🔥博客主页: 小羊失眠啦.
🎥系列专栏:《C语言》 《数据结构》 《C++》 《Linux》 《Cpolar》
❤️感谢大家点赞👍收藏⭐评论✍️

文章目录
- 一、默认成员函数
- 二、构造函数
- 构造函数的概念及特性
- 三、析构函数
- 析构函数的特性
- 四、拷贝构造函数
- 拷贝构造函数的特性
一、默认成员函数
上一章中我们谈到,如果一个类中什么成员也没有,那么这个类就叫作空类。其实这么说是不太严谨的,因为一个类不可能什么都没有。
当我们定义好一个类,不做任何处理时,编译器会自动生成以下6个默认成员函数:
默认成员函数:如果用户没有手动实现,则编译器会自动生成的成员函数。
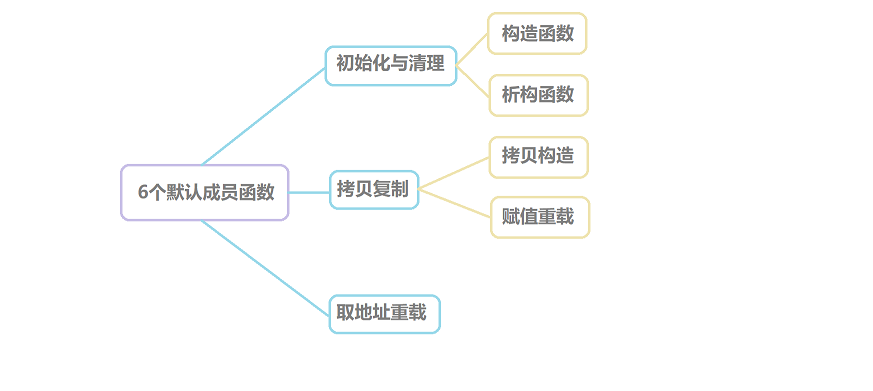
构造函数:主要完成初始化工作;析构函数:主要完成清理工作;拷贝构造:使用一个同类的对象初始化创建一个对象;赋值重载:把一个对象赋值给另一个对象;取地址重载:普通对象取地址操作;取地址重载(const):const对象取地址操作;
本章我们将学习四个默认成员函数——构造函数与析构函数——拷贝构造 与赋值重载
二、构造函数
在C语言阶段,我们实现栈的数据结构时,有一件事很苦恼,就是每当创建一个stack对象(之前叫作定义一个stack类型的变量)后,首先得调用它的专属初始化函数StackInit来初始化对象。
typedef int dataOfStackType;
typedef struct stack
{
dataOfStackType* a;
int top;
int capacity;
}stack;
void StackInit(stack* ps);
//...
int main()
{
stack s;
StackInit(&s);
//...
return 0;
}
这不免让人觉得有点麻烦。在C++中,构造函数为我们很好的解决了这一问题。
构造函数的概念及特性
构造函数是一个特殊的成员函数。构造函数虽然叫作构造,但是其主要作用并不是开辟空间创建对象,而是初始化对象。
构造函数之所以特殊,是因为相比于其它成员函数,它具有如下特性:
- 函数名与类名相同;
- 无返回值;
- 对象实例化时,编译器
自动调用对应的构造函数; - 构造函数可以重载;
举例
class Date
{
public:
//无参的构造函数
Date()
{};
//带参的构造函数
Date(int year,int month,int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
void TestDate()
{
Date d1;//调用无参构造函数(自动调用)
Date d2(2023, 3, 29);//调用带参构造函数(自动调用)
}
特别注意
- 创建对象时编译器会自动调用构造函数,若是
调用无参构造函数,则无需在对象后面使用()。否则会产生歧义:编译器无法确定你是在声明函数还是在创建对象。
错误示例
//错位示例
Date d3();
- 如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦用户显式定义编译器将不再生成。
class Date
{
public:
//若用户没有显示定义,则编译器自动生成。
/*Date(int year,int month,int day)
{
_year = year;
_month = month;
_day = day;
}*/
private:
int _year;
int _month;
int _day;
};
- 默认生成构造函数,对内置类型成员不作处理;对自定义类型成员,会调用它的默认构造函数;
- C++把类型分成
内置类型(基本类型)和自定义类型。内置类型就是语言提供的数据类型,如:int、char、double…,自定义类型就是我们使用class、struct、union等自己定义的类型。
举例
默认构造函数对内置类型
class Date
{
public:
//此处不对构造函数做显示定义,测试默认构造函数
/*Date()
{}*/
void print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
void TestDate1()
{
Date d1;
d1.print();
}

- 如图所示,默认构造函数的确未对内置类型做处理。
默认构造函数对自定义类型
class stack
{
public:
//此处对stack构造函数做显示定义
stack()
{
cout <<"stack()" << endl;
_a = nullptr;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
class queue
{
public:
//此处不对queue构造函数做显示定义,测试默认构造函数
/*queue()
{}*/
private:
//自定义类型成员
stack _s;
};
void TestQueue()
{
queue q;
}

- 如图所示,在创建
queue对象时,默认构造函数对自定义成员_s做了处理,调用了它的默认构造函数stack()。
这一波蜜汁操作让很多C++使用者感到困惑与不满,为什么要针对内置类型和自定义类型做不同的处理呢?终于,在C++11中针对内置类型成员不初始化的缺陷,又打了补丁,即:
- 内置类型成员变量在类中声明时可以给默认值;
举例
class Date
{
public:
//...
void print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
//使用默认值
int _year = 0;
int _month = 0;
int _day = 0;
};
void TestDate2()
{
Date d2;
d2.print();
}

默认值:若不对成员变量做处理,则使用默认值。
- 无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个;
举例
class Date
{
public:
//无参的默认构造函数
//Date()
//{
//}
//全缺省的默认构造函数
Date(int year = 0, int month = 0, int day = 0)
{
_year = year;
_month = month;
_day = day;
}
void print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year = 0;
int _month = 0;
int _day = 0;
};
默认构造函数:
- 无参的构造函数
- 全缺省的构造函数
- C++编译器生成的无参的构造函数
即三种必须要有一种,如果没有默认的构造函数(写的构造函数不是无参的,也不是全缺省的)就会报错
三、析构函数
析构函数与构造函数的特性相似,但功能有恰好相反。构造函数是用来初始化对象的,析构函数是用来销毁对象的。
- 需要注意的是,
析构函数并不是对对象本身进行销毁(因为局部对象出了作用域会自行销毁,由编译器来完成),而是在对象销毁时会自动调用析构函数,对对象内部的资源做清理(例如stack _s中的int* a)。
同样,有了析构函数,我们再也不用担心创建对象(或定义变量)后由于忘记释放内存而造成内存泄漏了。
举例
class Stack
{
public:
Stack()
{
//...
}
void Push(int x)
{
//...
}
bool Empty()
{
// ...
}
int Top()
{
//...
}
void Destory()
{
//...
}
private:
// 成员变量
int* _a;
int _top;
int _capacity;
};
void TestStack()
{
Stack s;
st.Push(1);
st.Push(2);
//过去需要手动释放
st.Destroy();
}
析构函数的特性
- 析构函数名是在类名前加上字符
~; - 无参数;
- 无返回值;
- 一个类只能有一个析构函数。若未显式定义,系统会自动生成默认的析构函数;
- 析构函数不能重载;
举例
class Date
{
public:
Date()
{
cout << "Date()" << endl;
}
~Date()
{
cout << "~Date()" << endl;
}
private:
int _year = 0;
int _month = 0;
int _day = 0;
};
void TestDate3()
{
Date d3;
//d3生命周期结束时自动调用构造函数
}

- 编译器生成的默认析构函数,对自定类型成员调用它的析构函数;
举例
class stack
{
public:
//此处对stack构造函数做显示定义
stack()
{
cout <<"stack()" << endl;
_a = nullptr;
_top = _capacity = 0;
}
~stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
class queue
{
public:
//此处不对queue构造函数做显示定义,测试默认构造函数
/*queue()
{}*/
private:
//自定义类型成员
stack _s;
};
void TestQueue1()
{
queue q;
}

- 这里可能有小伙伴会好奇:
为什么析构函数不像构造函数那样区分内置类型与自定义类型呢?
答案是:因为内置类型压根不需要我们担心清理工作,在其生命周期结束时会自动销毁。而自定义类型需要担心,因为自定义类型里可能含有申请资源(例如:malloc申请内存须手动释放)。
- 如果类中没有申请资源时,析构函数可以不写,直接使用编译器生成的默认析构函数,比如
Date类;有资源申请时,一定要写,否则会造成资源泄漏,比如stack类。
四、拷贝构造函数
同样,拷贝构造函数也属于6个默认成员函数,而且拷贝构造函数是构造函数的一种重载形式。
- 拷贝构造函数的功能就如同它的名字——拷贝。
我们可以用一个已存在的对象来创建一个与已存在对象一模一样的新的对象。
举例
class Date
{
public:
//构造函数
Date()
{
cout << "Date()" << endl;
}
//拷贝构造函数
Date(const Date& d)
{
cout << "Date()" << endl;
_year = d._year;
_month = d._month;
_day = d._day;
}
//析构函数
~Date()
{
cout << "~Date()" << endl;
}
private:
int _year = 0;
int _month = 0;
int _day = 0;
};
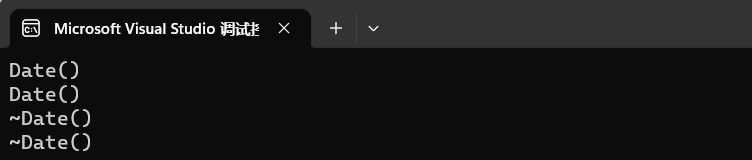
void TestDate()
{
Date d1;
//调用拷贝构造创建对象
Date d2(d1);
}
拷贝构造函数的特性
拷贝构造函数作为特殊的成员函数同样也有异于常人的特性:
- 拷贝构造函数是构造函数的重载;
- 拷贝构造函数的参数只有一个且必须是
类类型对象的引用。若使用传值的方式,则编译器会报错,因为理论上这会引发无穷递归。
错误示例
class Date
{
public:
//错误示例
//如果这样写,编译器就会直接报错,但我们现在假设如果编译器不会检查,
//这样的程序执行起来会发生什么
Date(const Date d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
private:
int _year = 0;
int _month = 0;
int _day = 0;
};
void TestDate()
{
Date d1;
//调用拷贝构造创建对象
Date d2(d1);
}
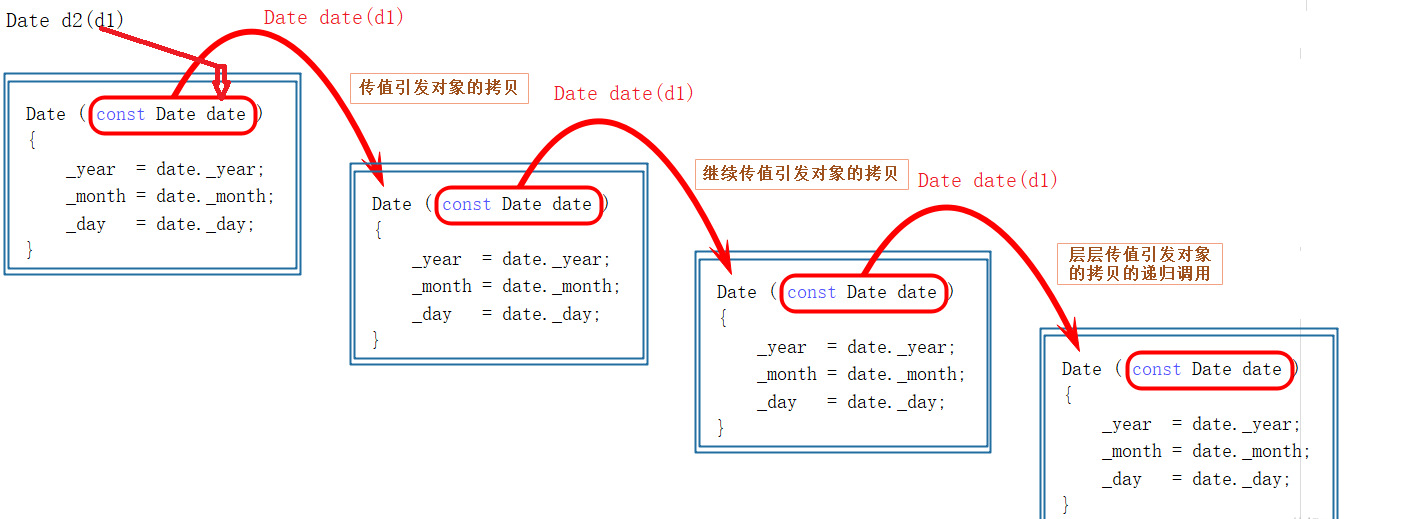
- 当拷贝构造函数的参数采用
传值的方式时,创建对象d2,会调用它的拷贝构造函数,d1会作为实参传递给形参d。不巧的是,实参传递给形参本身又是一个拷贝,会再次调用形参的拷贝构造函数…如此便会引发无穷的递归。
- 若未显式定义,编译器会生成默认的拷贝构造函数。 默认的拷贝构造函数对象按
内存存储按字节序完成拷贝,这种拷贝叫做浅拷贝或者值拷贝;
举例
class Date
{
public:
//构造函数
Date(int year = 0, int month = 0, int day = 0)
{
//cout << "Date()" << endl;
_year = year;
_month = month;
_day = day;
}
//未显式定义拷贝构造函数
/*Date(const Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}*/
void print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year = 0;
int _month = 0;
int _day = 0;
};
void TestDate()
{
Date d1(2023, 3, 31);
//调用拷贝构造创建对象
Date d2(d1);
d2.print();
}

- 有的小伙伴可能会有疑问:编译器默认生成的拷贝构造函数貌似可以很好的完成任务,那么还需要我们手动来实现吗?
答案是:当然需要。Date类只是一个较为简单的类且类成员都是内置类型,可以不需要。但是当类中含有自定义类型时,编译器可就办不了事儿了。
- 类中如果没有涉及资源申请时,拷贝构造函数写不写都可以;一旦涉及到资源申请时,则拷贝构造函数是一定要写的,否则就是浅拷贝;
错误示例
class stack
{
public:
stack(int defaultCapacity=10)
{
_a = (int*)malloc(sizeof(int)*defaultCapacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
_top = 0;
_capacity = defaultCapacity;
}
~stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void push(int n)
{
_a[_top++] = n;
}
void print()
{
for (int i = 0; i < _top; i++)
{
cout << _a[i] << " ";
}
cout << endl;
}
private:
int* _a;
int _top;
int _capacity;
};
void TestStack()
{
stack s1;
s1.push(1);
s1.push(2);
s1.push(3);
s1.push(4);
s1.print();
stack s2(s1);
s2.print();
s2.push(5);
s2.push(6);
s2.push(7);
s2.push(8);
s2.print();
}
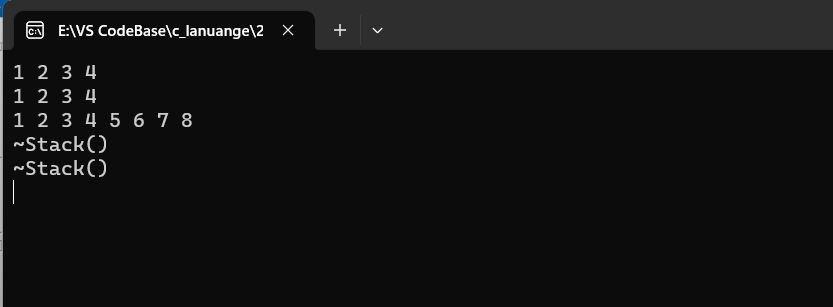
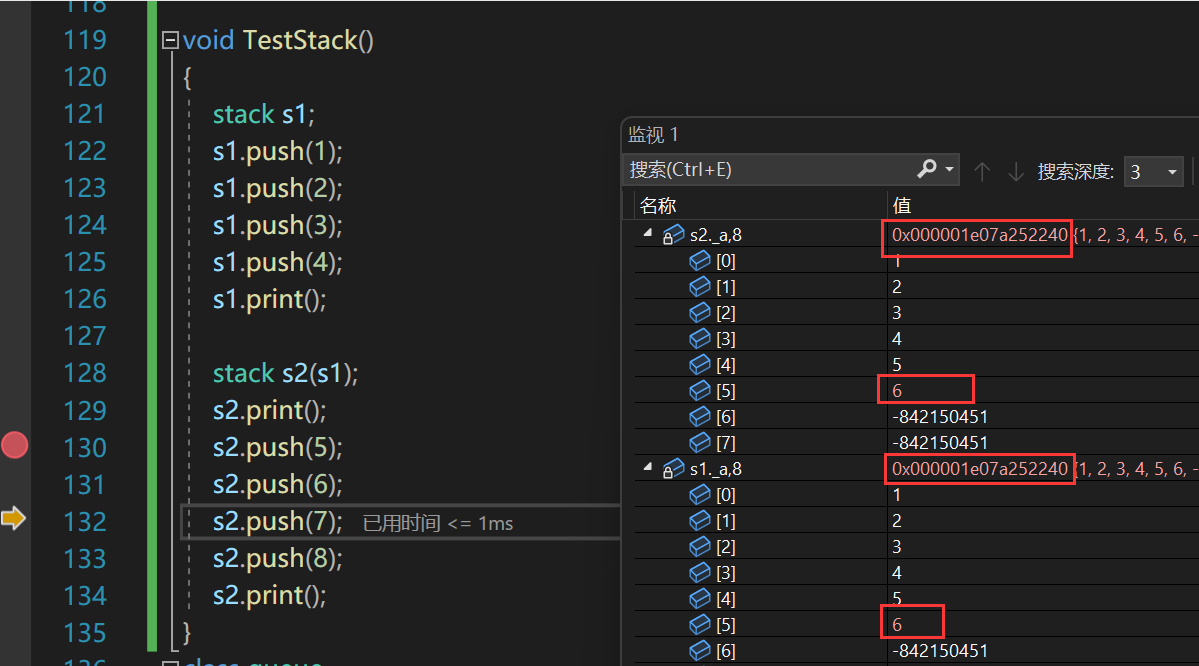
如图所示,这段程序的运行结果是程序崩溃了,且通过观察发现,是在第二次析构时出现了错误。其实出现错误的原因是在第二次析构时对野指针进行free了。
一个小tip
- 多个对象进行析构的顺序如同
栈一样,先创建的对象后析构,后创建的对象先析构。
为什么会出现对野指针进行free呢?
- 原因是,对象
s1与对象s2中的成员_a,指向的是同一块空间。在s2析构完成后,这块空间已经被释放,此时的s1._a就是野指针。这就是浅拷贝导致的后果。
理解浅拷贝
编译器默认生成的拷贝构造函数是按字节序拷贝的,在创建s2对象时,仅仅是把s1._a的值赋值给s2._a,并没有重新开辟一块与s1._a所指向的空间大小相同内容相同的空间。我们把前者的拷贝方式称为浅拷贝,后者称为深拷贝。
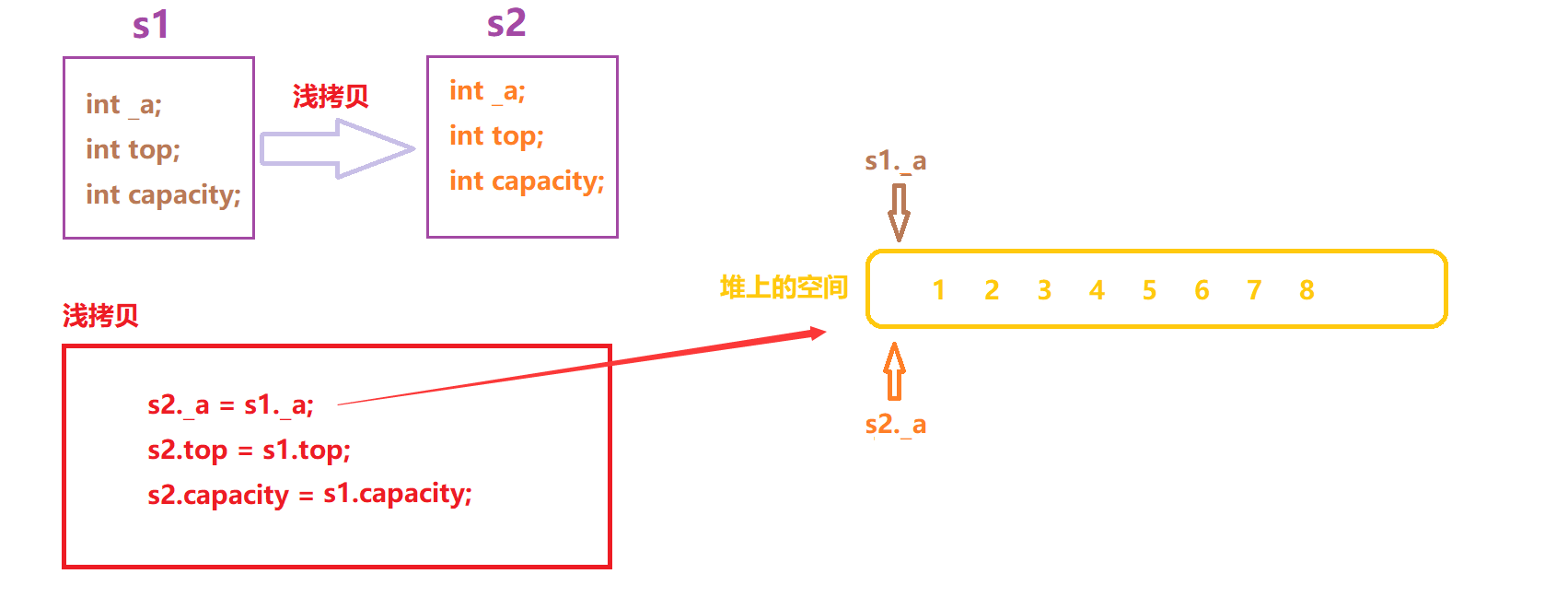
当开启监视窗口来观察这一过程,我们可以看到s2在进行push时,s1的内容也在跟着改变,且s1._a=s2._a:
正确的做法
class stack
{
public:
stack(int defaultCapacity=10)
{
_a = (int*)malloc(sizeof(int)*defaultCapacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
_top = 0;
_capacity = defaultCapacity;
}
//用户自己定义拷贝构造函数
stack(const stack& s)
{
_a= (int*)malloc(sizeof(int) * s._capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
memcpy(_a, s._a, sizeof(int) * s._capacity);
_top = s._top;
_capacity = s._capacity;
}
~stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void push(int n)
{
_a[_top++] = n;
}
void print()
{
for (int i = 0; i < _top; i++)
{
cout << _a[i] << " ";
}
cout << endl;
}
private:
int* _a;
int _top;
int _capacity;
};
- 拷贝构造函数典型调用场景:
- 使用已存在对象创建新对象;
- 函数参数类型为类类型对象;
- 函数返回值类型为类类型对象。
为了提高程序效率,一般对象传参时,尽量使用引用类型,返回时根据实际场景,能用引用尽量使用引用。









![[计算机网络]--I/O多路转接之poll和epoll](https://img-blog.csdnimg.cn/direct/af5a1f8d957f4f8da99d2015b10482bb.png)