DELL +31% 引爆AI,都在寻找catch-up plays
软件和云都没咋动,硬件尤其是Semi全在涨。NVDA+4%,AMD+5%,MRVL+8%,西部数据+8%,博通+7%(Oppenheimer、BofA提目标价),台积电+4%,镁光+5%,超威盘后+14%(纳入指数)。除了PMI数据和美债,美联储今天都提了AI:"AI could improve labor outcomes, reduce inequality”
感受下来自sell side们的热情:
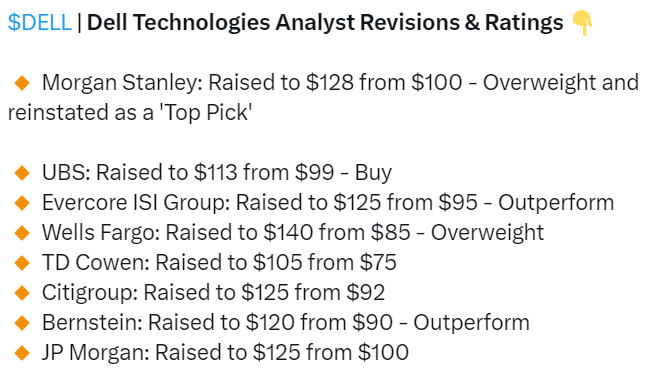
这些都是反光镜,不得不提一下海通国际Jeff 10天前的print,事实证明,市场的确就是在找AI catchup plays

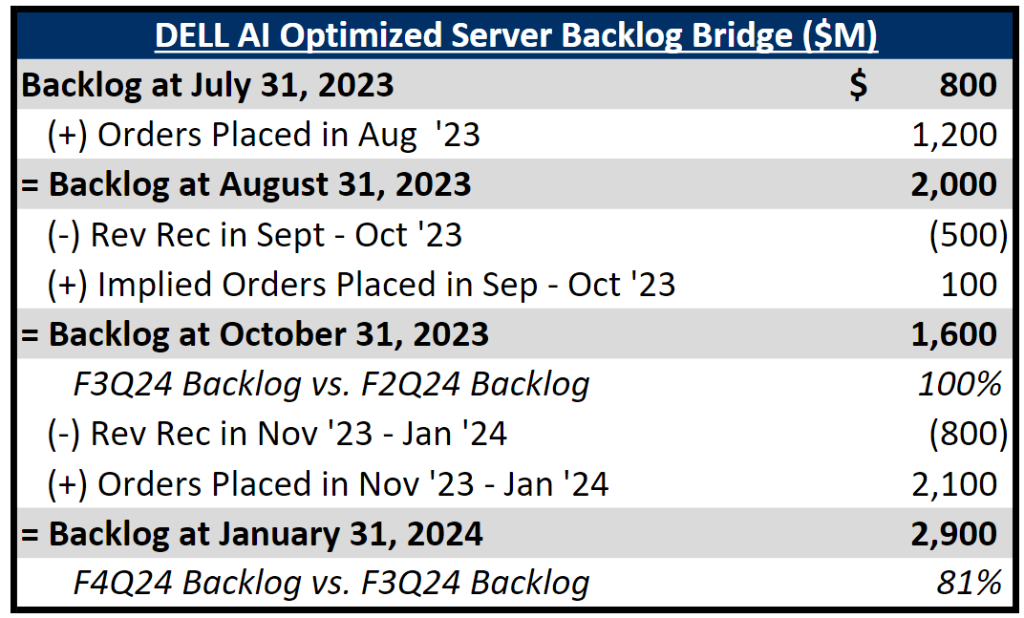
大摩对DELL订单做的流水图,非常清晰,说到底,新增订单增速远快于业绩确认速度(交付速度),导致到今天Backlog(在手订单)已经是6个月前的3.5倍...上个季度担心的GPU lead time耽误收入确认,现在H100 lead time缩短成利好
最关键的,公司跟TSMC AMD也学会了,出来上调一把行业TAM,2027年AI服务器1520亿美元(之前1240亿美元)。2027几颗卫星开始脚踩脚了。负面也有,PC市场疲软和传统服务器的竞争激烈定价压力,复苏要到下半年出现,整体毛利率也有压力(成本上升和AI稀释)。不过看市场基本选择了look through,都在找lagger,已知的传统疲软似乎基本price in了。估值便宜+分红又提升了20%...
citi也发了业绩会后的callback,要点:
指引:对于2025财年(24CY)的指引好于预期,预计全年大幅增长,对服务器中AI势头的乐观,传统服务器的反弹,以及下半年PC和存储的复苏持乐观态度。
服务器:积压订单中GPU mix(H100/H200/MI300X),以及他们lead time mix的不同,将导致AI服务器在季度间收入确认上的不均匀(H100确认加速,新产品确认估计又受交付限制)。29亿美元的积压订单中H200和MI300x占比在提升。管理层希望在第一季度尽可能多地出货H100,H100的交货时间已经从第三季度的39周下降。
毛利率:预计2025财年的毛利率将下降,这是由于存储mix比例下降、大宗商品成本增加、更多价格竞争(PC、传统服务器),以及预计将出货更多的AI服务器(AI服务器会稀释毛利率)。
此外NTAP(美国网存)业绩超预期,其实beat幅度不大,但股价+18%,因为也在提AI...NTAP在业绩会上重点强调进了英伟达DGX PODs中的“多个”项目...
AMD除了传的小段子,看下来 1)YTD英伟达65%,AMD 35%,可能就是追一追;2)8bn是否得到默许了不确定,但如果推理真的要引爆,那就水涨船高阳光普照了...
总之现在市场对AI的追逐,或者说寻找“AI新标的”的热情极其高涨。MS搞了个AI股票坐标系,横轴AI收入占比%,纵轴是25年PE multiple。静态去看的话,当然是越处于东南方向的越好。动态去看的话,大家都会往右边走,谁能保持在趋势线下方就是价格更划算。其实这种坐标系,潜台词就是AI占比越高市场给与更多追逐从而会带来更高估值溢价。那处于趋势线下方的且偏离较远的,都是“潜力股”。
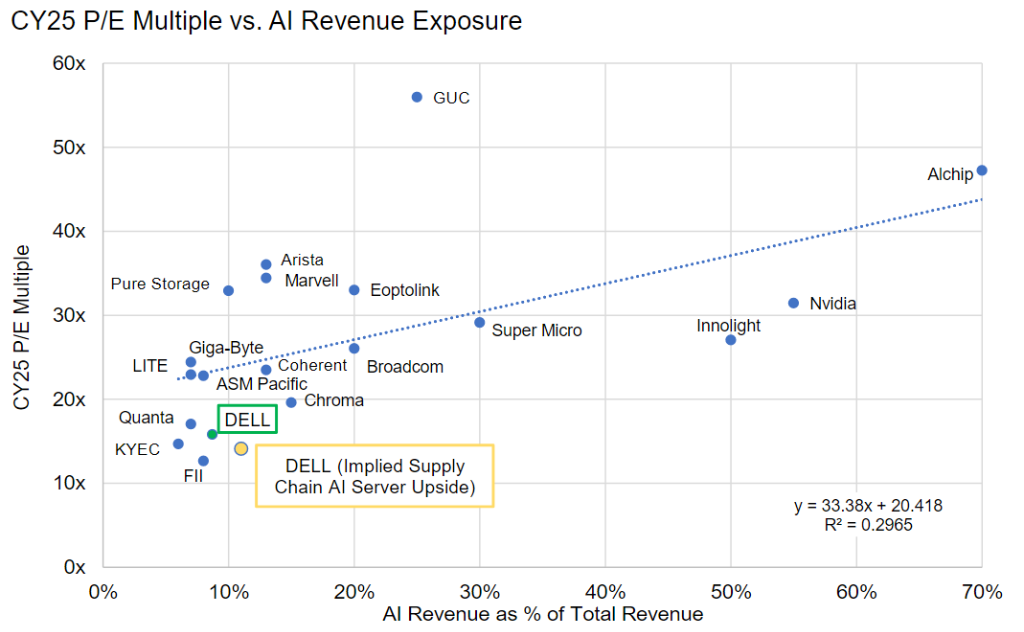
标的不够?MS给了另一张图,IDC里面各个公司的AI收入占比:
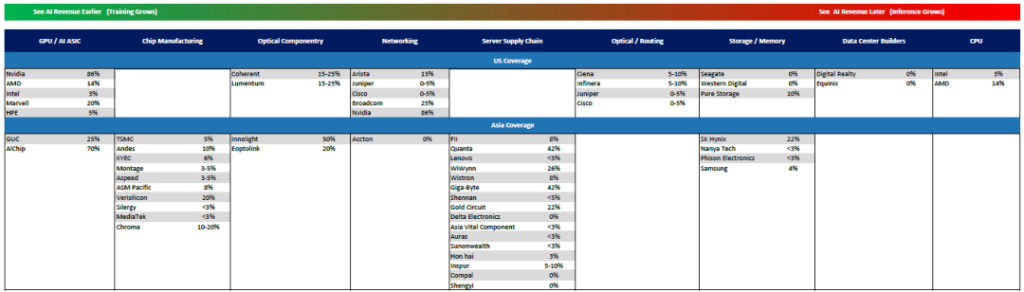
推理需求到了70%?
上周末 The wire对Jensen的采访广泛传播,但其中一个细节被修改了(来自读者Dai的提醒),很微妙。原文中Jensen表示 “如果我猜的话,Nvidia 今天的业务可能是 70% 的推理,30% 的训练。” 之后似乎是被公关修改了:

言之凿凿的70%,再考虑上下文,不像是口误,更像是说漏了。被公关也合理,毕竟和财报披露口径差别太大。而且Dai分析很有道理,全年40%,年初很低的话,年末到了70%也很合理。
Alchip世芯业绩会上要点
ASIC市占率已经是纯ASIC公司第一名,就算跟MTK、AVGO、MRVL比,也只输给AVGO;来自最大客户(亚马逊)的PO持续上升,相比之前要上修了,且这颗新的chip生命周期和需求都比之前预期的要大。客户给的5nm新产品的forecast "too good to be true"
国产HBM的一份纪要
国内良率50-60%对比海外85%(但国内是中试线,做成量产线良率会提升很多);国内两派,一个大家知道的XXXX,一个是H+XX+XX(具体放星球了)。项目定义是3,可能要到26年出产品,也可能比这个更早。
马斯克除了起诉OpenAI,今天还有个发言,增量:
我从未见过任何技术进步得像AI这么快,目前AI的增长接近每六个月增加十倍(我理解是计算量)。这就是为什么英伟达的市值如此巨大,他们拥有最好的AI芯片,它的市值还可能会更高,AI芯片热潮会比任何曾经的淘金热都要大。我认为我们真的处于可能是有史以来最大的技术革命的边缘。
我们离完全自动驾驶非常接近;乘用车的平均使用时间大约是每周10小时,但如果实现了自动驾驶,每周使用时间可以达到50到60小时,这意味着乘用车的效用将增加五倍
张忠谋:“有人跟我要10个fabs”
最近在日本一个会议上表示,有人跟他说,需要10个fab来生产AI芯片,“他们谈论的不是wafers,而是fabs” 张忠谋认为10 fabs过于惊人,真实的需求可能在 几万片晶圆~10个fabs之间,更为合理(但这个范围也很大,也就是几万~百万片量级之间,参考英伟达2024需求可能也在10万片以上了)
月之暗面杨植麟访谈长文,干货满满,省流:
Scaling law为什么能成为第一性原理?你只要能找到一个结构,满足两个条件:一是足够通用,二是可规模化。通用是你把所有问题放到这个框架建模,可规模化是只要你投入足够多算力,它就能变好。这是我在Google学到的思维:如果能被更底层的东西解释,就不应该在上层过度雕花。有一句重要的话我很认同:如果你能用scale解决的问题,就不要用新的算法解决。新算法最大价值是让它怎么更好的scale。当你把自己从雕花的事中释放出来,可以看到更多。
长文本是登月第一步,因为足够本质,它是新的计算机内存。老的计算机内存,在过去几十年涨了好几个数量级,一样的事会发生在新的计算机上。它能解决很多现在的问题。比如,现在多模态架构还需要tokenizer(标记器),但当你有一个无损压缩的long context就不需要了,可以把原始的放进去。进一步讲,它是把新计算范式变成更通用的基础。旧的计算机可以0、1表示所有,所有东西可被数字化。但今天新计算机还不行,context不够多,没那么通用。要变成通用的世界模型,是需要long context的。第二,能够做到个性化。AI最核心的价值是个性化互动,价值落脚点还是个性化,AGI会比上一代推荐引擎更加个性化。但个性化过程不是通过微调实现,而是它能支持很长的context(上下文)。你跟机器所有的历史都是context,这个context定义了个性化过程,而且无法被复刻,它会是更直接的对话,对话产生信息。
scaling law走到最后发现根本走不通的概率几乎为0。模型可扩展的空间还非常大,一方面是本身窗口的提升,有很长路要走,会有几个数量级。另一方面是,在这个窗口下能实现的推理能力、the faithfulness的能力(对原始信息的忠实度)、the instruction following的能力(遵循指令的能力)。如果这两个维度都持续提升,能做非常多事。可能可以follow(执行)一个几万字的instruction(指令),instruction本身会定义很多agent(智能体),高度个性化。
AI不是我在接下来一两年找到什么PMF,而是接下来十到二十年如何改变世界——这是两种不同思维
开源的开发方式跟以前不一样了,以前是所有人都可以contribute(贡献)到开源,现在开源本身还是中心化的。开源的贡献可能很多都没有经过算力验证。闭源会有人才聚集和资本聚集,最后一定是闭源更好,是一个consolidation(对市场的整合)。如果我今天有一个领先的模型,开源出来,大概率不合理。反而是落后者可能会这么做,或者开源小模型,搅局嘛,反正不开源也没价值。
从GPT-3.5到GPT-4,解锁了很多应用;从GPT-4到GPT-4.5再到GPT-5,大概率会持续解锁更多,甚至是指数型的应用。所谓“场景摩尔定律”,就是你能用的场景数量会随着时间指数级上升。我们需要边提升模型能力,边找更多场景,需要这样的平衡。它是个螺旋。
可以理解成有两种不同压缩。一种是压缩原始世界,这是视频模型在做的。另一种是压缩人类产生的行为,因为人类产生的行为经过了人的大脑,这是世界上唯一能产生智能的东西。你可以认为视频模型在做第一种,文本模型在做第二种,当然视频模型也一定程度包含了第二种。它最终可能会是mix,来建立世界模型。
硅谷一直有一个争论:one model rules all还是many specialized smaller models(一个通用模型来处理各种任务,还是采用许多专门的较小模型来处理特定任务),我认为是前者。