java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846
文章目录
1. 暴力求解,深度优先 2. KMP算法进行串匹配
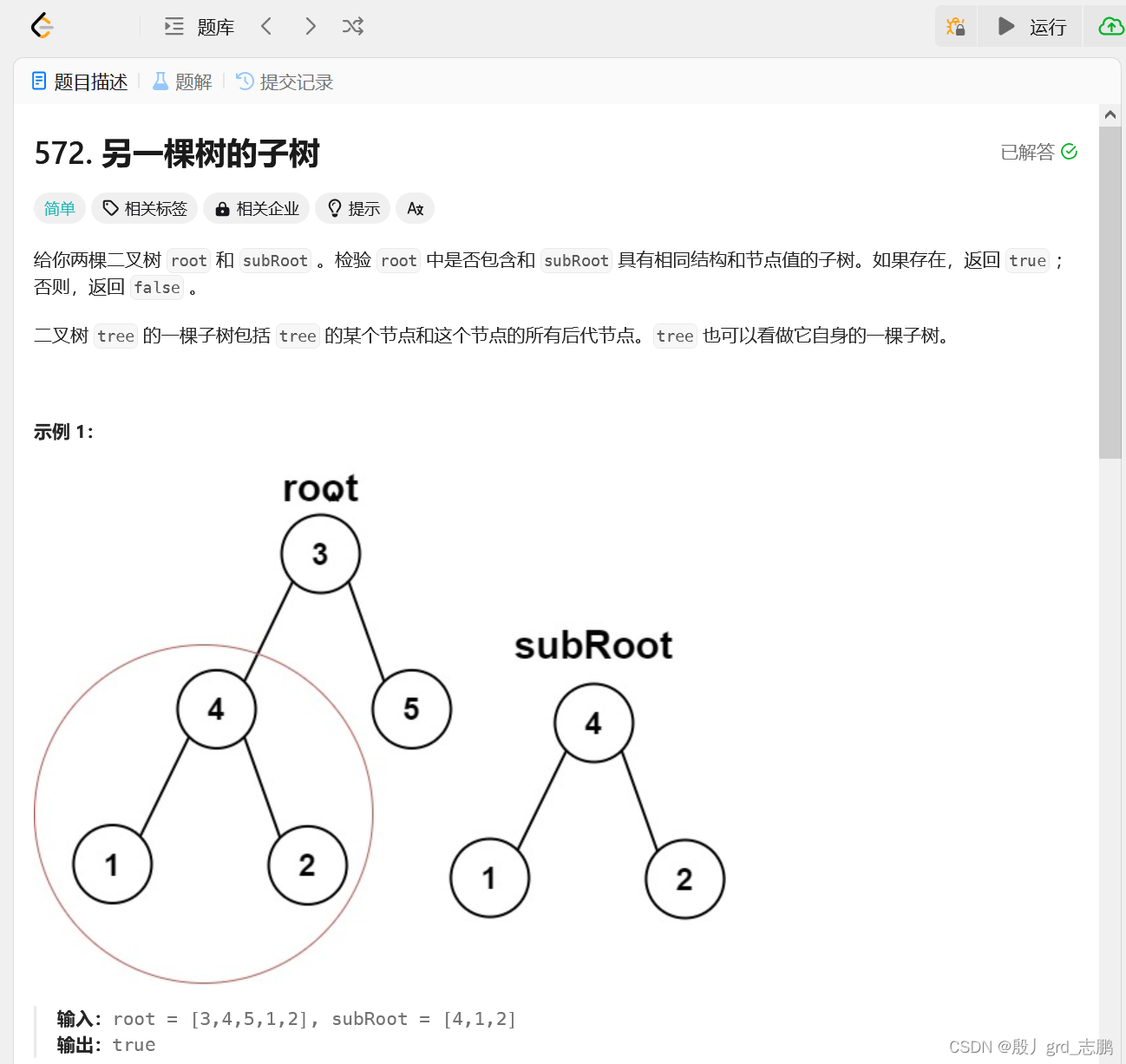
暴力求解,深度优先 解题思路:时间复杂度O(s*t)其中s是树的结点个数,t是子树的结点个数。空间复杂度O(max(ds,dt))其中ds是树的深度,dt是子树的深度
我们先对整个树深度优先遍历 每个结点都与子树的根节点进行比对 如果对上了,就以当前结点为根节点,进行和子树的深度优先遍历,看看是否一一对应 对应上就返回true,没对应上就继续深度优先遍历。直到整个树遍历完成
class Solution {
public boolean isSubtree ( TreeNode root, TreeNode subRoot) {
if ( root == null && subRoot == null ) return true ;
else if ( root == null || subRoot == null ) return false ;
else return isSubtree ( root. left, subRoot) || isSubtree ( root. right, subRoot) || isSameTree ( root, subRoot) ;
}
public boolean isSameTree ( TreeNode root, TreeNode subRoot) {
if ( root == null && subRoot == null ) return true ;
if ( root == null || subRoot == null ) return false ;
if ( root. val == subRoot. val) {
return isSameTree ( root. left, subRoot. left) && isSameTree ( root. right, subRoot. right) ;
}
return false ;
}
}
KMP算法进行串匹配 KMP算法https://blog.csdn.net/grd_java/article/details/136107363
解题思路:时间复杂度O(s+t),空间复杂度O(s+t)
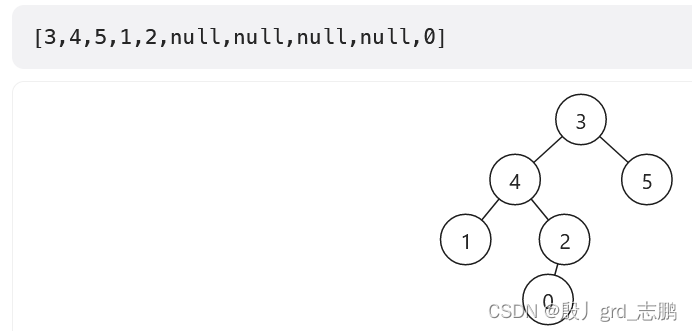
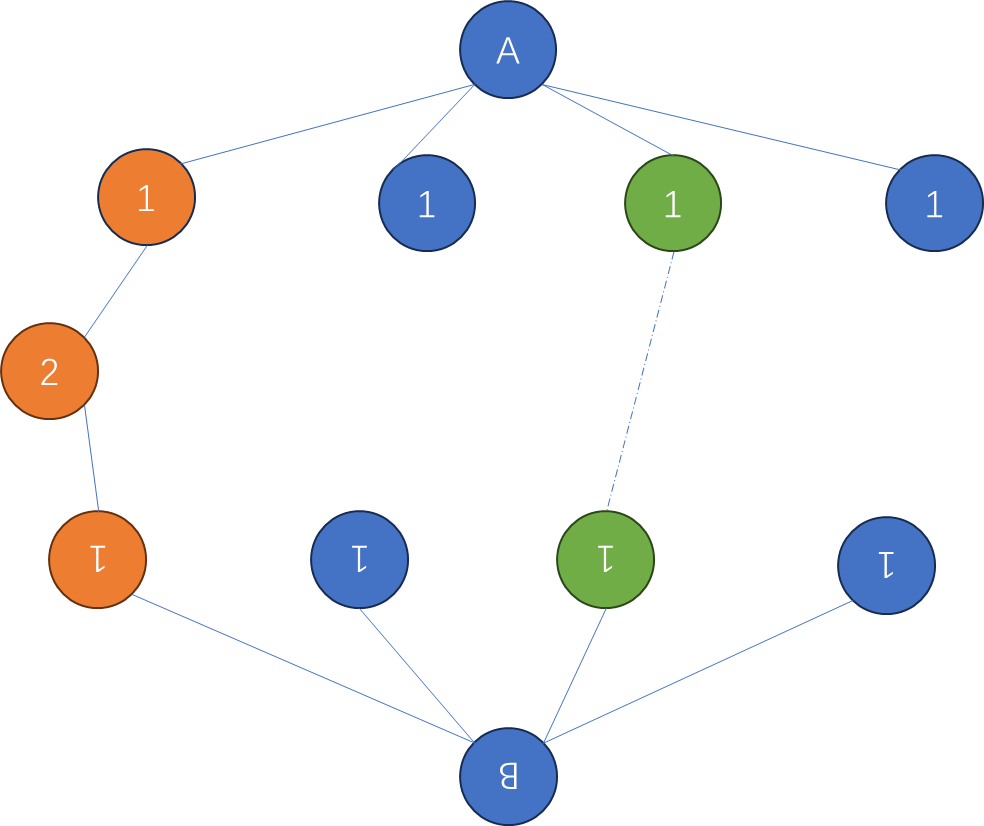
生成两颗树的遍历序列,以类似如下的形式:(下面形式是广度(层序)遍历序列,需要额外空间辅助,所以我们放弃) 为了效率和更少的空间,我们使用广度优先遍历。那么就需要两个不同的值,来表示某结点左子树为空,和右子树为空的情况。 同样为了效率,我们不使用字符串比较,选用int型容器,比如int型的链表来生成匹配串 那么null如何来表示呢?
我们可以规定两个值,来分别表示左子树为null和右子树为null的情况 这里我选择先找到树中最大值max,然后令max+1表示左子树为空情况,max+2表示右子树为空情况
生成两颗树的匹配串后,让大树作为主字符串,要匹配的子树作为要匹配的子串,改编KMP算法,如果匹配成功,说明树中可以匹配到子树
代码:leetcode的特色之一就是,更优的算法,有时因为使用程序自带的特殊容器(比如Java中的List),因为这些容器初始化比较耗时间,反而耗时更高。但是实际工作场景,一旦数据量起来,肯定是这个算法优于上面的暴力解法的。
class Solution {
List < Integer > = new ArrayList < Integer > ( ) ;
List < Integer > = new ArrayList < Integer > ( ) ;
int maxElement, lNull, rNull;
public void getMaxElement ( TreeNode t) {
if ( t == null ) return ;
maxElement = Math . max ( maxElement, t. val) ;
getMaxElement ( t. left) ;
getMaxElement ( t. right) ;
}
public void getDfsOrder ( TreeNode t, List < Integer > ) {
if ( t == null ) return ;
tar. add ( t. val) ;
if ( t. left != null ) getDfsOrder ( t. left, tar) ;
else tar. add ( lNull) ;
if ( t. right != null ) getDfsOrder ( t. right, tar) ;
else tar. add ( rNull) ;
}
public boolean isSubtree ( TreeNode s, TreeNode t) {
maxElement = Integer . MIN_VALUE ;
getMaxElement ( s) ;
getMaxElement ( t) ;
lNull = maxElement + 1 ;
rNull = maxElement + 2 ;
getDfsOrder ( s, sOrder) ;
getDfsOrder ( t, tOrder) ;
return kmp ( ) ;
}
public boolean kmp ( ) {
int sLen = sOrder. size ( ) , tLen = tOrder. size ( ) ;
int [ ] fail = new int [ tOrder. size ( ) ] ;
fail[ 0 ] = 0 ;
for ( int i = 1 , j = 0 ; i < tLen; ++ i) {
while ( j > 0 && ! ( tOrder. get ( i) . equals ( tOrder. get ( j) ) ) ) j = fail[ j- 1 ] ;
if ( tOrder. get ( i) . equals ( tOrder. get ( j) ) ) ++ j;
fail[ i] = j;
}
for ( int i = 0 , j = 0 ; i < sLen; ++ i) {
while ( j > 0 && ! ( sOrder. get ( i) . equals ( tOrder. get ( j) ) ) ) j = fail[ j- 1 ] ;
if ( sOrder. get ( i) . equals ( tOrder. get ( j) ) ) ++ j;
if ( j == tLen) return true ;
}
return false ;
}
}







![练习 3 Web [ACTF2020 新生赛]Upload](https://img-blog.csdnimg.cn/direct/93d49f2a68414016b523c4ea5d959175.png)