参考:
【1】 https://lilianweng.github.io/posts/2018-08-12-vae/
写在前面:
只是直觉上的认识,并没有数学推导。后面会写一篇(抄)大一统文章(概率角度理解为什么AE要选择MSE Loss)
TOC
- 1 AutoEncoder
- 2 Denoising AutoEncoder
1 AutoEncoder
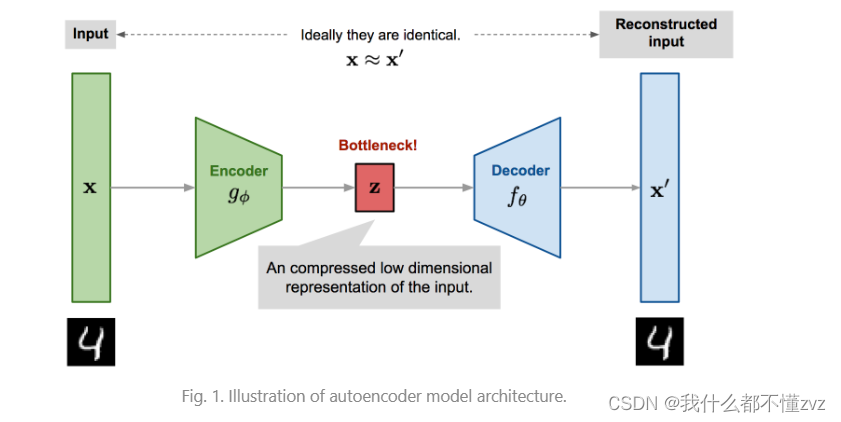
AE实际上是一个压缩模型,它通过将输入
x
x
x传进encoder将图像压缩到隐式特征(latant representation),然后再通过decoder输出
x
′
x'
x′,试图重建出
x
x
x。既重建公式为该两个变量的均方差损失:
L
=
∣
∣
x
−
x
′
∣
∣
2
=
1
N
∑
i
=
1
N
(
x
i
−
x
′
i
)
2
L=||x-x'||^2=\frac{1}{N}\sum_{i=1}^N(x^i -x'^i)^2
L=∣∣x−x′∣∣2=N1i=1∑N(xi−x′i)2
如果成功训练好一个AE,那么encoder就可以说能正确提取出输入 x x x的重要特征,而decoder也可以根据这些重要特征还原出与输入 x x x相近的 x ′ x' x′。
但AE仅仅是在学习等式函数 x = x ′ x=x' x=x′,所以很容易就过拟合了(神经网络有强大的拟合函数的能力),过拟合之后那么其仅对训练集数据表现很好,对未知数据的表现就一塌糊涂了。
2 Denoising AutoEncoder
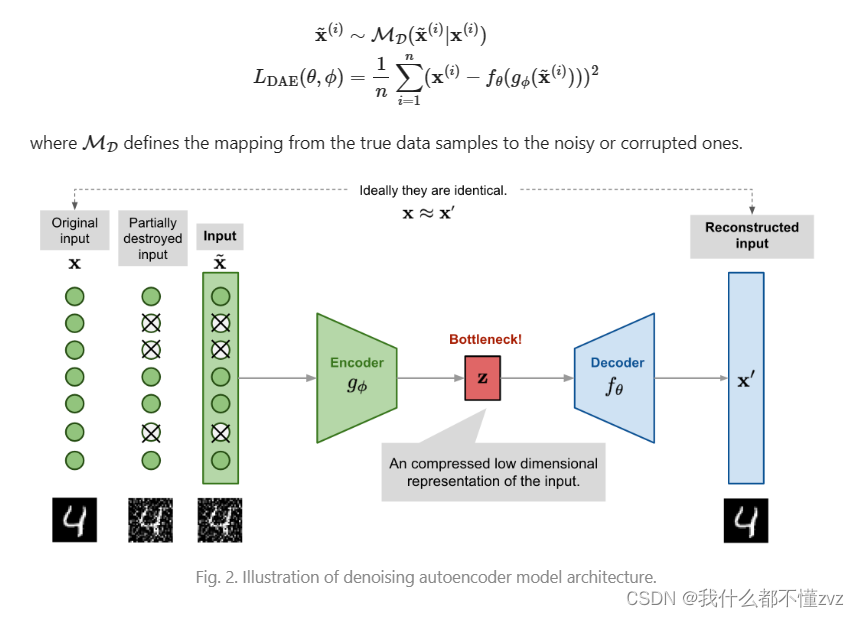
DAE相当于该模型上了强度,与其给你看完整的东西,不如我遮盖一部分,让你猜这部分是什么,然后将这个东西还原出来(人类视觉方面,如果遮盖了某个东西的一部分,大概率我们还是能想象出来的)
输入到encoder的数据就由 x x x,变为 x ~ i ∼ M D ( x ~ i ∣ x i ) \tilde x^i \sim M_D(\tilde x^i|x^i) x~i∼MD(x~i∣xi),其中 x ~ \tilde x x~表示被破坏的,或者被噪声污染过后的 x x x。 M D M_D MD表示噪声的随即映射分布,或者被随机破坏(置0)的每个像素上的概率。总之就是这么一回事。
我们可以理解为,当一部分像素被破坏之后,对于图像这种高维输入且高度冗余的数据,模型就要根据其他的维度去预测损失的维度的数据,就不再是去过拟合一个维度,这就构建了一个很好的学习到鲁棒隐式特征的基础。
【一个不恰当的例子:比如看到1、2、3,AE就记住了1、2、3的特征,那么给数据1、3、4,那么它可能就还原不出4。但是看到1、2、_,GT为1、2、3,那么模型可能就会根据1、2去推理出3(比如1+2=3),那么给出数据1、3、4,对于4,模型也有能力根据1、3去推出,学习到了某些加法操作的特征】

![[HackMyVM] 靶场 Wave](https://img-blog.csdnimg.cn/direct/497d860c7f4a472a8a92f1c75f06557b.png)