知识出处:Hello算法:https://www.hello-algo.com/
文章目录
- 2.4 树
- 2.4.1 「二叉树 binary tree」
- 2.4.1.1 二叉树基本操作
- 2.4.1.2 二叉树的常见类型
- 「完美二叉树 perfect binary tree」
- 「完全二叉树 complete binary tree」
- 「完满二叉树 full binary tree」
- 「平衡二叉树 balanced binary tree」
- 2.4.1.3 二叉树的退化&进化
- 2.4.2 二叉树遍历
- 2.4.2.1 层序遍历 level-order traversal
- 代码
- 复杂度分析
- 2.4.2.2 前序、中序和后序遍历(DFS)
- 深度优先搜索通常基于递归实现。
- 深度优先遍历基于迭代的方式实现
- 2.4.3 二叉树数组表示
- 2.4.3.1 数组表示完美二叉树
- 2.4.3.2 数组表示任意二叉树
- 2.4.3.3 优点与局限性
- 2.4.4 二叉搜索树
- 2.4.4.1 二叉搜索树的搜索操作
- 查询
- 插入节点
- 中序遍历
- 2.4.4.2 搜索二叉树的效率
- 2.4.4.3 二叉搜索树常见应用
2.4 树
2.4.1 「二叉树 binary tree」
二叉树 binary tree是一种非线性数据结构,代表“祖先”与“后代”之间的派生关系,体现了“一分为二”的分治逻辑。与链表类似,二叉树的基本单元是节点,每个节点包含值、左子节点引用和右子节点引用。
/* 二叉树节点类 */
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点引用
TreeNode right; // 右子节点引用
TreeNode(int x) { val = x; }
}
-
每个节点都有两个引用(指针),分别指向「左子节点 left-child node」和「右子节点 right-child node」
-
该节点自身被称为这两个子节点的「父节点 parent node」.
-
当给定一个二叉树的节点时,我们将该节点的左子节点及其以下节点形成的树称为该节点的「左子树 left subtree」,同理可得「右子树 right subtree」。
-
在二叉树中,除叶节点外,其他所有节点都包含子节点和非空子树。也就是说,不包含子节点的节点就被称为「叶节点 leaf node」
二叉树的常用术语如图所示。
- 「根节点 root node」:位于二叉树顶层的节点,没有父节点。
- 「叶节点 leaf node」:没有子节点的节点,其两个指针均指向
None。 - 「边 edge」:连接两个节点的线段,即节点引用(指针)。
- 节点所在的「层 level」:从顶至底递增,根节点所在层为 1 。
- 节点的「度 degree」:节点的子节点的数量。在二叉树中,度的取值范围是 0、1、2 。
- 二叉树的「高度 height」:从根节点到最远叶节点所经过的边的数量。
- 节点的「深度 depth」:从根节点到该节点所经过的边的数量。
- 节点的「高度 height」:从距离该节点最远的叶节点到该节点所经过的边的数量。

Tip:
- 请注意,我们通常将“高度”和“深度”定义为“经过的边的数量”,但有些题目或教材可能会将其定义为“经过的节点的数量”。在这种情况下,高度和深度都需要加 1 。
- 如何理解深度和高度?
- 深度是根部到该节点的举例,高度是该节点到叶节点的距离
- 深度可以表示找到这个节点需要花费的时间,深度越深,找到这个节点就经过更多边,也需要更多时间。可以用于判断“查询”操作所需的时间
- 高度可以表示从这个节点到最外层需要花费的时间,高度越高,找到叶节点的时间就需要花费更多时间。可以用于判断遍历“该子树所有节点”所需的时间。
- 另外,深度只能描述某个节点的深度,而高度既可以直接表示树,也可以描述某个节点。
2.4.1.1 二叉树基本操作
初始化
与链表类似,首先初始化节点,然后构建引用(指针)。
插入与删除节点
与链表类似,在二叉树中插入与删除节点可以通过修改指针来实现
注意:
插入节点可能会改变二叉树的原有逻辑结构,而删除节点通常意味着删除该节点及其所有子树。因此,在二叉树中,插入与删除通常是由一套操作配合完成的,以实现有实际意义的操作。
2.4.1.2 二叉树的常见类型
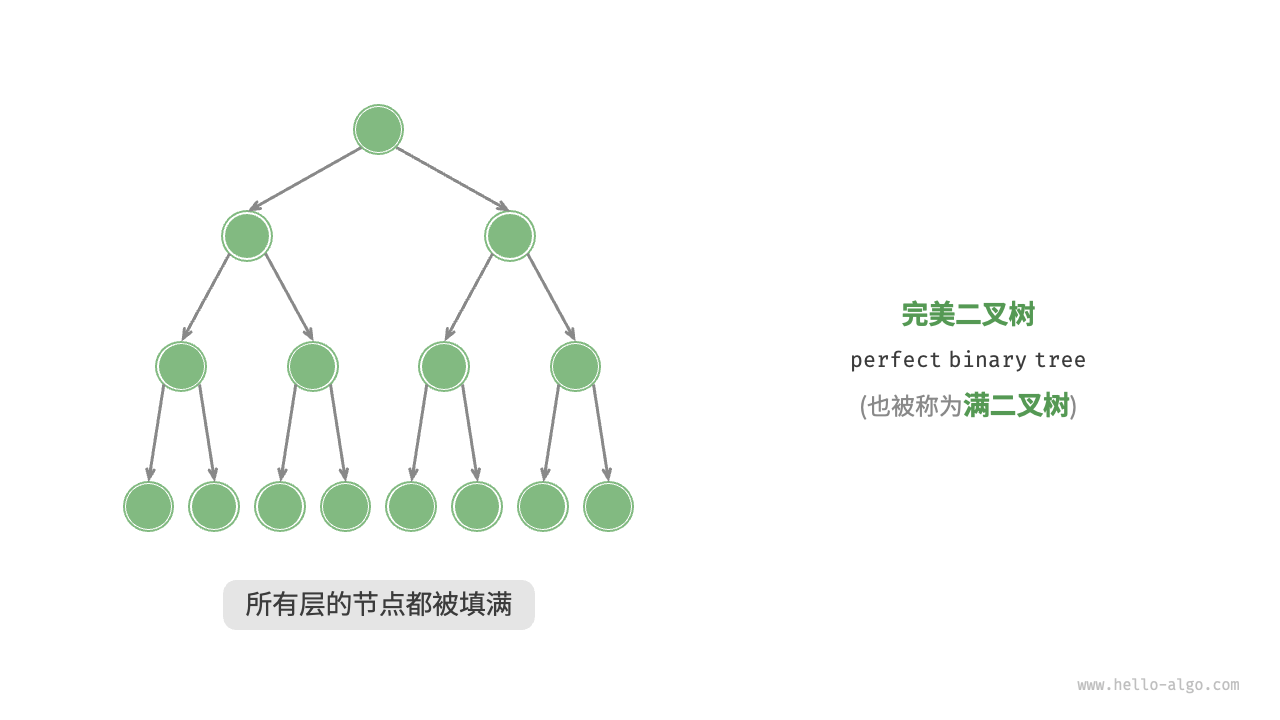
「完美二叉树 perfect binary tree」
完美二叉树(又称“满二叉树”)是所有层的节点都被完全填满的二叉树,具有以下特点:
- 所有叶节点的度都为0,且其余所有节点都为0;
- 若树的高度为h,则节点总数为 2h+1−1 。呈指数级关系,反应了自然界中的细胞分裂现象。
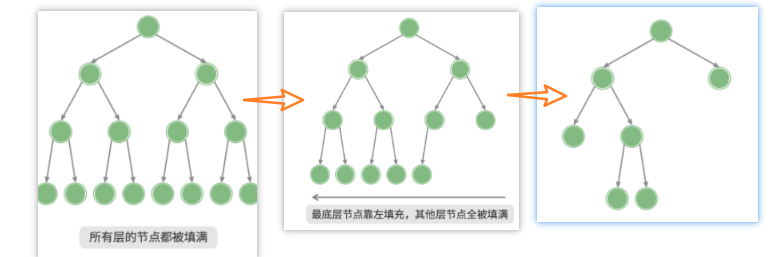
「完全二叉树 complete binary tree」
只有最底层的节点未被填满,且最底层节点尽量靠左填充。
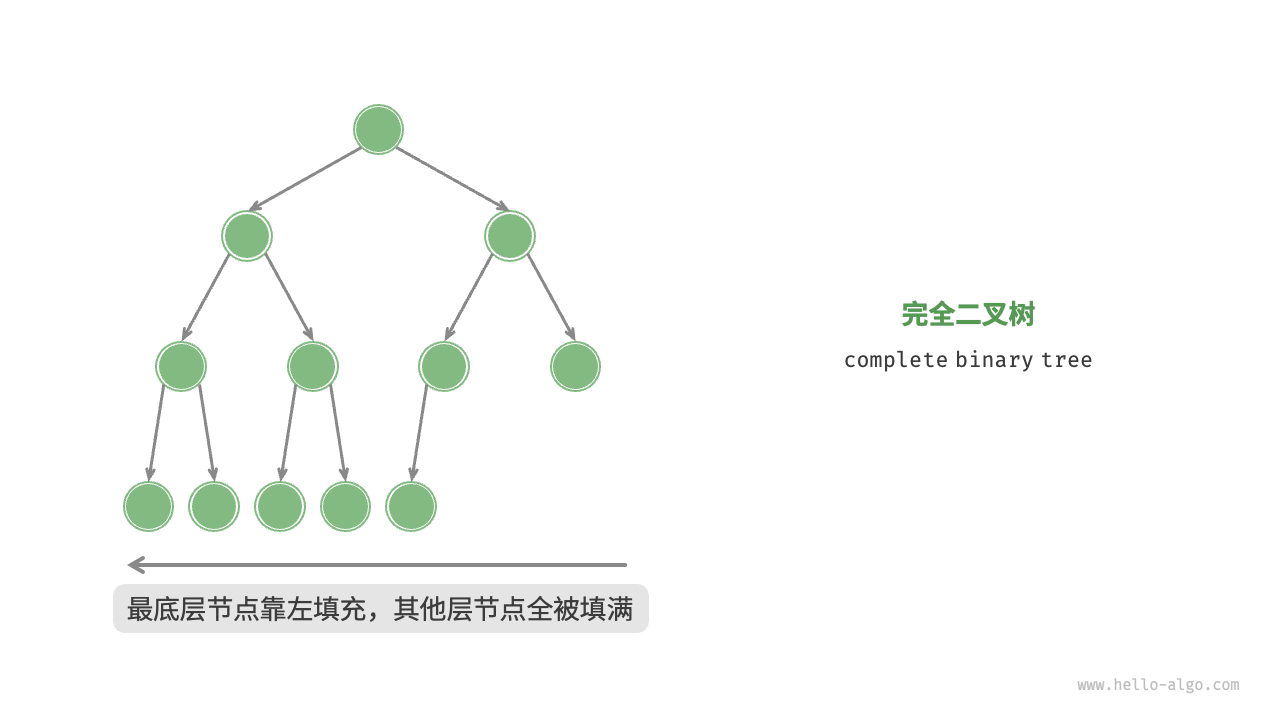
之前被忽略的类型,实际上这样的二叉树可以直接使用数组进行表示,需要有将一维序列转换换位二维序列的思维能力。
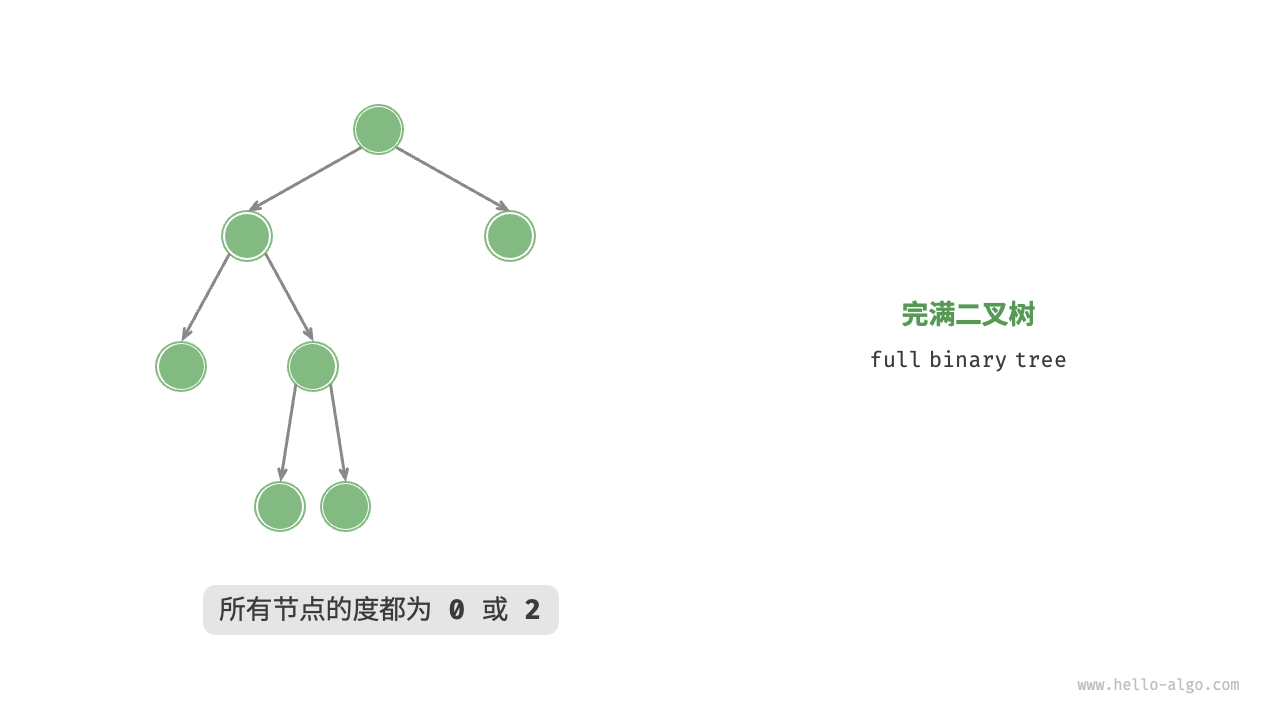
「完满二叉树 full binary tree」
除了叶节点之外,其余所有节点都有两个子节点。
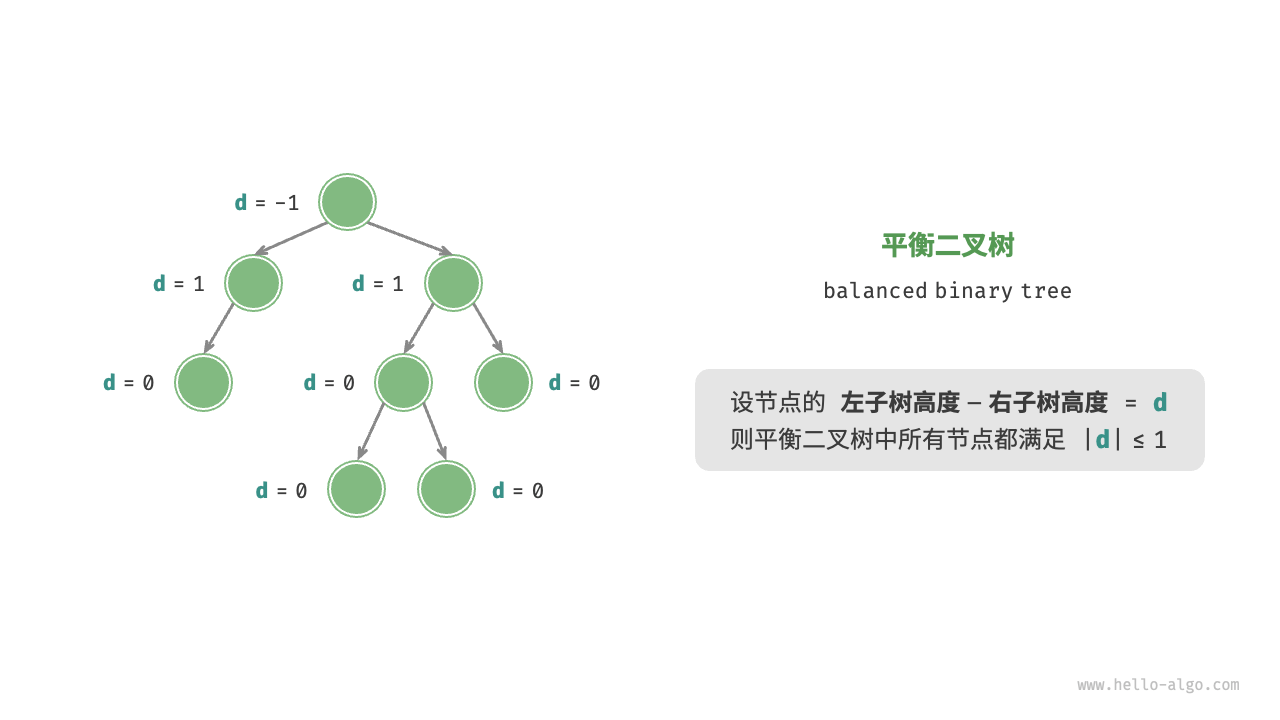
「平衡二叉树 balanced binary tree」
任意节点的左子树和右子树的高度之差的绝对值不超过 1 。
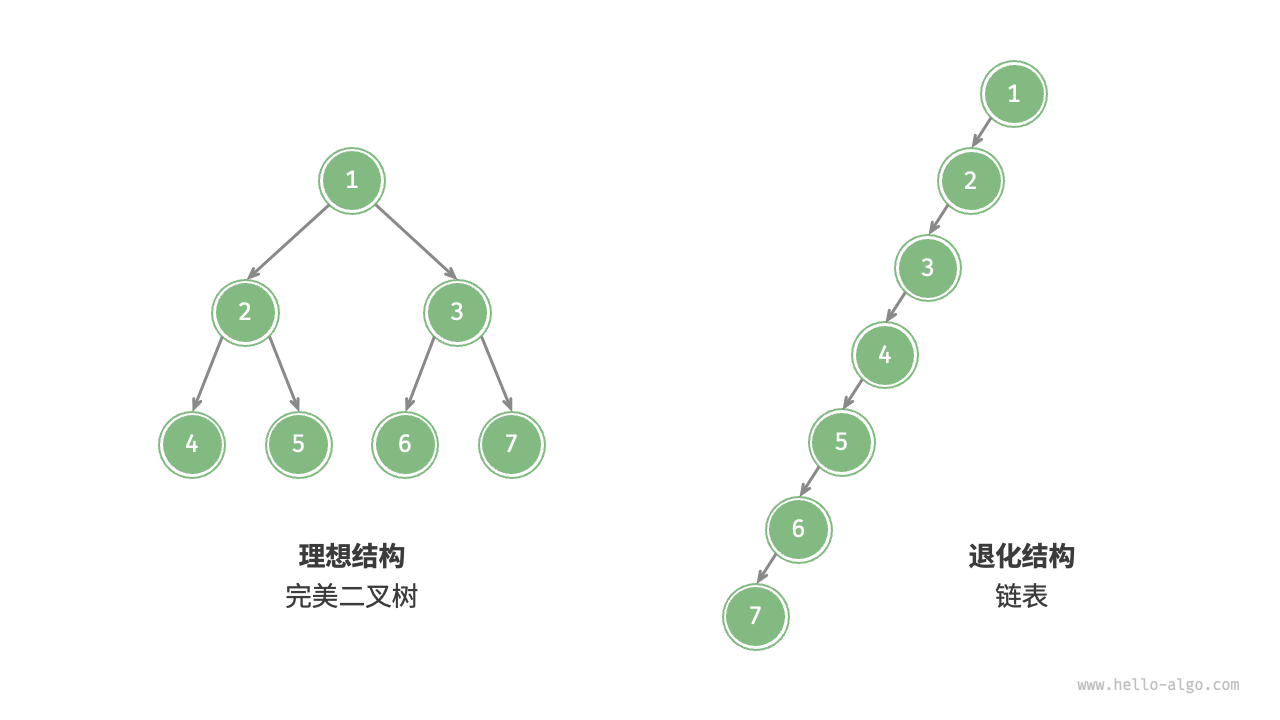
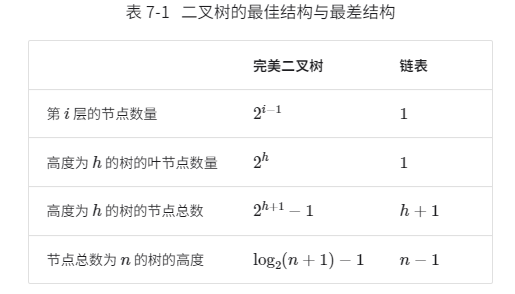
2.4.1.3 二叉树的退化&进化
当二叉树的每层节点都被填满时,达到“完美二叉树”;而当所有节点都偏向一侧时,二叉树退化为“链表”。
在最佳结构和最差结构下,二叉树的叶节点数量、节点总数、高度等达到极大值或极小值。
关于二叉树演变的个人理解
- 链表可以看成“所有节点的度都为1的二叉树”,是一种特化的二叉树,理论上适用于二叉树的计算公式,也适用于链表。反过来,链表拥有的部分特点在会在二叉树上实现。
- 二叉树的几种常用类型也有自身的演化过程:
- 平衡二叉树(左子树和右子树相差不大即可
- 圆满二叉树(非叶节点都有两个子节点)
- 完全二叉树(在圆满二叉树的基础上,要求节点都靠左)
- 完美二叉树(在完全二叉树的基础上,要求叶节点这层的节点都必须被填满)
2.4.2 二叉树遍历
链表的遍历方式是通过指针逐个访问节点。然而,从物理结构的角度来看,树是一种基于链表的非线性数据结构,这使得遍历树比遍历链表更加复杂,需要借助搜索算法来实现。
二叉树常见的遍历方式包括层序遍历、前序遍历、中序遍历和后序遍历等。(手敲代码帮助理解)
2.4.2.1 层序遍历 level-order traversal
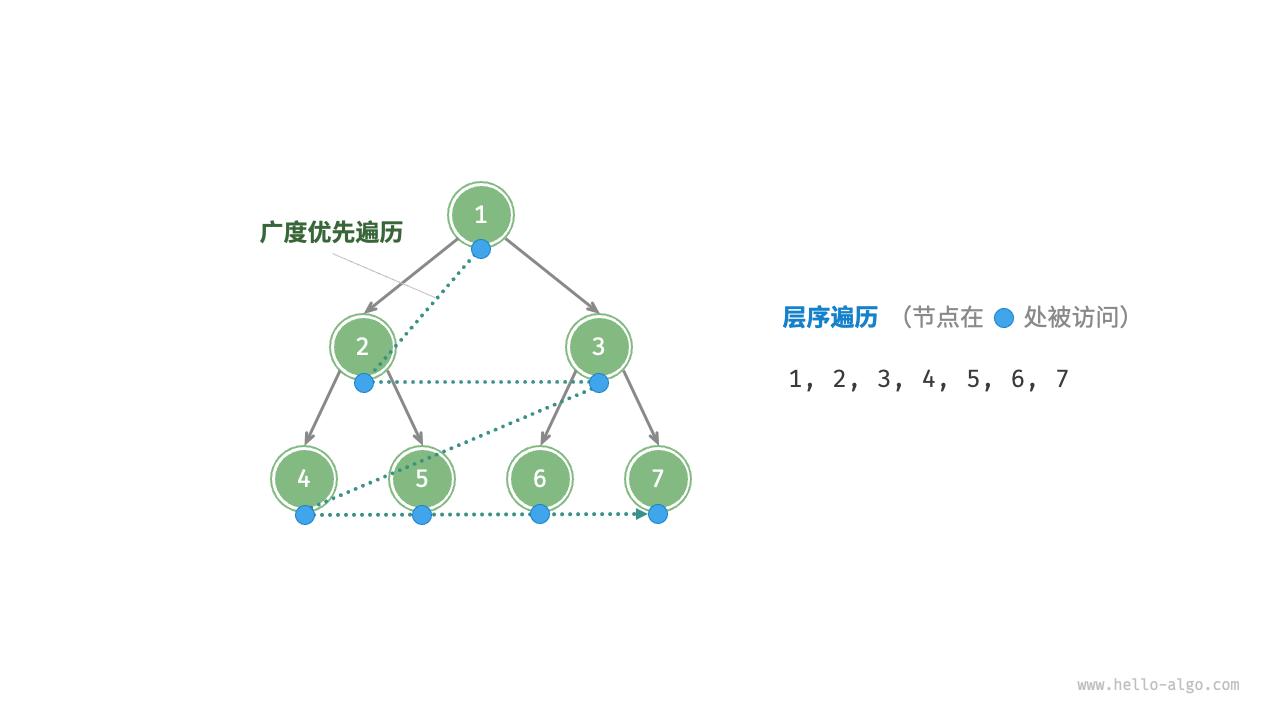
从顶部到底部逐层遍历二叉树,并在每一层按照从左到右的顺序访问节点。
层序遍历本质上属于**「广度优先遍历 breadth-first traversal」,也称「广度优先搜索 breadth-first search, BFS」**,它体现了一种“一圈一圈向外扩展”的逐层遍历方式。
代码
广度优先遍历通常借助“队列”来实现。
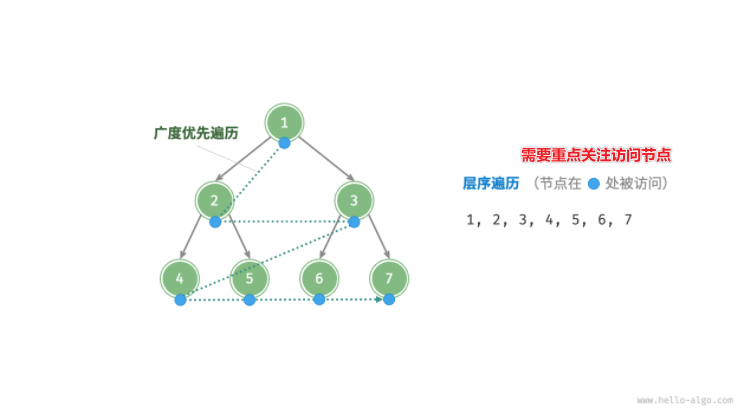
实现思路如下:
- 给出一个队列,先存入根节点; 给出一个列表,用于存储结果
- 遍历该队列
- 节点出队
- 像列表,存入数值
- 将出队的节点对应的节点(如有)入队
- 以此循环
// 层序遍历
Queue<TreeNode> treeNodeQueue = new ArrayDeque<>();
treeNodeQueue.add(n1);
List<Integer> resList = new ArrayList<>();
while (!treeNodeQueue.isEmpty()){
TreeNode node = treeNodeQueue.poll();
resList.add(node.val);
if (node.left != null){
treeNodeQueue.add(node.left);
}
if (node.right != null){
treeNodeQueue.add(node.right);
}
}
复杂度分析
- 时间复杂度为 O(n) :所有节点被访问一次,使用 O(n) 时间,其中 n 为节点数量。
- 空间复杂度为 O(n) :在最差情况下,即满二叉树时,遍历到最底层之前,队列中最多同时存在 (n+1)/2 个节点,占用 O(n) 空间。
2.4.2.2 前序、中序和后序遍历(DFS)
相应地,前序、中序和后序遍历都属于**「深度优先遍历 depth-first traversal**」,也称「深度优先搜索 depth-first search, DFS」,它体现了一种“先走到尽头,再回溯继续”的遍历方式。
深度优先遍历就像是绕着整棵二叉树的外围“走”一圈,在每个节点都会遇到三个位置,分别对应前序遍历、中序遍历和后序遍历,
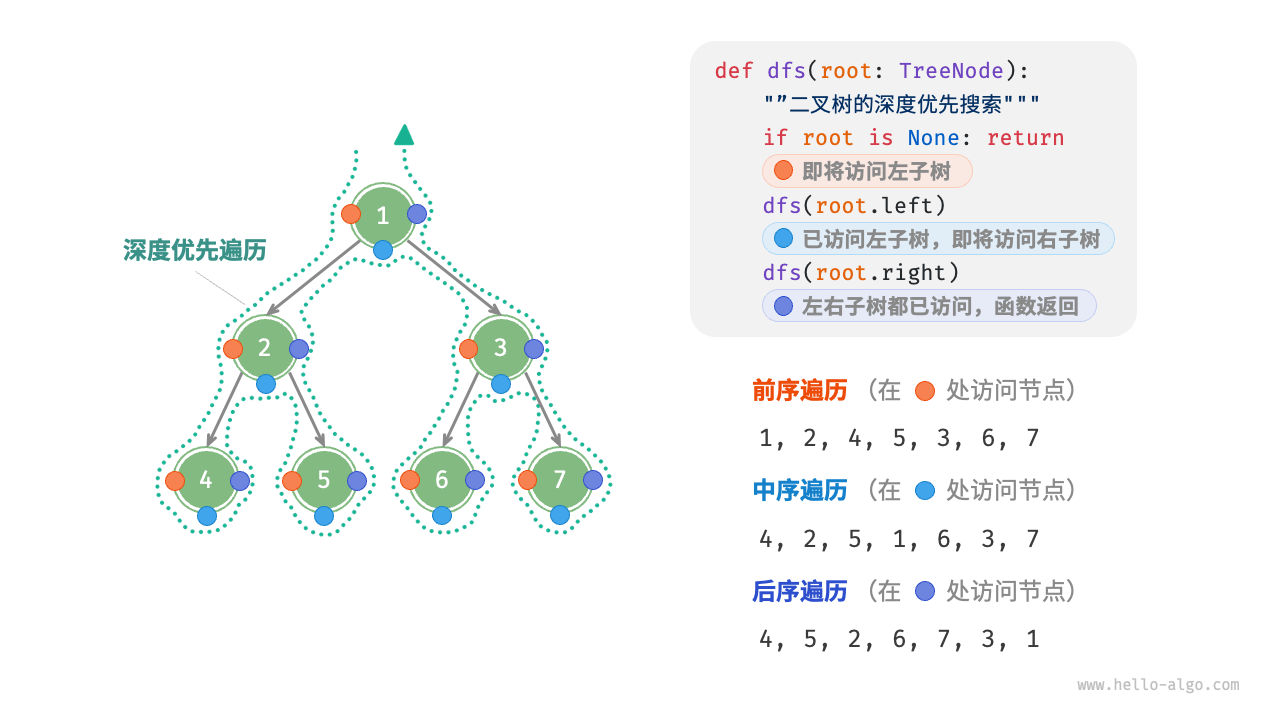
深度优先搜索通常基于递归实现。
递归过程,可分为“递”和“归”两个逆向的部分。
- “递”表示开启新方法,程序在此过程中访问下一个节点。
- “归”表示函数返回,代表当前节点已经访问完毕。
public static void main(String[] args) {
/* 初始化二叉树 */
// 初始化节点
TreeNode n1 = new TreeNode(1);
TreeNode n2 = new TreeNode(2);
TreeNode n3 = new TreeNode(3);
TreeNode n4 = new TreeNode(4);
TreeNode n5 = new TreeNode(5);
TreeNode n6 = new TreeNode(6);
TreeNode n7 = new TreeNode(7);
// 构建节点之间的引用(指针)
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;
n3.left = n6;
n3.right = n7;
System.out.println("\n初始化二叉树\n");
PrintUtil.printTree(n1);
resList.clear();
preOrder(n1, resList);
System.out.println(resList);
resList.clear();
midOrder(n1, resList);
System.out.println(resList);
resList.clear();
afterOrder(n1, resList);
System.out.println(resList);
}
/**
* 前序遍历
*/
static void preOrder(TreeNode node, List<Integer> res) {
if (node == null) {
return;
}
// 遍历节点本身
res.add(node.val);
// 遍历左节点
preOrder(node.left, res);
// 遍历右节点
preOrder(node.right, res);
}
static void midOrder(TreeNode node, List<Integer> res) {
if (node == null) {
return;
}
// 遍历左节点
preOrder(node.left, res);
// 遍历节点本身
res.add(node.val);
// 遍历右节点
preOrder(node.right, res);
}
static void afterOrder(TreeNode node, List<Integer> res) {
if (node == null) {
return;
}
// 遍历左节点
preOrder(node.right, res);
// 遍历右节点
preOrder(node.left, res);
// 遍历节点本身
res.add(node.val);
}
深度优先遍历基于迭代的方式实现
力扣找到的解法:解答思路
我们也可以用迭代的方式实现方法一的递归函数,两种方式是等价的,区别在于递归的时候隐式地维护了一个栈,而我们在迭代的时候需要显式地将这个栈模拟出来,其余的实现与细节都相同,具体可以参考下面的代码。
Stack<TreeNode> stack = new Stack<>();
TreeNode node = n1;
List<Integer> res = new ArrayList<Integer>();
while (!stack.isEmpty() || node != null) {
while (node != null) {
res.add(node.val);
stack.push(node);
node = node.left;
}
node = stack.pop();
node = node.right;
}
2.4.3 二叉树数组表示
2.4.3.1 数组表示完美二叉树
原文中给出的图非常直观的展示了数组如何表示二叉树
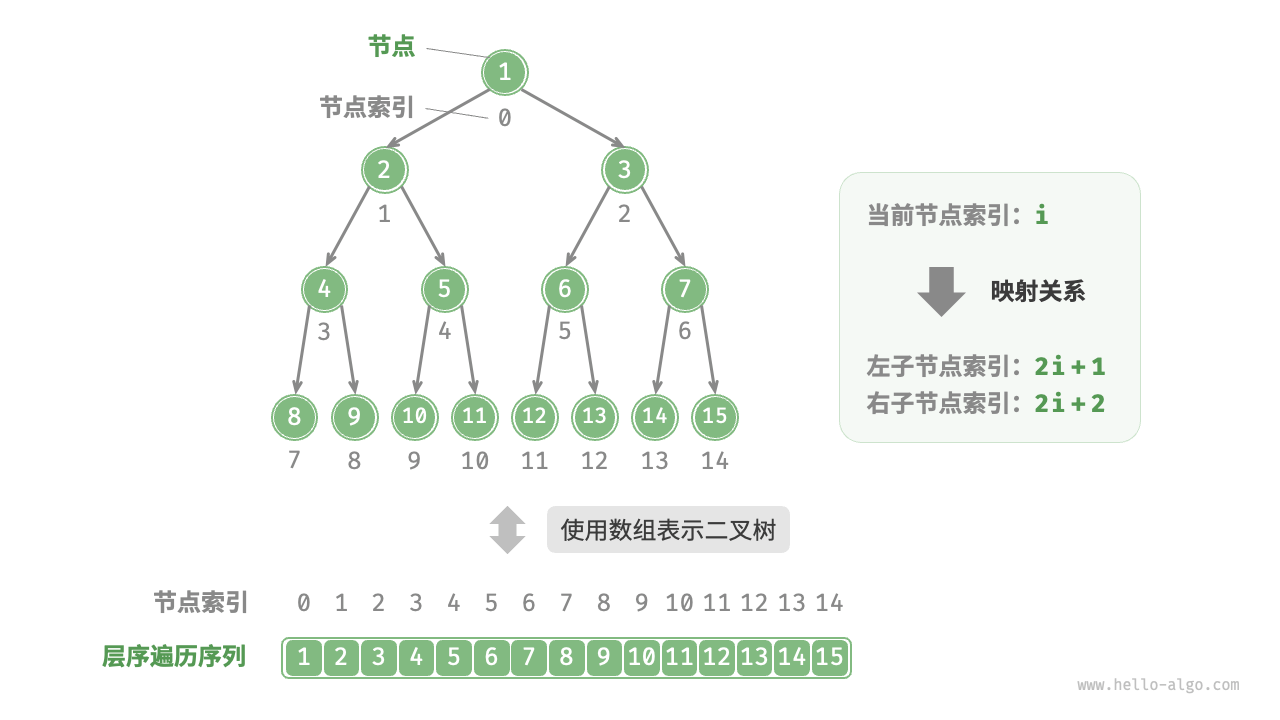
2.4.3.2 数组表示任意二叉树
在上面的基础上,显式地写出所有 None
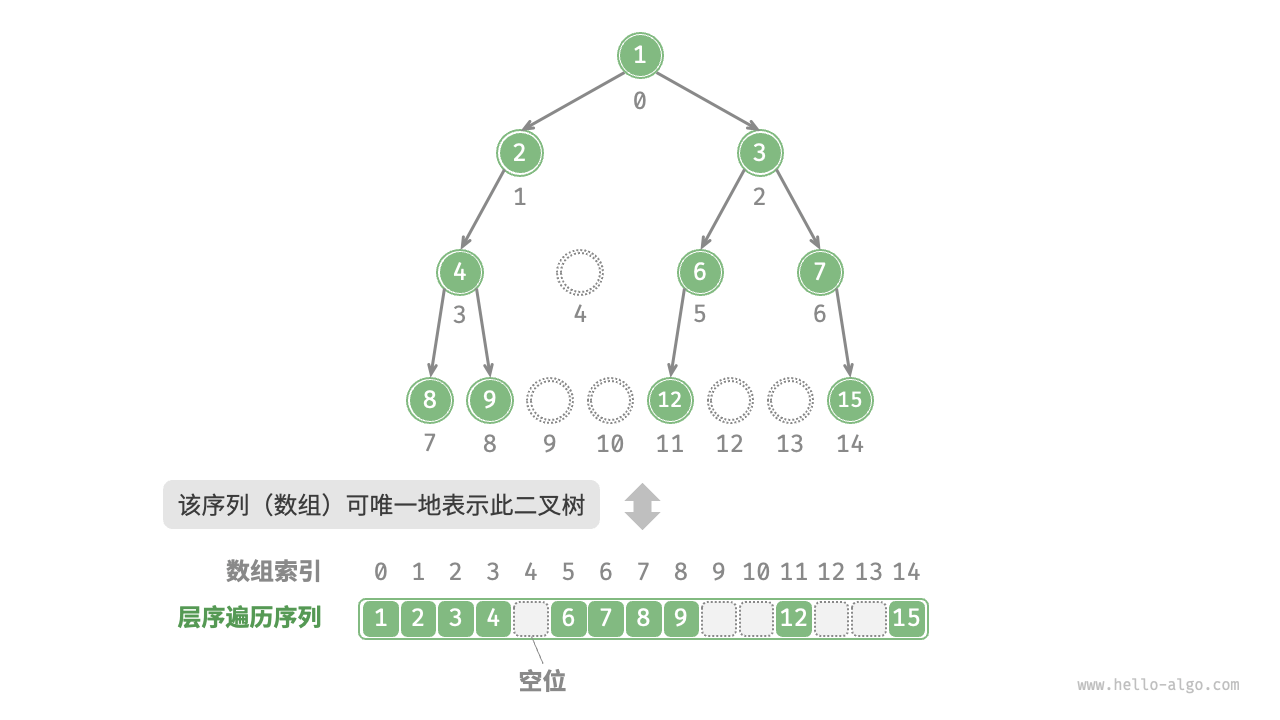
综上不难发现,,完全二叉树非常适合使用数组来表示。回顾完全二叉树的定义,None 只出现在最底层且靠右的位置,因此所有 None 一定出现在层序遍历序列的末尾。
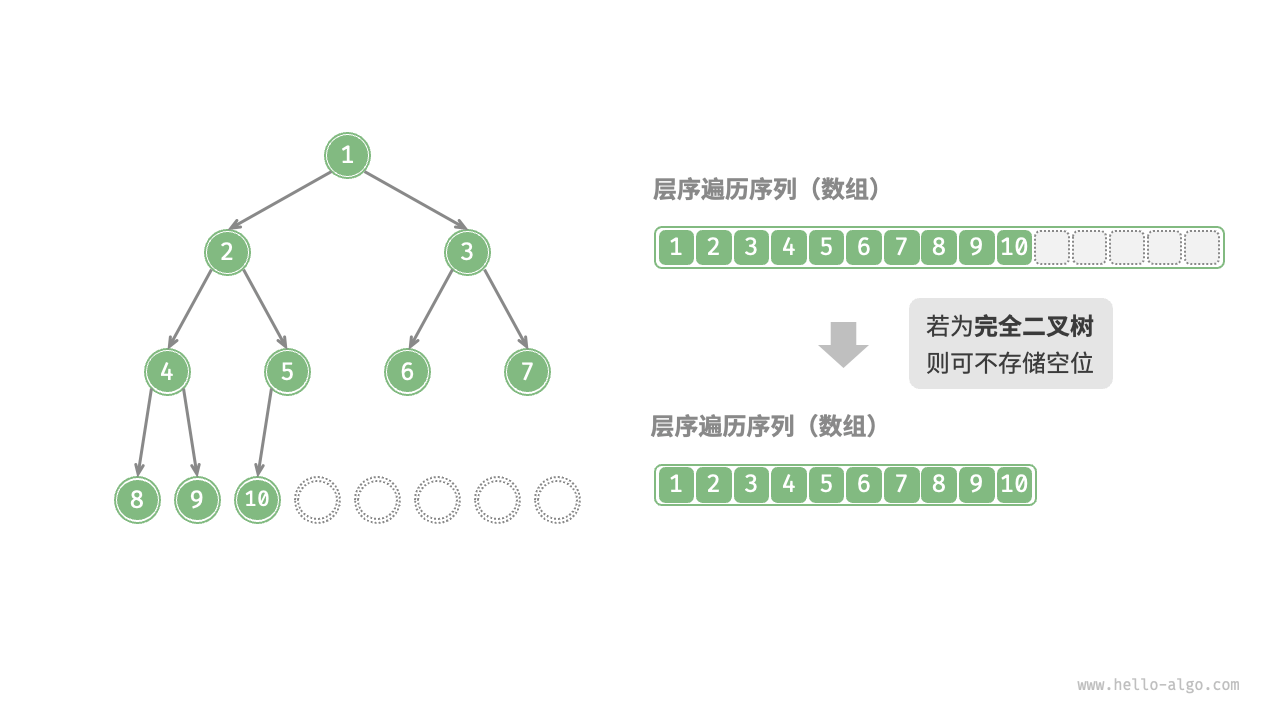
代码实现
尝试用List<Integer>来表示的二叉树,实现以下操作:
- 给定某节点,获取它的值、左(右)子节点、父节点。
- 获取前序遍历、中序遍历、后序遍历、层序遍历序列。
2.4.3.3 优点与局限性
二叉树的数组表示主要有以下优点。
- 数组存储在连续的内存空间中,对缓存友好,访问与遍历速度较快。
- 不需要存储指针,比较节省空间。
- 允许随机访问节点。
然而,数组表示也存在一些局限性。
- 数组存储需要连续内存空间,因此不适合存储数据量过大的树。
- 增删节点需要通过数组插入与删除操作实现,效率较低。
- 当二叉树中存在大量
None时,数组中包含的节点数据比重较低,空间利用率较低。
2.4.4 二叉搜索树
「二叉搜索树 binary search tree」满足以下条件。
- 对于根节点,左子树中所有节点的值 < 根节点的值 < 右子树中所有节点的值。
- 任意节点的左、右子树也是二叉搜索树,即同样满足条件
1.。
和“堆”的概念近似,也要做出区分。
- 「小顶堆 min heap」:任意节点的值 ≤ 其子节点的值。
- 「大顶堆 max heap」:任意节点的值 ≥ 其子节点的值。
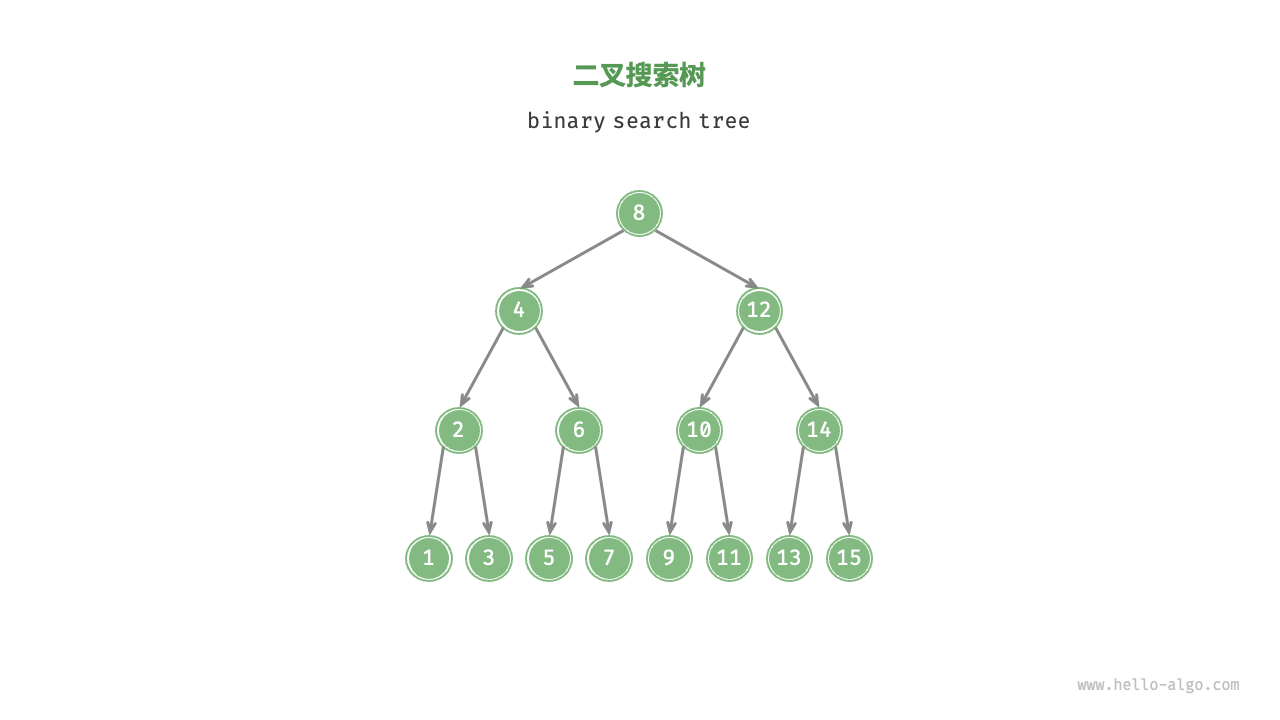
个人理解:
- 二叉搜索树体现了二分算法的思想
2.4.4.1 二叉搜索树的搜索操作
查询
给定目标节点值 num ,可以根据二叉搜索树的性质来查找。如图 7-17 所示,我们声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系。
- 若
cur.val < num,说明目标节点在cur的右子树中,因此执行cur = cur.right。 - 若
cur.val > num,说明目标节点在cur的左子树中,因此执行cur = cur.left。 - 若
cur.val = num,说明找到目标节点,跳出循环并返回该节点。
插入节点
插入节点时需要注意保持二叉搜索树“左子树 < 根节点 < 右子树”的性质
- 需要查询插入位置:和查询操作类似,从根节点触发,直到叶节点(遍历至
None)时跳出循环。 - 在该位置插入节点:初始化节点
num,将该节点置于None的位置。
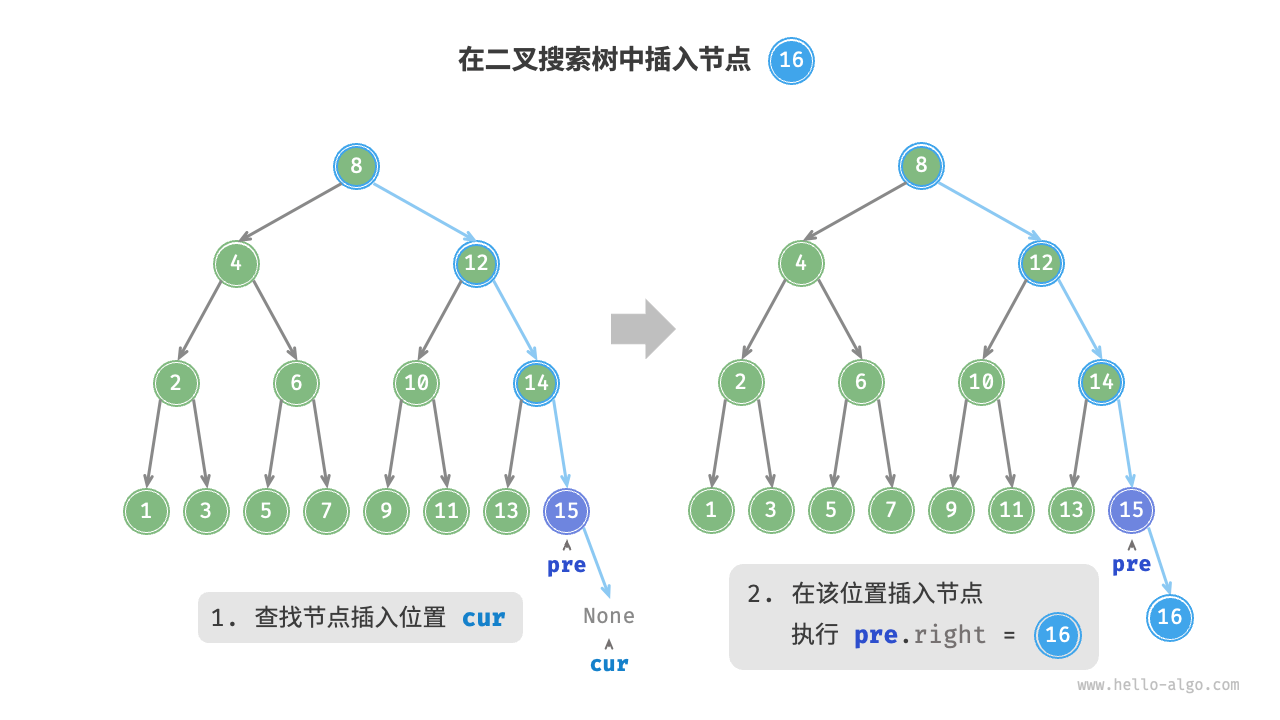
插入时需要注意:
- 二叉搜索树不允许存在重复节点,否则将违反其定义。因此,若待插入节点在树中已存在,则不执行插入,直接返回。
删除节点
删除节点需要区分三种情况,分别是节点的度为0/1/2时,进行的操作是不同的
- 度为0时,节点是叶节点,直接删除
- 度为1时,该节点只有一个叶节点(高度为1),将待删除节点替换为其子节点即可。
- 当待删除节点的度为 2 时,我们无法直接删除它,而需要使用一个节点替换该节点。由于要保持二叉搜索树“左子树 < 根节点 < 右子树”的性质,因此这个节点可以是右子树的最小节点或左子树的最大节点。
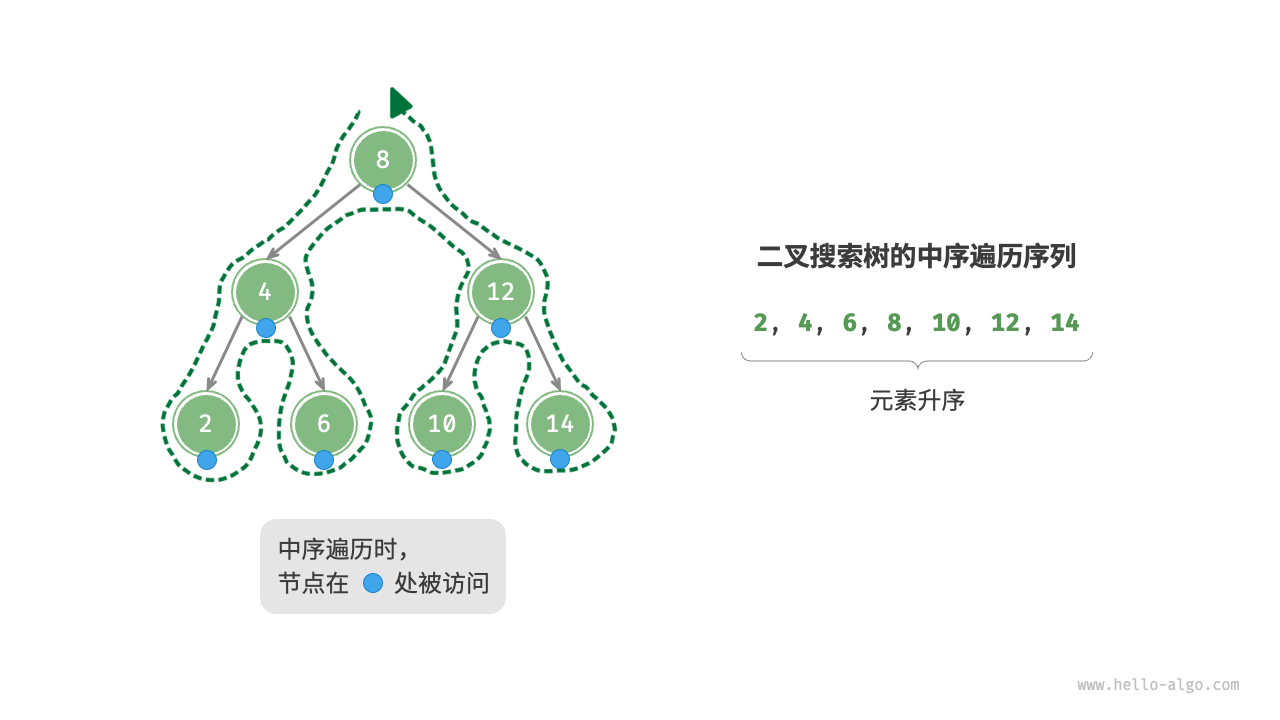
中序遍历
由于二叉搜索树的特性,中序遍历遵循“左 → 根 → 右”的遍历顺序,而二叉搜索树满足“左子节点 < 根节点 < 右子节点”的大小关系。从而得出一个重要性质:二叉搜索树的中序遍历序列是升序的。
利用中序遍历升序的性质,我们在二叉搜索树中获取有序数据仅需 O(n) 时间,无须进行额外的排序操作,非常高效。
2.4.4.2 搜索二叉树的效率
对比无序数组和二叉搜索树。
| 无序数组 | 二叉搜索树 | |
|---|---|---|
| 查找元素 | O(n) | O(logn) |
| 插入元素 | O(1) | O(logn) |
| 删除元素 | O(n) | O(logn) |
- 二叉搜索树的各项操作的时间复杂度都是对数阶,具有稳定且高效的性能。可以得出二叉搜索树是“平衡”的(理想状态下
- 比较之下,二叉搜索树在查询和删除元素时有较大优势。
- 只有在高频添加、低频查找删除数据的场景下,数组比二叉搜索树的效率更高。.
- 如果我们在二叉搜索树中不断地插入和删除节点,各种操作的时间复杂度也会退化为 O(n) 。
2.4.4.3 二叉搜索树常见应用
- 用作系统中的多级索引,实现高效的查找、插入、删除操作。
- 作为某些搜索算法的底层数据结构。
- 用于存储数据流,以保持其有序状态。
由于劣化的现象存在,所以在实际业务场景中是比较少见的。
为了解决二叉搜索树会劣化的问题,后续基于二叉搜索树给出了更优的算法
- 比如平衡二叉树(AVL树),通过一系列操作,确保在持续添加和删除节点后,AVL 树不会退化。AVL 树¶
- 还有非常出名的红黑树——自平衡的二叉查找树具体可以看看文章
2.5 堆