背景
ES7 相比于 ES6 有多个层面的优化,对于开源的ES而言,升级是必经之路。
ES的使用场景非常多,在升级过程中可能会遇到非预期的结果;
比如之前文章提到的典型案例:ES7.17版本terms查询性能问题
ES7.17版本terms查询性能问题_es terms查询慢 profile-CSDN博客
接下来再分析一个升级之后聚合性能下降的case;
场景
1. 按照标准最佳实践进行改造(分片控制在20G左右,term/terms查询使用keyword类型...)
2. 集群从ES6.8.5 升级到 ES7.17.5
3. 异常:升级后性能骤降
avg 100ms -> 400ms
特定聚合查询 400ms -> 1500ms
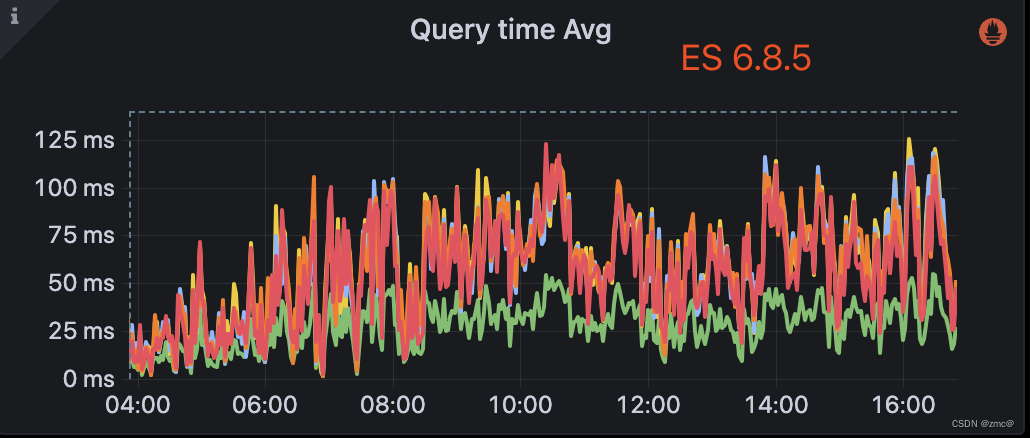
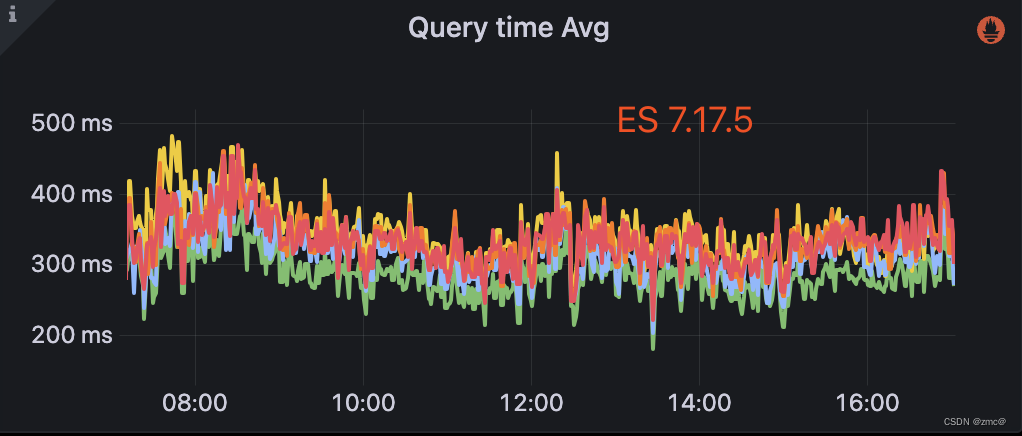
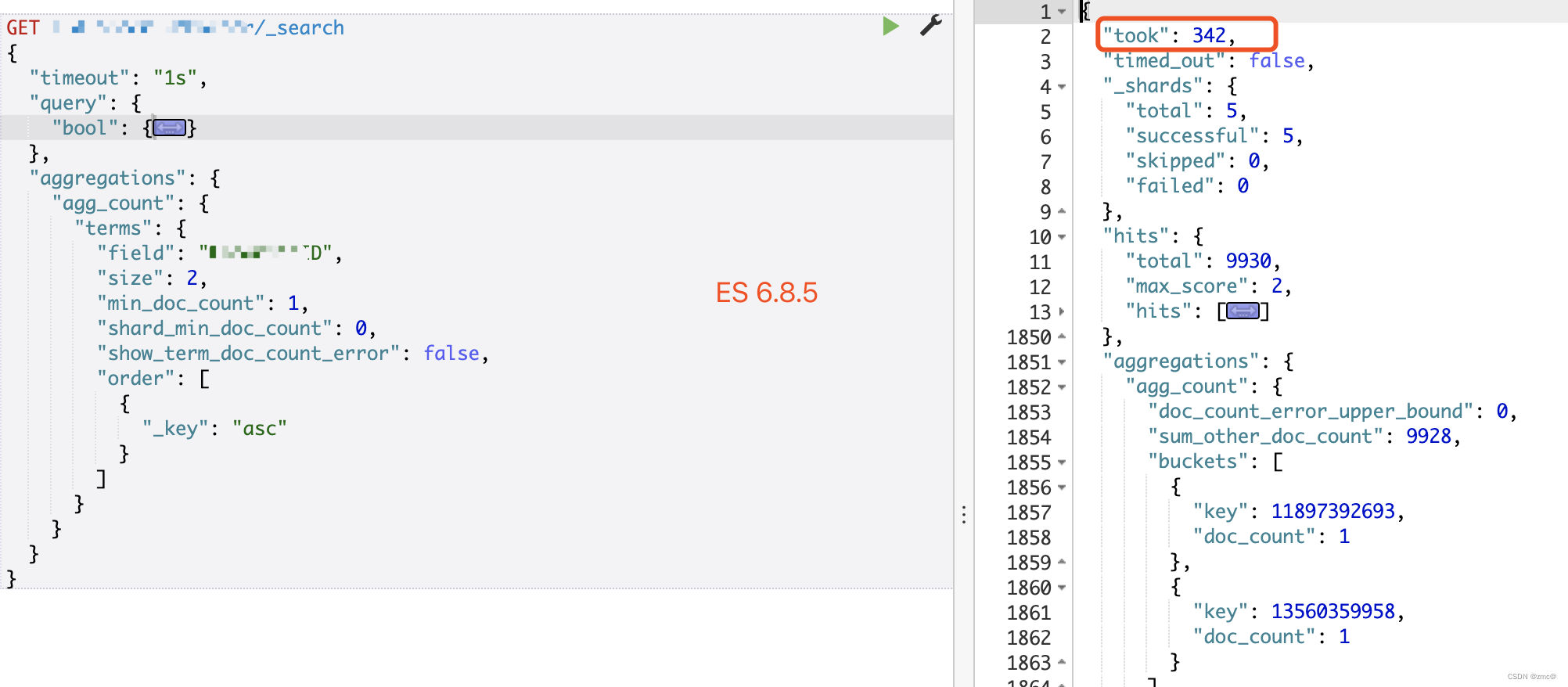
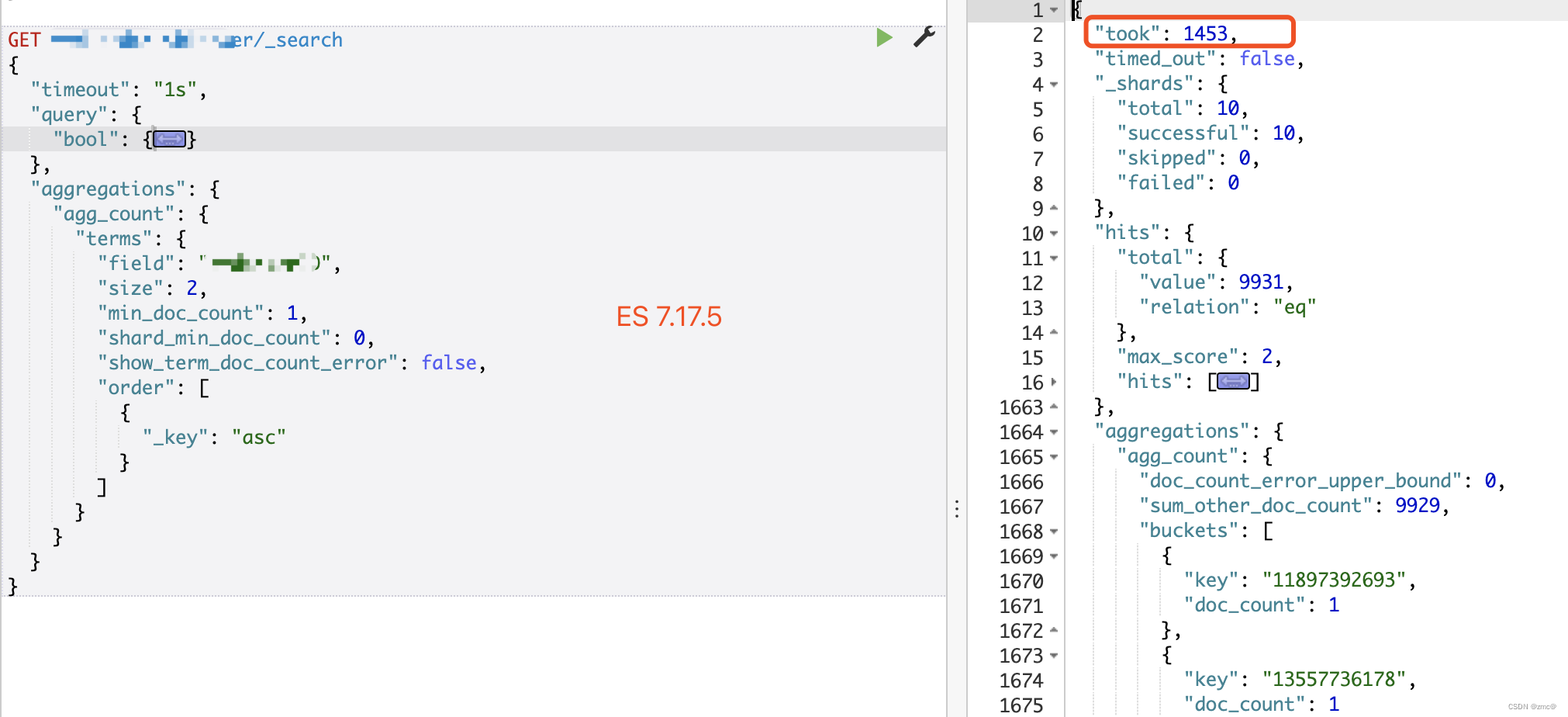
4. 通过 profile ,以及实际测试,耗时主要是在聚合
分析
1. 性能下降,随之而来的还有CPU升高
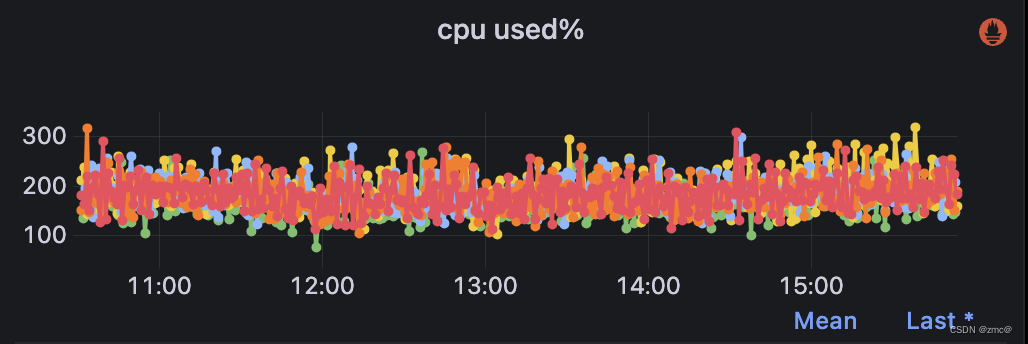
2. 通过 arthas 工具采集火焰图
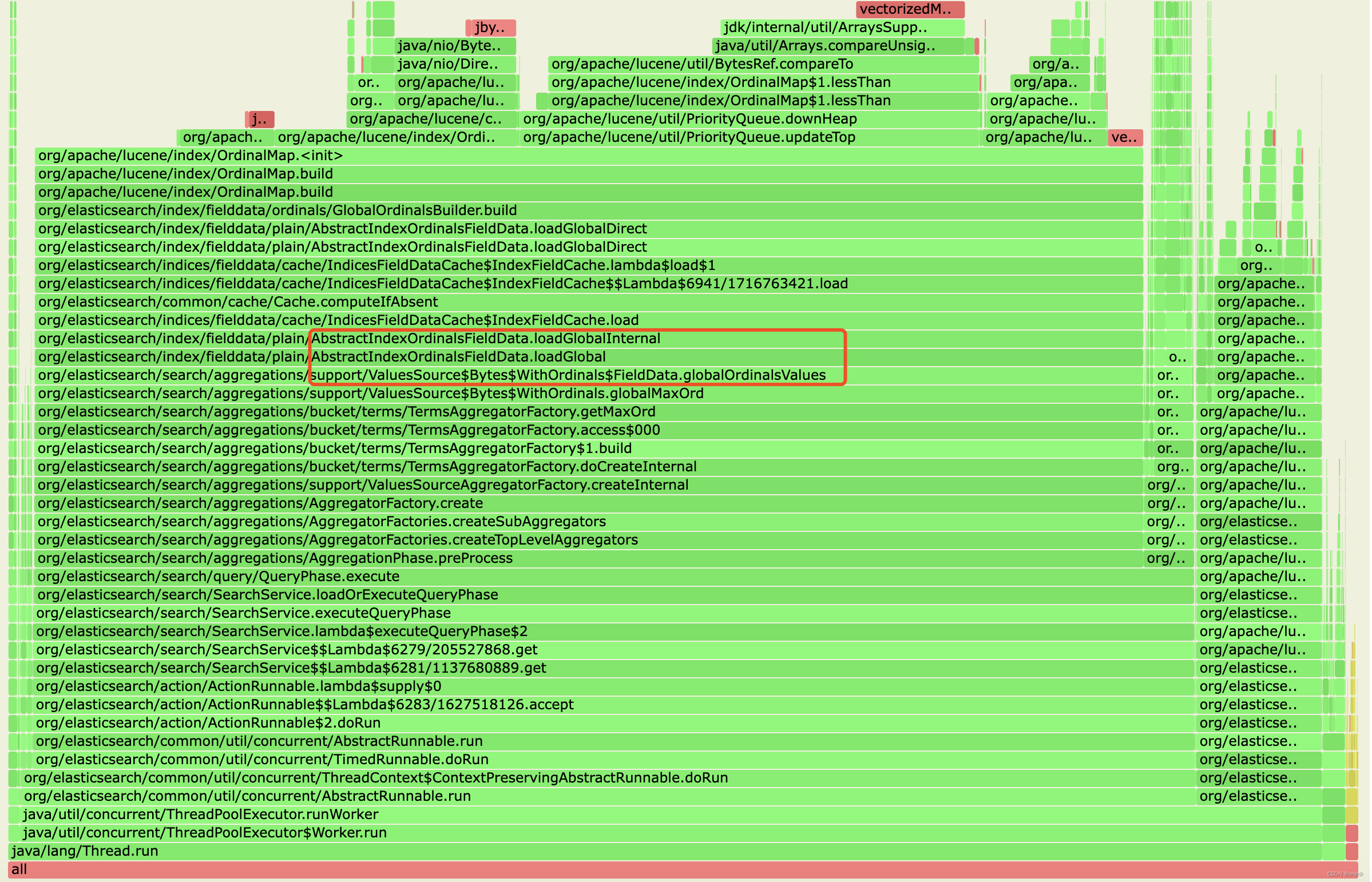
可以看到和global_ordinals全局序数相关;(查询/聚合时临时构建全局序数)
3. 针对全局序数,一般是2种优化手段
方案一:不使用序数 "execution_hint": "map"
注:只有在聚合时基数较小的情况下适用,否则容易OOM;(即字段整体数据基数较小;或者聚合时需要带有查询条件,查询条件筛选后用于聚合的字段数据基数比较小)
"aggregations": {
"agg_count": {
"terms": {
"field": "xxxxID",
"execution_hint": "map",
"size": 2,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_key": "asc"
}
]
}
}
}方案二:在查询之前提前创建好全局序数 "eager_global_ordinals": true,将全局序数的构建转移到索引(写数据)阶段,保证查询的效率
PUT xxxx/_mapping
{
"properties": {
"xxxxxID":{
"type": "keyword",
"eager_global_ordinals": true
}
}
}结论
1. 使用方案一,"execution_hint": "map",性能大幅提升
1600ms -> 10ms (没有pageCache时候是40ms左右)
注:POST xxxx/_cache/clear 只能清理ES本身的缓存,无法清理pageCache
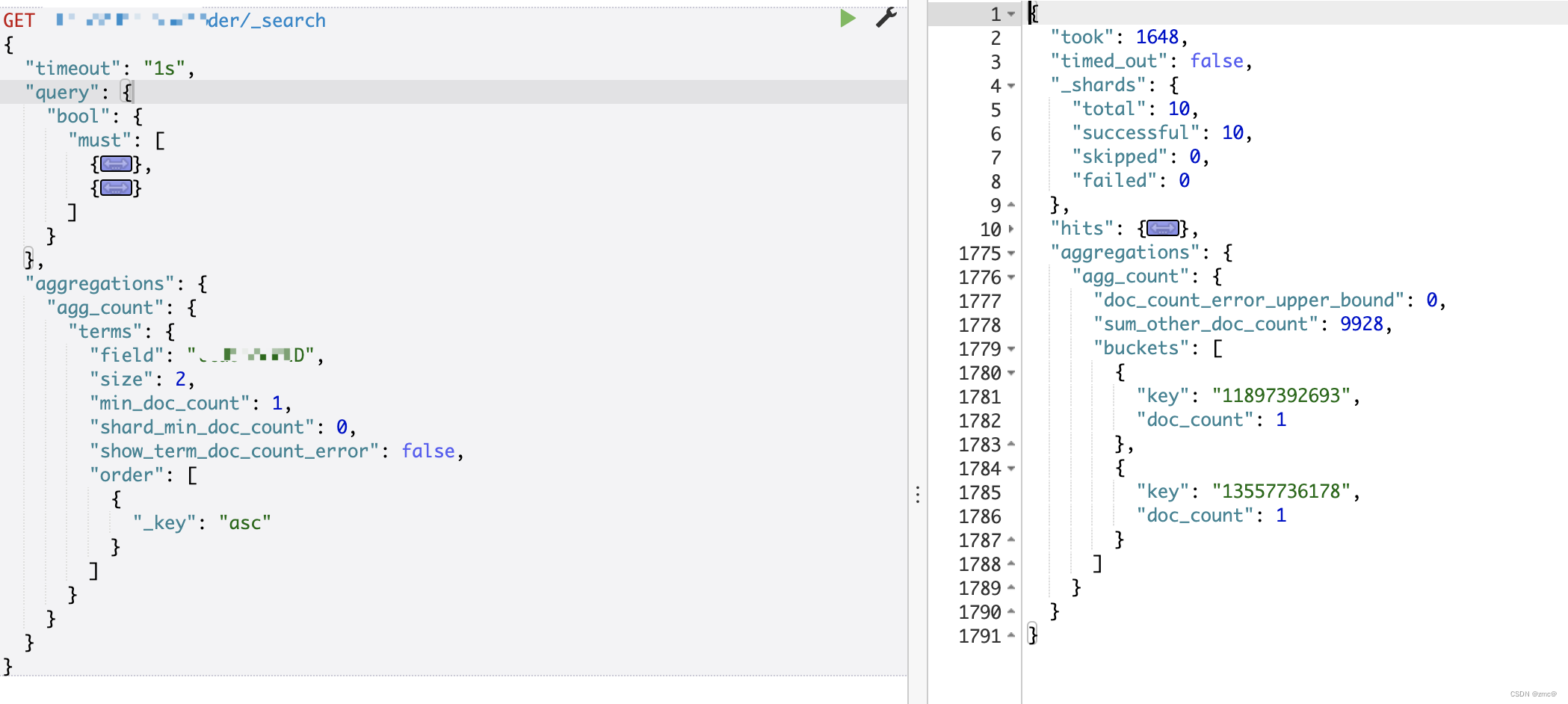
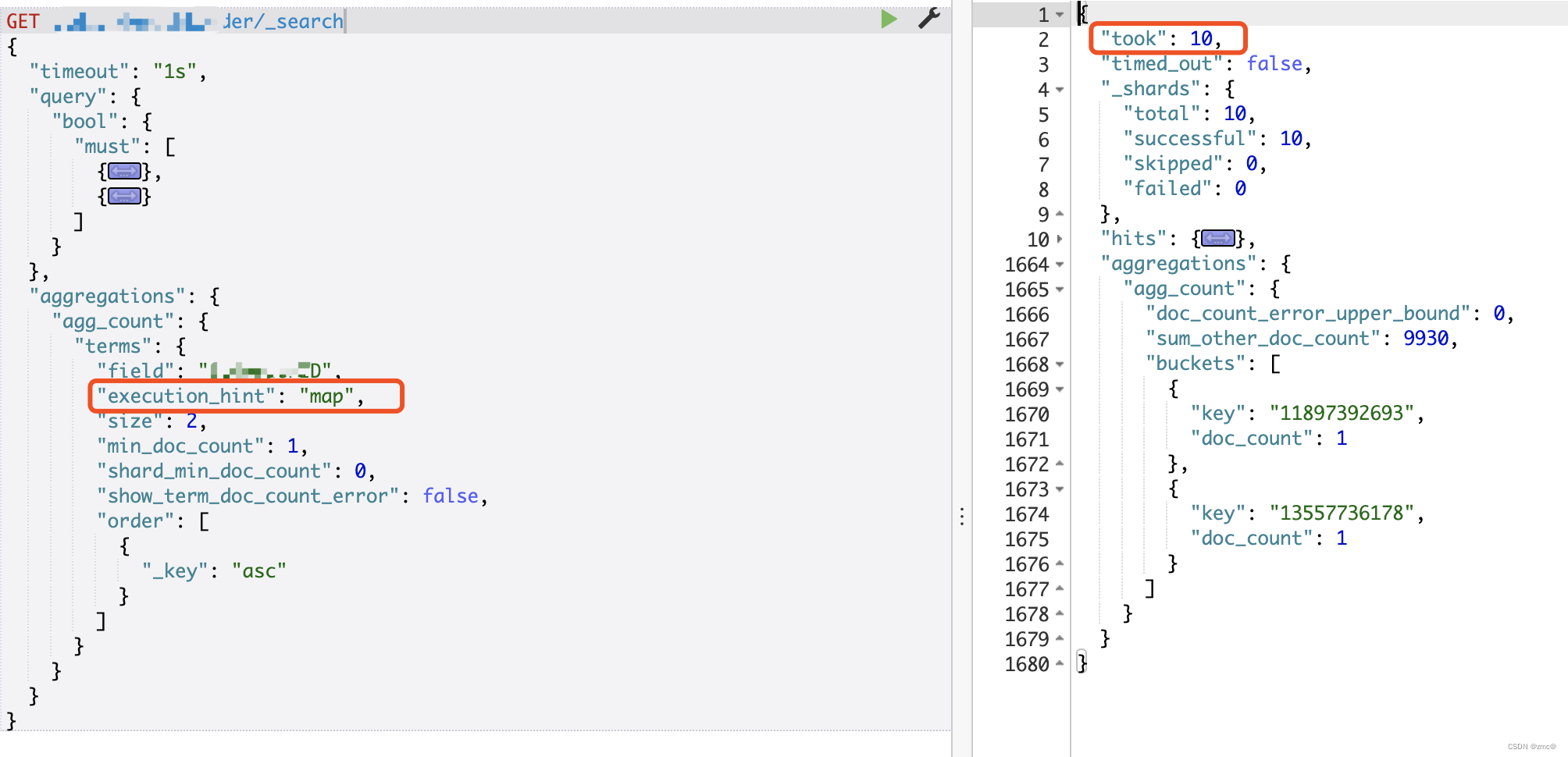
然后check一下terms聚合使用的字段的基数
POST xxxxx/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"count_aggs": {
"cardinality": {
"field": "xxxxID"
}
}
}
}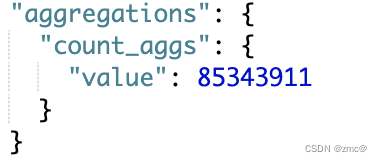
整个索引,该字段的基数为 8kw,如果聚合不带任何条件就会消耗大量内存;
如果聚合都带查询条件,那么该方案适用,并且性能提升 90%+;
2. 方案二需要重建索引,理论查询性能也会大幅提升,此处暂无测试数据
PUT xxxx/_mapping
{
"properties": {
"xxxxxID":{
"type": "keyword",
"eager_global_ordinals": true
}
}
}