前言:
相信提高文本检索工具,大家脑海里肯定有很多工具会自动跳出来,比如,grep,egrep,sed,cat,more,less,cut,awk,vim,vi,nano,strings等等工具(vim,nano 这样的文本编辑工具也是兼具文本检索功能的嘛,要是不能检索就没有存在的必要了~~~~~)
那么,这些文本信息检索工具里如果按照使用频率来说,第一个毫无疑问是文本编辑工具vim了,其次就是文本检索工具cat和grep了,在次就是sed和awk这样的流检索工具了,而egrep可能使用频率上就比较低了,但,其实有些工具就和人的性格一样:低调不代表能力不行,相反,egrep的强大应该是和vim一样毋庸置疑的啊!!!
其实呢,grep和grep这两个命令是比较有意思的,也就是非常的有用的,在Linux这里,grep和egrep这两个命令是必要要熟练掌握和运用的
那么,本文将就grep和egrep命令在做一个详细的介绍
一、
grep和egrep的相似处和不同处
- egrep执行效果与"grep-E"相似,使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
- egrep是用extended regular expression语法来解读的,而grep则用basic regular expression 语法解读,extended regular expression比basic regular expression的表达更规范,且egep支持更多的元字符,即egrep使用的是拓展的正则表达式
- grep和egrep这两个命令的帮助基本是一致的,so,学会了一个命令,另一个命令就也学会了
那么,也就是可以简单的认为grep和egrep基本是一个命令,只是egrep使用的时候更为简练,搜索的时候正则规则egrep比grep更多,它们之间的关系可以认为是vim和vi (vim比vi多了语法,搜索高亮等等附加功能,但主要的功能---文本编辑并没有任何区别)的关系,这里,我可以保证,这么理解绝对绝对的没有问题~~~~!!!
🆗,那么,其实grep这个命令并没有使用的太多必要,如果只是简单的文本搜索过滤的话,好吧,grep还是可以勉强一用的
二、
grep和egrep的基本无脑用法
示例文件,我这里选择使用本地yum仓库的xml配置文件,选择此文件的原因是数字和字母都有,比较像配置文件,其实也确实是一个配置文件
可以看到,该文件的文本特征是数字和字母混杂在一起了,有纯字母行,但没有纯数字行
[root@centos7 repodata]# cat repomd.xml
<?xml version="1.0" encoding="UTF-8"?>
<repomd xmlns="http://linux.duke.edu/metadata/repo" xmlns:rpm="http://linux.duke.edu/metadata/rpm">
<revision>1709240060</revision>
<data type="filelists">
<checksum type="sha256">406fe311374b513103fc6968c07da6f9a99b561c90871608cfd89cad119a1126</checksum>
<open-checksum type="sha256">ba1d9203986defbf63d9361351ed24d33aabad40a014061e669f6fa62dccd868</open-checksum>
<location href="repodata/406fe311374b513103fc6968c07da6f9a99b561c90871608cfd89cad119a1126-filelists.xml.gz"/>
<timestamp>1709240061</timestamp>
<size>87505</size>
<open-size>935761</open-size>
</data>
<data type="primary">
<checksum type="sha256">8595bbc4226db56075dfaf6317e5effd7f92f18d5a6d7526e77c6f6552cebf94</checksum>
<open-checksum type="sha256">ffc6df89c274e8925cc631ead5f6cfe9435a193c22d5b22a9c99b400a51d881a</open-checksum>
<location href="repodata/8595bbc4226db56075dfaf6317e5effd7f92f18d5a6d7526e77c6f6552cebf94-primary.xml.gz"/>
<timestamp>1709240061</timestamp>
<size>49182</size>
<open-size>444084</open-size>
</data>
<data type="primary_db">
<checksum type="sha256">e65d3a6cf36df5021676d932b2a2d0b0c03e4271655c045c07e94222a5290b18</checksum>
<open-checksum type="sha256">c24e01dc5b3388cba3b876c64ddf9406cffb175ee3b2a7fd7e4b11a43c62a84a</open-checksum>
<location href="repodata/e65d3a6cf36df5021676d932b2a2d0b0c03e4271655c045c07e94222a5290b18-primary.sqlite.bz2"/>
<timestamp>1709240061</timestamp>
<database_version>10</database_version>
<size>115549</size>
<open-size>524288</open-size>
</data>
<data type="other_db">
<checksum type="sha256">fb5a57bd9729ce92ea197c79fb637d77f6c2abf1bedd8e6fe8407f6582b118d3</checksum>
<open-checksum type="sha256">a2fb0f11d2991d2756117198c24cc5e92ddcefa763a6708b4a3f6a55c55e41ce</open-checksum>
<location href="repodata/fb5a57bd9729ce92ea197c79fb637d77f6c2abf1bedd8e6fe8407f6582b118d3-other.sqlite.bz2"/>
<timestamp>1709240061</timestamp>
<database_version>10</database_version>
<size>60744</size>
<open-size>296960</open-size>
</data>
<data type="other">
<checksum type="sha256">f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8</checksum>
<open-checksum type="sha256">2708ba2eac9dff6e1118067b0b1bc42f138ccf58335c92214dcae503813e3112</open-checksum>
<location href="repodata/f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8-other.xml.gz"/>
<timestamp>1709240061</timestamp>
<size>43373</size>
<open-size>319989</open-size>
</data>
<data type="filelists_db">
<checksum type="sha256">258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3</checksum>
<open-checksum type="sha256">25a2e76fe87f7fed34ace38b0daae9de3b9b8f4aca259441d226f6633db3ab10</open-checksum>
<location href="repodata/258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3-filelists.sqlite.bz2"/>
<timestamp>1709240061</timestamp>
<database_version>10</database_version>
<size>106570</size>
<open-size>476160</open-size>
</data>
</repomd>
🆗,什么叫无脑呢?这里自然说的是不需要绞尽脑汁想正则表达式,也就是跟cat命令一样,仅仅查看文本文档的内容
说明:空单引号表示没有字符串过滤,自然就是取的所有文本内容了,通过管道符结合tail -n 10 回显了该文件的最后10行,其实这个命令等同于cat repomd.xml|tail -n 10
[root@centos7 repodata]# grep '' repomd.xml |tail -n 10
<data type="filelists_db">
<checksum type="sha256">258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3</checksum>
<open-checksum type="sha256">25a2e76fe87f7fed34ace38b0daae9de3b9b8f4aca259441d226f6633db3ab10</open-checksum>
<location href="repodata/258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3-filelists.sqlite.bz2"/>
<timestamp>1709240061</timestamp>
<database_version>10</database_version>
<size>106570</size>
<open-size>476160</open-size>
</data>
</repomd>
自然的,egrep的效果和grep是一模一样的,无需废话多言:
[root@centos7 repodata]# egrep '' repomd.xml |tail -n 10
<data type="filelists_db">
<checksum type="sha256">258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3</checksum>
<open-checksum type="sha256">25a2e76fe87f7fed34ace38b0daae9de3b9b8f4aca259441d226f6633db3ab10</open-checksum>
<location href="repodata/258ab32bd065ef14ed56b34a06798c95ee2de2652b83dce93a3cd8d62928d3c3-filelists.sqlite.bz2"/>
<timestamp>1709240061</timestamp>
<database_version>10</database_version>
<size>106570</size>
<open-size>476160</open-size>
</data>
</repomd>
三、
反向过滤 -v 逻辑符 not
egrep 过滤,去除所有带数字的行,只保留纯字母行
[root@centos7 repodata]# egrep -v '[0-9]' repomd.xml
<repomd xmlns="http://linux.duke.edu/metadata/repo" xmlns:rpm="http://linux.duke.edu/metadata/rpm">
<data type="filelists">
</data>
<data type="primary">
</data>
<data type="primary_db">
</data>
<data type="other_db">
</data>
<data type="other">
</data>
<data type="filelists_db">
</data>
</repomd>
同样的,过滤去除所有带字母的行,只保留纯数字行(没有纯数字行,因此没有输出):
[root@centos7 repodata]# egrep -v '[a-z]' repomd.xml
[root@centos7 repodata]#
四、
过滤单词 完全精确匹配 -w
###说明:sed命令精确匹配要写很多,比较麻烦
[root@centos7 repodata]# egrep -w 'size' repomd.xml
<size>87505</size>
<open-size>935761</open-size>
<size>49182</size>
<open-size>444084</open-size>
<size>115549</size>
<open-size>524288</open-size>
<size>60744</size>
<open-size>296960</open-size>
<size>43373</size>
<open-size>319989</open-size>
<size>106570</size>
<open-size>476160</open-size>
[root@centos7 repodata]# egrep -w 'siz' repomd.xml ###这个无输出回显五、
匹配行显示行号
过滤的同时显示行号 -n 显示行号
[root@centos7 repodata]# egrep -n -v '[0-9]' repomd.xml
2:<repomd xmlns="http://linux.duke.edu/metadata/repo" xmlns:rpm="http://linux.duke.edu/metadata/rpm">
4:<data type="filelists">
11:</data>
12:<data type="primary">
19:</data>
20:<data type="primary_db">
28:</data>
29:<data type="other_db">
37:</data>
38:<data type="other">
45:</data>
46:<data type="filelists_db">
54:</data>
55:</repomd>
[root@centos7 repodata]# cat repomd.xml |egrep -n -v '[0-9]'
2:<repomd xmlns="http://linux.duke.edu/metadata/repo" xmlns:rpm="http://linux.duke.edu/metadata/rpm">
4:<data type="filelists">
11:</data>
12:<data type="primary">
19:</data>
20:<data type="primary_db">
28:</data>
29:<data type="other_db">
37:</data>
38:<data type="other">
45:</data>
46:<data type="filelists_db">
54:</data>
55:</repomd>
🆗,这里就有意思了,egrep可以回显上下文
行号+上下文回显 -C 1 显示匹配行的上下文各一行 数字按需指定
[root@centos7 repodata]# egrep -C 1 -n -w 'other' repomd.xml
31- <open-checksum type="sha256">a2fb0f11d2991d2756117198c24cc5e92ddcefa763a6708b4a3f6a55c55e41ce</open-checksum>
32: <location href="repodata/fb5a57bd9729ce92ea197c79fb637d77f6c2abf1bedd8e6fe8407f6582b118d3-other.sqlite.bz2"/>
33- <timestamp>1709240061</timestamp>
--
37-</data>
38:<data type="other">
39- <checksum type="sha256">f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8</checksum>
40- <open-checksum type="sha256">2708ba2eac9dff6e1118067b0b1bc42f138ccf58335c92214dcae503813e3112</open-checksum>
41: <location href="repodata/f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8-other.xml.gz"/>
42- <timestamp>1709240061</timestamp>
行号+上下文回显 -A 1 显示匹配行的下文一行 数字按需指定
[root@centos7 repodata]# egrep -A 1 -n -w 'other' repomd.xml
32: <location href="repodata/fb5a57bd9729ce92ea197c79fb637d77f6c2abf1bedd8e6fe8407f6582b118d3-other.sqlite.bz2"/>
33- <timestamp>1709240061</timestamp>
--
38:<data type="other">
39- <checksum type="sha256">f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8</checksum>
--
41: <location href="repodata/f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8-other.xml.gz"/>
42- <timestamp>1709240061</timestamp>

行号+上下文回显 -B 1 显示匹配行的上文一行 数字按需指定
[root@centos7 repodata]# egrep -B 1 -n -w 'other' repomd.xml
31- <open-checksum type="sha256">a2fb0f11d2991d2756117198c24cc5e92ddcefa763a6708b4a3f6a55c55e41ce</open-checksum>
32: <location href="repodata/fb5a57bd9729ce92ea197c79fb637d77f6c2abf1bedd8e6fe8407f6582b118d3-other.sqlite.bz2"/>
--
37-</data>
38:<data type="other">
--
40- <open-checksum type="sha256">2708ba2eac9dff6e1118067b0b1bc42f138ccf58335c92214dcae503813e3112</open-checksum>
41: <location href="repodata/f31c3eb35c261d4437cfa9dc1fef589cd0142ce2575cedc6ccca0e9c355c48f8-other.xml.gz"/>

六、
特征匹配
正则表达式 以">结束的行
[root@centos7 repodata]# egrep -n '.*">$' repomd.xml
2:<repomd xmlns="http://linux.duke.edu/metadata/repo" xmlns:rpm="http://linux.duke.edu/metadata/rpm">
4:<data type="filelists">
12:<data type="primary">
20:<data type="primary_db">
29:<data type="other_db">
38:<data type="other">
46:<data type="filelists_db">

以</ 开始的行
[root@centos7 repodata]# egrep -n '^</' repomd.xml
11:</data>
19:</data>
28:</data>
37:</data>
45:</data>
54:</data>
55:</repomd>
很多时候,查看配置文件的时候,不想看那些以#开始的注释文件,那么egrep将会非常简单:
下面一个是不过滤#开始的行,一个是过滤掉#开始的行
[root@centos7 ~]# egrep '^#' /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
[root@centos7 ~]# egrep -v '^#' /etc/selinux/config
SELINUX=disabled
SELINUXTYPE=targeted
七、
递归目录匹配并忽略大小写
egrep -r 递归扫描 -i 忽略大小写 搜索/etc/目录下所有包含root这个单词的文件
Binary file /etc/aliases.db matches
[root@centos7 repodata]# egrep -r -i 'root' /etc/ |more
/etc/fstab:/dev/mapper/centos-root / xfs defaults 0 0
/etc/pki/ca-trust/ca-legacy.conf:# The upstream Mozilla.org project tests all changes to the root CA
/etc/pki/ca-trust/ca-legacy.conf:# to temporarily keep certain (legacy) root CA certificates trusted,
/etc/pki/ca-trust/ca-legacy.conf:# It may keep root CA certificate as trusted, which the upstream
/etc/pki/ca-trust/extracted/README:root CA certificates.
/etc/pki/ca-trust/extracted/java/README:root CA certificates.
Binary file /etc/pki/ca-trust/extracted/java/cacerts matches
/etc/pki/ca-trust/extracted/openssl/README:root CA certificates.
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# Actalis Authentication Root CA
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# AddTrust External Root
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# AddTrust Low-Value Services Root
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# Amazon Root CA 1
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# Amazon Root CA 2
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt:# Amazon Root CA 3
八、
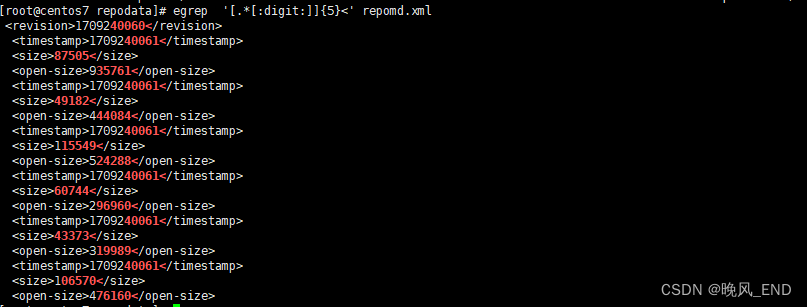
搜索包含有5个连续数字的行,5个数字后接的是< 可以看到有10位数字被匹配到了,并不是十分准确
[root@centos7 repodata]# egrep '[.*[:digit:]]{5}<' repomd.xml
<revision>1709240060</revision>
<timestamp>1709240061</timestamp>
<size>87505</size>
<open-size>935761</open-size>
<timestamp>1709240061</timestamp>
<size>49182</size>
<open-size>444084</open-size>
<timestamp>1709240061</timestamp>
<size>115549</size>
<open-size>524288</open-size>
<timestamp>1709240061</timestamp>
<size>60744</size>
<open-size>296960</open-size>
<timestamp>1709240061</timestamp>
<size>43373</size>
<open-size>319989</open-size>
<timestamp>1709240061</timestamp>
<size>106570</size>
<open-size>476160</open-size>
[:alnum:] 匹配字母和数字.等同于A-Za-z0-9.
[:alpha:] 匹配字母. 等同于A-Za-z.
[:blank:] 匹配一个空格或是一个制表符(tab).
[:cntrl:] 匹配控制字符.
[:digit:] 匹配(十进制)数字. 等同于0-9.
[:graph:] (可打印的图形字符). 匹配 ASCII 码值的33 - 126之间的字符. 这和下面提到的
[:print:]一样,但是不包括空格字符.[:lower:] 匹配小写字母. 等同于a-z.
[:print:] (可打印字符). 匹配 ASCII码值 32 - 126之间的字符. 这和上面提到的一样
[:graph:],但是增多一个空格字符.[:space:] 匹配空白字符 (空格符和水平制表符).
[:upper:] 匹配大写字母. 等同于A-Z.
[:xdigit:] 匹配十六进制数字. 等同于0-9A-Fa-f.






![练习 3 Web [ACTF2020 新生赛]Upload](https://img-blog.csdnimg.cn/direct/93d49f2a68414016b523c4ea5d959175.png)