首发AIWalker,欢迎关注~

https://arxiv.org/abs/2402.15704
https://github.com/hellloxiaotian/HDSRNet
卷积神经网络可以通过深度网络架构和给定的输入样本自动学习特征。然而,所获得的模型的鲁棒性在不同的场景中可能具有挑战性。网络架构的差异越大,有利于提取更多的互补结构信息,从而增强获得的超分辨率模型的鲁棒性。
在本文中,我们提出了一种异构动态卷积网络图像超分辨率(HDSRNet)。为了获取更多的信息,HDSRNet由一个异构的并行网络实现的。
- 上层网络可以通过堆叠异构块来提供更多的纹理信息,以提高图像超分辨率的效果。每个异构块由扩展的、动态的、公共卷积层、ReLU和残差学习操作的组合组成。它不仅可以根据不同的输入自适应地调整参数,而且可以防止长期依赖问题。
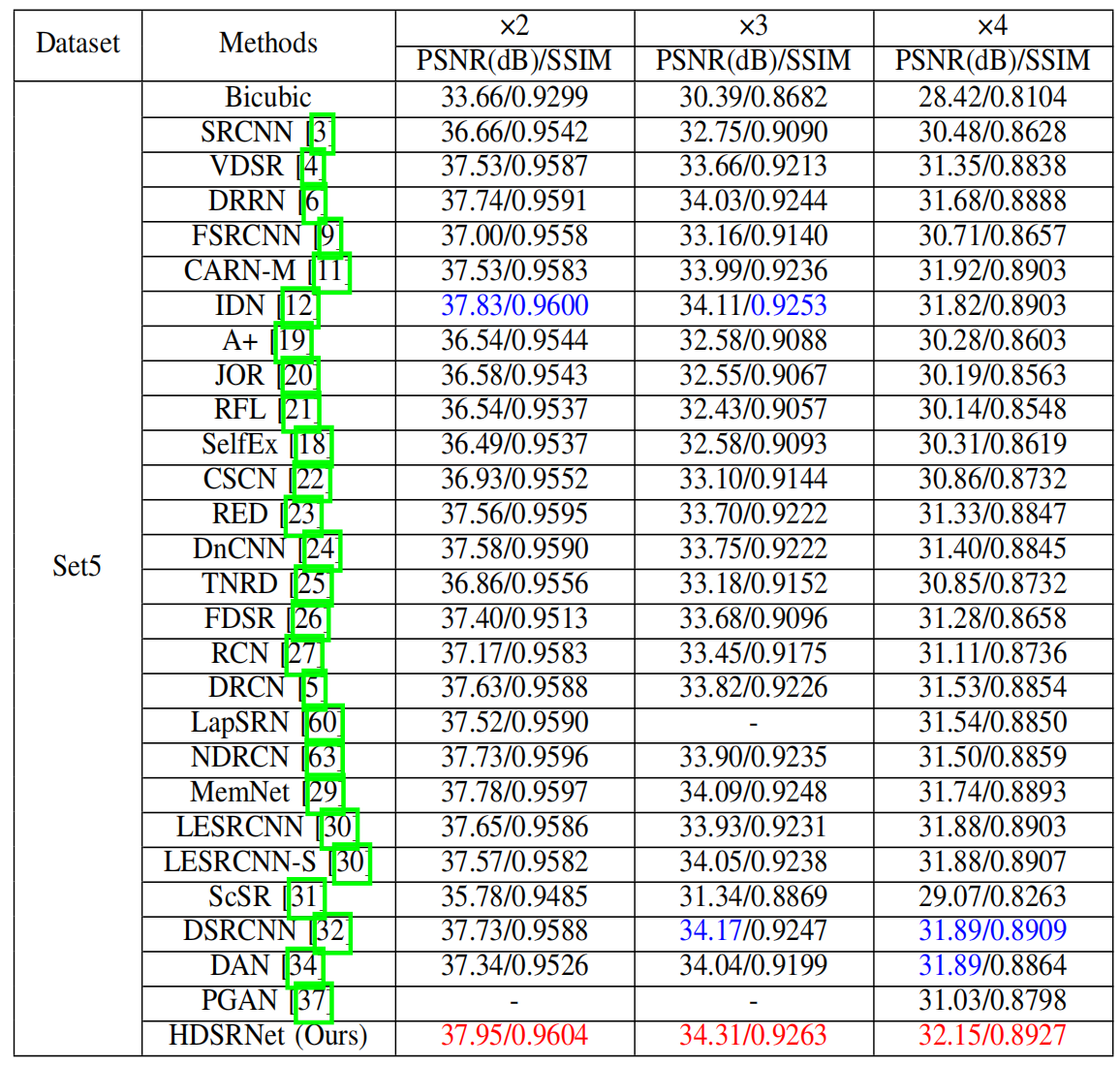
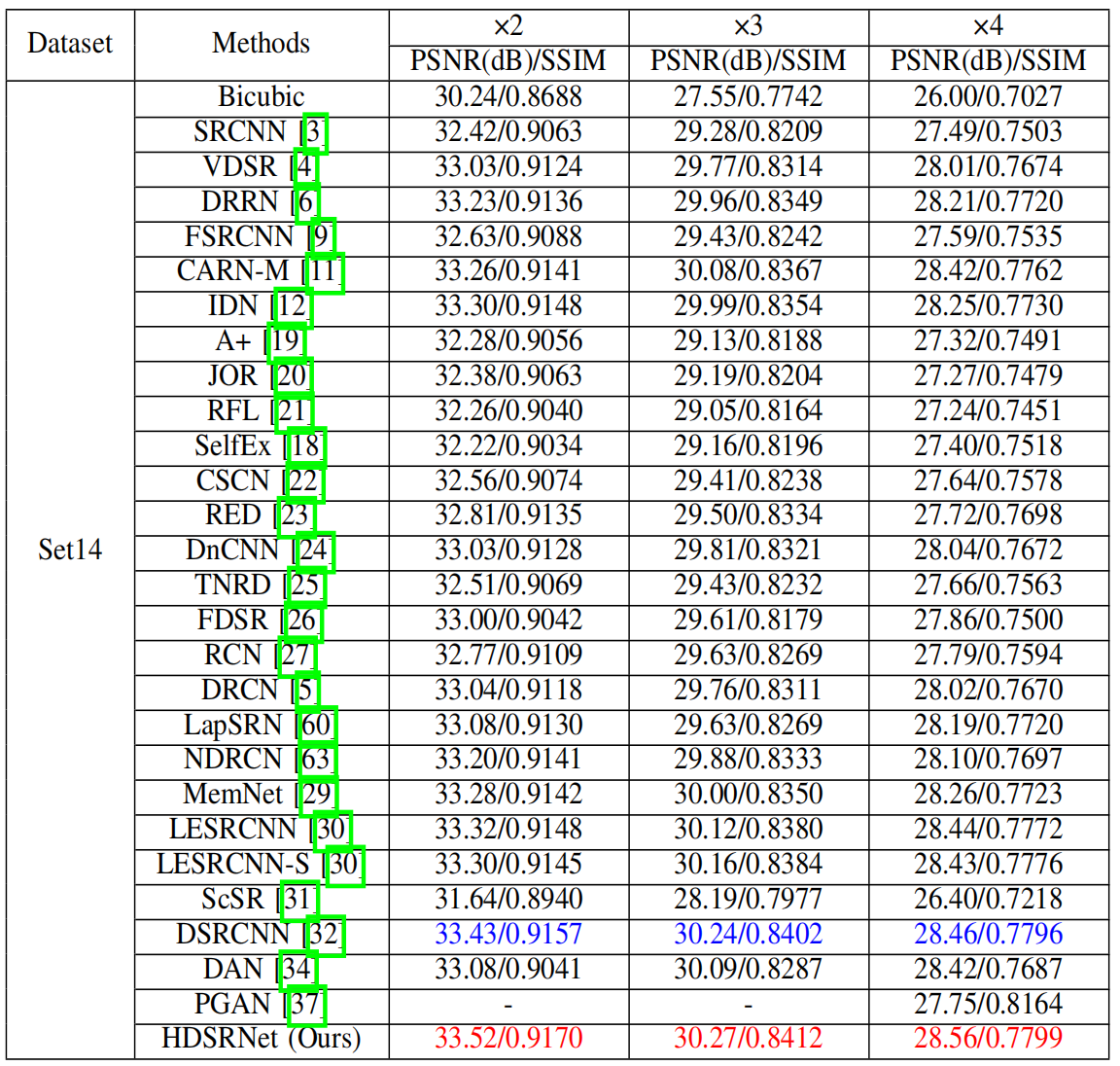
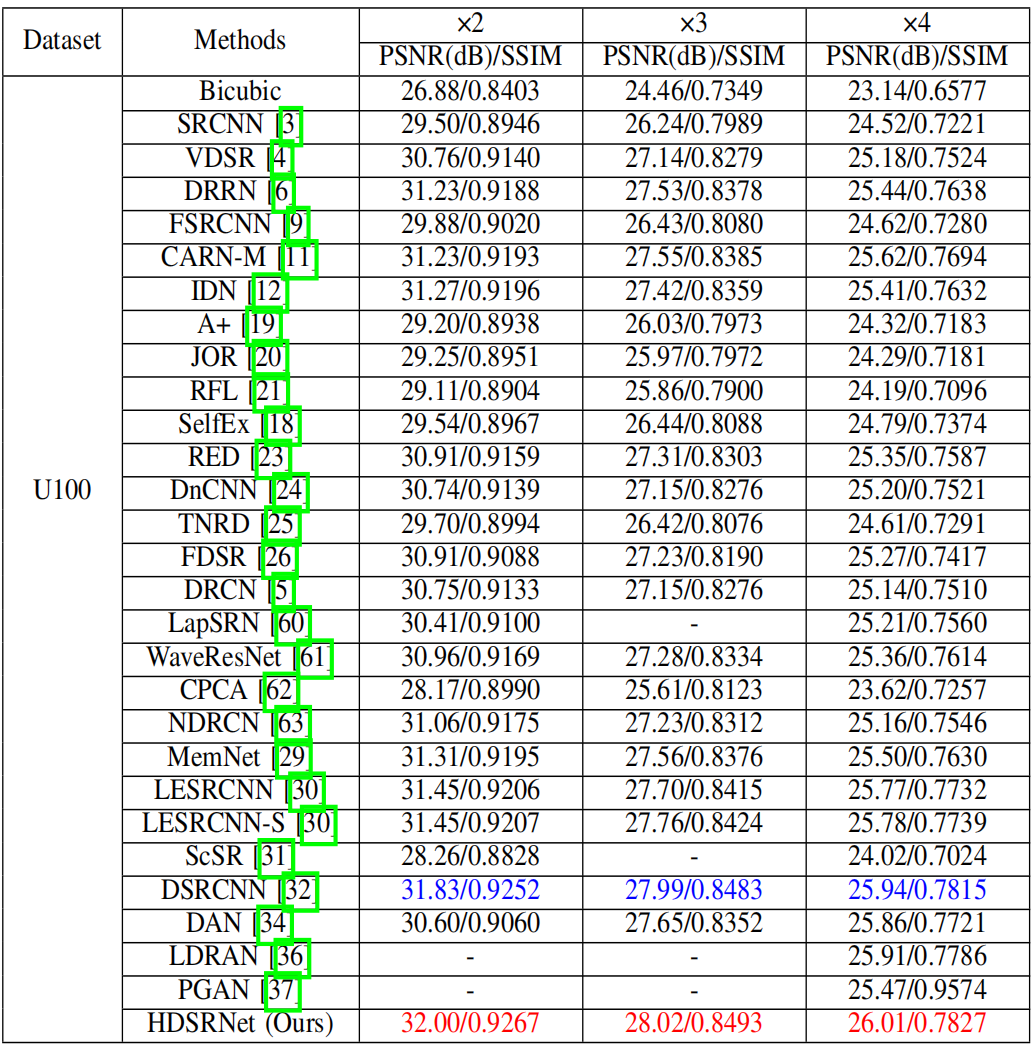
- 下层网络采用对称结构增强不同层之间的关系,挖掘更多的结构信息,与上层网络互补,实现图像超分辨率。相关实验结果表明,该方法能够有效地解决图像分辨问题.
本文方案

所提18层HDSRNet包含两个16层并行异构网络和一个2层重构模块。16层并行异构网络由16层异构上层网络和对称下层网络组成。
- 异构上层网络由一个Conv+ReLU和五个堆叠的异构块组成,可以提取更多的图像超分辨率的纹理信息。Conv+ReLU是卷积层和ReLU操作的组合,用于从给定的低分辨率图像中提取非线性信息。此外,其输入和输出通道数分别为3和64。其内核大小为3×3。这些堆叠的异构块利用不同的卷积层(即,动态和公共卷积层)和ReLU,根据不同输入的低分辨率图像动态调整参数以获得鲁棒的低频信息。
- 为了获得互补的低频信息,设计了一个16层对称下层网络。它依赖于一个对称的结构来增强层次间的联系,以获得更多的互补结构信息。此外,两个子网络可以通过乘法运算来交互信息。使用2层重建模块将低频信息转换为高频信息并构造预测的高质量图像。

Heterogeneous Block
为了训练鲁棒去噪器,根据不同的输入低分辨率图像,进行异构块动态调整参数,以获得鲁棒的低频信息。每个异构块由扩张Conv+ReLU、动态Conv+ReLU和Conv+ReLU组成,其中扩张Conv+ReLU表示扩张卷积和ReLU的组合。用于捕获更多上下文信息的。动态Conv+ReLU是动态卷积和ReLU的组合,其中可以根据不同的输入信息自适应地学习参数。为了防止长期依赖性,在扩张的Conv+ReLU的输入和Conv+ReLU的输出之间进行残差操作。所有卷积核都是3×3 。输入、输出通道编号,即,扩展的、动态的和普通的卷积层是64。此外,在扩张卷积层中,扩张因子为2。
H B ( O t ) = C R ( D y C R ( D i C R ( O t ) ) ) + O t HB(O_t) = CR(DyCR(DiCR(O_t))) + O_t HB(Ot)=CR(DyCR(DiCR(Ot)))+Ot
Symmetrical Lower Sub-network
为了获得互补的低频信息,进行了16层对称下层网络。每一层包含一个Conv+ReLU,其中除了第一层之外,其输入和输出通道数为64,其内核为3×3 。第一层的输入和输出通道数分别为3和64。为了增强不同层之间的关系,使用残差学习操作在第1层和第16层、第2层和第15层、第3层和第14层、第4层和第13层、第5层和第12层、第6层和第11层、第7层和第10层、第8层和第9层之间起作用,以将获得的浅层信息转移到深层,以防止长期依赖性,并获得用于图像超分辨率的鲁棒信息。
O S L N e t = C R ( C R ( . . . ( C R ( C R ( O 8 + C R ( O 8 ) ) + O 7 ) + O 6 ) + . . . ) + O 2 ) + O 1 O_{SLNet} = CR(CR(...(CR(CR(O_8+CR(O_8)) + O_7) + O_6) +...) + O_2) + O_1 OSLNet=CR(CR(...(CR(CR(O8+CR(O8))+O7)+O6)+...)+O2)+O1
Construction Block
使用2层构造块来构造预测的HR图像。它包含两个阶段。第一阶段采用亚像素卷积层将低频信息转换为高频信息,其输入和输出通道数分别为128和64。第二阶段仅利用卷积层(Conv)来构造预测分辨率图像,其中其输入和输出通道数分别为64和3。它们的内核大小是 3×3。
O S = C ( S u b ( O H U N e t × O S L N e t ) ) O_S = C(Sub(O_{HUNet} \times O_{SLNet})) OS=C(Sub(OHUNet×OSLNet))
本文实验




推荐阅读
- 超越SwinIR,Mamba入局图像复原,达成新SOTA
- 入局CV,Mamba再显神威!华科王兴刚团队首次将Mamba引入ViT,更高精度、更快速度、更低显存!
- Swin版VMamba来了!精度再度提升,VMamba-S达成83.5%,超越Swin-S,已开源!
- MiOIR | 直面 “多合一”图像复原,港理工张磊团队提出MiOIR,融顺序学习与提示学习于一体!
- NAFNet :无需非线性激活,真“反直觉”!但复原性能也是真强!
- 真实用!ETH团以合成数据+Swin-Conv构建新型实用盲图像降噪
- ELAN | 比SwinIR快4倍,图像超分中更高效Transformer应用探索