数组
- 1. 前言
- 2. 一维数组的创建和初始化
- 3. 一维数组的使用
- 4. 一维数组在内存中的存储
- 5. 二维数组的创建和初始化
- 6. 二维数组的使用
- 7. 二维数组在内存中的存储
- 8. 数组越界
- 9. 数组作为函数参数
- 10. 综合练习
- 10.1 用函数初始化,逆置,打印整型数组
- 10.2 交换两个整型数组
- 10.3 三子棋
- 10.4 扫雷

1. 前言
大家好,我是努力学习游泳的鱼。今天我们来学习数组。

数组分为一维数组和二维数组,我们需要学习它们如何创建和初始化,如何使用,如何在内存中存储。话不多说,让我们开始对数组的学习吧。
2. 一维数组的创建和初始化
数组是一组相同类型元素的集合。
一维数组的创建格式如下:
数组的元素类型 数组名[常量表达式];
int arr[100]; // 表示数组能存放100个int类型的数据
我们使用大括号来初始化数组。
完全初始化:对数组的所有元素都进行初始化。大括号里初始化的元素个数和数组最多存放的元素个数相同。
int arr[10] = {1,2,3,4,5,6,7,8,9,10}; // 完全初始化:数组最多存放10个元素,大括号内初始化了10个元素
不完全初始化:只初始化数组的部分元素,剩下的被初始化成0。
int arr[100] = {0}; // 不完全初始化:第一个元素被手动初始化成0,剩下的元素默认被初始化为0
如果对数组初始化,数组大小可以省略,默认为初始化元素的个数。如下面两种写法效果是相同的。
int arr[5] = {1,2,3,4,5};
int arr[] = {1,2,3,4,5}; // 省略数组大小,默认是5
如果创建数组时不初始化,则数组大小不能省略,此时分为两种情况:
- 局部数组里存放的都是随机值。
- 全局数组会被默认初始化为
0。
int arr1[10]; // 默认初始化为0
int main()
{
int arr2[10]; // 存储的是随机值
return 0;
}
对于一个变量,这两种情况也成立。
- 当一个局部变量不初始化时,存储的是随机值。
- 当一个全局变量或静态变量不手动初始化时,会被默认初始化成
0。
int a; // 默认初始化为0
int main()
{
static int b; // 默认初始化为0
int c; // 存储的是随机值
return 0;
}
本质上,这是存储位置的差异导致的。局部变量是存储在栈区的,栈区上的数据如果不初始化,存储的是随机值。全局变量和静态变量是存储在静态区的,静态区上的数据如果不手动初始化,会被默认初始化为0。
C99中引入了变长数组的概念,允许数组的大小用变量来指定,如果编译器不支持C99中的变长数组,那就不能使用。
int n = 10;
int arr[n]; // 变长数组
变长数组不能初始化。
int n = 10;
int arr[n] = {0}; // 不能像这样初始化
3. 一维数组的使用
数组通过下标来访问,数组的下标是从
0开始的。
[]是下标引用操作符。
比如,int arr[] = {10,20,30,40,50};,10的下标是0,20的下标是1,30的下标是2,40的下标是3,50的下标是4。
那么,arr[3]对应的就是40,如果我们想把40改成400,就这么写:arr[3] = 400;
我们如何计算数组的元素个数呢?很简单,用数组的总大小除以数组一个元素的大小就行了。比如对于arr数组,数组元素个数sz就可以这么算:int sz = sizeof(arr) / sizeof(arr[0]);
假设我们想存储1~100的整数并打印出来,就可以这么写:
#include <stdio.h>
int main()
{
int arr[100] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (; i < sz; ++i)
{
arr[i] = i + 1;
}
for (i = 0; i < sz; ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
4. 一维数组在内存中的存储
一维数组在内存中是连续存放的。
随着数组下标的增长,地址是由低到高变化的。
我们可以写个程序来验证。
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (; i < sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}
我们把数组元素的地址按照下标从低到高打印出来。
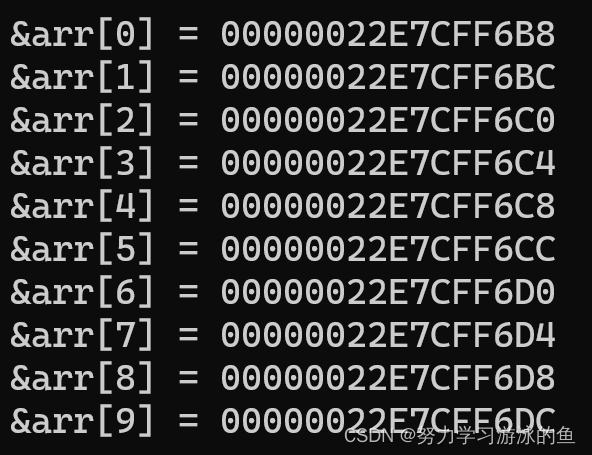
我们发现,相邻两个元素之间的地址都差4,这是因为数组在内存中是连续存放的,相邻元素的地址就差一个int,即4个字节。
并且,随着下标的增长,地址是由低到高变化的。
5. 二维数组的创建和初始化
如我们想要创建一个三行五列的二维整型数组,就可以这么写:int arr[3][5];这个数组有三行五列,共15个元素,每个元素是int类型的。
int int int int int
int int int int int
int int int int int
对二维数组进行初始化要使用大括号,初始化时会一行一行放,一行放满后才会放下一行。若是不完全初始化,剩余元素会被默认初始化成0。
如:int arr[3][5] = { 1,2,3,4,5,6 };的效果是:
1 2 3 4 5
6 0 0 0 0
0 0 0 0 0
由于二维数组的每一行都可以看作一个一维数组,如果要对每一行分别初始化,可以在大括号里使用大括号。
这么说有点抽象,举个例子:int arr[3][5] = { {1,2}, {3,4}, {5,6} };的效果是:
1 2 0 0 0
3 4 0 0 0
5 6 0 0 0
如果对二维数组初始化,二维数组的行可以省略,但是列不能省略。如果省略二维数组的行,编译器会根据初始化的内容来确定有几行。
如:int arr[][5] = {1,2,3,4,5,6};的效果是:
1 2 3 4 5
6 0 0 0 0
由于两行就够放了,编译器会默认行数为2。
再比如:int arr[][5] = { {1,2}, {3,4}, {5,6} };的效果是:
1 2 0 0 0
3 4 0 0 0
5 6 0 0 0
由于3行就够放了,编译器会默认行数为3。
如果我们想给数组的所有元素都初始化成0,就可以这么写:
int arr[3][5] = {0};数组的第一个元素被初始化成0,剩下的元素会被默认初始化成0,效果是,数组的全部元素都被初始化成0。
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
6. 二维数组的使用
二维数组也是用下标来访问的。和一维数组的区别是,二维数组有两个下标,行标和列标。行标和列标都是从0开始的。比如说,一个3行5列的数组arr,每个位置的元素的访问方式如下:
arr[0][0] arr[0][1] arr[0][2] arr[0][3] arr[0][4]
arr[1][0] arr[1][1] arr[1][2] arr[1][3] arr[1][4]
arr[2][0] arr[2][1] arr[2][2] arr[2][3] arr[2][4]
如果我们想把这些元素打印出来,可以用一层循环产生行标,另一层循环产生列标。每行打印完后,记得换个行。
#include <stdio.h>
int main()
{
int arr[3][5] = { {1,2,3,4,5}, {2,3,4,5,6}, {3,4,5,6,7} };
int i = 0;
for (; i < 3; ++i)
{
int j = 0;
for (; j < 5; ++j)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
当然,二维数组有几行几列也是可以通过代码计算出来的。
计算行数的方法:sizeof(arr) / sizeof(arr[0]);即数组的总大小除以数组第一行元素的大小。
计算列数的方法:sizeof(arr[0]) / sizeof(arr[0][0]);即数组第一行元素的大小除以数组第一行第一列的元素的大小。
上面的代码就可这样改进:
#include <stdio.h>
int main()
{
int arr[3][5] = { {1,2,3,4,5}, {2,3,4,5,6}, {3,4,5,6,7} };
int i = 0;
for (; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
int j = 0;
for (; j < sizeof(arr[0]) / sizeof(arr[0][0]); ++j)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
7. 二维数组在内存中的存储
我们用下面的程序把二维数组每个元素的地址打印出来。
#include <stdio.h>
int main()
{
int arr[3][5] = { 0 };
int i = 0;
for (; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
int j = 0;
for (; j < sizeof(arr[0]) / sizeof(arr[0][0]); ++j)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}
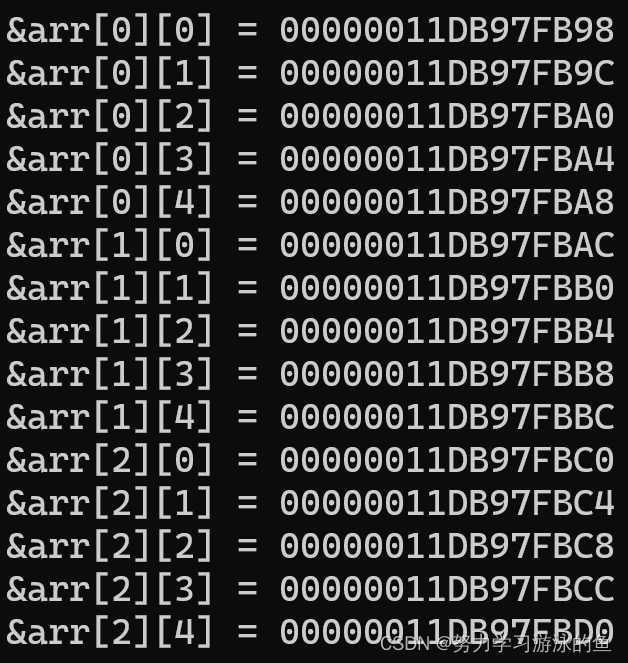
我们发现,每两个元素之间都差4个字节,每当发生换行,如第一行最后一个元素arr[0][4]到第二行第一个元素arr[1][0]也差4个字节。arr是一个整型数组,每两个元素之间差1个int类型的大小。这说明:
二维数组在内存中也是连续存放的。
随着下标的增长,地址也是由低到高变化的。
除此之外,我们还可以把二维数组的每个元素理解成一维数组。如:对于三行五列的二维数组arr,arr[0]就是这个二维数组的第一个元素,同时arr[0]也是一个有五个元素的一维数组,这五个元素分别是arr[0][0],arr[0][1],arr[0][2],arr[0][3],arr[0][4]。
8. 数组越界
数组的下标是有范围限制的。
数组的下标规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,最好自己做越界的检查。
如下面的程序,当i为10时就越界了。
int main()
{
int arr[10] = {0};
int i = 0;
for (; i<=10; ++i)
{
arr[i] = i;
}
return 0;
}
二维数组的行和列也可能存在越界。
9. 数组作为函数参数
数组名表示什么?看看下面的代码:
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
printf("arr = %p\n", arr);
printf("arr + 1 = %p\n", arr + 1);
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0] + 1 = %p\n", &arr[0] + 1);
printf("&arr = %p\n", &arr);
printf("&arr + 1 = %p\n", &arr + 1);
printf("sizeof(arr) = %d\n", sizeof(arr));
return 0;
}
运行结果:

由运行结果可知,数组名(arr)和数组首元素地址(&arr[0])是完全相同的,且+1之后也是完全相同的,都跳过了4个字节(1个int)。数组的地址(&arr)和前两者值是相同的,但+1之后跳过了40个字节(即跳过了整个数组),这是因为,如果写arr或&arr[0]都表示首元素地址,即第一个整型元素的地址,+1会跳过一个整型;如果写&arr,取出的是整个数组的地址,+1自然也跳过了整个数组。注意:以上所有计算都是十六进制的计算,如所谓的跳过40个字节其实是+0x28,再转换成十进制后得到的40。
并且,sizeof(arr)计算的是整个数组的大小,即40。
数组名一般表示数组首元素的地址。但是有两个例外:
- sizeof(数组名),数组名不是数组首元素的地址,数组名表示整个数组,计算的是整个数组的大小。
- &数组名,数组名不是数组首元素的地址,数组名表示整个数组,取出的是整个数组的地址。
题目:写一个函数,对一个整型数组进行冒泡排序。
冒泡排序:对数组中
2个相邻的元素进行比较,如果不满足就交换。
比如,一个数组里存放的是
9 8 7 6 5 4 3 2 1 0
我想把它排成升序,也就是左边的数要比右边的数小。
首先比较9和8,因为9比8大,不满足升序,就交换。
8 9 7 6 5 4 3 2 1 0
接着比较9和7,因为9比7大,不满足升序,就交换。
8 7 9 6 5 4 3 2 1 0
接着比较9和6,因为9比6大,不满足升序,就交换。
8 7 6 9 5 4 3 2 1 0
……
这一趟冒泡排序下来,数组就排序成
8 7 6 5 4 3 2 1 0 9
9的位置就正确了。接下来进行下一趟冒泡排序。由于9的位置处在正确的位置上,下一趟冒泡排序就不需要考虑9了,只需排序除了9之外的数字。
首先比较8和7,因为8比7大,不满足升序,就交换。
7 8 6 5 4 3 2 1 0 9
接着比较8和6,因为8比6大,不满足升序,就交换。
7 6 8 5 4 3 2 1 0 9
……
这一趟冒泡排序下来,数组就排序成
7 6 5 4 3 2 1 0 8 9
8的位置就正确了。
有没有发现,一趟冒泡排序,可以使一个数字的位置正确。那么,假设有10个数字,总共需要几趟冒泡排序呢?答案:10个数字需要9趟冒泡排序。因为一趟冒泡排序搞定一个数字,9趟冒泡排序就搞定9个数字,最后一个数字的位置自然也是正确的。
那么一趟内部又需要多少次比较呢?假设有10个数字,第一趟就需要比较9次,第一趟结束后就搞定了其中一个数字,只需排序剩下9个数字,所以第二趟需要比较8次。由于每趟排序都能够搞定一个数字,每趟排序都会比上一趟少一次比较,这样就知道每一趟需要几次比较了。
有了以上的分析,我们需要写两层循环。外层循环负责控制冒泡排序的趟数,假设数组有sz个元素,就需要排序sz-1趟;内层循环控制一趟内部冒泡排序的比较,第一趟需要sz-1次比较,第二趟需要sz-2次比较,后面每趟都比前一趟少一次比较,如果外层循环的循环变量(假设是i)是从0开始的,那第i趟就需要sz-1-i次比较。
如果一趟比较完后没有发生交换,则数组就已经有序了,就不需要继续排序了。我们可以定义一个flag并初始化为1,假设数组已经有序。如果发生交换,则把flag改成0。如果一趟冒泡排序中没有发生交换,则flag仍然是1,就已经有序了,不需要继续排序了。
数组元素个数怎么知道呢?一定要在数组创建的局部范围内计算数组的元素个数int sz = sizeof(arr) / sizeof(arr[0]);因为如果传参给别的函数后,我们使用数组名传参,由前面的知识可知,数组名表示数组首元素的地址,传递过去的是一个指针,所以sizeof(arr)就是4或者8,sizeof(arr) / sizeof(arr[0])这个表达式是无法计算出数组元素个数的。
#include <stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (; i < sz - 1; ++i)
{
// 一趟冒泡排序
int flag = 1; // 假设已经有序
int j = 0;
for (; j < sz - 1 - i; ++j)
{
if (arr[j] > arr[j + 1])
{
flag = 0;
// 交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (1 == flag)
return;
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
// 冒泡排序
bubble_sort(arr, sz);
int i = 0;
for (; i < sz; ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
当然,就一种情况是无法代表所有场景的。我写了个测试代码,在不同场景下测试这个冒泡排序是否正确,供大家参考。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int test_bubble_sort()
{
srand((unsigned int)time(NULL));
const int sz = 100; // 数组元素个数
int* arr = (int*)malloc(sz * sizeof(int));
if (NULL == arr)
{
perror("test_bubblesort::malloc");
return 0;
}
int i = 0;
for (; i < 1000; ++i)
{
// 生成随机数组
int j = 0;
for (; j < sz; ++j)
{
arr[j] = rand();
}
// 冒泡排序
bubble_sort(arr, sz);
// 检验排序是否成功
for (j = 0; j < sz - 1; ++j)
{
if (arr[j] > arr[j + 1])
{
free(arr);
return 0; // 排序失败
}
}
}
free(arr);
return 1; // 检验成功
}
int main()
{
int ret = test_bubble_sort();
if (1 == ret)
printf("检验成功\n");
else
printf("检验失败\n");
return 0;
}
10. 综合练习
10.1 用函数初始化,逆置,打印整型数组
初始化和打印应该相当简单了吧,只需要产生所有的下标,遍历数组,就能够访问整个数组并初始化或打印了。唯一需要注意的是,整型数组无法在函数内部使用sizeof(arr) / sizeof(arr[0])计算元素个数,因为数组作为函数参数传递时,传递的是首元素的地址。
初始化函数(假设初始化为全0):
void init(int arr[], int sz)
{
int i = 0;
for (; i < sz; ++i)
{
arr[i] = 0;
}
}
打印函数:
#include <stdio.h>
void print(int arr[], int sz)
{
int i = 0;
for (; i < sz; ++i)
{
printf("%d ", arr[i]);
}
printf("\n");
}
接下来讲讲如何逆置。类似字符串的逆置,整型数组的逆置只需交换第一个元素和最后一个元素,再交换第二个元素和倒数第二个元素,接着交换第三个元素和倒数第三个元素……
如果用下标来访问数组,我们需要一个左下标left指向第一个元素,一个右下标right指向最后一个元素,交换后,left向后走,right向前走,当left还在right左边时,说明还有元素可以交换,否则就跳出循环。
void reverse(int arr[], int sz)
{
int left = 0;
int right = sz - 1;
while (left < right)
{
int tmp = arr[left];
arr[left] = arr[right];
arr[right] = tmp;
++left;
--right;
}
}
10.2 交换两个整型数组
如何交换两个整型数组arr1和arr2(假设两个数组一样大)呢?
很简单,只需要遍历两个数组,把对应位置的元素交换就行了!
#include <stdio.h>
int main()
{
int arr1[] = { 1,3,5,7,9 };
int arr2[] = { 2,4,6,8,0 };
int i = 0;
int sz = sizeof(arr1) / sizeof(arr1[0]);
printf("交换前:\n");
printf("arr1: ");
for (i = 0; i < sz; ++i)
{
printf("%d ", arr1[i]);
}
printf("\narr2: ");
for (i = 0; i < sz; ++i)
{
printf("%d ", arr2[i]);
}
printf("\n");
// 交换arr1和arr2
for (i = 0; i < sz; ++i)
{
int tmp = arr1[i];
arr1[i] = arr2[i];
arr2[i] = tmp;
}
printf("交换后:\n");
printf("arr1: ");
for (i = 0; i < sz; ++i)
{
printf("%d ", arr1[i]);
}
printf("\narr2: ");
for (i = 0; i < sz; ++i)
{
printf("%d ", arr2[i]);
}
printf("\n");
return 0;
}
10.3 三子棋
我们可以用已有的知识,实现一个三子棋小游戏。详细讲解戳这里
10.4 扫雷
再来实现一个扫雷小游戏。详细讲解戳这里
![[计算机网络]--I/O多路转接之poll和epoll](https://img-blog.csdnimg.cn/direct/af5a1f8d957f4f8da99d2015b10482bb.png)