图神经网络实战——图论基础
- 0. 前言
- 1. 图属性
- 1.1 有向图和无向图
- 1.2 加权图和非加权图
- 1.3 连通图和非连通图
- 1.4 其它图类型
- 2. 图概念
- 2.1 基本对象
- 2.2 图的度量指标
- 2.2 邻接矩阵表示法
- 3. 图算法
- 3.1 广度优先搜索
- 3.2 深度优先搜索
- 小结
- 系列链接
0. 前言
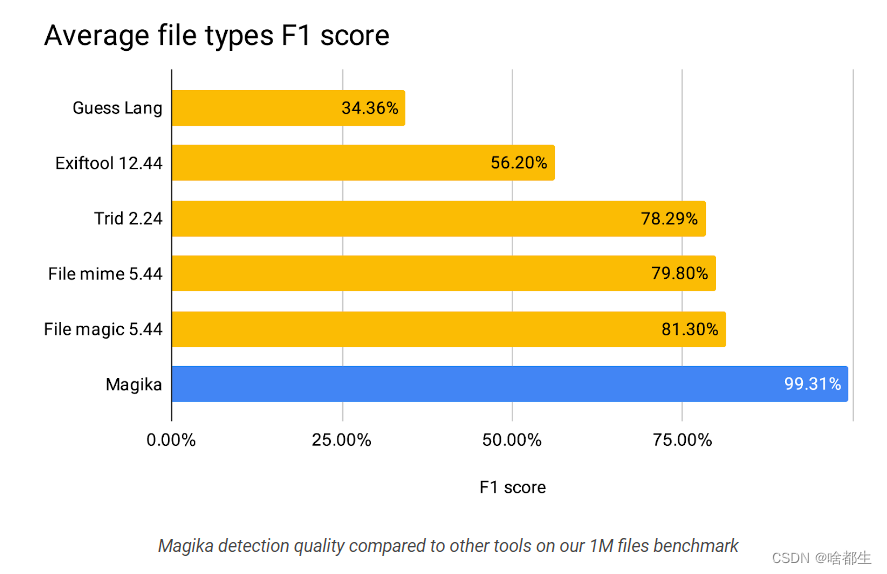
图论 (Graph theory) 是数学的一个基本分支,涉及对图研究。图是复杂数据结构的可视化表示,有助于理解不同实体之间的关系。图论提供了大量建模和分析现实问题的工具,如交通系统、社交网络和互联网等。
在本节中,将介绍图论的基本原理,主要涉及三个方面:图属性、图概念和图算法。首先,我们将定义图及其组成部分;然后,我们将介绍不同类型的图,并分析它们的属性和应用。接下来,我们将介绍基本的图概念,包括邻接矩阵等;最后,将深入介绍图算法,重点包括广度优先搜索 (breadth-first search, BFS) 和深度优先搜索 (depth-first search, DFS)。
1. 图属性
在图论中,图 (Graph) 是一种数学结构,由一组对象(称为顶点或节点)和一组连接顶点对的连接(称为边)组成。使用符号
G
=
(
V
,
E
)
G = (V,E)
G=(V,E) 表示图,其中
G
G
G 是图、
V
=
{
v
1
,
v
2
,
.
.
.
,
v
i
,
.
.
.
v
n
}
V=\{v_1, v_2,...,v_i,...v_n\}
V={v1,v2,...,vi,...vn} 是顶点集、
E
{
e
1
,
e
2
,
.
.
.
,
e
i
,
.
.
.
e
m
}
E\{e_1, e_2,...,e_i,...e_m\}
E{e1,e2,...,ei,...em} 是边集,
v
i
v_i
vi表示节点
i
i
i,
e
i
j
=
(
v
i
,
v
j
)
e_{ij}=(v_i,v_j)
eij=(vi,vj) 表示连接节点
i
i
i 和节点
j
j
j 之间的边。
图中的节点可以代表任何对象,例如城市、人物、网页或分子,而边则代表它们之间的关系或联系,如城市道路、社会关系、超链接或化学键。
1.1 有向图和无向图
如果图中的边都存在方向性,则称这样的边为有向边
e
i
j
=
<
v
i
,
v
j
>
e_{ij}=<v_i,v_j>
eij=<vi,vj>,这意味着边以特定的方向连接两个节点,其中节点
v
i
v_i
vi 是这条有向边的起点,节点
v
j
v_j
vj 是这条有向边的终点,包含有向边的图称为有向图 (directed graph)。相对应的,无向图 (undirected graph) 的边是无向的,即边没有方向。这意味着两个顶点之间的边可以朝任意方向遍历,访问节点的顺序并不重要,也可以认为无向边是对称的,同时包含两个方向:
e
i
j
=
<
e
i
,
e
j
>
=
e
j
i
=
<
e
j
,
e
i
>
e_{ij}=<e_i,e_j>=e_{ji}=<e_j,e_i>
eij=<ei,ej>=eji=<ej,ei>。
在 Python 中,可以使用 networkx 库的 nx.Graph() 定义无向图:
import networkx as nx
from matplotlib import pyplot as plt
G = nx.Graph()
G.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'F'), ('C', 'G')])
nx.draw_networkx(G)
plt.show()

使用 networkx 库创建有向图只需将 nx.Graph() 替换为 nx.DiGraph():
DG = nx.DiGraph()
DG.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'F'), ('C', 'G')])
nx.draw_networkx(DG)
plt.show()
在有向图中,边通常用箭头表示其方向,如下图所示。

1.2 加权图和非加权图
图的另一个重要属性是边是加权的还是非加权的。在加权图 (weighted graph) 中,每条边都有相关的权重,一般情况下,我们可以将权重抽象为两个节点之间的连接强度。这些权重可以代表不同性质,如距离、旅行时间或成本。
例如,在一个交通网络中,边的权重可能代表不同城市之间的距离或在这些城市之间旅行所需的时间。相对应的,非加权图 (unweighted graph) 的边没有权重,这类图通常用于节点间关系为二元关系的情况,边只表示节点间是否存在连接。
可以修改上一小节的无向图,为边添加权重。在 networkx 中,图的边用一个包含起点和终点节点的元组以及一个指定边权重的字典来定义的:
WG = nx.Graph()
WG.add_edges_from([('A', 'B', {"weight": 10}), ('A', 'C', {"weight": 20}),
('B', 'D', {"weight": 30}), ('B', 'E', {"weight": 40}),
('C', 'F', {"weight": 50}), ('C', 'G', {"weight": 60})])
labels = nx.get_edge_attributes(WG, 'weight')
nx.draw_networkx(WG)
nx.draw_networkx_edge_labels(WG, pos=nx.spring_layout(WG), edge_labels=labels)
plt.show()

1.3 连通图和非连通图
图的连通性是图论中的一个基本概念,与图的结构和功能密切相关。在连通图 (connected graph) 中,图中任意两个顶点之间都有一条路径。从形式上看,当且仅当对于图中的每一对顶点
v
i
v_i
vi 和
v
j
v_j
vj,都存在一条从
v
i
v_i
vi 到
v
j
v_j
vj 的路径时,该图才是连通的。 相反,如果一个图不连通,即至少有两个顶点之间没有路径连接(即图中存在孤立的点),则该图是非连通图 (connected graph)。
networkx 库提供了一个内置函数,用于验证图形是否连通。在以下示例中,第一个图包含孤立节点 (4 和 5),与第二个图不同:
g1 = nx.Graph()
g1.add_edges_from([(1, 2), (2, 3), (3, 1), (4, 5)])
print(f"Is graph 1 connected? {nx.is_connected(g1)}")
g2 = nx.Graph()
g2.add_edges_from([(1, 2), (2, 3), (3, 1), (1, 4)])
print(f"Is graph 2 connected? {nx.is_connected(g2)}")
plt.subplot(121)
nx.draw_networkx(g1, pos=nx.spring_layout(g1))
plt.subplot(122)
nx.draw_networkx(g2, pos=nx.spring_layout(g2))
plt.show()
代码输出结果如下:
Is graph 1 connected? False
Is graph 2 connected? True
由于节点 4 和 5 的存在,第一个图是非连通的,而第二个图没有孤立节点,因此是连通的。

连通图许多有趣的特性和应用。例如,在通信网络中,连通图可以确保任何两个节点都能相互通信。相反,非连通图中存在孤立的节点,这些节点无法与网络中的其他节点通信,这为设计高效路由算法带来了挑战。
判断图形连通性的方法多种多样。最常见的一种判断方法是,使得图不再连通需要移除的最少边数,称为图的最小割。最小切割问题在网络流量优化、聚类和群落检测方面有多种应用。
1.4 其它图类型
除了常用的图类型外,还有一些具有独特属性和特征的特殊图类型:
- 树 (
Tree):一种连通的、无向、无循环的图。由于树中任意两个节点之间只有一条路径,因此树是一类特殊的图。树通常用于模拟层次结构,如家族树、组织结构或分类树 - 有根树 (
Rooted tree):树上有一个节点被指定为根,其他节点都通过唯一的路径与之相连。计算机科学中常用有根树来表示层次数据结构,如文件系统或 XML 文档的结构 - 有向无环图 (
Directed acyclic graph,DAG):一种没有循环的有向图,其中边只能沿特定方向遍历,不存在循环。DAG通常用于模拟任务或事件之间的依赖关系,例如项目管理或计算工作的关键路径 - 二部图 (
bipartite graph):顶点可分为两个不相交集合的图,所有边都连接不同集合中的顶点。数学和计算机科学中经常使用二部图来模拟两类不同对象之间的关系,如用户和商品、作者和作品 - 完全图 (
complete graph):每对顶点都由一条边连接的图。在组合学中,完全图常用于模拟涉及成对连接的问题;在计算机网络中,完整图常用于模拟完全连接的网络。
下图展示了上述不同类型的图:

2. 图概念
在本节中,我们将介绍图论中的一些基本概念,包括图对象(如度和邻居)、图度量(如中心性和密度)以及邻接矩阵表示法。
2.1 基本对象
图论中的一个关键概念是节点的度 (degree),即与该节点相连的边的数量。如果某节点是一条边的端点,则称该边与该节点关联。节点
v
v
v 的度通常用
d
e
g
(
v
)
deg(v)
deg(v) 表示:
- 在无向图中,节点的度是与之相连的边的数量。如果节点与自身相连(称为循环或自循环),则度数会增加
2 - 在有向图中,度分为两种:入度 (
indegree) 和出度 (outdegree)。节点的入度(用 d e g − ( v ) deg^-(v) deg−(v) 表示)代表指向该节点的边的数量;而出度(用 d e g + ( v ) deg^+(v) deg+(v) 表示)代表从该节点出发的边的数量。在这种情况下,一个自循环会使入度和出度分别增加1
入度和出度对于分析和理解有向图至关重要,因为它们可以帮助我们了解信息或资源在图中的分布情况。例如,入度高的节点可能是重要的信息或资源的重要目的地。相反,出度高的节点可能是信息或资源来源。
在 networkx 中,可以使用内置方法计算节点度、入度或出度:
G = nx.Graph()
G.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'F'), ('C', 'G')])
print(f"deg(A) = {G.degree['A']}")
DG = nx.DiGraph()
DG.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'F'), ('C', 'G')])
print(f"deg^-(A) = {DG.in_degree['A']}")
print(f"deg^+(A) = {DG.out_degree['A']}")
输出结果如下所示:
deg(A) = 2
deg^-(A) = 0
deg^+(A) = 2
在以上有向图中,节点与两条边相连 (
d
e
g
(
a
)
=
d
e
g
+
(
a
)
=
2
deg(a)=deg^+(a)=2
deg(a)=deg+(a)=2),但不是其中任何一条边的目的节点
(
d
e
g
−
(
a
)
=
0
(deg^-(a)=0
(deg−(a)=0)。
节点邻居的概念与节点度密切相关,如果存在一条边连接
v
i
v_i
vi 和
v
j
v_j
vj,则称
v
j
v_j
vj 是
v
i
v_i
vi 的邻居 (neighbor),反之亦然。如果两个结点
v
i
v_i
vi 和
v
j
v_j
vj 是边
e
e
e 的端点,则称
v
i
v_i
vi 与
v
j
v_j
vj 互为邻接点 (adjacent point)。邻居和邻接的概念是许多图算法的基础,例如在两个节点之间搜索路径或识别网络中的集群。
在图论中,路径 (path) 是连接图中两个(或多个)节点的边序列。路径的长度是沿路径遍历的边的数量。路径有多种类型,其中以下两种路径尤为重要:
- 简单路径 (
simple path):不重复经过任何节点(除起点和终点外)的路径 - 循环(
cycle):首尾节点相同的路径。如果一个图不包含循环(如树和 DAG),则称其为非循环图
度和路径可用于确定节点在网络中的重要性,这种度量被称为中心性 (centrality)。
2.2 图的度量指标
中心性量化了图中节点的重要性,可以根据节点的连通性以及对图内信息流或互动的影响来识别图中的关键节点。中心度有多种度量方法,每种方法都能从不同角度反映节点的重要性:
- 度中心性 (
Degree centrality):最简单、最常用的中心性度量方法之一,其定义为节点的度数。度中心性越高,表明节点与图中其他节点的连接程度越高,因此对网络的影响越大 - 接近中心性(
Closeness centrality):衡量一个节点与图中所有其他节点的接近程度,它相当于目标节点与图中所有其他节点之间最短路径的平均长度。接近中心性高的节点可以快速到达网络中的所有其他节点 - 中介中心性 (
Betweenness centrality):衡量一个节点位于图中其他节点对之间最短路径上的次数。具有高中介中心性的节点是图中不同部分之间的瓶颈或桥梁
可以使用 networkx 的内置函数计算图中的这些度量指标并分析结果:
print(f"Degree centrality = {nx.degree_centrality(G)}")
print(f"Closeness centrality = {nx.closeness_centrality(G)}")
print(f"Betweenness centrality = {nx.betweenness_centrality(G)}")
输出结果如下所示,字典中包含每个节点的得分:
Degree centrality = {'A': 0.3333333333333333, 'B': 0.5, 'C': 0.5, 'D': 0.16666666666666666, 'E': 0.16666666666666666, 'F': 0.16666666666666666, 'G': 0.16666666666666666}
Closeness centrality = {'A': 0.6, 'B': 0.5454545454545454, 'C': 0.5454545454545454, 'D': 0.375, 'E': 0.375, 'F': 0.375, 'G': 0.375}
Betweenness centrality = {'A': 0.6, 'B': 0.6, 'C': 0.6, 'D': 0.0, 'E': 0.0, 'F': 0.0, 'G': 0.0}
图中节点 A、B 和 C 的重要性取决于所使用的中心度类型。度中心性认为节点 B 和 C 比节点 A 更重要,因为它们有更多的邻居。而节点 A、B 和 C 具有相同的中介中心性,因为它们都位于许多其他节点之间的最短路径上。
密度 (density) 是另一个重要的度量指标,它度量了图的连接程度,是图中实际边数与最大可能边数之间的比值。与密度低的图相比,密度高的图通常连通性更强,信息流动更多。
密度的计算公式取决于图是有向图还是无向图。对于有
n
n
n 个节点的无向图,最大可能的边数是
n
(
n
−
1
)
2
\frac {n(n-1)} 2
2n(n−1);对于有
n
n
n 个节点的有向图,边的最大可能数量为
n
(
n
−
1
)
n(n-1)
n(n−1)。
图密度的计算方法是边数除以最大边数。例如,下图中的图有 6 条边,最大可能的边数为
7
(
7
−
1
)
2
=
21
\frac {7(7 - 1)}2 = 21
27(7−1)=21 条。因此,该图的密度为
6
21
≈
0.2857
\frac 6 {21} ≈ 0.2857
216≈0.2857。
稠密图的密度接近 1,而稀疏图的密度接近 0。对于稠密图或稀疏图的定义没有严格的规则,但一般来说,如果密度大于 0.5,则视为稠密图;如果密度小于 0.1,则视为稀疏图。
2.2 邻接矩阵表示法
邻接矩阵 (adjacency matrix)
A
A
A 是表示图中边的矩阵,其中每个元素表示两个节点之间是否有边。邻接矩阵是大小为
n
×
n
n\times n
n×n 的正方形矩阵,其中
n
n
n 是图中的节点数量。
A
i
j
A_{ij}
Aij 的值为 1 表示节点
i
i
i 和节点
j
j
j 之间有一条边,而值为 0 则表示没有边。对于无向图,邻接矩阵沿主对角线对称,而对于有向图,邻接矩阵不一定对称:
A
i
j
=
{
1
,
(
v
i
,
v
j
)
∈
E
0
,
e
l
s
e
≤
0
A_{ij}= \begin{cases} 1, & (v_i,v_j)\in E\\ 0, & else \le 0 \end{cases}
Aij={1,0,(vi,vj)∈Eelse≤0
图 G 的邻接矩阵表示如下所示:

在 Python 中,可以将其实现为一个列表的列表:
adj = [[0,1,1,0,0,0,0],
[1,0,0,1,1,0,0],
[1,0,0,0,0,1,1],
[0,1,0,0,0,0,0],
[0,1,0,0,0,0,0],
[0,0,1,0,0,0,0],
[0,0,1,0,0,0,0]]
邻接矩阵是一种直观的表示方法,可以方便的将其可视化为二维数组。使用邻接矩阵的一个主要优点是,可以在恒定时间内检查两个节点是否相连,因此是检测图中是否存在边的有效表示方法。此外,它还可用于执行矩阵运算,这对某些图算法非常有用,例如计算两个节点之间的最短路径。
但邻接矩阵表示法添加或删除节点的成本很高,因为需要调整矩阵的大小。使用邻接矩阵的主要缺点之一是空间复杂性:随着图中节点数量的增加,存储邻接矩阵所需的空间也呈指数级增长,邻接矩阵的空间复杂度为
O
∣
V
∣
2
O|V|^2
O∣V∣2,其中
∣
V
∣
|V|
∣V∣ 表示图中的节点数。
总的来说,虽然邻接矩阵是表示小型图的有用数据结构,但由于其空间复杂度,对于大型图来说可能并不实用。此外,添加或删除节点的开销使其在动态变化的图中效率较低。
另一种常用的图存储方式是边列表 (edge list)。边列表是一个图中所有边的列表。每条边由一个元组或一对节点表示,边列表还可以包括每条边的权重,边列表的空间复杂度为
O
∣
E
∣
O|E|
O∣E∣ ,其中
∣
E
∣
|E|
∣E∣ 是边的数量。这种表示方法是 networkx 创建图时使用的结构:
edge_list = [(0, 1), (0, 2), (1, 3), (1, 4), (2, 5), (2, 6)]
边列表对于存储稀疏图更有效,因为稀疏图中边的数量远远少于节点的数量。但是,在边列表中检查两个节点是否相连需要遍历整个列表,这对于有很多边的大型图来说可能很耗时。因此,边列表更常用于对空间有要求的应用中。
第三种常用的表示方法是邻接表 (adjacency list)。它由一组成对的列表组成,其中每一对代表图中的一个节点及其相邻节点。根据实现方式的不同,这些列表对可以存储在链表、字典或其他数据结构中。例如,可以使用字典表示图的邻接表:
adj_list = {
0: [1, 2],
1: [0, 3, 4],
2: [0, 5, 6],
3: [1],
4: [1],
5: [2],
6: [2]
}
与邻接矩阵或边列表相比,邻接表有如下优点。首先,其空间复杂度为
O
∣
V
∣
+
O
∣
E
∣
O|V| + O|E|
O∣V∣+O∣E∣ ,其中
∣
V
∣
|V|
∣V∣ 是节点数,
∣
E
∣
|E|
∣E∣ 是边数,这比稀疏图中邻接矩阵的空间复杂度
O
∣
V
∣
2
O|V|^2
O∣V∣2 更低。其次,它可以用于高效迭代节点的相邻顶点,这对于许多图算法而言都非常有用。最后,添加节点或边可以在恒定时间内完成。
但,检查两个节点是否相连可能比使用邻接矩阵慢。这是因为它需要遍历其中一个顶点的邻接列表,而这对于大型图来说非常耗时。每种数据结构都有优缺点,选择何种数据结构通常取决于具体的应用和要求。
3. 图算法
图算法对于解决与图相关的问题至关重要,例如查找两个节点之间的最短路径或查找图中的关键节点。本节将讨论两种图遍历算法:广度优先搜索 (Breadth-first search, BFS) 和深度优先搜索 (Depth-first search, DFS)。
3.1 广度优先搜索
广度优先搜索 (Breadth-first search, BFS) 是一种图遍历算法,从根节点开始,在移动到下一层节点之前,先探索特定层的所有相邻节点。其算法思想是,从图中某一节点
v
i
v_i
vi 开始,从
v
i
v_i
vi 出发,依次访问
v
i
v_i
vi 的所有未被访问过的邻居
u
1
,
u
2
,
…
,
u
n
u_1,u_2,…,u_n
u1,u2,…,un;然后再顺序访问
u
1
,
u
2
,
…
,
u
n
u1,u_2,…,u_n
u1,u2,…,un 的所有未被访问过的邻居,如此一层一层执行,直到图中所有的节点都被访问到为止。具体实现时,可以维护一个要访问的节点队列并在将每个访问过的节点添加到队列时标记该节点,然后,算法从队列中移除下一个节点并探索其所有邻居,如果它们尚未被访问过,则将它们添加到队列中,
BFS 的算法过程如下所示:

接下来,使用 Python 实现 BFS。
(1) 创建图 G,使用 add_edges_from() 方法添加边:
G = nx.Graph()
G.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'), ('B', 'E'), ('C', 'F'), ('C', 'G')])
(2) 定义函数 bfs(),在图上实现 BFS 算法,函数需要两个参数:图对象和搜索的起始节点:
def bfs(graph, node):
(3) 初始化两个列表 (visited 和 queue) 并添加起始节点。visited 记录搜索过程中已访问过的节点,而 queue 则存储需要访问的节点:
visited, queue = [node], [node]
(4) 使用 while 循环,直到 queue 为空。在循环中,使用 pop(0) 方法移除 queue 中的第一个节点,并将结果存储在变量 node 中:
while queue:
node = queue.pop(0)
(5) 使用 for 循环遍历节点的邻居。对于每个尚未被访问的邻居,使用 append() 方法将其添加到 visited 和 queue 的末尾。完成后,返回 visited 列表:
for neighbor in graph[node]:
if neighbor not in visited:
visited.append(neighbor)
queue.append(neighbor)
return visited
(6) 使用参数 G 和起始节点 A 调用 bfs() 函数:
bfs(G, 'A')
(7) 函数将按照节点被访问的顺序返回 visited 列表:
['A', 'B', 'C', 'D', 'E', 'F', 'G']
BFS 适用于查找非权重图中两个节点之间的最短路径。这是因为该算法按照节点与起始节点的距离依次访问节点,因此第一次访问目标节点时,它一定是沿着与起始节点距离最短的路径。
除了寻找最短路径外,BFS 还可用于检查图是否连通或寻找图的所有连通部分,以及网络爬虫、社交网络分析和网络中的最短路径路由等应用。
BFS 的时间复杂度为
O
∣
V
∣
+
O
∣
E
∣
O|V| + O|E|
O∣V∣+O∣E∣ ,其中
∣
V
∣
|V|
∣V∣ 是图中的节点数,
∣
E
∣
|E|
∣E∣ 是图中的边数。对于连通度较高的图或稀疏图来说,计算代价较高。为了缓解这一问题,提出几种 BFS 变体,如双向 BFS 和 A* 搜索,使用启发式方法减少需要探索的节点数量。
3.2 深度优先搜索
深度优先搜索 (Depth-first search, BFS) 是一种递归算法,它从根节点开始,在回溯之前尽可能沿着每个分支进行探索。
它选择一个节点,探索其所有未探索的邻居,访问第一个未探索的邻居,只有当所有邻居都被访问过之后才会回溯。这样,在回溯探索其他分支之前,它会从起始节点沿着尽可能深的路径探索图,直到所有节点都被探索完为止。
DFS 的算法过程如下:

接下来,使用 Python 实现 DFS。
(1) 首先初始化一个空列表 visited:
visited = []
(2) 定义函数 dfs(),将 visited、graph 和 node 作为参数:
def dfs(visited, graph, node):
(3) 如果当前节点不在 visited 列表中,就将其添加到列表中:
if node not in visited:
visited.append(node)
(4) 然后,遍历当前节点的每个邻居。对于每个邻居节点,都会递归调用 dfs() 函数,并将 visited、graph 和邻居节点作为参数:
for neighbor in graph[node]:
visited = dfs(visited, graph, neighbor)
(5) dfs() 函数继续以深度优先方式探索图,访问每个节点的所有邻居,直到没有未访问的邻居为止。最后,返回列表 visited:
return visited
(6) 调用 dfs() 函数时,visited 设置为空列表,G 为待遍历图,A 为起始节点:
print(dfs(visited, G, 'A'))
(7) 函数将按照节点被访问的顺序返回列表 visited:
['A', 'B', 'D', 'E', 'C', 'F', 'G']
DFS 在解决多种图问题时都非常有用,例如查找图中连接部分、拓扑排序和解决迷宫问题,尤其适用于查找图中的循环,因为它以深度优先的顺序遍历图,当且仅当一个节点在遍历过程中被访问两次时,循环才存在。
与 BFS 类似,其时间复杂度为
O
∣
V
∣
+
O
∣
E
∣
O|V| + O|E|
O∣V∣+O∣E∣ ,其中
∣
V
∣
|V|
∣V∣ 是图中的节点数,
∣
E
∣
|E|
∣E∣ 是图中的边数。它需要的内存更少,但不能保证得到最浅路径解 (shallowest path solution)。与 BFS 不同,使用 DFS 可能会陷入死循环。
图论中的许多其他算法都建立在 BFS 和 DFS 的基础上,例如 Dijkstra 最短路径算法、Kruskal 最小生成树算法等。
小结
在本节中,我们介绍了图论的基本内容,图论是研究图和网络的数学分支。首先定义了什么是图,并解释了有向图、加权图和连接图等不同类型的图。然后,介绍了基本图对象和度量指标。此外,还讨论了图的邻接矩阵及其他表示方法。最后,探讨了两种基本图算法,即广度优先算法和深度优先算法,它们是设计更复杂图算法的基础。
系列链接
图神经网络实战——图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战——基于DeepWalk创建节点表示








![[GXYCTF2019]BabyUpload1 -- 题目分析与详解](https://img-blog.csdnimg.cn/direct/18d025e0f70a42a6a7797e8c3bf230c6.png)