引言:
北京时间:2023/11/20/9:17,昨天成功更文,上周实现了更文两篇,所以这周再接再厉。当然做题任在继续,而目前做题给我的感觉以套路和技巧偏多,还是那句话很多东西不经历你就是不懂,很多套路和技巧只有你见过用过,你才能明白,下次碰到某题涉及该知识点时,你才会往这个方向想,从而增加做出该题的可能性。而不是看到一个题,虽然有思路,但是却不知道如何下手。而在上篇博客我们主要学习的是对数据加密,保证数据的安全性。我的看法就是别人的善良从不是因为它们大发慈悲,而是因为自身的强大。这句话给我的感想很深,从两点出发,一点是人好像对这种越简单的道理,反而认知更薄弱。另一点就是这句话表述的意思,无论是从数据安全问题,还是人际交往。人的善良好像总是容易被漠视,感受不到回报。心越软你的感受越深。好比各种加密方法,当你无懈可击的时候,你会发现自己一个人生活也挺好,所以在生活中我们一定要降低与他人的耦合程度,就像网络协议栈一样,每一层洋洋洒洒。

引言实时更新补充:
北京时间:2024/2/15/14:19,哈哈哈,先来三个字化解一下尴尬场面。看了一下上述引言,发现该篇博客是在去年11月份写的,当然当时没有及时发布,肯定是因为没有写完。简单用小学学过的加减算了一下,已经85天没有码字了,当然同理之前博客中所说,当时的主攻方向不是写博客,而是学习算法。生活就是这样曲曲折折,因为一系列原因,你不可能一直保持同一状态,简单回顾了一下,发现至今已经68天没有学习了,也就是说我以前视之为宝贝的小绿点(gitee),悄然已经失去了68个,回想当初只是因为失去一个小绿点而产生的失落感,现在只能是哑然一笑。如果没记错的话,从开始学习算法到结束,头尾时间大概是一个月左右,而这一个月由浅入深的学习了双指针、模拟、二分、位运算、字符串、链表、栈、优先级队列、分治、哈希、递归、回溯、BFS,当然只是见识这一类的题型,同理目前的我还没有独立做题的能力。ok,讲完了之前的学习内容,我就要开始分享摆烂68天都干了什么,大体分为两部分:校园部分+寒假部分。我记得那是一个周六的下午,因为被算法题目折磨了许久,那天睡到了中午12点多,使得本应该日常8点去图书馆的我产生了一股无太大所谓情结,然后又因为当时体育选修课是篮球,在每个星期一节篮球课中,我逐渐热爱上了篮球,从而萌生了去打篮球的想法。因为种种原因,舍友对于我的想法响应积极,也许当时是一句戏言,但在人情世故之下不出预料的我们打了一下午的篮球。这场篮球给我的印象很深,原因种种。第二天,在舍友的强烈要求,我开始了金铲铲S10赛季的闯荡,从开始的被虐到后来的虐菜,那种人性和游戏的结合体现的淋漓尽致,当然这也就是游戏成瘾的本质,至此一发不可收拾。放假之后,各回各家,组队的人越来越少,最后高分段掉了几把分之后,也就失去了玩该游戏的动力。后转战王者荣耀(00后的圈子真小),当然玩该游戏最初的动力来源于几个新英雄以及刚好赛季更新,然后因为该游戏自身的一些策略,上分之路越来越艰辛,最终在连跪中失去了玩该游戏的动力。没有了游戏可玩,就开始了追番之路,在追番的过程中,一部叫《恶魔法则》的动漫成功吊起了我的胃口,之后当然也就是将《恶魔法则》这本小说给看完了,具体用了多少时间忘记了。充分意识到当年跳舞(起点白金)有多强以及为什么当年连三少的斗罗大陆女主介绍都是:我叫小舞,跳舞的舞。可见当时网文界跳舞大佬的实力。看完该本经典小说,当然该小说在我心目中能排进前三,第一于紫川不可替代。我进入了一个空窗期,好多天无所适从,我开始寻找其它有意思的事物,看了几部新剧,提到新剧,上述在学校过程中,我还看了胡歌的繁花。发现除了繁花其它新剧并不能给我很好的感觉,在机缘巧合之下我接触到了知否。知否给我的感觉纯属就是另一个感觉,这个感觉比当时繁花完结不够看还要深。足以和上述小说给我的感觉媲美。最终转战和平精英,当然这个游戏不像是上述游戏,这个游戏必须要有游戏塔子,之所以玩这个游戏,也是因为我姐她玩,所以在组队的快乐之中又度过了几天。可叹,美好的时光终会如流水般消逝,我姐又要重新成为一个打工人。时至今日,我再也找不到任何有趣的事物,在无声的夜晚和内心的空洞中,想起了曾经的许多往事。悲寂、无奈之感涌上心头,感慨万千。大道理说的好:即使时光不再,但是那些美好将永远铭刻在我们的心中,成为我们一生宝贵的财富。最后送给自己四个字:我还是我。
回顾HTTPS协议相关知识
在上篇博客中,我们对HTTPS协议进行了详细的学习。从区分HTTP和HTTPS到明确HTTPS的工作原理,在多个方面由浅入深的对HTTPS协议进行了立体化探究。理解了什么是HTTPS协议,原来HTTPS协议只不过是对HTTP协议在数据安全方面的缺陷进行了一个完善,保证了当前网络通信的安全性和可靠性。并且本着追根究底的原则,我们明白了HTTPS协议之所以能够保证数据安全,是因为它在HTTP协议的基础上添加了一层提供加密解密操作的软件层,其中最常见的软件层为SSL/TLS。随着学习的深入,我们逐渐明白了SSL/TLS中涉及的加密解密方式有对称加密解密和非对称加密解密,在明白了对称加密解密和非对称加密解密的工作机制之后,我们明白单独使用其中一种,并不能保证网络通信的安全性和高效性,从而诞生了对称加密解密和非对称加密解密配合使用的机制。最后经过不断的探究,我们发现了网络通信的核心BUG,对端主机无法确保公钥来源的合法性。所以在对称加密解密和非对称加密解密配合使用机制之上,我们引入了CA证书的概念,明确CA证书的本质就是使用一套新的非对称加密解密操作来确保公钥来源的合法性。当然上篇博客在引入CA证书概念之前,我们对数据摘要、数字签名等概念进行了详细的介绍,对于数据摘要的使用场景以及优点进行了着重讲解。并结合CA证书的理解,我们明白之所以对CA证书进行数字签名,而不是直接对证书做加密,本质就是因为我们在提高加密解密效率的同时,还需要提供一套兼容性、灵活性高的解决方案。避免了因为数据间差异带来的效率问题。最终明确,之所以HTTPS协议能够保证网络安全通信,是因为它使用了非对称加密解密+对称加密解密+证书认证的方案。而对于这个方案而言,其中一共涉及到了三组不同的秘钥。明确,第一组秘钥是CA机构为了确保网站合法性而产生的一组非对称加密解密秘钥,而第二组秘钥则是网站自身为了确保数据通信安全而产生的一组非对称加密解密秘钥,最后一组则是对端主机获取到合法公钥之后同理为了数据通信安全而产生的一组对称加密解密秘钥。从这三组秘钥的关系来看,一个共识扮演着重要角色。拓展: 一般的摘要算法MD5、SHA。成为中间人的方法ARP欺骗、ICMP攻击。
正式进入传输层的学习
学完HTTP和HTTPS协议之后,应用层我们就算大功告成啦!当然在应用层还有非常多不同的协议,但凭借我们对HTTP协议的认知,我们明白在应用层,无论是何种协议,它都一定需要完成套接字的创建、数据序列化反序列化、数据接收响应和处理的工作。从网络协议栈来谈,它的工作就是确保应用程序之间能够正确、高效地通信,只不过此时基于应用层而言,它的工作重点则体现在成功接收/响应和数据处理方面上。而谈到数据处理,此时不同的开发者就可以根据不同的用户需求来设计不同的软件方案,从而让应用层蓬勃发展。So,对于我们而言,应用层才是我们生存的地方,谁让下层已经一成不变。但在当今这个时代,想要进入应用层的门槛越来越高,所以我们并不能局限于应用层,而需要不断深入,所以接下来我们就正式开始学习应用层的下一层,网络协议栈从上到下的第二层,大名鼎鼎的传输层吧!
传输层简单理解
一个问题,什么是传输层?应用层的下一层吗?答案显然不符合我的预期,俗话说的好,想法来源于生活,此时我们就可以举一个快递的例子。在生活中,所有人各司其职,当我们需要寄一个快递的时候,身为用户我们需要完成的工作很简单,只需要填写地址以及接收人的电话,然后交给驿站。最后在我们的认知里,这个快递就会被成功发送到目的地。同理在网络数据传输过程中,用户在应用层想要访问某个远端服务器,他只需要输入目标服务器的IP地址和端口号,然后通过网络协议栈将请求发送出去。类比上述例子,我们可以明白,当用户将数据处理完成之后,也就是经过应用层之后,它来到的一定就是传输层,此时传输层起的作用与驿站所起的作用相差无几。所以我们明白,当数据在应用层处理完成之后,并不是直接就发送到了网络之中,它必须经过网络协议栈,也就是必须经过传输层,由传输层起与驿站一样的作用,规定该数据应该什么时候发送、采用什么方式发送、发送过程出错了应该怎么办等独属于传输层的策略。并且结合之前所学有关封装和分用的知识,此时我们就意识到封装并不只是简单的两个字,其中涉及到了非常多的细节,这也就是我们学习传输层的意义所在。所以此时的一个问题我们就转变为:传输层如何封装?
深入理解端口号
在之前应用层学习套接字通信的过程中,我们明白通信双方是通过源IP、源端口、目的IP、目的端口的逻辑来定位,用IP来标识全网唯一的一台主机,端口号来标识全网唯一的一个进程,从而让网络通信抽象成进程间通信。因此我们需要明确,端口号只与进程相关联。并且明白,虽然不同的应用层协议都有与之配对的端口号,但是此端口号起的作用仅仅只是标识和区分。从浏览器的角度来看,为了降低用户使用浏览器的成本,并且兼容所有的Web服务器,浏览器就规定了URL的首部只能为HTTP/HTTPS,也就是浏览器默认只会访问Web服务器的80/443端口。所以也就导一个网站想要被浏览器访问,那么该网站使用的协议只能是HTTP/HTTPS,并且在用户不知道指定端口号的情况下,该网站程序的端口号只能是80/443。而从非浏览器客户端的角度来看,你具体使用什么端口号,都是有开发者自己决定的,你可以根据对应程序使用的协议来匹配对应的端口号,当然你也可以使用任意端口号,同理上述所说,端口号只与进程相关联。而为了标识区分不同的协议,达成一个共识,使得在某些方面变得更加便利,我们就将端口号进行范围划分,其中0~1023端口号代表的知名端口,提供给较为常见的协议使用,而1024 ~65535则默认为操作系统动态分配使用,如:当我们启动了本地主机上的微信程序,那么此时该微信进程的端口号就是其中的一个,而对于远端的微信服务器而言,因为其使用的协议通常为HTTPS协议,所以远端微信服务器进程的端口号在外界看来通常就是443,但对于其设计者而言,基于多方面的考量,如:减少非法访问和外部攻击,它也可能使用任意端口号。
查看网络状态指令
在Linux系统中,我们可以通过netstat或者ss指令来查看当前系统中所有的网络进程,其中配合该指令使用的选项如下:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项,默认不显示LISTEN相关
选项和指令相结合,所以平时我们经常使用的就是netstat -nltp、netstat -natp、netstat -naup
传输层协议之UDP
完成了上述基础知识的铺垫,此时我们正式开始学习传输层协议。当然对于传输层协议而言,它分为UDP协议和TCP协议,具体这两种协议有什么不同,在之前学习套接字编程时我们有进行简单介绍。而面对传输层有两种不同的协议,此时我们就必须先解决一个问题,同理上述所说,我们是通过源IP、目的IP、源端口、目的端口来保证全网唯一两个进程之间的通信,并且在通信过程中,数据都需要经过网络协议栈,那么问题来了,当数据想要从网络层交付到传输层,网络层应该如何识别这两种协议呢?换一种说法也就是网络层(操作系统)应该调用那种协议的代码呢?所以对于这个问题,此时基于传输层而言,它同理应用层中端口号可以标识不同的进程,只不过对于传输层而言,它使用协议号来标识不同的传输层协议(UDP/TCP)。对于UDP而言它的协议号为17,同理TCP协议号为6。当明确了协议号的概念之后,此时就可以分为两部分来学习传输层协议,首先我们从UDP协议开始。同理类比学习法,通过之前应用层学习的HTTP协议以及对于封装和分用的理解,我们明白对于UDP报文而言,它一定也是由报头(UDP报头)和有效载荷(应用层报文)组成。回顾应用层编码过程中我们用到的sendto和recvfrom接口,当然因为UDP协议是一个面向数据报的协议,所以它并没有发送缓冲区,而为了提高UDP协议接收数据的高效性,所以UDP协议具有接收缓冲区,也就是当时在应用层我们说,发送数据的本质就是将数据拷贝到下层缓冲区,接收数据就是从下层缓冲区读取数据的说话是不完全正确的。除了两种协议缓冲区之间的不同之外,更重要的是我们要明确,调用sendto和recvfrom接口并不只只意味着完成数据的拷贝,更为重要的是它会请求传输层完成对该数据的封装和分用。 所以此时我们就基于UDP协议来看看它是如何完成封装和分用功能的吧!当然想要深入理解,此时如下图所示,我们就需要一幅UDP协议示意图:
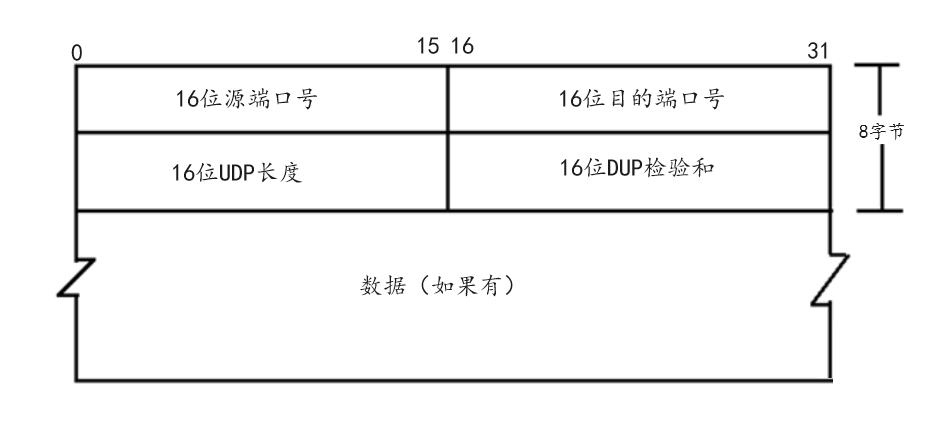
同理上述所说,因为UDP协议是一个面向数据报的协议,所以它不存在发送缓冲区,只存在接收缓冲区。并结合上述UDP协议示意图我们发现一个UDP报文的长度为16位(64KB),所以我们明确,如果应用层报文超过64KB,那么此时它就无法直接对其进行封装,而需要对其进行拆分。当然由于该部分知识还涉及到IP协议,也就是当UDP协议将大报文拆分成若干个小报文时,因为拆分过程是有序的,也就是封装过程是有序的,所以当IP协议在对其进行封装时,就可以通过一个叫序列号的字段来标识,以便于后续的报文还原过程。当然后续这个过程我们还会深入学习,此时只需要明白,对于UDP协议而言数据太大要拆分就行。同理上述所说,为了提高数据的接收效率,一般UDP协议也会有一个属于自己的接收缓冲区,而因为有了这个接收缓冲区,此时就有可能导致缓冲区存放了多段数据,并且明确该缓冲区中的数据一般是以字节为单位,也就是当应用层想要从该缓冲区读取其中一段数据,那么它一定是以字节流的方式读取,因为只有这样才能读取到完整、可靠的数据。明白了这点之后,结合上述UDP协议示意图,我们就很容易发现,因为UDP报文的报头固定大小为8字节,所以当我们读取接收缓冲区中的数据时,首先读取的就是该缓冲区的首部8个字节。当我们将报头读取之后,此时我们就可以通过报头中的UDP长度字段获取到该UDP报文的总长度,然后减去报头长度,最终获取到有效载荷的长度。而当我们获取到有效载荷的长度,此时我们就可以继续读取接收缓冲区该长度字节的数据,从而读取到一个完整的应用层报文,以此类推我们就可以将对端发送的数据全部读取到应用层了。当然最后该数据需要拷贝到那个进程的缓冲区中,此时操作系统就会根据对应的操作判断该进程绑定的端口号是否与UDP报头中的目的端口号匹配。当然根据上述这句话,我们可以明白,数据向上交付并不只是本层单独完成的,它也需要上层调用对应的系统调用接口(recvfrom)配合完成。注意: 有关UDP报头中的校验和字段我们忽略。
理解UDP协议下的封装和分用
明白了上述知识,对于UDP协议而言我们就学习完了,所以我们到底应该如何来理解封装和分用呢?当然对于上述所说的封装和分用,它只是一个宏观的过程,并不能让我们深入具体的理解封装和分用,那么此时我们就可以从代码的角度来理解。由于网络协议栈和操作系统之间的关系,我们明确传输层属于操作系统(Linux),并且因为操作系统是由C语言编码,所以对于传输层的UDP报头而言,它的本质就是一个结构体(struct udp_header),当然换一种说法也就是协议(UDP协议),类比当时在学习HTTP协议之前我们自己用标识符进行格式控制实现的协议,此时这种直接使用结构体作为协议的方法就会显得非常清晰。当然值得注意的是,之所以UDP协议可以直接使用结构体作为协议来传输数据,本质是因为对于网络协议栈(TCP/IP)而言,除了应用层之外,整个网络协议栈是不会改变的、是全网互通的,而应用层因为开发需求不同,就会导致数据在进行格式控制时使用的协议不同,当然也就是结构体不同,所以应用层不允许直接使用结构体进行通信,当然也就是我们之前为什么要学习序列化和反序列化的本质原因。如下图就是UDP协议代码理解:
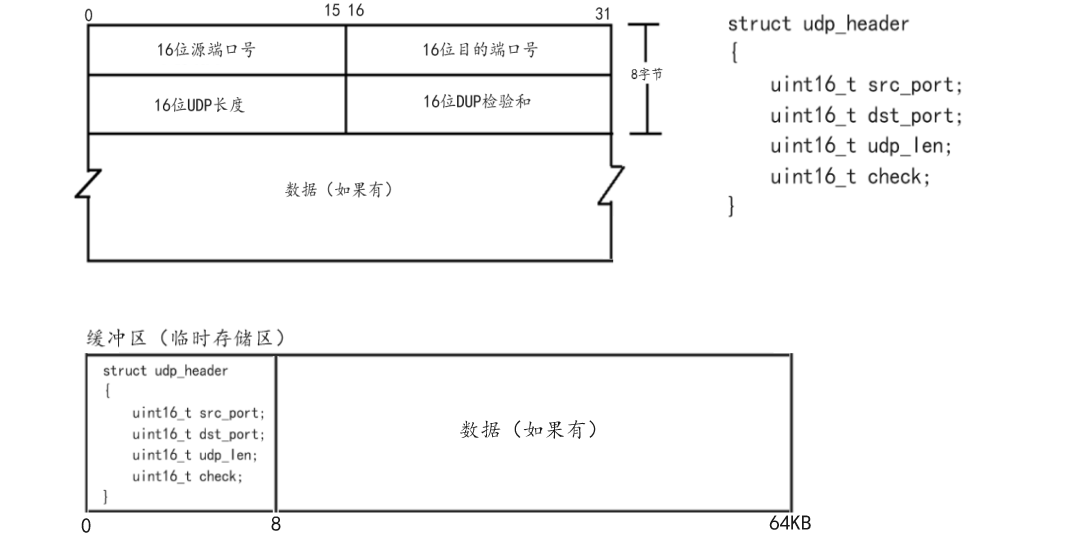
同理上述所说,UDP报头的本质就是一个结构体数据,并且这个结构体数据是一成不变的。所以此时想要从代码角度理解封装,我们就有了一个很强的抓手,也就是对于UDP协议而言,封装的本质: 通过一个临时存储区和一个指针(步长/字节),也就是一个char*类型的缓冲区,通过对指针进行固定字节的移动,也就是让指针向后移动8个字节预留出存放报头数据的空间大小,然后将应用层报文拷贝到该指针之后的空间中。当应用层报文拷贝完成之后,此时再将char *类型的指针还原到起始位置,并且将其强制类型转换成struct udp_header *指针类型,最后依据已知和该指针变量读取udp_header中的变量并赋值,至此封装过程完成,UDP报文前往网络层。当然值得注意的是,也就是回应之前所说,应用层调用sendto接口并不只是单纯的拷贝数据,而是通过该系统调用让操作系统完成数据封装工作,当然也就是上述代码的执行,所以明确上述无论是空间的预留,还是类型的强壮,亦或者是报头的变量的赋值,都是操作系统通过特定的代码完成。而我们需要明确的数据的来源,也就是目的端口、源端口、长度、校验和(不考虑)是如何得到的。对于源端口号而言则非常明确,一定是操作系统通过特定的操作动态生成的,而目的端口号则是通过系统调用接口参数获取到的,也就是sendto接口中的sockaddr_in参数获取,当然目的IP地址同理,最后是UDP长度,同理该数据来源也是sendto接口,只不过此时是其中的第三个参数size_t len参数,通过应用层提前计算好发送数据的大小提供给系统调用接口,当然也就是操作系统,然后操作系统根据规则默认加8,从而构成了该长度大小。同理解包过程,当然也就是分用的本质: 还是将数据拷贝到一个char *类型的缓冲区中,然后先获取前8个字节并同理将其类型转换成struct udp_header *指针类型,读取对应变量数据,获取UDP长度,再减去报头长度,得到应用层报文长度,最后向后读取该长度字节的数据。当然最后如何进行数据交付,上述详谈,也就是让操作系统进行匹配操作。
上述内容就是有关UDP协议的学习,对于UDP协议的特点无连接、不可靠、面向数据报而言之前介绍过,这里我们再重点理解一下面向数据报,区别于TCP的面向字节流,面向数据报也就是UDP协议在读取数据时,每一次数据读取都是固定的,也就是对端每一次发送多少,对应我就只能读取多少,无法像TCP一样,读取任意字节大小的数据。其次明确,因为UDP协议没有发送缓冲区,只有接收缓冲区,所以它们不存在共享资源的概念,所以允许一边读取,一边发送,也就是对于UDP协议而言,它是全双工的,反之称为半双工。拓展: 查看进程ID指令pidof 进程名