写在前面
在真正了解Memory Order的作用之前,曾经简单地将Memory Order等同于mutex和atomic来进行线程间数据同步,或者用来限制线程间的执行顺序,其实这是一个错误的理解。直到后来仔细研究了Memory Order之后,才发现无论是功能还是原理,Memory Order与他们都不是同一件事。实际上,Memory Order是用来用来约束同一个线程内的内存访问排序方式的,虽然同一个线程内的代码顺序重排不会影响本线程的执行结果(如果结果都不一致,那么重排就没有意义了),但是在多线程环境下,重排造成的数据访问顺序变化会影响其它线程的访问结果。
正是基于以上原因,引入了内存模型。C++的内存模型解决的问题是如何合理地限制单一线程中的代码执行顺序,使得在不使用锁的情况下,既能最大化利用CPU的计算能力,又能保证多线程环境下不会出现逻辑错误。
指令乱序
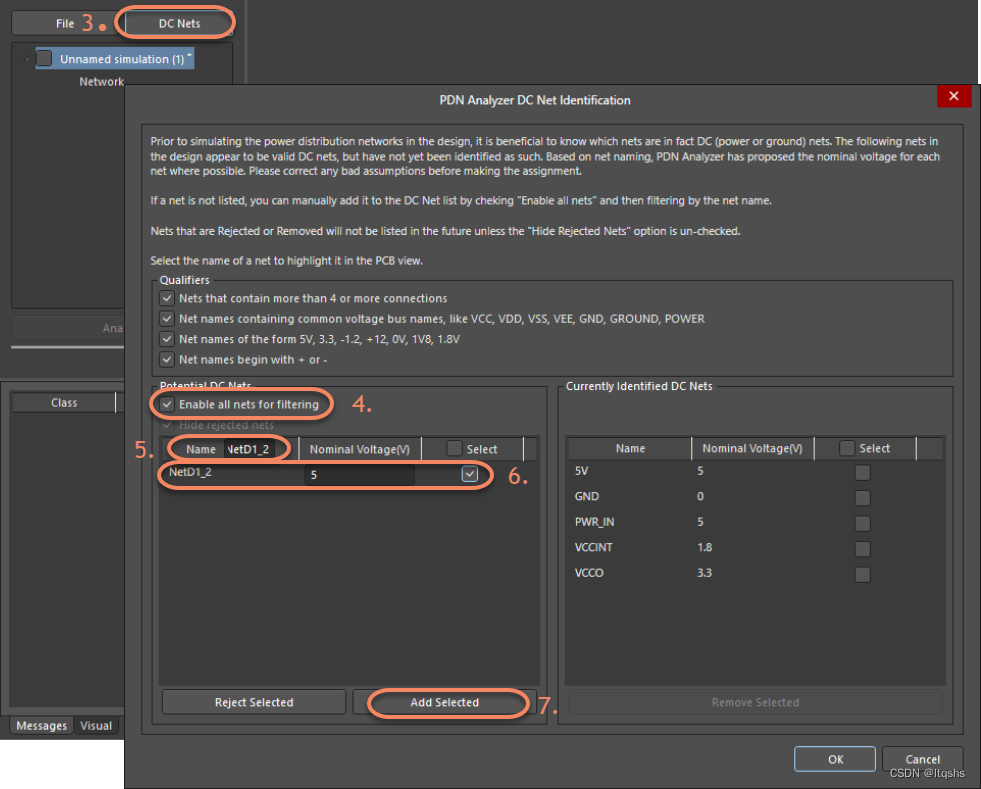
现在的CPU都采用的是多核、多线程技术用以提升计算能力;采用乱序执行、流水线、分支预测以及多级缓存等方法来提升程序性能。多核技术在提升程序性能的同时,也带来了执行序列乱序和内存序列访问的乱序问题。与此同时,编译器也会基于自己的规则对代码进行优化,这些优化动作也会导致一些代码的顺序被重排。
首先,我们看一段代码,如下:
int A = 0;
int B = 0;
void fun() {
A = B + 1; // L5
B = 1; // L6
}
int main() {
fun();
return 0;
}如果使用 g++ test.cc,则生成的汇编指令如下:
movl B(%rip), %eax
addl $1, %eax
movl %eax, A(%rip)
movl $1, B(%rip)通过上述指令,可以看到,先把B放到eax,然后eax+1放到A,最后才执行B = 1。
而如果我们使用g++ -O2 test.cc,则生成的汇编指令如下:
movl B(%rip), %eax
movl $1, B(%rip)
addl $1, %eax
movl %eax, A(%rip)可以看到,先把B放到eax,然后执行B = 1,再执行eax + 1,最后将eax赋值给A。从上述指令可以看出执行B赋值(语句L6)语句先于A赋值语句(语句L5)执行。
我们将上述这种不按照代码顺序执行的指令方式称之为指令乱序。
对于指令乱序,这块需要注意的是:编译器只需要保证在单线程环境下,执行的结果最终一致就可以了,所以,指令乱序在单线程环境下完全是允许的。对于编译器来说,它只知道:在当前线程中,数据的读写以及数据之间的依赖关系。但是,编译器并不知道哪些数据是在线程间共享,而且是有可能会被修改的。而这些是需要开发人员去保证的。
那么,指令乱序是否允许开发人员控制,而不是任由编译器随意优化?
可以使用编译选项停止此类优化,或者使用预编译指令将不希望被重排的代码分隔开,比如在gcc下可用asm volatile,如下:
void fun() {
A = B + 1;
asm volatile("" ::: "memory");
B = 0;
}类似的,处理器也会提供指令给开发人员使用,以避免乱序控制,例如,x86,x86-64上的指令如下:
lfence (asm), void _mm_lfence(void)
sfence (asm), void _mm_sfence(void)
mfence (asm), void _mm_mfence(void)为什么需要内存模型
多线程技术是为了最大限度地压榨cpu,提升计算能力。在单核时代,多线程的概念是在宏观上并行,微观上串行,多线程可以访问相同的CPU缓存和同一组寄存器。但是在多核时代,多个线程可能执行在不同的核上,每个CPU都有自己的缓存和寄存器,在一个CPU上执行的线程无法访问另一个CPU的缓存和寄存器。CPU会根据一定的规则对机器指令的内存交互进行重新排序,特别是允许每个处理器延迟存储并且从不同位置装载数据。与此同时,编译器也会基于自己的规则对代码进行优化,这些优化动作也会导致一些代码的顺序被重排。这种指令的重排,虽然不影响单线程的执行结果,但是会加剧多线程访问共享数据时的数据竞争(Data Race)问题。
以上节例子中的A、B两个变量为例,在编译器将其乱序后,虽然对于当前线程是没问题的。但是在多线程环境下,如果其它线程依赖了A 和 B,会加剧多线程访问共享数据的竞争问题,同时可能会得到意想不到的结果。
正是因为指令乱序以及多线程环境数据竞争的不确定性,我们在开发的时候,经常会使用信号量或者锁来实现同步需求,进而解决数据竞争导致的不确定性问题。但是,加锁或者信号量是相对接近操作系统的底层原语,每一次加锁或者解锁都有可能导致用户态和内核态的互相切换,这就导致了数据访问开销,如果锁使用不当,可能会造成严重的性能问题,所以就需要一种语言层面的机制,既没有锁那样的大开销,又可以满足数据访问一致性的需求。2004年,Java5.0开始引入适用于多线程环境的内存模型,而C++直到C++11才开始引入。
**Herb Sutter**在其文章中这样来评价C++11引入的内存模型:
The memory model means that C++ code now has a standardized library to call regardless of who made the compiler and on what platform it's running. There's a standard way to control how different threads talk to the processor's memory. "When you are talking about splitting [code] across different cores that's in the standard, we are talking about the memory model. We are going to optimize it without breaking the following assumptions people are going to make in the code," Sutter said
从内容可以看出,C++11引入Memory model的意义在于有了一个语言层面的、与运行平台和编译器无关的标准库,可以使得开发人员更为便捷高效地控制内存访问顺序。
一言以蔽之,引入内存模型的原因,有以下几个原因:
-
• 编译器优化:在某些情况下,即使是简单的语句,也不能保证是原子操作
-
• CPU out-of-order:CPU为了提升计算性能,可能会调整指令的执行顺序
-
• CPU Cache不一致:在CPU Cache的影响下,在某个CPU下执行了指令,不会立即被其它CPU所看到
相关视频推荐
linux c/c++后端开发中的重点技术:内存管理(内存管理架构、numa、slab、vmalloc、内存池、内存泄漏、物理内存、虚拟内存、MMU机制)![]() https://www.bilibili.com/video/BV1Vc411F7wv/
https://www.bilibili.com/video/BV1Vc411F7wv/
免费学习地址:Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
关系术语
为了便于更好地理解后面的内容,我们需要理解几种关系术语。
sequenced-before
sequenced-before是一种单线程上的关系,这是一个非对称,可传递的成对关系。
在了解sequenced-before之前,我们需要先看一个概念evaluation(求值)。
对一个表达式进行求值(evaluation),包含以下两部分:
-
• value computations: calculation of the value that is returned by the expression. This may involve determination of the identity of the object (glvalue evaluation, e.g. if the expression returns a reference to some object) or reading the value previously assigned to an object (prvalue evaluation, e.g. if the expression returns a number, or some other value)
-
• Initiation of side effects: access (read or write) to an object designated by a volatile glvalue, modification (writing) to an object, calling a library I/O function, or calling a function that does any of those operations.
上述内容简单理解就是,value computation就是计算表达式的值,side effect就是对对象进行读写。
对于C++来说,语言本身并没有规定表达式的求值顺序,因此像是f1() + f2() + f3()这种表达式,编译器可以决定先执行哪个函数,之后再按照加法运算的规则从左边加到右边,因此编译器可能会优化成为(f1() + f2()) + f(3),但f1() + f2()和f3()都可以先执行。
经常可以看到如下这种代码:
i = i++ + i;正是因为语言本身没有规定表达式的求值顺序,所以上述代码中两个子表达式(i++和i)无法确定先后顺序,因此这个语句的行为是未定义的。
sequenced-before就是对在同一个线程内,求值顺序关系的描述:
-
• 如果A sequenced-before B,代表A的求值会先完成,才进行对B的求值
-
• 如果A not sequenced-before B,而B sequenced-before A,则代表先对B进行求值,然后对A进行求值
-
• 如果A not sequenced-before B,而B not sequenced-before A,则A和B都有可能先执行,甚至可以同时执行
happens-before
happens-before是sequenced-before的扩展,因为它还包含了不同线程之间的关系。当A操作happens-before B操作的时候,操作A先于操作B执行,且A操作的结果对B来说可见。
看下cppreference对happens-before关系的定义,如下:
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true: 1) A is sequenced-before B 2) A inter-thread happens before B
从上述定义可以看出,happens-before包含两种情况,一种是同一线程内的happens-before关系(等同于sequenced-before),另一种是不同线程的happens-before关系。
对于同一线程内的happens-before,其等同于sequenced-before,所以在此忽略,着重讲下线程间的happens-before关系。
假设有一个变量x,其初始化为0,如下:
int x = 0;此时有两个线程同时运行,线程A进行++x操作,线程B打印x的值。因为这两个线程不具备happens-before关系,也就是说没有保证++x操作对于打印x的操作是可见的,因此打印的值有可能是0,也有可能是1。
对于这种场景,语言本身必须提供适当的手段,可以使得开发人员能够在多线程场景下达到happens-before的关系,进而得到正确的运行结果。这也就是上面说的第二点A inter-thread happens before B。
C++中定义了5种能够建立跨线程的happens-before的场景,如下:
-
• A synchronizes-with B
-
• A is dependency-ordered before B
-
• A synchronizes-with some evaluation X, and X is sequenced-before B
-
• A is sequenced-before some evaluation X, and X inter-thread happens-before B
-
• A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
synchronizes-with
synchronized-with描述的是不同线程间的同步关系,当线程A synchronized-with线程B的时,代表线程A对某个变量或者内存的操作,对于线程B是可见的。换句话说,synchronized-with就是跨线程版本的happens-before。
假设在多线程环境下,线程A对变量x进行x = 1的写操作,线程B读取x的值。在未进行任何同步的条件下,即使线程A先执行,线程B后执行,线程B读取到的x的值也不一定是最新的值。这是因为为了让程序执行效率更高编译器或者CPU做了指令乱序优化,也有可能A线程修改后的值在寄存器内,或者被存储在CPU cache中,还没来得及写入内存 。正是因为种种操作 ,所以在多线程环境下,假如同时存在读写操作,就需要对该变量或者内存做同步操作。
所以,synchronizes-with是这样一种关系,它可以保证线程A的写操作结果,在线程B是可见的。
在2014年C++的官方标准文件(Standard for Programming Language C++)N4296的第12页,提示了C++提供的同步操作,也就是使用atomic或mutex:
The library defines a number of atomic operations and operations on mutexes that are specially identified as synchronization operations. These operations play a special role in making assignments in one thread visible to another.
memory_order
C++11中引入了六种内存约束符用以解决多线程下的内存一致性问题(在头文件中),其定义如下:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;这六种内存约束符从读/写的角度进行划分的话,可以分为以下三种:
-
• 读操作(memory_order_acquire memory_order_consume)
-
• 写操作(memory_order_release)
-
• 读-修改-写操作(memory_order_acq_rel memory_order_seq_cst)
ps: 因为memory_order_relaxed没有定义同步和排序约束,所以它不适合这个分类。
举例来说,因为store是一个写操作,当调用store时,指定memory_order_relaxed或者memory_order_release或者memory_order_seq_cst是有意义的。而指定memory_order_acquire是没有意义的。
从访问控制的角度可以分为以下三种:
-
• Sequential consistency模型(memory_order_seq_cst)
-
• Relax模型(memory_order_relaxed)
-
• Acquire-Release模型(memory_order_consume memory_order_acquire memory_order_release memory_order_acq_rel)
从从访问控制的强弱排序,Sequential consistency模型最强,Acquire-Release模型次之,Relax模型最弱。
在后面的内容中,将结合这6种约束符来进一步分析内存模型。
内存模型
Sequential consistency模型
Sequential consistency模型又称为顺序一致性模型,是控制粒度最严格的内存模型。最早追溯到Leslie Lamport在1979年9月发表的论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》,在该文里面首次提出了Sequential consistency概念:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program
根据这个定义,在顺序一致性模型下,程序的执行顺序与代码顺序严格一致,也就是说,在顺序一致性模型中,不存在指令乱序。
顺序一致性模型对应的约束符号是memory_order_seq_cst,这个模型对于内存访问顺序的一致性控制是最强的,类似于很容易理解的互斥锁模式,先得到锁的先访问。
假设有两个线程,分别是线程A和线程B,那么这两个线程的执行情况有三种:第一种是线程A先执行,然后再执行线程B;第二种情况是线程 B 先执行,然后再执行线程A;第三种情况是线程A和线程B同时并发执行,即线程A的代码序列和线程B的代码序列交替执行。尽管可能存在第三种代码交替执行的情况,但是单纯从线程A或线程B的角度来看,每个线程的代码执行应该是按照代码顺序执行的,这就顺序一致性模型。总结起来就是:
-
• 每个线程的执行顺序与代码顺序严格一致
-
• 线程的执行顺序可能会交替进行,但是从单个线程的角度来看,仍然是顺序执行
为了便于理解上述内容,举例如下:
x = y = 0;
thread1:
x = 1;
r1 = y;
thread2:
y = 1;
r2 = x;因为多线程执行顺序有可能是交错执行的,所以上述示例执行顺序有可能是:
-
• x = 1; r1 = y; y = 1; r2 = x
-
• y = 1; r2 = x; x = 1; r1 = y
-
• x = 1; y = 1; r1 = y; r2 = x
-
• x = 1; r2 = x; y = 1; r1 = y
-
• y = 1; x = 1; r1 = y; r2 = x
-
• y = 1; x = 1; r2 = x; r1 = y
也就是说,虽然多线程环境下,执行顺序是乱的,但是单纯从线程1的角度来看,执行顺序是x = 1; r1 = y;从线程2角度来看,执行顺序是y = 1; r2 = x。
std::atomic的操作都使用memory_order_seq_cst 作为默认值。如果不确定使用何种内存访问模型,用 memory_order_seq_cst能确保不出错。
顺序一致性的所有操作都按照代码指定的顺序进行,符合开发人员的思维逻辑,但这种严格的排序也限制了现代CPU利用硬件进行并行处理的能力,会严重拖累系统的性能。
Relax模型
Relax模型对应的是memory_order中的memory_order_relaxed。从其字面意思就能看出,其对于内存序的限制最小,也就是说这种方式只能保证当前的数据访问是原子操作(不会被其他线程的操作打断),但是对内存访问顺序没有任何约束,也就是说对不同的数据的读写可能会被重新排序。
为了便于理解Relax模型,我们举一个简单的例子,代码如下:
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> x{false};
int a = 0;
void fun1() { // 线程1
a = 1; // L9
x.store(true, std::memory_order_relaxed); // L10
}
void func2() { // 线程2
while(!x.load(std::memory_order_relaxed)); // L13
if(a) { // L14
std::cout << "a = 1" << std::endl;
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}上述代码中,线程1有两个代码语句,语句L9是一个简单的赋值操作,语句L10是一个带有memory_order_relaxed标记的原子写操作,基于reorder原则,这两句的顺序没有确定下即不能保证哪个在前,哪个在后。而对于线程2,也有两个代码句,分别是带有memory_order_relaxed标记的原子读操作L13和简单的判断输出语句L14。需要注意的是语句L13和语句L14的顺序是确定的,即语句L13 happens-before 语句L14,这是由while循环代码语义保证的。换句话说,while语句优先于后面的语句执行,这是编译器或者CPU的重排规则。
对于上述示例,我们第一印象会输出a = 1 这句。但实际上,也有可能不会输出。这是因为在线程1中,因为指令的乱序重排,有可能导致L10先执行,然后再执行语句L9。如果结合了线程2一起来分析,就是这4个代码句的执行顺序有可能是#L10-->L13-->L14-->L9,这样就不能得到我们想要的结果了。
那么既然memory_order_relaxed不能保证执行顺序,它们的使用场景又是什么呢?这就需要用到其特性即只保证当前的数据访问是原子操作,通常用于一些统计计数的需求场景,代码如下:
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void fun1() {
for (int n = 0; n < 100; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
void fun2() {
for (int n = 0; n < 900; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}在上述代码执行完成后,cnt == 1000。
通常,与其它内存序相比,宽松内存序具有最少的同步开销。但是,正因为同步开销小,这就导致了不确定性,所以我们在开发过程中,根据自己的使用场景来选择合适的内存序选项。
Acquire-Release模型
Acquire-Release模型的控制力度介于Relax模型和Sequential consistency模型之间。其定义如下:
-
• Acquire:如果一个操作X带有acquire语义,那么在操作X后的所有读写指令都不会被重排序到操作X之前
-
• Relase:如果一个操作X带有release语义,那么在操作X前的所有读写指令操作都不会被重排序到操作X之后
结合上面的定义,重新解释下该模型:假设有一个原子变量A,对A的写操作(Release)和读操作(Acquire)之间进行同步,并建立排序约束关系,即对于写操作(release)X,在写操作X之前的所有读写指令都不能放到写操作X之后;对于读操作(acquire)Y,在读操作Y之后的所有读写指令都不能放到读操作Y之前。
Acquire-Release模型对应六种约束关系中的memory_order_consume、memory_order_acquire、memory_order_release和memory_order_acq_rel。这些约束关系,有的只能用于读操作(memory_order_consume、memory_order_acquire),有的适用于写操作(memory_order_release),有的技能用于读操作也能用于写操作(memory_order_acq_rel)。这些约束符互相配合,可以实现相对严格一点的内存访问顺序控制。
memory_order_release
假设有一个原子变量A,对其进行写操作X的时候施加了memory_order_release约束符,则在当前线程T1中,该操作X之前的任何读写操作指令都不能放在操作X之后。当另外一个线程T2对原子变量A进行读操作的时候,施加了memory_order_acquire约束符,则当前线程T1中写操作之前的任何读写操作都对线程T2可见;当另外一个线程T2对原子变量A进行读操作的时候,如果施加了memory_order_consume约束符,则当前线程T1中所有原子变量A所依赖的读写操作都对T2线程可见(没有依赖关系的内存操作就不能保证顺序)。
需要注意的是,对于施加了memory_order_release约束符的写操作,其写之前所有读写指令操作都不会被重排序写操作之后的前提是:其他线程对这个原子变量执行了读操作,且施加了memory_order_acquire或者 memory_order_consume约束符。
memory_order_acquire
一个对原子变量的load操作时,使用memory_order_acquire约束符:在当前线程中,该load之后读和写操作都不能被重排到当前指令前。如果其他线程使用memory_order_release约束符,则对此原子变量进行store操作,在当前线程中是可见的。
假设有一个原子变量A,如果A的读操作X施加了memory_order_acquire标记,则在当前线程T1中,在操作X之后的所有读写指令都不能重排到操作X之前;当其它线程如果对A进行施加了memory_order_release约束符的写操作Y,则这个写操作Y之前所有的读写指令对当前线程T1是可见的(这里的可见请结合 happens-before 原则理解,即那些内存读写操作会确保完成,不会被重新排序)。也就是说从线程T2的角度来看,在原子变量A写操作之前发生的所有内存写入在线程T1中都会产生作用。也就是说,一旦原子读取完成,线程T1就可以保证看到线程 A 写入内存的所有内容。
为了便于理解,使用cppreference中的例子,如下:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}在上述例子中,原子变量ptr的写操作(L12)施加了memory_order_release标记,根据前面所讲,这意味着在线程producer中,L10和L11不会重排到L12之后;在consumer线程中,对原子变量ptr的读操作L17施加了memory_order_acquire标记,也就是说L8和L19不会重排到L17之前,这也就意味着当L17读到的ptr不为null的时候,producer线程中的L10和L11操作对consumer线程是可见的,因此consumer线程中的assert是成立的。
memory_order_consume
一个load操作使用了memory_order_consume约束符:在当前线程中,load操作之后的依赖于此原子变量的读和写操作都不能被重排到当前指令前。如果有其他线程使用memory_order_release内存模型对此原子变量进行store操作,在当前线程中是可见的。
在理解memory_order_consume约束符的意义之前,我们先了解下依赖关系,举例如下:
std::atomic<std::string*> ptr;
int data;
std::string* p =newstd::string("Hello");
data =42;
ptr.store(p,std::memory_order_release);在该示例中,原子变量ptr依赖于p,但是不依赖data,而p和data互不依赖
现在结合依赖关系,理解下memory_order_consume标记的意义:有一个原子变量A,在线程T1中对原子变量的写操作施加了memory_order_release标记符,同时线程T2对原子变量A的读操作被标记为memory_order_consume,则从线程T1的角度来看,在原子变量写之前发生的所有读写操作,只有与该变量有依赖关系的内存读写才会保证不会重排到这个写操作之后,也就是说,当线程T2使用了带memory_order_consume标记的读操作时,线程T1中只有与这个原子变量有依赖关系的读写操作才不会被重排到写操作之后。而如果读操作施加了memory_order_acquire标记,则线程T1中所有写操作之前的读写操作都不会重排到写之后(此处需要注意的是,一个是有依赖关系的不重排,一个是全部不重排)。
同样,使用cppreference中的例子,如下:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}与memory_order_acquire一节中示例相比较,producer()没有变化,consumer()函数中将load操作的标记符从memory_order_acquire变成了memory_order_consume。而这个变动会引起如下变化:producer()中,ptr与p有依赖 关系,则p不会重排到store()操作L12之后,而data因为与ptr没有依赖关系,则可能重排到L12之后,所以可能导致L19的assert()失败。
截止到此,分析了memory_order_acquire&memory_order_acquire组合以及memory_order_release&memory_order_consume组合的对重排的影响:当对读操作使用memory_order_acquire标记的时候,对于写操作来说,写操作之前的所有读写都不能重排到写操作之后,对于读操作来说,读操作之后的所有读写不能重排到读操作之前;当读操作使用memory_order_consume标记的时候,对于写操作来说,与原子变量有依赖关系的所有读写操作都不能重排到写操作之后,对于读操作来说,当前线程中任何与这个读取操作有依赖关系的读写操作都不会被重排到当前读取操作之前。
当对一个原子变量的读操作施加了memory_order_acquire标记时,对那些使用 memory_order_release标记的写操作线程来说,这些线程中在写之前的所有内存操作都不能被重排到写操作之后,这将严重限制 CPU 和编译器优化代码执行的能力。所以,当确定只需对某个变量限制访问顺序的时候,应尽量使用 memory_order_consume,减少代码重排的限制,以提升程序性能。
memory_order_consume约束符是对acquire&release语义的一种优化,这种优化仅限定于与原子变量存在依赖关系的变量操作,因此在重新排序的限制上,其比memory_order_acquire更为宽容。需要注意的是,因为memory_order_consume实现的复杂性,自2016年6月起,所有的编译器的实现中,memory_order_consume和memory_order_acquire的功能完全一致,详见《P0371R1: Temporarily discourage memory_order_consume》
memory_order_acq_rel
Acquire-Release模型中的其它三个约束符,要么用来约束读,要么用来约束写。那么如何对一个原子操作中的两个动作执行约束呢?这就要用到 memory_order_acq_rel,它既可以约束读,也可以约束写。
对于使用memory_order_acq_rel约束符的原子操作,对当前线程的影响就是:当前线程T1中此操作之前或者之后的内存读写都不能被重新排序(假设此操作之前的操作为操作A,此操作为操作B,此操作之后的操作为B,那么执行顺序总是ABC,这块可以理解为同一线程内的sequenced-before关系);对其它线程T2的影响是,如果T2线程使用了memory_order_release约束符的写操作,那么T2线程中写操作之前的所有操作均对T1线程可见;如果T2线程使用了memory_order_acquire约束符的读操作,则T1线程的写操作对T2线程可见。
理解起来可能比较绕,这个标记相当于对读操作使用了memory_order_acquire约束符,对写操作使用了memory_order_release约束符。当前线程中这个操作之前的内存读写不能被重排到这个操作之后,这个操作之后的内存读写也不能被重排到这个操作之前。
cppreference中使用了3个线程的例子来解释memory_order_acq_rel约束符,代码如下:
#include <thread>
#include <atomic>
#include <cassert>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1() {
data.push_back(42); // L10
flag.store(1, std::memory_order_release); // L11
}
void thread_2() {
int expected=1; // L15
// memory_order_relaxed is okay because this is an RMW,
// and RMWs (with any ordering) following a release form a release sequence
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_relaxed)) { // L18
expected = 1;
}
}
void thread_3() {
while (flag.load(std::memory_order_acquire) < 2); // L24
// if we read the value 2 from the atomic flag, we see 42 in the vector
assert(data.at(0) == 42); // L26
}
int main() {
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join();
b.join();
c.join();
return 0;
}线程thread_2中,对原子变量flag的compare_exchange操作使用了memory_order_acq_rel约束符,这就意味着L15不能重排到L18之后,也就是说当compare_exchange操作发生的时候,能确保expected的值是1,使得这个 compare_exchange_strong操作能够完成将flag替换成2的动作;thread_1线程中对flag使用了带memory_order_release约束符的store,这意味着当thread_2线程中取flag的值的时候,L10已经完成(不会被重排到L11之后)。当thread_2线程compare_exchange操作将2写入flag的时候,thread_3线程中带memory_order_acquire标记的load操作能看到L18之前的内存写入,自然也包括L10的内存写入,所以L26的断言始终是成立的。
上面例子中,memory_order_acq_rel约束符用于同时存在读和写的场景,这个时候,相当于使用了memory_order_acquire&memory_order_acquire组合组合。其实,它也可以单独用于读或者单独用于写,示例如下:
// Thread-1:
a = y.load(memory_order_acq_rel); // A
x.store(a, memory_order_acq_rel); // B
// Thread-2:
b = x.load(memory_order_acq_rel); // C
y.store(1, memory_order_acq_rel); // D另外一个实例:
// Thread-1:
a = y.load(memory_order_acquire); // A
x.store(a, memory_order_release); // B
// Thread-2:
b = x.load(memory_order_acquire); // C
y.store(1, memory_order_release); // D上述两个示例,效果完全一样,都可以保证A先于B执行,C先于D执行。
总结
C++11提供的6种内存访问约束符中:
-
• memory_order_release:在当前线程T1中,该操作X之前的任何读写操作指令都不能放在操作X之后。如果其它线程对同一变量使用了memory_order_acquire或者memory_order_consume约束符,则当前线程写操作之前的任何读写操作都对其它线程可见(注意consume的话是依赖关系可见)
-
• memory_order_acquire:在当前线程中,load操作之后的读和写操作都不能被重排到当前指令前。如果有其他线程使用memory_order_release内存模型对此原子变量进行store操作,在当前线程中是可见的。
-
• memory_order_relaxed:没有同步或顺序制约,仅对此操作要求原子性
-
• memory_order_consume:在当前线程中,load操作之后的依赖于此原子变量的读和写操作都不能被重排到当前指令前。如果有其他线程使用memory_order_release内存模型对此原子变量进行store操作,在当前线程中是可见的。
-
• memory_order_acq_rel:等同于对原子变量同时使用memory_order_release和memory_order_acquire约束符
-
• memory_order_seq_cst:从宏观角度看,线程的执行顺序与代码顺序严格一致
C++的内存模型则是依赖上面六种内存约束符来实现的:
-
• Relax模型:对应的是memory_order中的memory_order_relaxed。从其字面意思就能看出,其对于内存序的限制最小,也就是说这种方式只能保证当前的数据访问是原子操作(不会被其他线程的操作打断),但是对内存访问顺序没有任何约束,也就是说对不同的数据的读写可能会被重新排序
-
• Acquire-Release模型:对应的memory_order_consume memory_order_acquire memory_order_release memory_order_acq_rel约束符(需要互相配合使用);对于一个原子变量A,对A的写操作(Release)和读操作(Acquire)之间进行同步,并建立排序约束关系,即对于写操作(release)X,在写操作X之前的所有读写指令都不能放到写操作X之后;对于读操作(acquire)Y,在读操作Y之后的所有读写指令都不能放到读操作Y之前。
-
• Sequential consistency模型:对应的memory_order_seq_cst约束符;程序的执行顺序与代码顺序严格一致,也就是说,在顺序一致性模型中,不存在指令乱序。
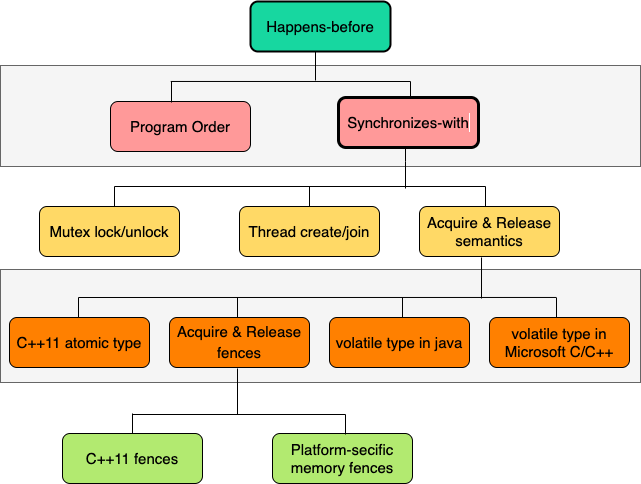
下面这幅图大致梳理了内存模型的核心概念,可以帮我们快速回顾。