任务:
输入自己的音频,导入maya模型,让maya模型通过音频驱动说话
教程:
https://www.bilibili.com/video/BV1rZ4y1R7H4/?p=2&spm_id_from=pageDriver&vd_source=ef114f70c3fd4d5394f12dbd3d022bbe
一.下载和安装
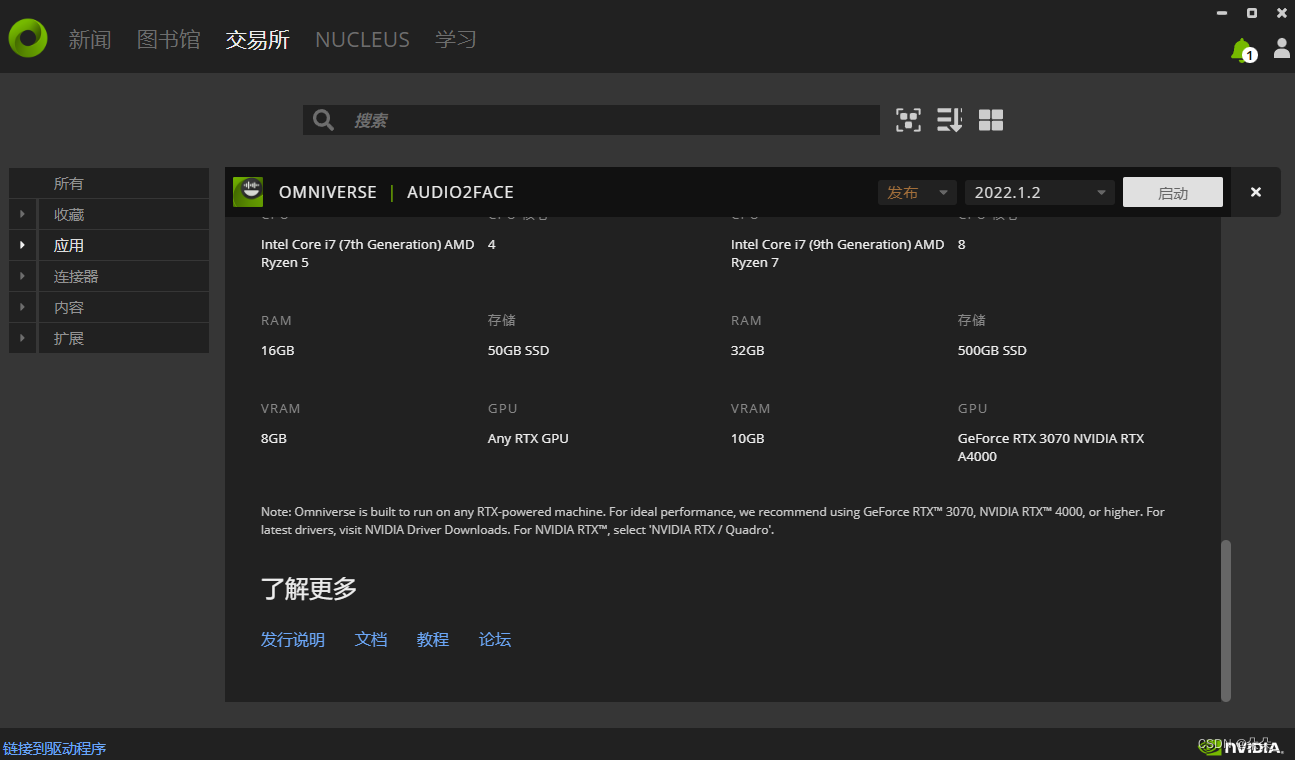
1.首先在官网下载NVIDIA Omniverse
https://www.nvidia.cn/omniverse/apps/audio2face/
2.再在Omniverse平台安Audio2Face
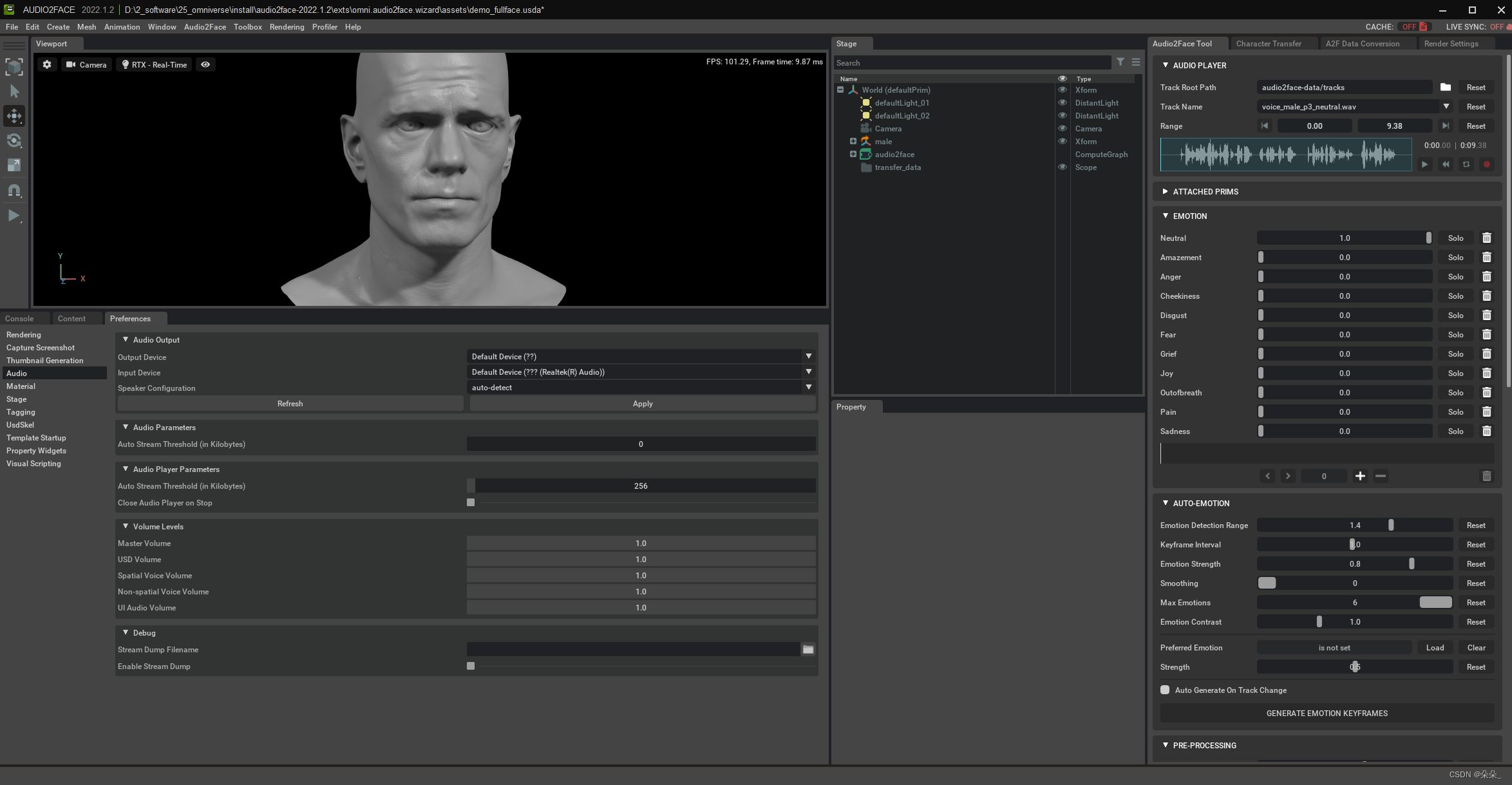
二.导入模型
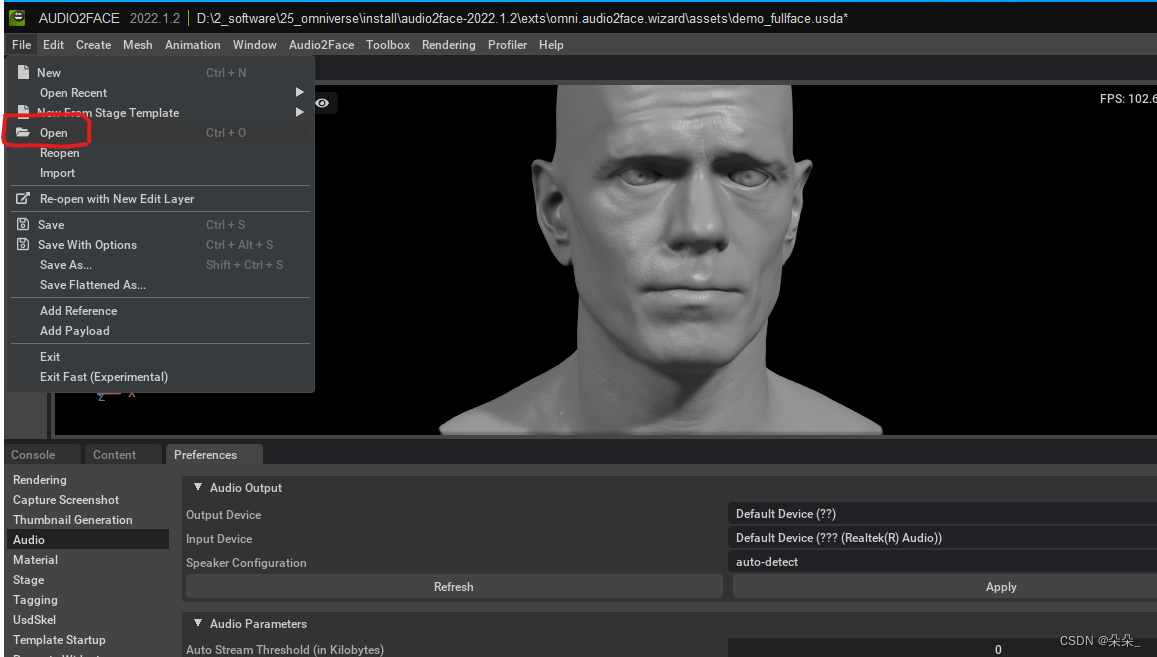
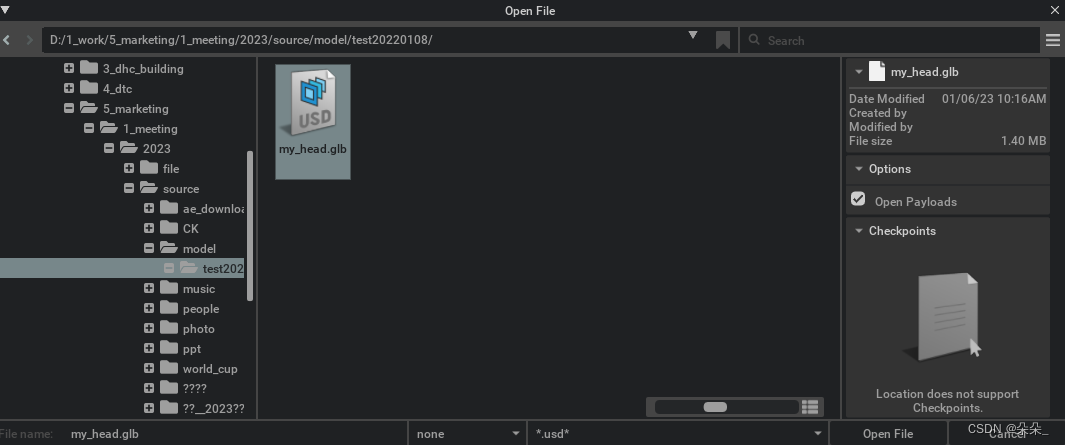
选中1,出现两个模板头像
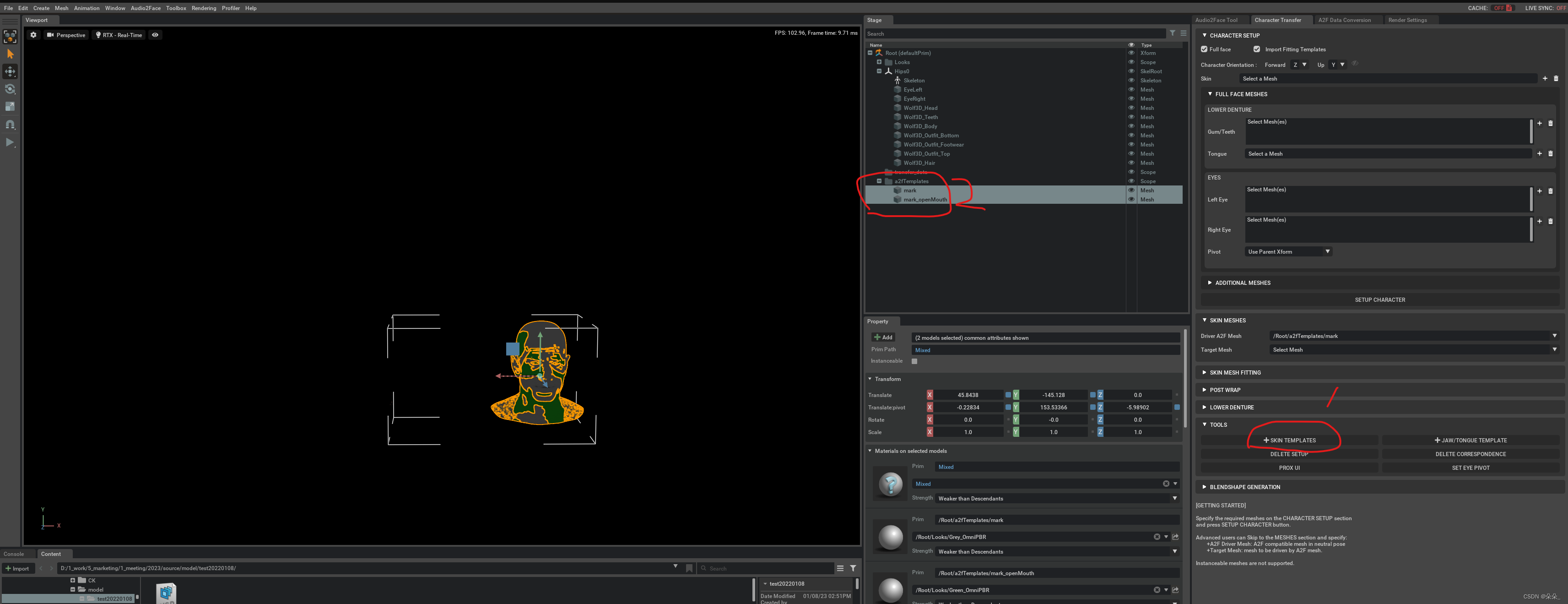
模型为glb格式,导入结果如下,教程里模型格式为usd
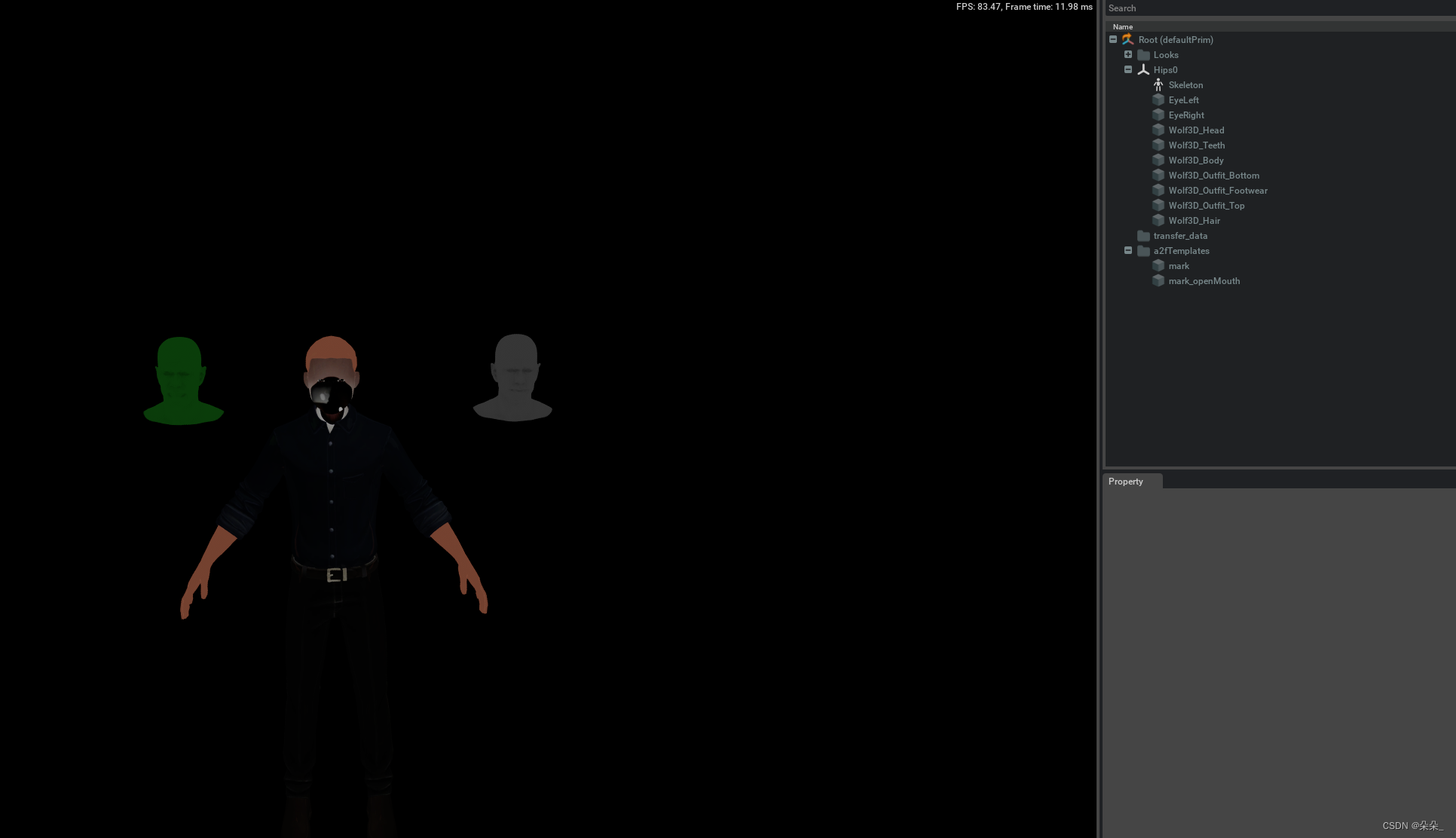
下图为教程里的模型格式

加灯光,方便看清人脸
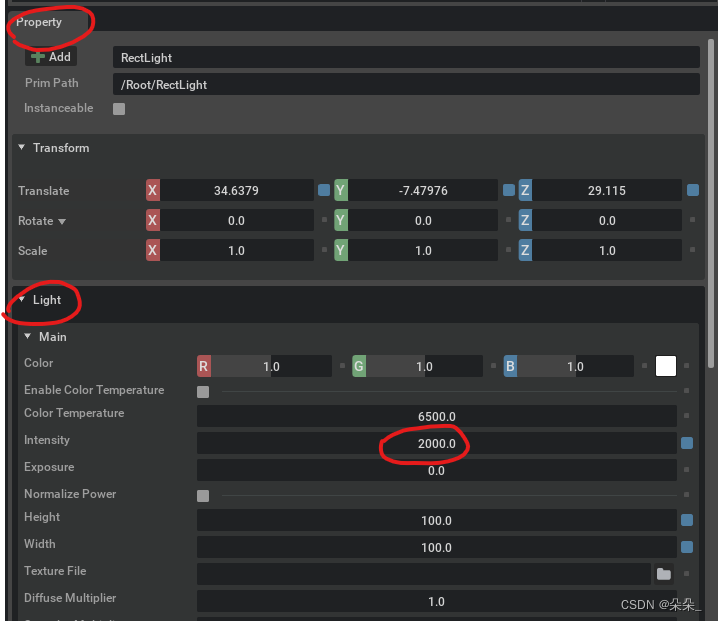
灯光参数
设置表情捕捉对象,1,2,3分别对应
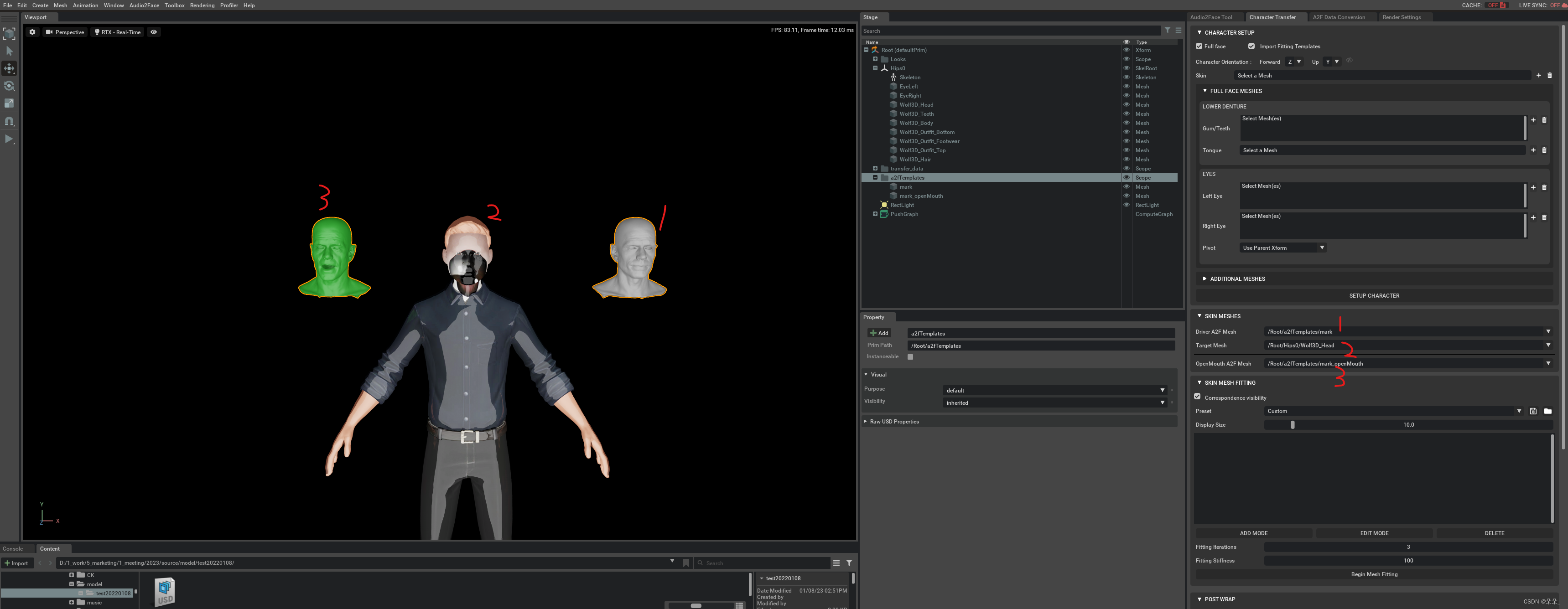
捕捉表情
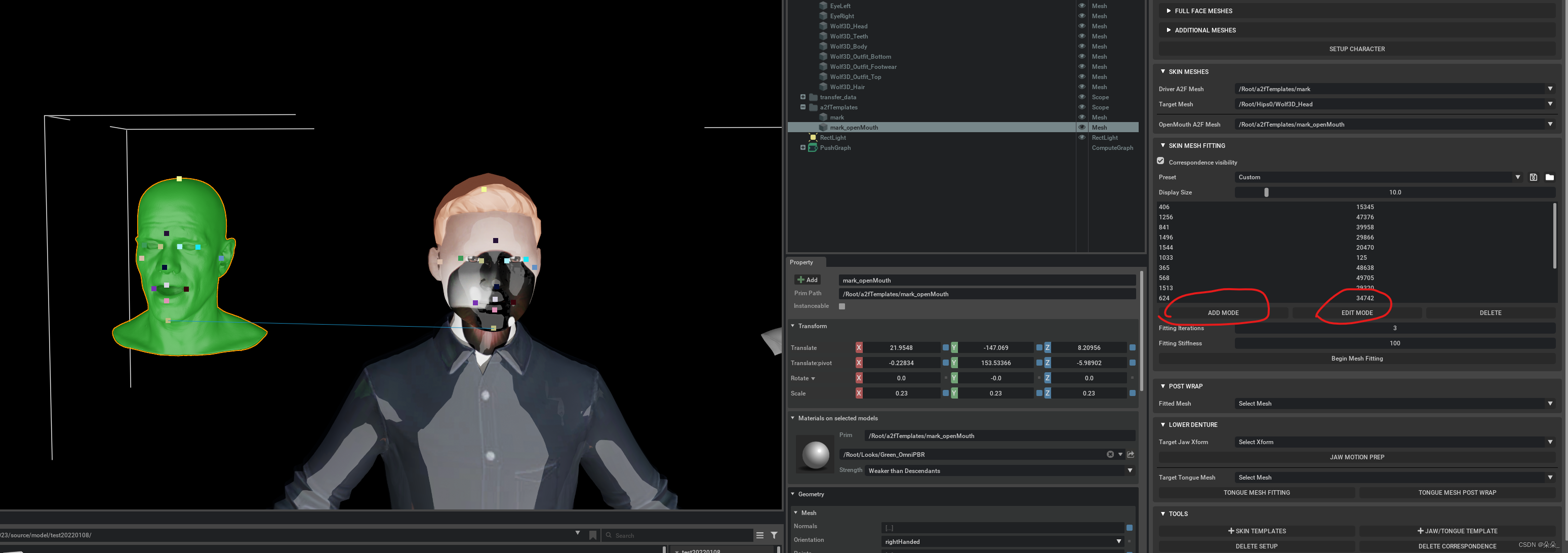
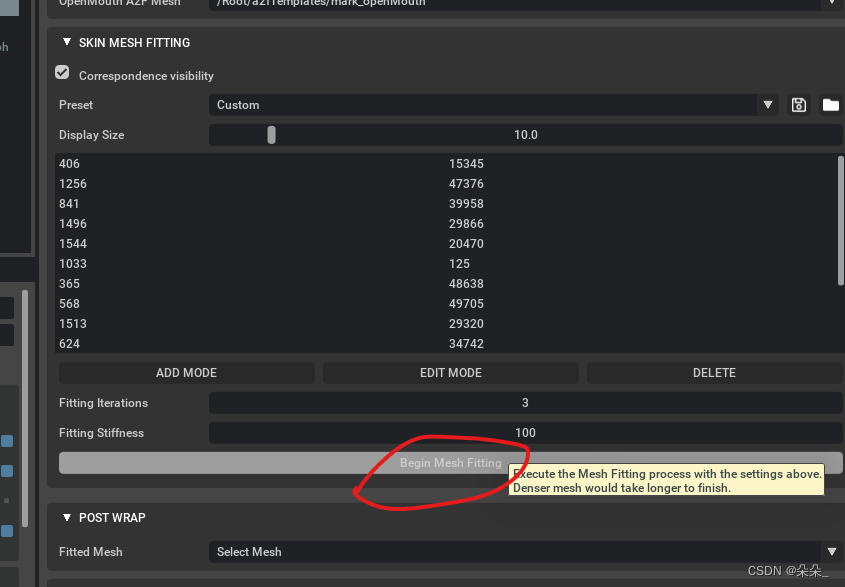
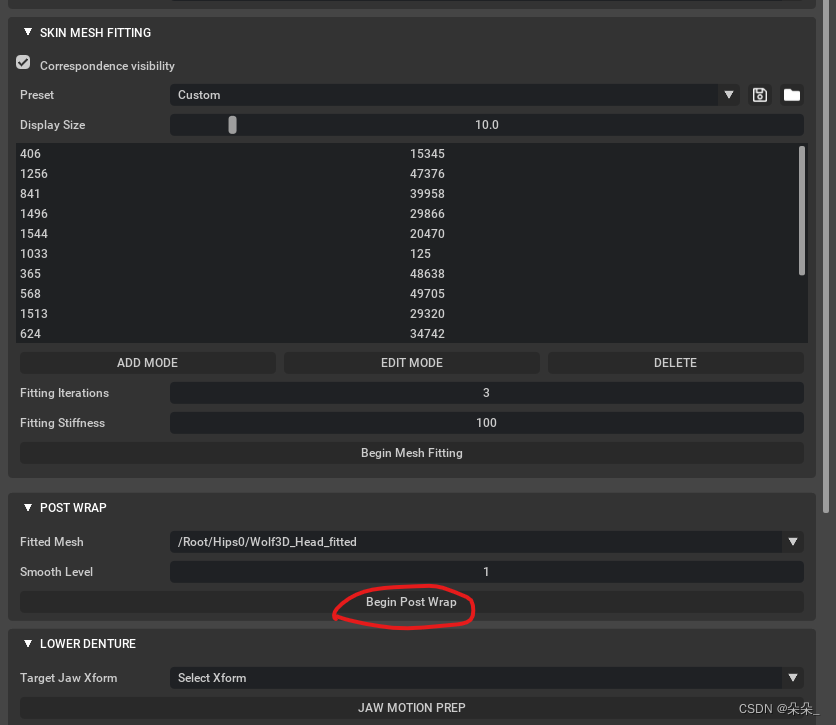
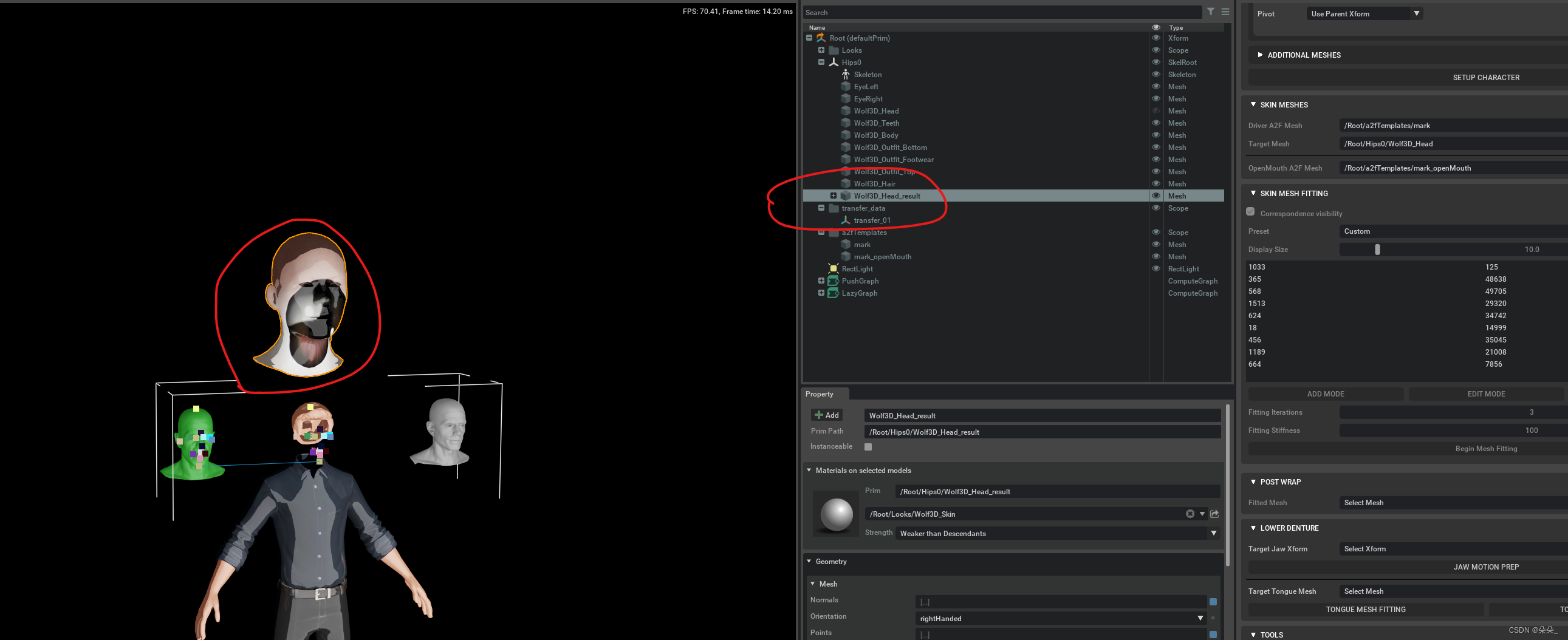
得到一个可以语音驱动的新模型
三.输入音频
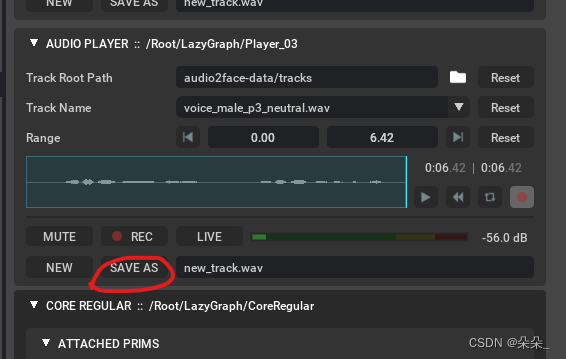
音频可以通过麦克风录制。
添加一个新语音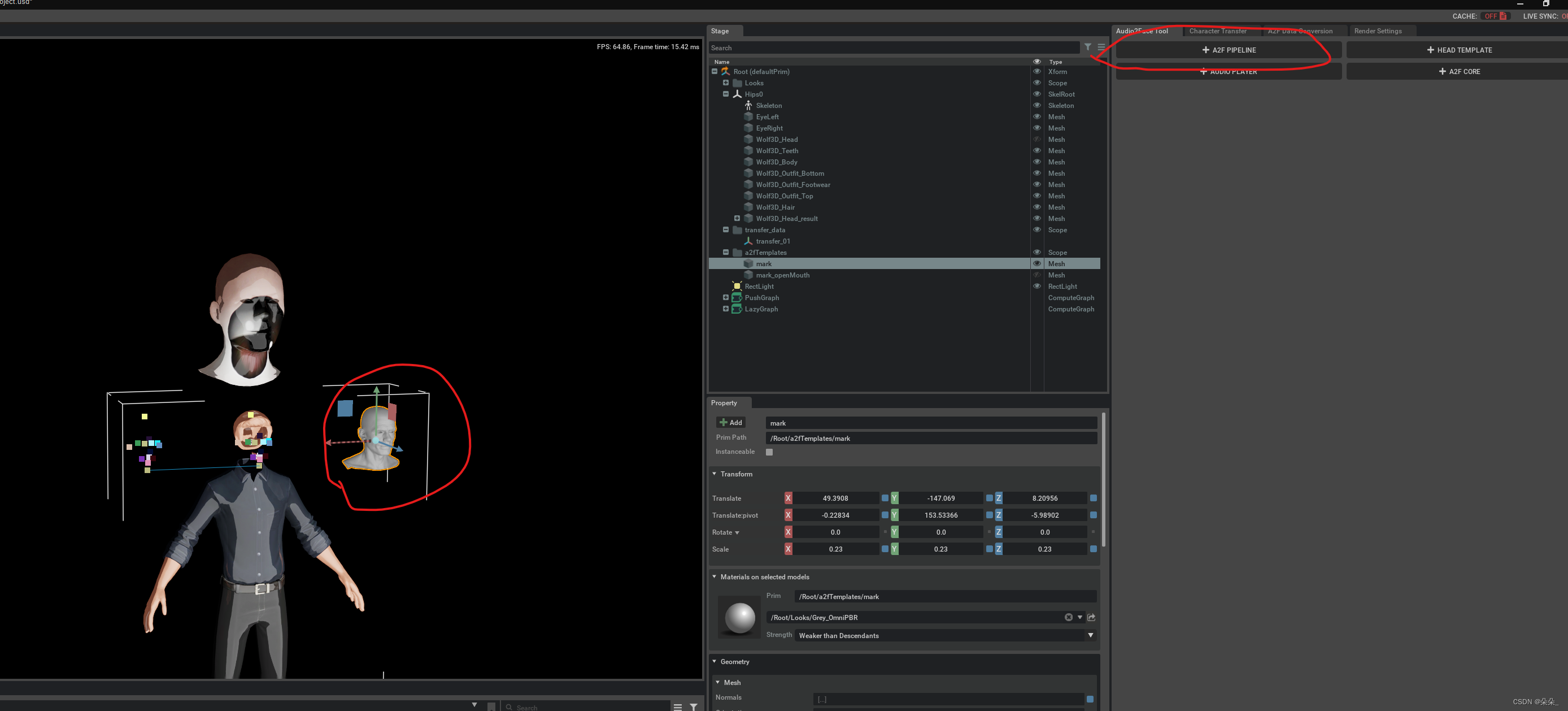
调节表情强度等
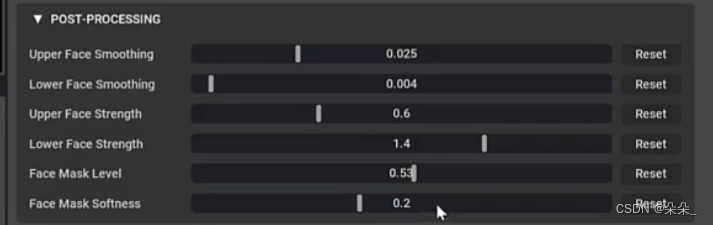
四.导出模型
导出音频
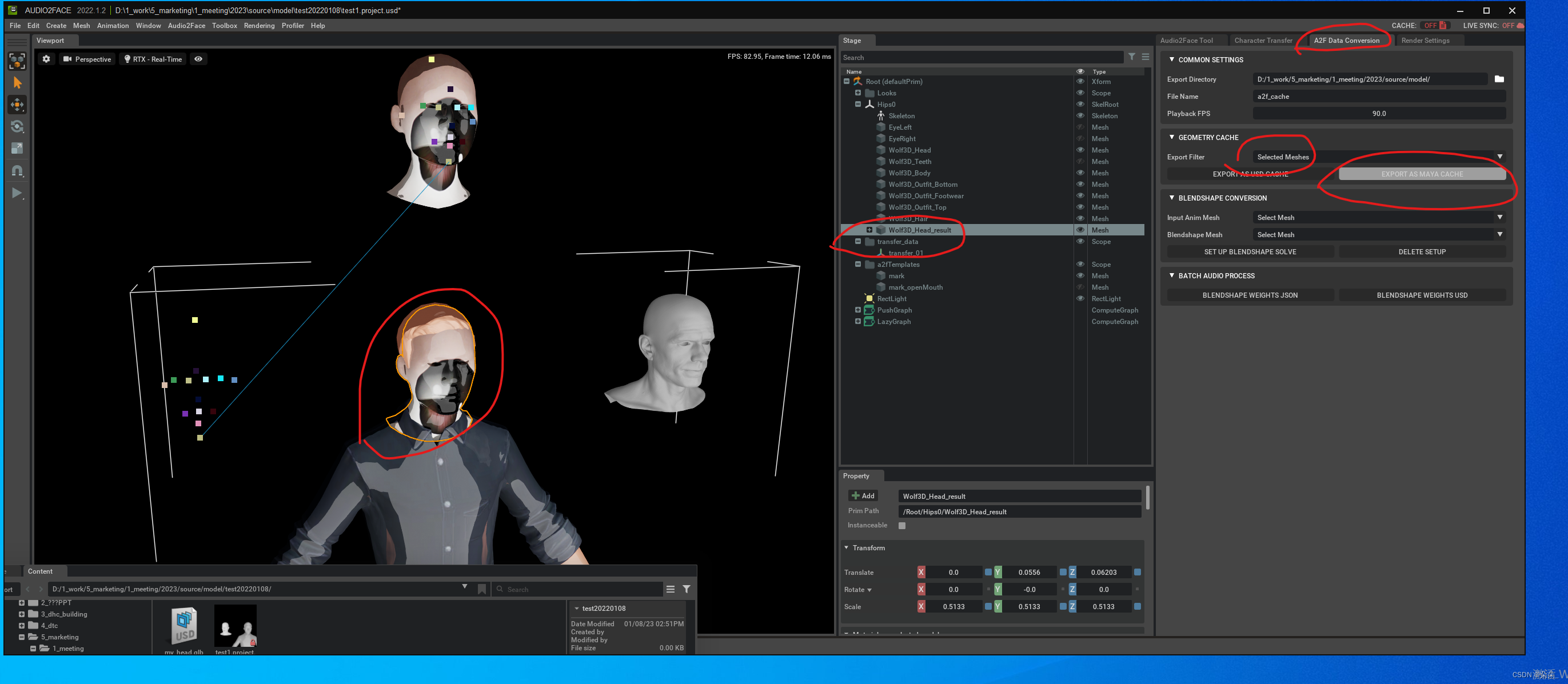
五.导入maya
导入模型
动画模式
添加缓存
添加音频