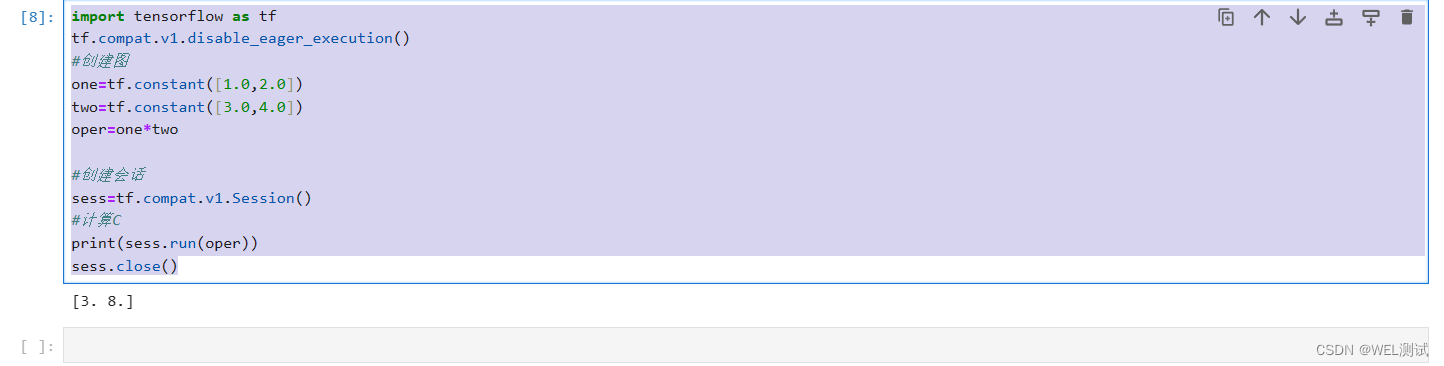
主从架构
主从架构有什么用?
通过搭建MySQL主从集群,可以缓解MySQL的数据存储以及访问的压力。
- 数据安全(主备):给主服务增加一个数据备份。基于这个目的,可以搭建主从架构,或者也可以基于主从架构搭建互主的架构。
- 读写分离(主从):对于大部分的Java业务系统来说,都是读多写少的,读请求远远高于写请求。这时,当主服务的访问压力过大时,可以将数据读请求转为由从服务来分担,主服务只负责数据写入的请求,这样大大缓解数据库的访问压力。
注意:我们不能对备份的的节点进行写操作只能进行读,我们写入一定是写入主节点 - 故障转移-高可用:当MySQL主服务宕机后,可以由一台从服务切换成为主服务,继续提供数据读
写功能。
对于高可用架构,主从数据的同步也只是实现故障转移的一个前提条件,要实现MySQL主从切换,
还需要依靠一些其他的中间件来实现。比如MMM、MHA、MGR。
主从架构原理
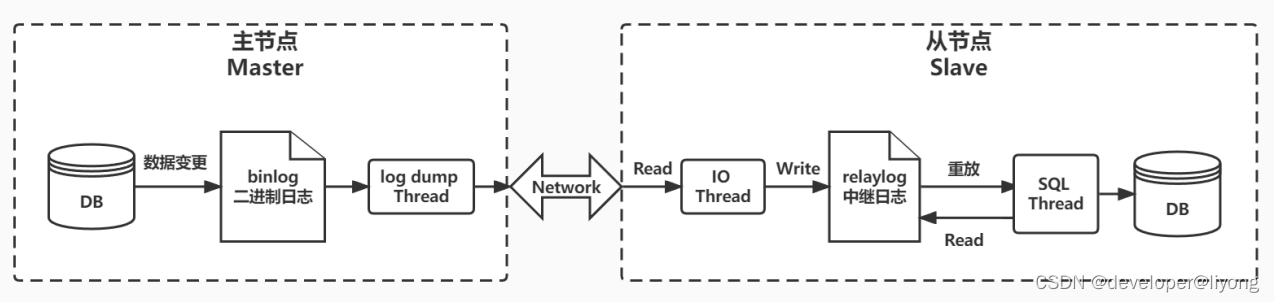
具体流程如下:
- 在主服务上打开binlog记录每一步的数据库操作
- 然后,从服务上会有一个IO线程,负责跟主服务建立一个TCP连接,请求主服务将binlog传输过来
- 这时,主库上会有一个IO dump线程,负责通过这个TCP连接把binlog日志传输给从库的IO线程
- 主服务器MySQL服务将所有的写操作记录在 binlog 日志中,并生成 log dump 线程,将 binlog 日志传给从服务器MySQL服务的 I/O 线程。
- 接着从服务的IO线程会把读取到的binlog日志数据写入自己的relay日志文件中。
- 然后从服务上另外一个SQL线程会读取relay日志里的内容,进行操作重演,达到还原数据的目的。
注意:
- 主从复制是异步的逻辑的 SQL 语句级的复制
- 复制时,主库有一个 I/O 线程,从库有两个线程,即 I/O 和 SQL 线程
- 实现主从复制的必要条件是主库要开启记录 binlog 的功能
- 作为复制的所有 MySQL 节点的 server-id 都不能相同
- binlog 文件只记录对数据内容有更改的 SQL 语句,不记录任何查询语句
- 双方MySQL必须版本一致,至少需要主服务的版本低于从服务
- 两节点间的时间需要同步
主从复制形式
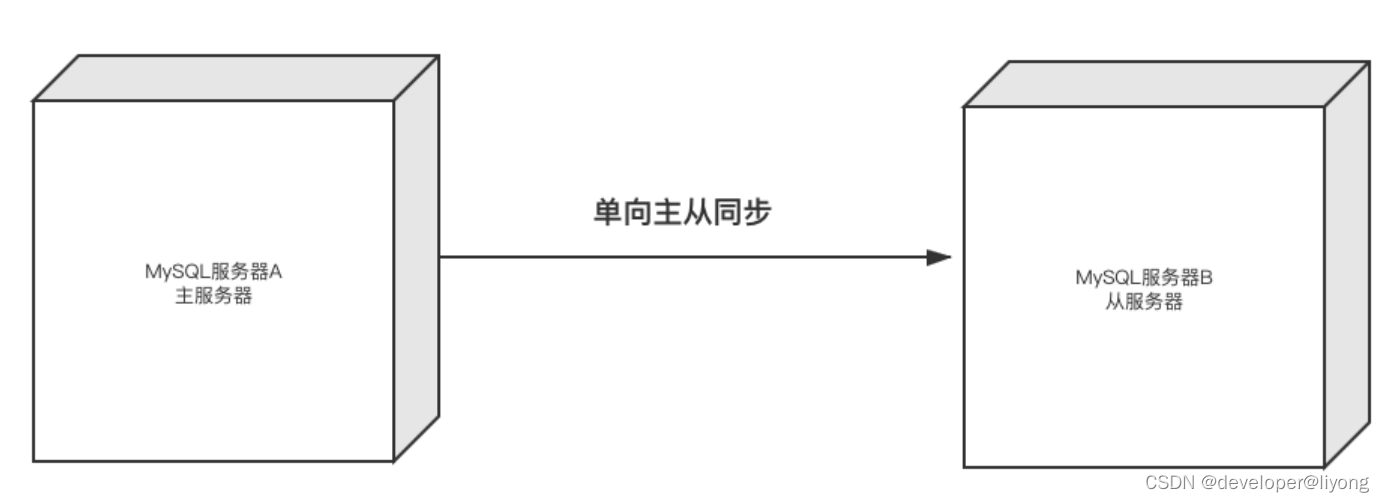
1 一主一从
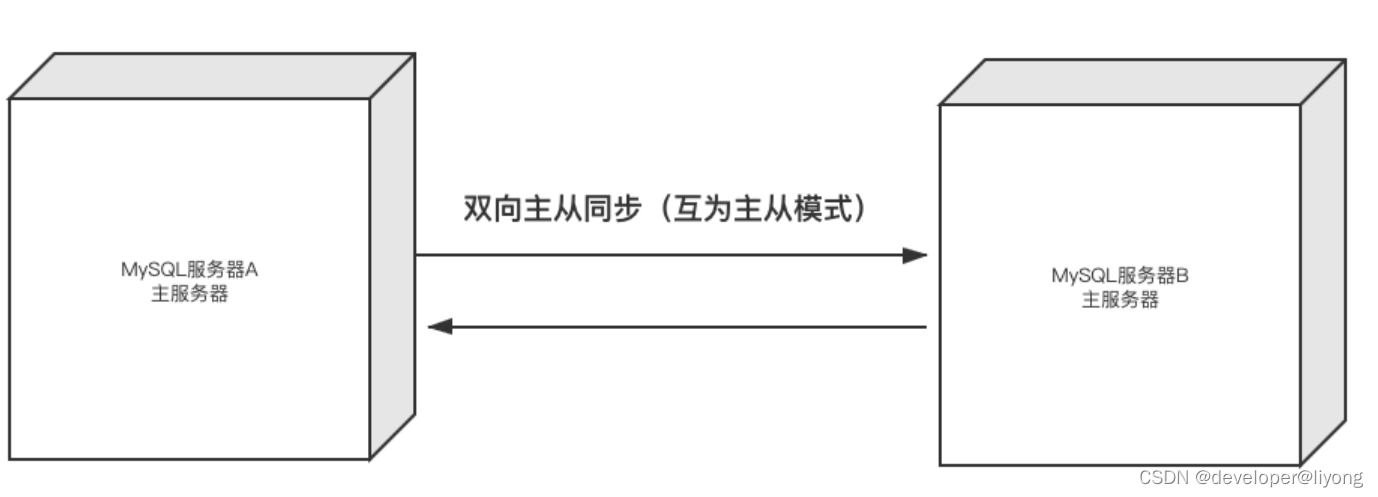
2 主主复制
存在数据一致性问题,可以提高读写能力。
3 一主多从
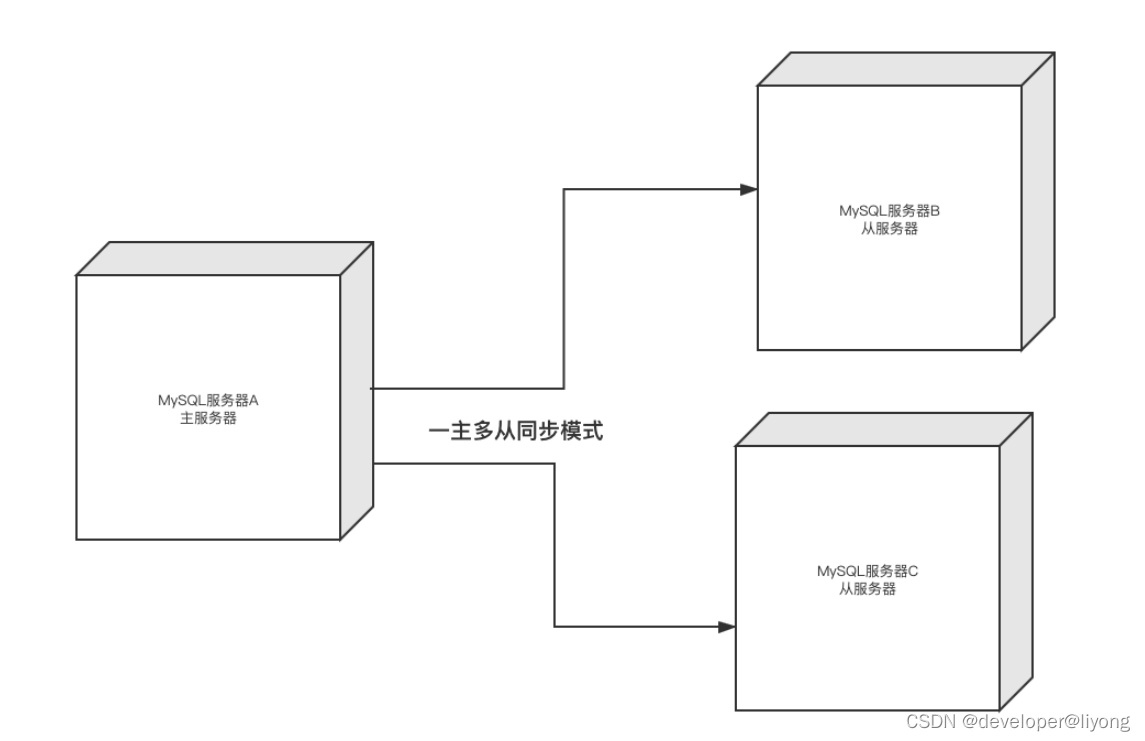
4 多主一从(mysql5.7以后)
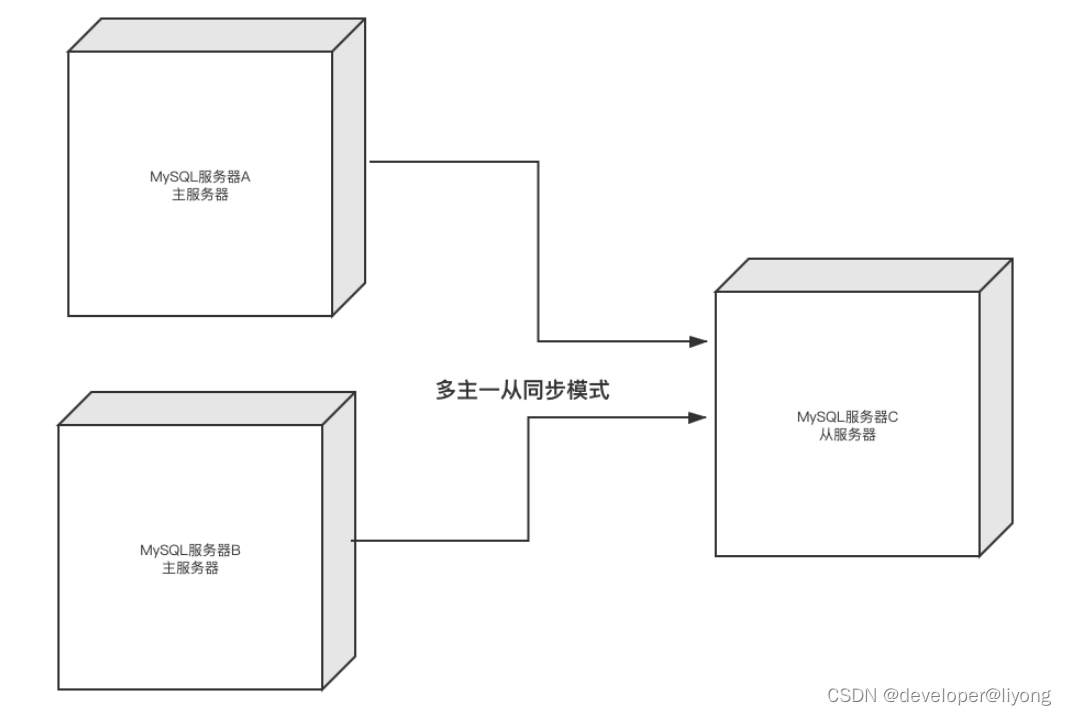
主一从的MySQL主从同步集群,具有了数据同步的基础功能。而在生产环境中,通常会以此为基础,根据业务情况以及负载情况,搭建更大更复杂的集群,掌握了一主一从的搭建方式,其它的方式就好弄了。
互主集群:我们也可以扩展出互为主从的互主集群甚至是环形的主从集群,实现多活部署。
5 联级复制
降低主从同步的延迟,降低主服务器的压力,因为同步也是要消耗资源的。

案例实战
一主一从
首先配置主服务器
[mysqld]
# binlog刷盘策略
sync_binlog=1
# 需要备份的数据库
binlog-do-db=hello
# 不需要备份的数据库
binlog-ignore-db=mysql
# 启动二进制文件
log-bin=mysql-bin
# 服务器ID
server-id=132
#设置错误日志输出路径
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查询相关日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#记录没有使用到索引的sql语句
log_queries_not_using_indexes=ON
创建用于同步的用户
#需要保证mysql-slave 主机名能够被解析
CREATE USER 'slave' @'mysql-slave' IDENTIFIED BY '654321';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave' @'mysql-slave';
docker run -d -p 3306:3306 -v $(pwd)/logs:/var/lib/logs -v $(pwd)/conf:/etc/mysql/conf.d -v $(pwd)/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=654321 --name mysql-master mysql:5.7
show master status;
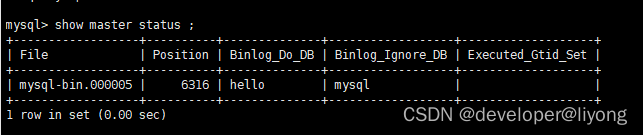
创建从数据库
[mysqld]
server-id=133
#设置错误日志输出路径
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查询相关日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#记录没有使用到索引的sql语句
log_queries_not_using_indexes=ON
#--link 这样从数据库可以直接和主数据库通信 原理就是在从数据库hosts文件里加了容器的端口映射并且和容器进行绑定
docker run -d -p 13306:13306 --link=mysql:msql-master -v $(pwd)/logs:/var/lib/logs -v $(pwd)/conf:/etc/mysql/conf.d -v $(pwd)/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=654321 --name mysql-slave mysql:5.7
change master to
master_host='myql-master',
master_port=3306,
master_user='slave',
master_password='654321',
master_log_file='mysql-bin.000004',
#这个值一定要填我上面 show master status 中的偏移值
master_log_pos=6316,
MASTER_AUTO_POSITION=0;
start slave;
show slave status \G;
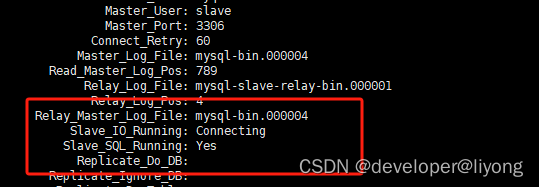
验证这个时候我们去主库间插入数据,就会被同步到从库。
基于主从复制有这样几个问题:
1 如果我们部署的是一主多从,这个时候如果主节点挂掉了,需要从节点变为主节点是一件麻烦的事情,并且丢失了很多数据。
2 同步有延迟或者同步丢失。
基于GTID的主从复制
什么是GTID?
从 MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式。GTID即全局事务ID (Global TransactionIdentifier),其保证每个主节点上提交的事务,在从节点可以一致性的复制。
这种方式强化了数据库的主备一致性,故障恢复以及容错能力。GTID在一主一从情况下没有优势,对于两主以上的结构优势异常明显,可以在数据不丢失的情况下切换新主
GTID实际上是由UUID+TID (即transactionId)组成的,其中UUID(即server_uuid) 产生于auto.conf文件,是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行。GTID在一组复制中,全局唯一。 通过GTID的UUID可以知道这个事务在哪个实例上提交的。
GTID的优势
- GTID相对于binlog+pos 复制数据安全性更高、failover更简单、搭建主从复制更简单
- 实现 failover不用像binlog+pos 复制那样需要找 log_file 和 log_pos
- 一个 GTID 在一个node上只执行一次,避免重复执行导致数据混乱或者主从不一致
- 根据 GTID 可以快速的确定事务最初是在哪个实例上提交
- 使得 DBA 在运维中做集群变迁时更加方便
注意事项 - 在一个复制组中必须要求统一开启GTID或是关闭GTID
- 主从库的表存储引擎必须是一致,不允许一个SQL同时更新一个事务引擎和非事务引擎的表
- MySQL在主从复制时如果要跳过报错,可以采取以下方式跳过SQL(event)组成的事务,但GTID不支持以下方式(也就是说GTID不支持跳过报错)
set global SQL_SLAVE_SKIP_COUNTER=1;
start slave sql_thread;
- 不支持下面语句的复制(主库直接报错)
create table….select
create temporary table
drop temporary table
GTID 主从复制原理
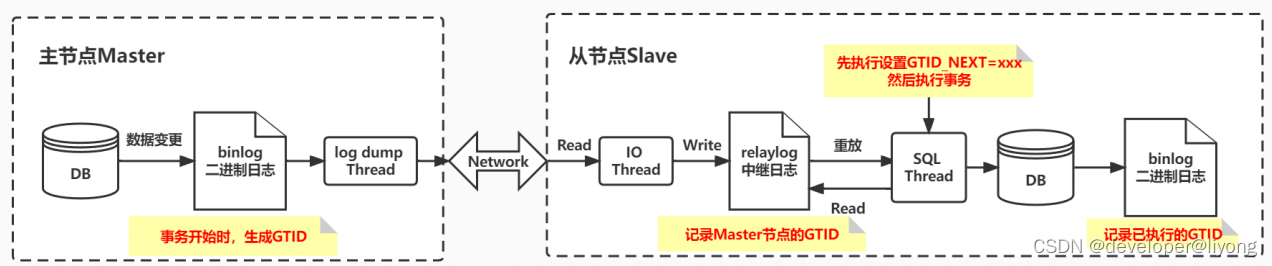
- Master更新数据时,会在事务前产生GTID一同记录到binlog日志中
- Slave的IO Thread将变更后的binlog写入到本地的relaylog中,这其中含有Master的GTID
- SQL Thread读取这个 GTID 的值并设置 GTID_NEXT变量,告诉 Slave下一个要执行的 GTID 值,然后对比 Slave 端的 binlog 是否有该 GTID
- 如果有,说明该 GTID 的事务已经执行 Slave 会忽略
- 如果没有,Slave 就会执行该 GTID 事务,并记录该 GTID 到自身的 binlog
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有二级索引就用全表扫描
在使用GTID的时候如果这个时候一主多从,切换从节点为主节点非常的方便,我们可以找到数据较为完整的Server。由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用
CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_AUTO_POSITION命令就可以直接完成failover的工作。
注意:在我们切换完Master以后不要在这个数据库上进行一些操作,例如更新和删除数据,因为这部分事务到时候会同步到从节点,万一操作错了,从节点的数据也被刷新了,容易导致数据出问题。
下面我们基于上面的一主一从来搭建GTID主从(直接搭建一主多从,需要重启):
主节点的配置
[mysqld]
server-id=133
#设置错误日志输出路径
log-error=/var/lib/logs/log-err.log
log_warnings=1
#开启gtid
gtid_mode=on
enforce_gtid_consistency=on
# 做级联复制的时候,再开启。允许下端接入slave
log_slave_updates=1
#慢查询相关日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#记录没有使用到索引的sql语句
log_queries_not_using_indexes=ON
#查看服务器的UUID
cat /var/lib/mysql/auto.cnf
#可以才看到GTID 是UUID + 事务ID
show master status;

从服务器
由于我们之前已经有数据了所以我们要,先把数据迁移过来。
#备份
mysqldump -u root -p --all-databases > backup.sql
#导入
mysql -uroot -p < backup.sql
[mysqld]
# binlog刷盘策略
sync_binlog=1
# 需要备份的数据库
binlog-do-db=hello
# 不需要备份的数据库
binlog-ignore-db=mysql
# 启动二进制文件
log-bin=mysql-bin
# 服务器ID
server-id=132
#设置错误日志输出路径
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查询相关日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#记录没有使用到索引的sql语句
log_queries_not_using_indexes=ON
gtid_mode=on
enforce_gtid_consistency=on
# 强烈建议,其他格式可能造成数据不一致
binlog_format=row
change master to
master_host='mysql-master',
master_port=3306,
master_user='slave',
master_password='654321',
MASTER_AUTO_POSITION=1;
另一个服务器一样的操作,记得一定要修改server-id。接着去验证是否同步即可。

半同步复制机制
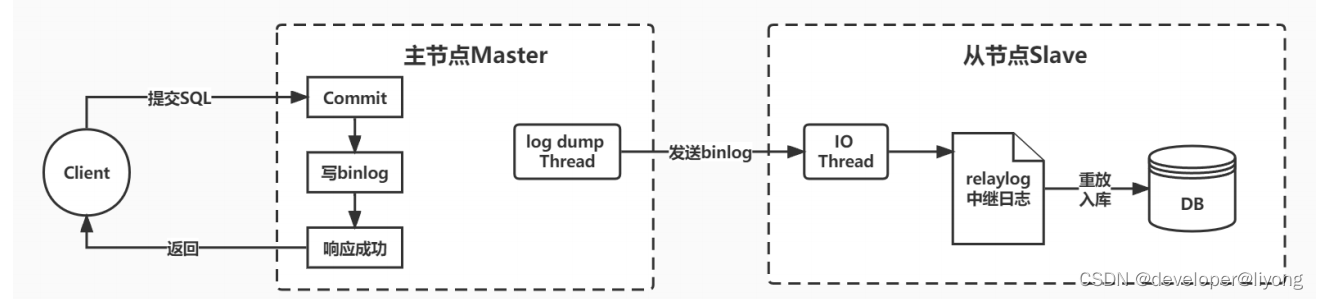
1)异步复制
MySQL主从集群默认采用的是一种异步复制的机制。
主服务在执行用户提交的事务后,写入binlog日志,然后就给客户端返回一个成功的响应了。而binlog
会由一个dump线程异步发送给Slave从服务。由于这个发送binlog的过程是异步的。主服务在向客户端
反馈执行结果时,是不知道binlog是否同步成功了的。这时候如果主服务宕机了,而从服务还没有备份
到新执行的binlog,那就有可能会丢数据。
2)半同步复制
半同步复制机制是一种介于异步复制和全同步复制之前的机制。
主库在执行完客户端提交的事务后,并不是立即返回客户端响应,而是等待至少一个从库接收并写到relaylog中,才会返回给客户端。
MySQL在等待确认时,默认会等 10 秒,如果超过10秒没有收到ack,就会降级成为 异步复制 。
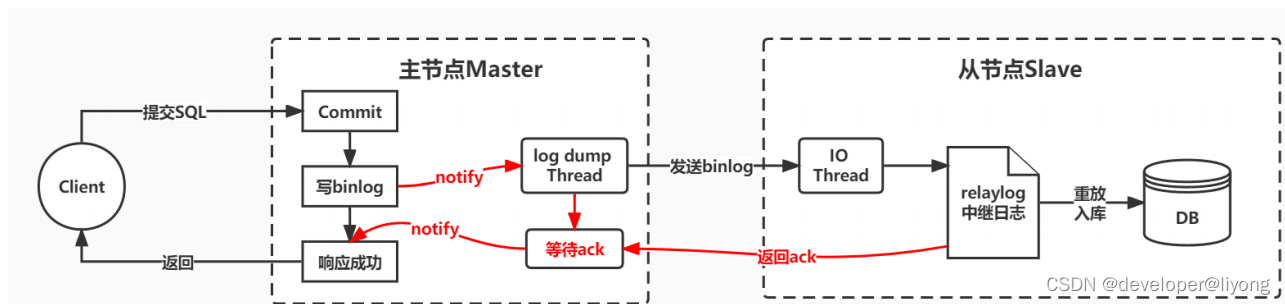
这种半同步复制相比异步复制,能够有效的提高数据的安全性。但是这种安全性也不是绝对的,他只保证事务提交后的binlog至少传输到了一个从库,且并不保证从库应用这个事务的binlog是成功的。另一方面,半同步复制机制也会造成一定程度的延迟,这个延迟时间最少是一个TCP/IP请求往返的时间。整个服务的性能是会有所下降的。而当从服务出现问题时,主服务需要等待的时间就会更长,要等到从服务的服务恢复或者请求超时才能给用户响应。
案例搭建
我们基于上面的GTID一主两从来搭建,只需要在这个基础上加上半同步机制就行。
#查看当前数据库是否支持 版同步机制
select @@have_dynamic_loading;
#查看插件的位置
show variables like 'plugin_dir';
安装插件
主机节点
install plugin rpl_semi_sync_master soname 'semisync_master.so';
#查看半同步机制的参数
show global variables like 'rpl_semi%';
#开半同步机制
set global rpl_semi_sync_master_enabled=ON;
# 单位是毫秒,可动态调整,表示主库事务等待从库返回commit成功信息超过30秒就降为异步模式,
set global rpl_semi_sync_master_timeout=30000;
#查看插件是否搭建成功了
select * from mysql.plugin;
#监控状态
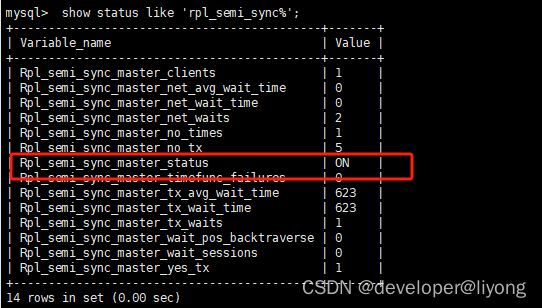
show status like 'rpl_semi_sync%';

半同步复制有两种方式,rpl_semi_sync_master_wait_point通过这个参数指定:
- AFTER_SYNC 方式:默认,主库把日志写入binlog并且复制给从库,然后开始等待从库的响应。从库返回成功后,主库再提交事务,接着给客户端返回一个成功响应性能更差,安全性更好。
- AFTER_COMMIT 方式:主库把日志写入binlog并且复制给从库,主库就提交自己的本地事务,再等待从库返回给自己一个成功响应,等到响应后主库再给客户端返回响应。性能更好,安全性较差区别:提交事务的时机不同。
安装从节点的插件
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
#开启半同步
set global rpl_semi_sync_slave_enabled = on;
#监控状态
show status like 'rpl_semi_sync%';
验证停止其中的一个节点
stop slave io_thread;
#下面插入一条数据然后看半同步状态

#恢复
start slave;