,比如numpy等。其他的库也会进行安装,如果没有找到对应的库,可以参考后面的安装命令重新来一次。
还需继续安装PIL的库:pillow,没错,import的名字和他的库名并不相同。
pip install pillow
安装画图的库
pip install matplotlib,python库os在安装python环境的时候,就会根据操作系统进行自动配置。
代码
1. 引入依赖包
首先我们需要如下的python包import
import numpy as np
import torch
from torch import nn
from PIL import Image
import matplotlib.pyplot as plt
import os
from torchvision import datasets, transforms,utils
其中:
- numpy是python著名以及普遍使用的第三方库,用于进行科学计算
- PIL全名为Python Image Library,用于图像的处理
- matplotlib是python中普遍使用的绘图库,而pyplot是其一种快捷的绘图接口
- os为python提供了丰富的方法来处理文件和目录
- torchvision通过这个库,我们能够实现很多经典数据集的下载,包括COCO,ImageNet,CIFCAR等,当然也包括我们的这个MNIST。
2. 准备数据集datasets
MNIST数据集是一张张黑底白字的手写体图片,大小均为28 × \times × 28。如下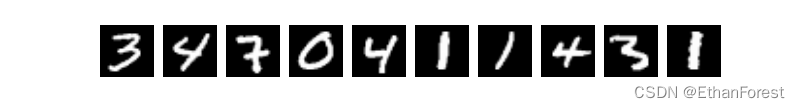
按照下面的代码取出的每一个数据都是:{ 图片, 数字 } 的组合。
运行以下的代码
# 1
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])])
# 2
train_data = datasets.MNIST(root = "./data/",
transform=transform,
train = True,
download = True)
# 3
test_data = datasets.MNIST(root="./data/",
transform = transform,
train = False)
我们使用torchvision库中提供的方法,把MNIST数据下载到本地并分为测试集和训练集。每一句的作用解释如下:
- 第一句指定了数据集预处理的方案,在上述代码中,制定了将数据转变为tensor()格式,可以理解这是pytorch中的矩阵;并且将数值归一化,指定均值和标准差均为0.5。数据的标准化或者说是归一化是神经网络数据预处理中经常采用的方式,能够剔除数据中的极端情况,并且有利于模型训练过程的收敛。
- 第二、三句通过引入torchvision中的datasets方法,指定MNIST数据集的位置,这里指定为和当前程序文件同一文件夹下的data文件夹,指定预处理方法为第一句设定的transform,然后训练集将train设定为true,测试集设定为false。第一个的download选项指定了如果没有在该路径下找到数据,那么会自动下载到该路径。
由于没有实现下载数据集,代码运行后有输出:
运行完代码后,我们会得到以下的文件树:
3. 准备数据加载器dataloader
# 1
train_loader = torch.utils.data.DataLoader(train_data,batch_size=64,
shuffle=True,num_workers=2)
# 2
test_loader = torch.utils.data.DataLoader(test_data,batch_size=64,
shuffle=True,num_workers=2)
刚才的datasets是将数据加载进来了,如何在这个数据集中按照我们希望的规则获取数据呢?我们就需要dataloader这个工具。
上面的代码中,我们进行了以下的设定:
- 我们将datasets对象train_data和test_data都传递给Dataloader类
- batchsize是指定每一次取数据,一下子取出几