文章目录
- 4.基于布隆过滤器解决Redis穿透问题
- 4.1什么是redis的穿透问题
- 4.2解决穿透问题
- 4.3布隆过滤器
- 4.3.1思想
- 4.3.2特点
- 4.3.3缺点
- 4.4基于Springboot实现布隆过滤器
- 4.4.1导入依赖
- 4.4.2yml配置
- 4.4.3两个工具类
- (1)BloomFilterHelper
- (2)RedisBloomFilter
- (3)将RedisBloomFilter装配到容器中
- 4.4.4使用RedisBloomFilter
- 4.4.5初始添加数据
- 4.4.6测试
- 4.5难点
- 4.6小结
4.基于布隆过滤器解决Redis穿透问题
4.1什么是redis的穿透问题
查询一个在数据库不存在的数据,redis不会将这个数据进行缓存,导致每一次查询都要到数据库中查询,增加数据库压力
4.2解决穿透问题
- 缓存空值:对于后端存储中不存在的数据,可以将其在缓存中设置为空值缓存,即存储一个特殊的空值标识。这样,在下一次查询该数据时,即使缓存中为空值标识,也可以避免请求直接穿透到后端存储系统。
- 布隆过滤器:使用布隆过滤器可以在缓存层面进行快速的数据存在性检查。布隆过滤器是一种概率型的数据结构,可以高效地判断一个元素是否可能存在于集合中,通过在缓存层进行预先判断,可以防止不存在的数据请求直接穿透到后端存储系统。
4.3布隆过滤器
4.3.1思想
布隆过滤器是一种空间效率高、时间效率快的数据结构,主要用于判断一个元素是否存在于一个集合中。
其基本思想是 通过多个哈希函数将元素映射到一个比特数组 中,并根据哈希函数的结果设置相应的比特位。
当需要判断一个元素是否存在于集合中时,布隆过滤器会使用相同的哈希函数计算出相应的比特位,并检查这些位置上的比特值。如果所有对应的比特位都为 1,则可以判断元素很可能在集合中;如果有任何一个比特位为 0,则可以断定元素一定不在集合中。
举例:
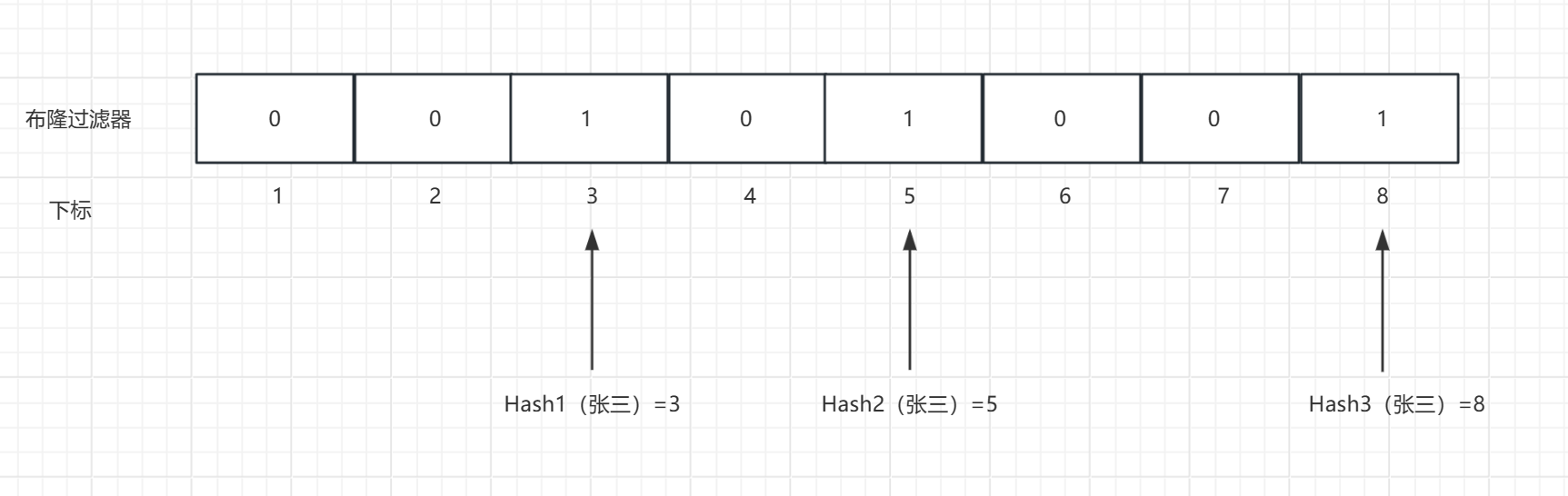
4.3.2特点
-
空间效率高:布隆过滤器只需要存储少量的比特位信息,所以占用的空间远远小于存储实际元素的空间。
-
时间效率快:判断一个元素是否存在于集合中只需要计算几个哈希函数并检查对应的比特位,所以查询速度非常快。
-
存在误判:因为多个元素可能映射到相同的比特位上,所以布隆过滤器可能会出现误判,即判断一个元素在集合中但实际并不存在。
-
布隆过滤器的误判率可以通过哈希函数的数量来进行调整
哈希函数数量越多,误判率越低!而哈希函数越多,所映射出来的下标值就越多,下标值越多,一维数组的长度就越长,布隆过滤器的空间复杂度就越高。
4.3.3缺点
- 存在误判:布隆过滤器的设计初衷是为了提高查询效率,但在实际应用中可能会出现误判,即判断某个元素在集合中但实际并不在。这是因为多个元素经过哈希函数映射后可能会落在相同的比特位上,导致冲突。误判的发生会根据布隆过滤器的大小和元素数量等因素而不同。
- 无法删除元素:由于布隆过滤器的设计是基于多个哈希函数映射到固定大小的比特数组上,所以无法直接删除已经添加的元素。因为删除一个元素可能会影响到其他元素映射到的比特位,从而导致误判的增加。如果需要实现删除操作,通常需要重新构建一个新的布隆过滤器。
- 需要合适的哈希函数:布隆过滤器的性能与哈希函数的选择密切相关,需要选择足够独立且分布均匀的哈希函数,以降低冲突率和误判率。
- 不适合小数据量:布隆过滤器对于小数据量的情况下,可能会浪费较大的空间,因为需要维护一个较大的比特数组。在数据量较小时,使用传统的数据结构如哈希表可能更为合适。
4.4基于Springboot实现布隆过滤器
使用Google Guava中提供的BloomFilter,布隆过滤器
4.4.1导入依赖
<!--使用Redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--借助guava的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
4.4.2yml配置
spring:
redis:
host: 127.0.0.1
port: 6379
password: 12345
jedis.pool.max-idle: 100 #连接池中最大空闲连接数
jedis.pool.max-wait: -1ms #连接池中获取连接的最大等待时间,-1表示无限等待
jedis.pool.min-idle: 2 #连接池中最小空闲连接数
timeout: 2000ms #连接redis的超时时间
4.4.3两个工具类
(1)BloomFilterHelper
BloomFilterHelper 类中的方法主要用于根据期望插入元素的数量和假阳性率计算 Bloom Filter 的比特数组长度和哈希函数个数,并 生成一组哈希偏移量,用于设置比特数组中的比特位。
package com.whrfjd.rescenter.utis;
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
/**
* 构造函数,用于初始化 BloomFilterHelper 对象。
* funnel 参数是用于将对象转换成比特数组的 Funnel 类型对象,expectedInsertions 参数是期望插入元素的数量,fpp 参数是 * 假阳性率(False Positive Probability)
*/
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
/*
* 根据给定的值生成一组哈希偏移量。该方法接受一个泛型类型的参数 value,并返回一个整型数组
* 数组包含了多个哈希偏移量,用于确定在布隆过滤器的比特数组中哪些位置需要设置为 1。
*/
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度:根据期望插入元素的数量和假阳性率计算布隆过滤器的比特数组长度。
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
// 设定最小期望长度
p = Double.MIN_VALUE;
}
int sizeOfBitArray = (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
return sizeOfBitArray;
}
/**
* 计算hash方法执行次数:根据期望插入元素的数量和比特数组长度计算需要执行的哈希函数个数
*/
private int optimalNumOfHashFunctions(long n, long m) {
int countOfHash = Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
return countOfHash;
}
}
(2)RedisBloomFilter
RedisBloomFilter该类通过使用 BloomFilterHelper 和 RedisTemplate,在 Redis 中实现了布隆过滤器的添加和查询功能。
在添加大量数据时,可以使用布隆过滤器来快速排除不需要的数据,从而减少查询开销。
package com.whrfjd.rescenter.utis;
import com.google.common.base.Preconditions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
@Service
public class RedisBloomFilter {
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value); //使用 bloomFilterHelper 对象的 murmurHashOffset() 方法为给定的值生成一组哈希偏移量。这些偏移量将用于确定在布隆过滤器的比特数组中哪些位置需要设置为 1。
for (int i : offset) {
System.out.println("key : " + key + " " + "value : " + i);
redisTemplate.opsForValue().setBit(key, i, true); //通过迭代遍历生成的偏移量数组,并使用 redisTemplate.opsForValue().setBit() 方法将对应的比特位设置为 1。具体地,它会将指定 key 对应的 Redis 字符串值的二进制位中的偏移量位置设置为 true。
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
// 使用 Preconditions 进行参数校验,确保 bloomFilterHelper 不为 null
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
// 根据给定的值计算哈希偏移量
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
System.out.println("key : " + key + " " + "value : " + i);
// 判断 Redis 中对应位置的比特值是否为 1
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
// 如果所有位置的比特值都为 1,则返回 true,表示值可能存在于布隆过滤器中
return true;
}
}
(3)将RedisBloomFilter装配到容器中
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedisBloomFilterConfig {
// 初始化布隆过滤器,放入到spring容器里面
@Bean
public BloomFilterHelper<String> initBloomFilterHelper() {
return new BloomFilterHelper<>((Funnel<String>) (from, into) -> into.putString(from, Charsets.UTF_8).putString(from, Charsets.UTF_8), 1000000, 0.01);
}
@Bean
public RedisBloomFilter{
return new RedisBloomFilter();
}
}
4.4.4使用RedisBloomFilter
首先在controller层注入redisBloomFilrer以及bloomFilterHelper
@Autowired
private RedisBloomFilter redisBloomFilter;
@Autowired
private BloomFilterHelper bloomFilterHelper;
4.4.5初始添加数据
- 需要手动发送请求
@GetMapping("/redis/bloomFilter")
public ResponseResult redisBloomFilter(){
List<String> allResourceId = resCenterDao.getAllResourceId();
for (String id : allResourceId) {
//将所有的资源id放入到布隆过滤器中
redisBloomFilter.addByBloomFilter(bloomFilterHelper,"bloom",id);
}
return new ResponseResult(ResponseEnum.SUCCESS);
}
4.4.6测试
@GetMapping("/redis/bloomFilter/resourceId")
@ApiOperation("redis布隆过滤器资源测试")
public ResponseResult redisBloomFilterResourceId(@RequestParam("resourceId")String resourceId){
boolean mightContain = redisBloomFilter.includeByBloomFilter(bloomFilterHelper,"bloom",resourceId);
if (!mightContain){
return new QueryResult<>(ResCenterEnum.RESOURCE_EXSIT,"");
}
return new ResponseResult(ResponseEnum.SUCCESS);
}
4.5难点
布隆过滤器的使用难点主要在于:如何在真实业务海量数据的背景下。实现对布隆过滤器的初始化,因为我们要直接从数据库中拿数据,这种大规模的IO操作势必会给服务器来带很大的压力
- 解决:
- 分批次初始化:创建定时任务,分批存储数据到布隆过滤器中。
- 利用多线程并发处理:可以开启多个线程来并发地读取和处理数据,以提高初始化速度。需要注意的是,在并发处理时需要保证线程安全,避免出现数据竞争等问题。
- 选择适合的哈希函数和比特数组大小:在初始化时,需要根据实际数据大小和误判率要求来选择合适的哈希函数和比特数组大小。较小的比特数组大小和合适的哈希函数可以减少初始化所需的空间和时间。
4.6小结
在解决Redis穿透问题时,布隆过滤器是一种非常有效的工具。它能够在缓存层面进行快速的数据存在性检查,从而避免了不存在的数据请求直接穿透到后端存储系统,减轻了数据库的压力。通过布隆过滤器的特点和使用方法的介绍,我们了解到它可以高效地判断一个元素是否可能存在于集合中,同时也存在一定的误判率和一些实际应用上的限制。
基于Spring Boot实现布隆过滤器需要依赖Google Guava中提供的BloomFilter,并结合Redis进行布隆过滤器的添加和查询功能。在实际使用中,我们可以通过BloomFilterHelper类和RedisBloomFilter类来完成对布隆过滤器的初始化和使用,从而应对真实业务海量数据的挑战。
在使用布隆过滤器时,需要考虑如何进行布隆过滤器的初始化,特别是在海量数据背景下,这可能会给服务器带来很大的压力。针对这个难点,我们可以采取分批次初始化、利用多线程并发处理以及选择适合的哈希函数和比特数组大小等策略来解决。
总的来说,布隆过滤器是一种强大的工具,可以在一定程度上解决Redis穿透问题,提高系统的性能和稳定性。
但是,前面已经介绍过了布隆过滤器的缺点:无法删除元素,内存效率低;在接下来的内容中,我们将继续介绍 另一种高效的过滤器——布谷鸟过滤器
布谷鸟过滤器(Cuckoo Filter)相对于布隆过滤器具有一些优点和缺点。
-
优点:
- 删除支持:布谷鸟过滤器支持删除操作,而布隆过滤器不支持删除。这意味着可以从布谷鸟过滤器中安全地删除元素,而不会对其他元素的存在性判断造成影响。
- 内存效率高:相比布隆过滤器,在相同的误判率下,布谷鸟过滤器通常能够使用更少的内存空间。
-
缺点:
- 性能:在某些情况下,布谷鸟过滤器的性能可能略逊于布隆过滤器,特别是在处理大规模数据时,布隆过滤器可能更快速。








![[技巧]Arcgis之图斑四至点批量计算](https://img-blog.csdnimg.cn/direct/93a8290831b445a797c71ace6cf08358.png)