如何自动化获取谷歌学术上学者的全部论文信息
在学术研究领域,追踪和分析学者的研究工作是非常重要的。本文介绍了如何使用Python自动化地收集指定学者的谷歌学术主页上的所有论文信息。
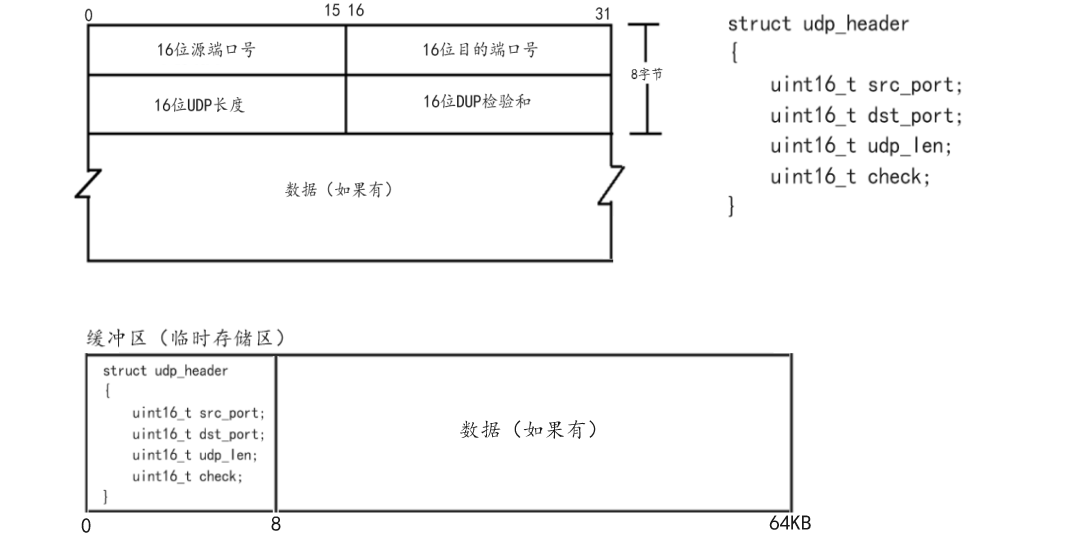
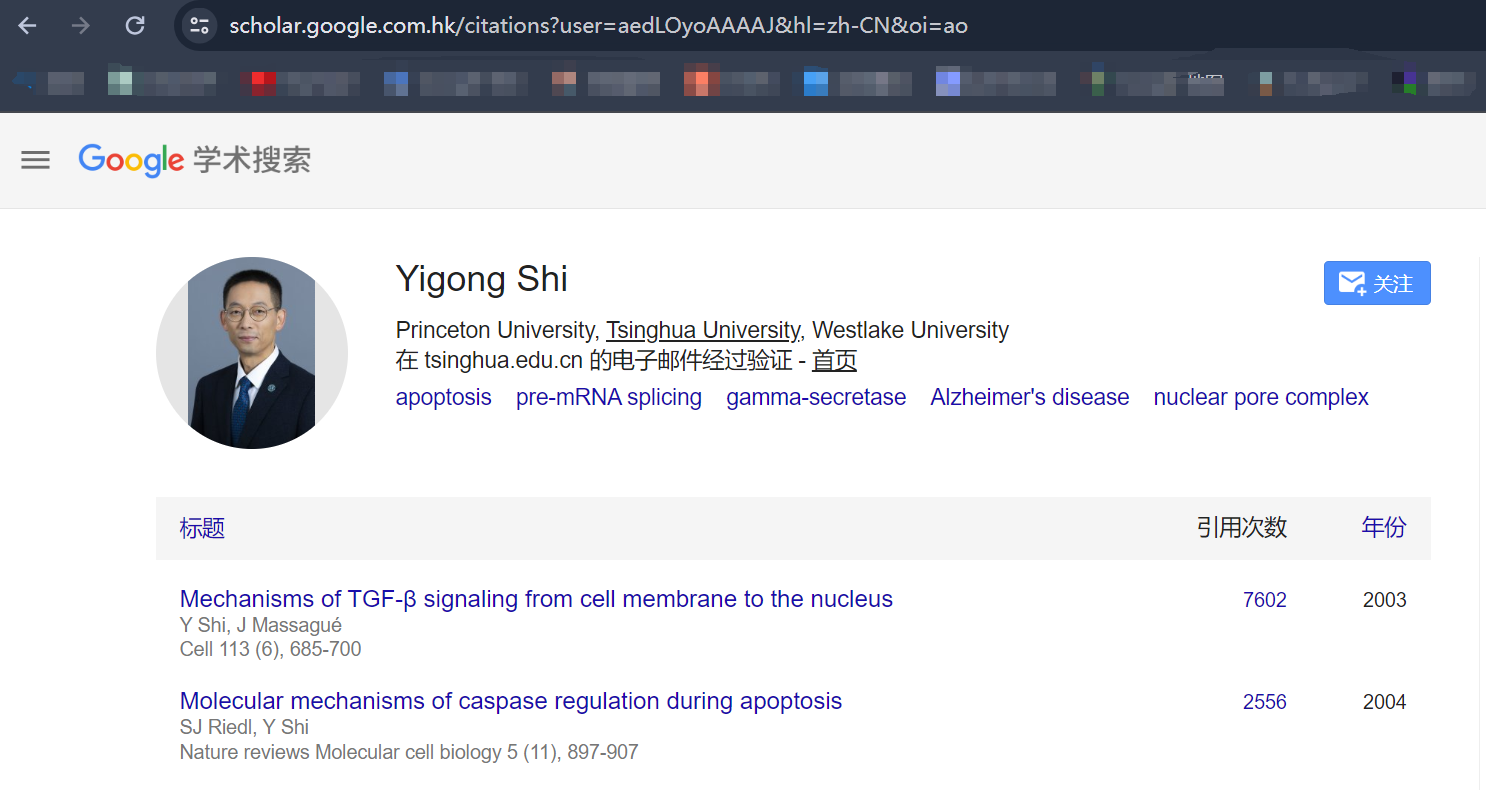
示例:施一公院士的谷歌学术主页
以施一公院士的谷歌学术主页为例,我们首先复制其页面链接:
https://scholar.google.com.hk/citations?user=aedLOyoAAAAJ&hl=zh-CN&oi=ao
将链接输入到下面提供的Python脚本中,脚本将自动收集页面上列出的所有论文信息。
输出结果
运行脚本后,输出为Excel,如下图所示:

此外,还提供了一个可执行文件(.exe),方便在不同的环境下运行,无需安装Python环境。相关文件可以在以下百度云链接中找到:
https://pan.baidu.com/s/1I9OA4h3tN0ogdchOQdDSUw?pwd=m31e
提取码:m31e
使用的代码
……
import re
import requests
import pandas as pd
from datetime import datetime
from bs4 import BeautifulSoup
# 请求用户输入Google Scholar主页的网址
url_base = input("请输入Google Scholar主页的网址: ")
# 定义HTTP请求头,模拟正常浏览器访问,以避免被网站阻止
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def get_soup(url):
"""
发送HTTP请求到指定URL并获取BeautifulSoup对象。
参数:
- url: 要请求的网页的URL字符串。
返回:
- BeautifulSoup对象,用于进一步解析网页内容。
异常:
- HTTPError: 如果响应的状态码不是200,即请求失败。
"""
# 定义请求头,模拟浏览器行为
response = requests.get(url, headers=HEADERS)
# 检查请求是否成功,如果状态码不是200,则抛出异常
response.raise_for_status()
# 使用BeautifulSoup解析响应内容,并返回BeautifulSoup对象
return BeautifulSoup(response.text, 'html.parser')
# 主逻辑
def main():
"""
主函数,从Google Scholar网站抓取指定数量的论文信息,并保存到Excel文件中。
"""
# 定义列名
columns = ['年份', '期刊', '题目', '作者', '一作','中文/英文']
# 初始化DataFrame,用于存储论文信息
papers_df = pd.DataFrame(columns=columns)
# Loop settings
cstart = 0 # Starting index of papers
pagesize = 100 # Number of papers per page
# 初始化一个空列表来存储每行的数据
data_rows = []
# 每次爬取100篇,直到爬取所有文章
while True:
url = f'{url_base}&cstart={cstart}&pagesize={pagesize}'
# 使用get_soup函数获取Google Scholar网页的BeautifulSoup对象
soup = get_soup(url)
# 找到所有表示论文的行
rows = soup.find_all('tr', class_='gsc_a_tr')
try:
for row in rows:
# 提取论文标题
title = row.find('a', class_='gsc_a_at').text
# 提取作者信息
authors = row.find('div', class_='gs_gray').text
# 提取第一作者
first_author = authors.split(',')[0] if authors else 'N/A'
# 提取发表年份
year = row.find('span', class_='gsc_a_h gsc_a_hc gs_ibl').text
# 提取期刊信息,并去除可能的页码等信息
journal_info = row.find_all('div', class_='gs_gray')[1].text.split(',')[0] if len(row.find_all('div', class_='gs_gray')) > 1 else 'N/A'
journal_name = re.sub(r'\s\d+.*$', '', journal_info)
# 判断中文还是英文
if ',' in authors:
Chinese_English = '英'
elif ',' in authors:
Chinese_English = '中'
else:
Chinese_English = ''
# 输出提示
print(f"题目:{title}\n作者:{authors}\n一作:{first_author}\n年份:{year}\n期刊:{journal_name}\n中英文:{Chinese_English}\n")
# 构造论文信息字典
data = {
'年份': year,
'期刊': journal_name,
'题目': title,
'作者': authors,
'一作': first_author,
'中文/英文': Chinese_English
}
# 将论文信息添加到列表中
data_rows.append(data)
cstart += 100
except:
# 所有文献检索完成
break
# 将列表转换为DataFrame
papers_df = pd.DataFrame(data_rows, columns=columns)
# 获取当前的日期和时间
current_time = datetime.now()
# 格式化日期和时间为字符串,用于文件名
formatted_time = current_time.strftime("%Y-%m-%d_%H-%M-%S")
# 创建文件名,包含当前的日期和时间
filename = f'papers_info_{formatted_time}.xlsx'
# 将DataFrame保存到Excel文件中
papers_df.to_excel(filename, index=False)
# 输出提示
print('文件已经生成')
if __name__ == "__main__":
main()