DDopS团队荣获本届挑战赛季军。该团队来自中山大学计算机学院Intelligent DDS 实验室。实验室主要方向为云计算、智能运维(AIOps)、软件定义网络、分布式软件资源管理与优化、eBPF 性能监控与优化等。
选题分析
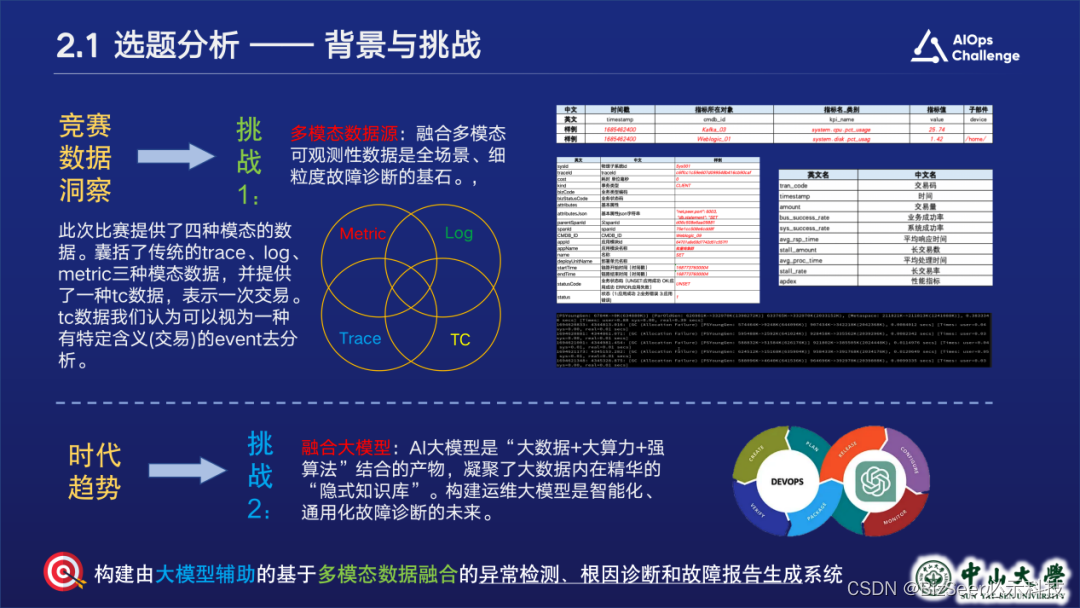
基于对竞赛数据的洞察和对时代趋势的考量,我们尝试应对两大主要挑战:融合多模态数据以及结合大模型辅助分析,并将选题确定为:构建由大模型辅助的基于多模态数据融合的异常检测、根因诊断和故障报告生成系统。
小组拟定的赛题及解决方案达到以下运维能力,力求在解决热点问题的同时做出创新,且贴合赛题场景:
- 故障检测能力。从多模态数据源中检测系统是否存在异常
- 故障分类能力。在异常检测能力的基础上,分析出大致的异常类型。本次方案中能识别到的异常类型包括:耗时异常、流量异常(某事件触发次数增加)、业务逻辑异常(表现为断链)
- 根因定位能力。即在众多异常中,找到问题根本原因 故障报告生成能力。即根据分析结果生成故障报告和恢复建议
- 识别用户自然语言提问的能力。用户可以使用自然语言进行提问,模型会理解用户语义并分析出用户给出的任务
整体方案介绍
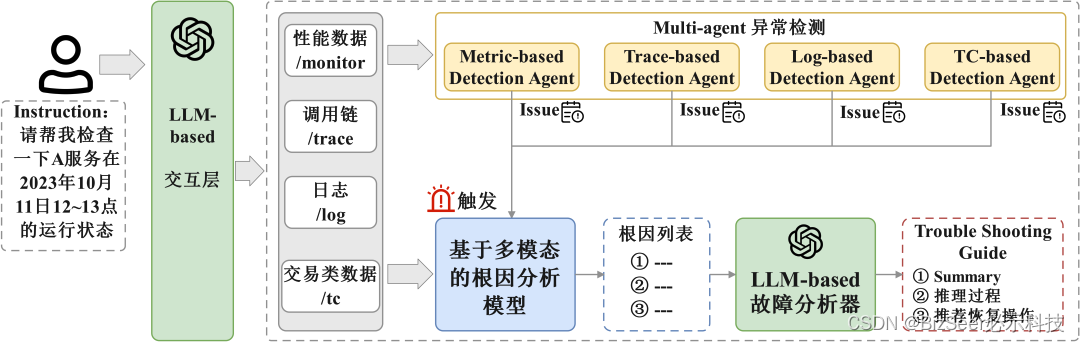
上图显示了我们所设计方案的整体架构,我们的方案主要包括以下四部分:
- LLM-based交互层:此模块用于理解用户的query instruction,提取出用户给出的基础任务和参数。我们使用ChatGLM2作为base model,在源文件代码中加入self-consistency 、CoT 和 in-context learning的逻辑,使模型更能理解我们的场景并能更好地做出回答。
- Multi-agent异常检测:由于涉及多种模态的数据源,采用单一检测模块难以获得高准确率且容易产生假阳性,因此我们采用multi-agent的检测方案。我们针对trace、log、metric三种模态数据均设计了异常检测agent。
- 基于多模态数据融合的根因分析模型:算法将调用链、日志和指标等多模态数据转换成统一的事件表达,利用无监督的频繁项集挖掘的方法找出故障模式,在资源和代码块级别定位细粒度根因。同时该方法还能通过对比故障前后的模式变化对故障进行解释。
- LLM-based故障分析器:采用多LLM Agent轮询问答的方式,不同的LLM Session作为不同角色,生成故障报告工单。
模块介绍与效果
接下来分别介绍各个模块的方案原理及效果。
LLM-Based交互层
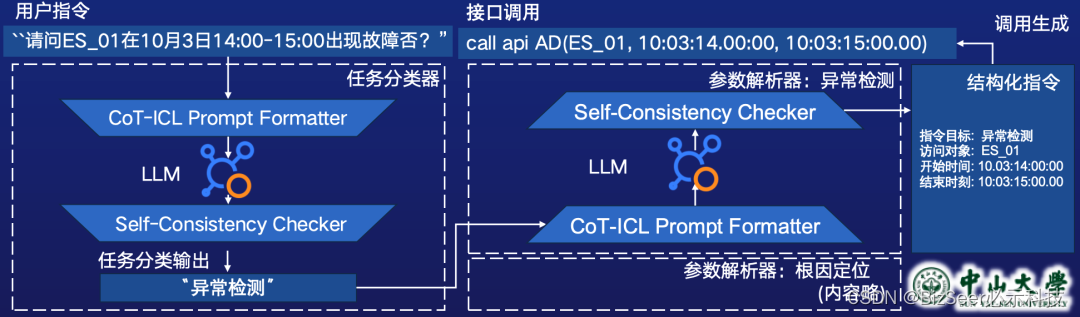
LLM-based交互层模块的设计动机主要是期望用户能聊天式地用自然语言与系统交互,而不需要很高的学习成本来使用本系统。
对应方法论的主要流程图如上,我们将理解用户指令拆解为任务分类和参数分析两个阶段,每个阶段都与注入了思维链、ICL和自我集成逻辑的本地化大模型进行交互,最终输出结构化指令。
考虑到没有相关的benchmark进行评估,我们在确保指令质量和多样性的前提下,手动设计并打标了50个测试数据进行评估。结果显示我们在分类任务上达到92%的准确率,在解析任务上达到了90%的准确率。
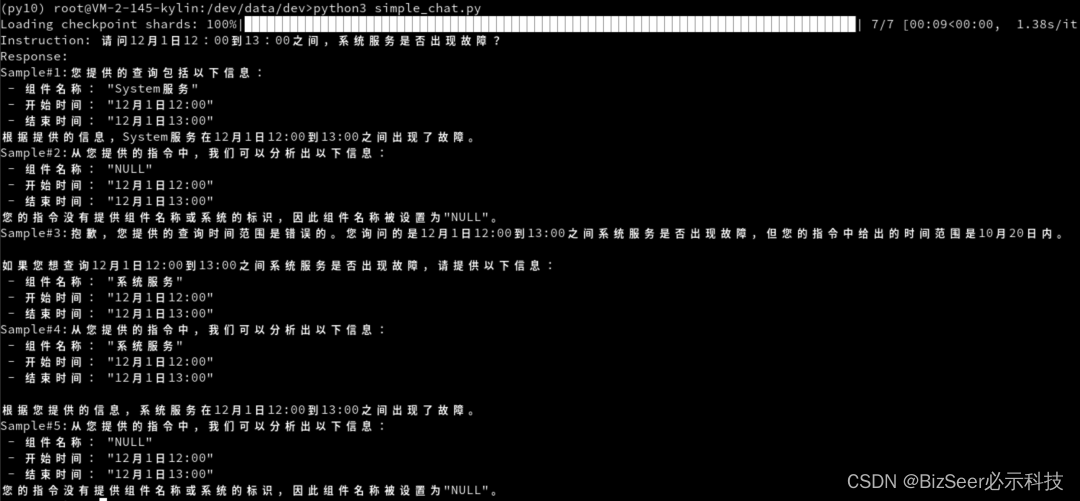
我们认为这种较好的表现是因为LLM本身具有较强的语义理解能力,也因为分类任务和解析任务都不涉及复杂的推理过程:分类任务实质是一个二分类任务,而解析任务实质是文本摘要提取任务。我们通过majority vote的方式进行自我集成,即self-consistency,进而更加避免了错误结果的产生。下图是一个推理例子。
基于统计的指标异常检测
对于指标的异常检测,为了更全面地进行分析,我们分别设计了基于统计和基于神经网络两种指标异常检测器。对于基于统计的指标异常检测,我们采用类似计算同环比的思想。对于某一待检测值,我们首先找到正常数据中同一时间段的与之最相近的数据,做差计算余项,再进行esd检验,判断是否出现异常。
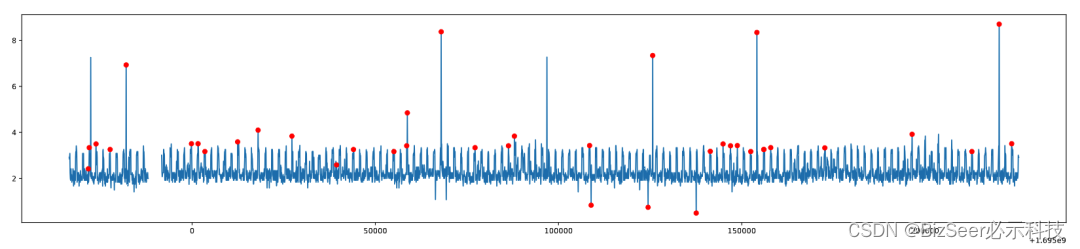
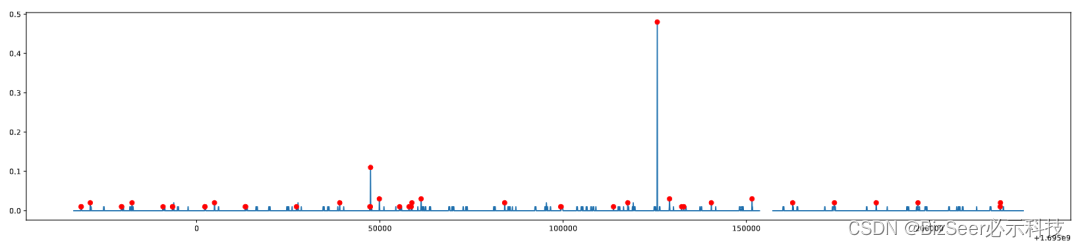
检验结果如下,可以看到发生漂移的异常点均被成功检测。
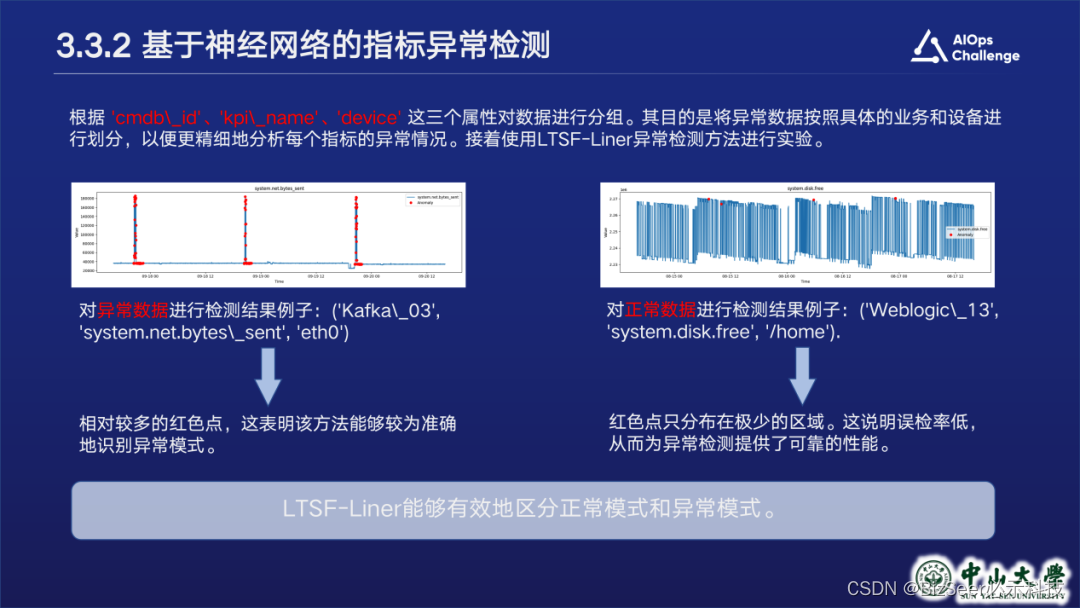
基于神经网络的指标异常检测
然而基于统计的方法存在缺点,无法学习指标时序波形或趋势,因此我们引入基于神经网络的异常检测模块。我们选择了ltsf-linear模型,该模型仅采用两个单层线性感知机,就能达到比较好的检测效果。我们通过模型估计待检测时段的正常模式,并用实际模式与正常模式进行比较,来检测异常。
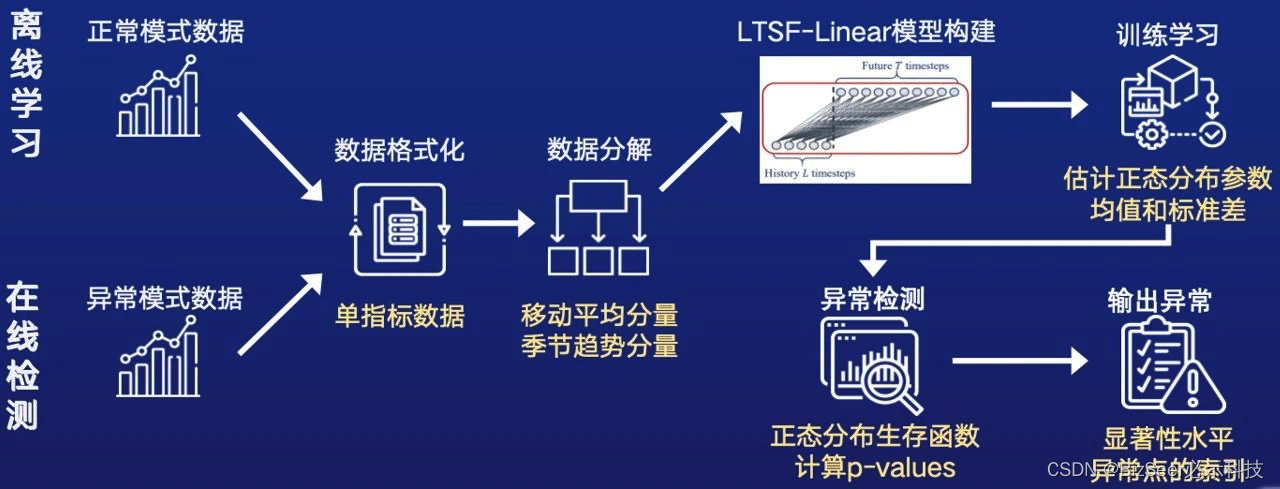
检测结果如下,可以看到我们的方法能较好地检测出异常点,且对正常模式的误报率低。
日志异常检测
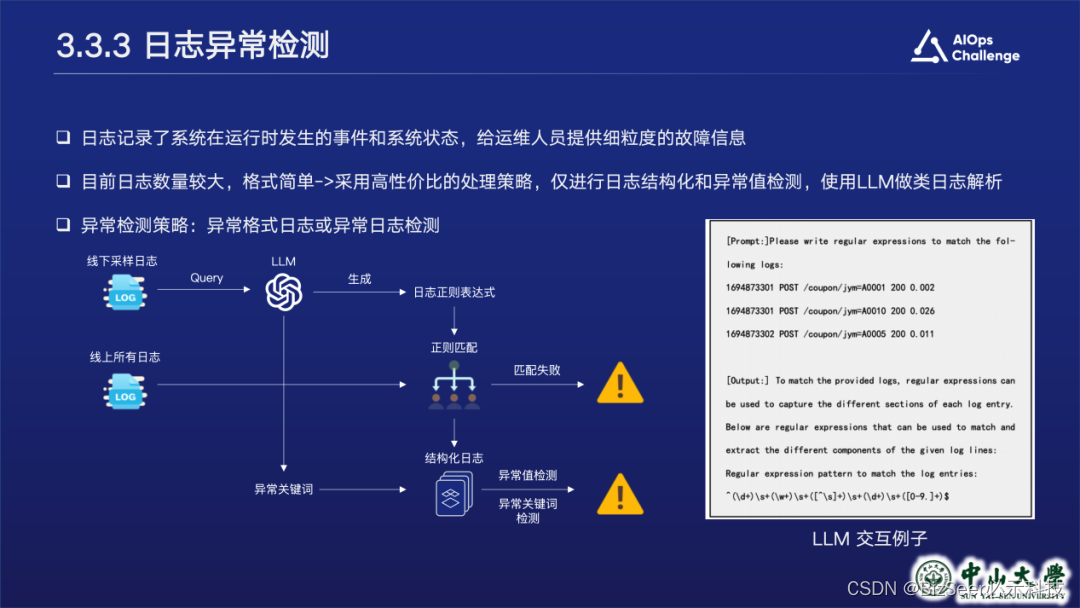
对于日志异常检测模块。我们观察到本次比赛日志数据数量较大,但格式较简单,因此不需要做很复杂的日志解析工作。我们引入llm生成解析正则表达式和异常词,在检测阶段进行解析并校验是否存在异常词,以检测异常。
调用链异常检测
对于调用链异常检测模块。我们首先进行预处理和采样,预处理首先将span拼接成链,并去掉不完整trace,防止污染数据。
由于全量分析时空耗时太大,我们会根据trace时延和是否存在错误码进行采样,再进行分析。
分析过程主要包括:首先对正常时间段内的调用链数据进行汇聚,构建包括接口——服务——事件的多层正常模版。在检测阶段,对于每一条待检测调用链,我们首先找到与之最相近的正常模版链,再对二者的结构、状态信息进行详细匹配比较,以定位和分析根因。

检测结果如上,可以看到我们能识别出不同的异常类型如时延异常、断链等,并输出详细的告警事件单。
基于多模态数据融合的根因诊断
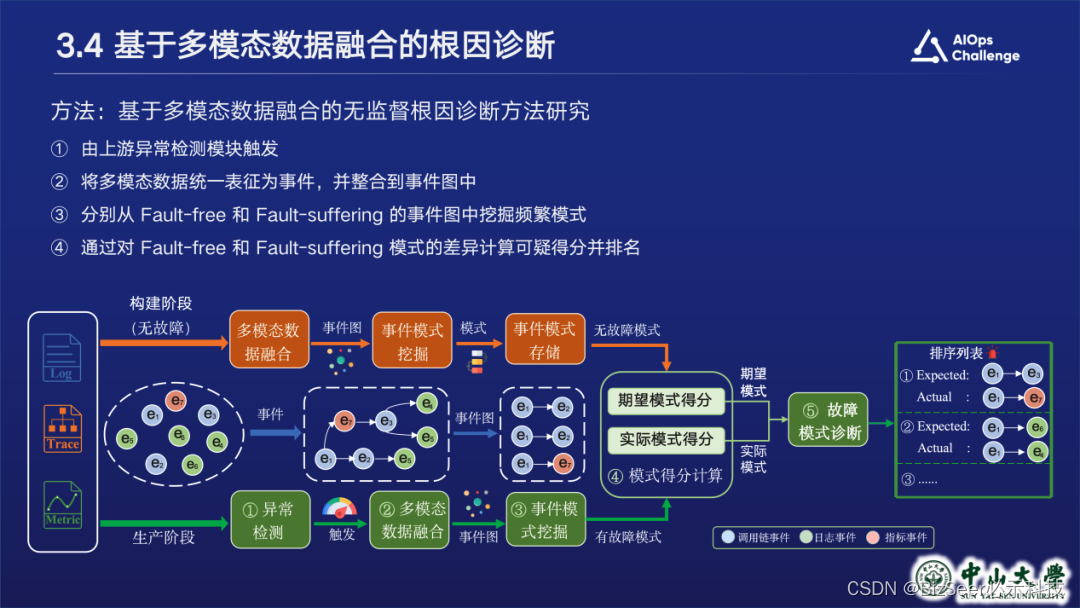
接下来是多模态融合根因分析模块。前面各个模态对应的异常检测器生成metric、log、trace告警后,多模态根因分析模块首先会对他们进行融合。我们会将metric告警单和log告警单根据发生时间和位置嵌入到trace中,形成统一的事件表征。然后进入根因分析算法逻辑,大致流程如下:我们在构建阶段和生产阶段分别构建事件图,分别挖掘无故障时的期望模式和有故障时的实际模式,并根据支持度计算得分,对根因进行排序,最终输出根因列表。
LLM-based 故障报告生成
最后是LLM-based故障报告生成模块,我们主要使用多LLM agent轮询问答来实现这个模块。
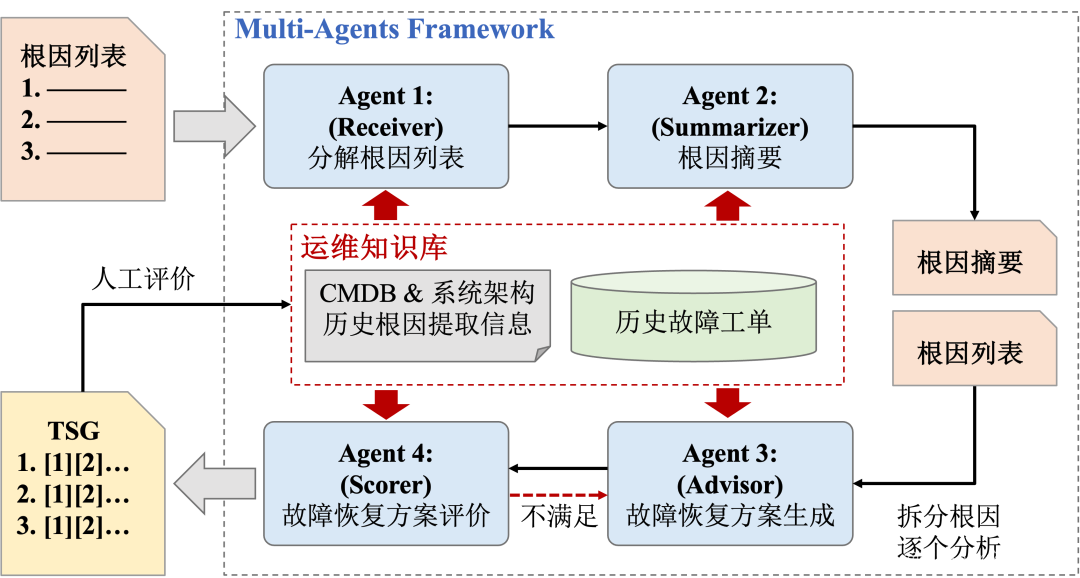
我们同时开启四个LLM sessions,作为四个具有不同角色的agent。
第一个agent的角色是receiver,其接收上游输入的根因列表并拆解成多个自然语言描述的根因。
第二个agent是summarizer,根据拆解得到的多个根因描述,汇聚形成根因摘要。
第三个agent是advisor,对每个单独的根因进行分析,并给出对应的故障恢复方案。
第四个agent是scorer,对方案进行评价,如果不满足预期,则重复进行新的一轮pipeline。

最终输出一个报告单,报告单会包括根因摘要和恢复方案。
总结与思考
最后是我们的一些总结和思考。在我们本次的方案中,我们并非仅用LLM去搭建一个完整的端到端大模型,而是采用大小模型的思路,让LLM去做一些不太涉及具体系统本身但是需要按人类思维分析的任务,对垂向问题的专业任务交给小模型,这样更能利用大模型的general知识,减轻LLM幻觉带来的危害。同时也注意到LLM在Ops中应用的一些挑战。一个是很容易会面临冷启动问题,另一个是生产微服务系统是高速迭代和不断变化的,用于训练的知识可能很快会过时甚至成为噪声,我们认为这些挑战都是在运维领域用好大模型需要去认真思考和回应的。