文章目录
- 0、基本介绍
- 1、研究动机
- 2、创新点
- 3、挑战
- 4、准备
- 4.1、图上分类任务
- 4.2、少样本提示
- 4.3、提示图表示
- 5、方法论
- 5.1、提示图上的信息传播架构
- 5.1.1、Data graph Message Passing
- 5.1.2、Task graph Message Passing
- 5.1.3、Prediction Read out
- 5.2、In-context Pretraining Objectives
- 5.2.1、Pretraining Task Generation
- 5.2.2、用增广生成提示图
- 5.2.3、Pretraining Loss
- 6、实验
0、基本介绍
- 作者:Qian Huang,Hongyu Ren, Peng Chen
- 会议:NIPS-2023
- 文章链接:PRODIGY: Enabling In-context Learning Over Graphs
- 代码链接:PRODIGY: Enabling In-context Learning Over Graphs
What?Why?How?
1、研究动机
这是一篇思想迁移的文章。
首先,上下文学习是预训练模型通过提示示例进行调整以适应新的下游任务,而不需要参数优化。大语言模型具有这种上下文学习(In-context Learning)的能力,但是如何在图上进行上下文学习还没有被探索,那么这种上下文学习的能力,图学习具不具备呢?
读完本篇文章,答案是肯定的。本文作者,提出Pretraining Over Diverse In-Context Graph Systems(PRODIGY),第一个在图上使用上下文学习的预训练框架。
In-context Learning 提出在GPT-3之后,In-context Learning(上下文学习)是指在特定的上下文中学习的机器学习方法,他考虑到文本,图像等数据的上下文以及数据之间的关系和上下文信息的影响,在这种方法中,学习算法会利用上下文信息来提高预测和分类的准确性和有效性。又分为Few-Shot,One-Shot和Zero-shot。
图上上下文学习的目标是什么?
图的上下文学习应该能够在新的图上解决新的任务。
作者的目的是旨在将上下文学习的成功扩展到图形,并开始构建图形基础模型
2、创新点
提出Pretraining Over Diverse In-Context Graph Systems(PRODIGY),第一个在图上使用上下文学习的预训练框架。
关键思想是,设计了一种提示图来表示图上的上下文学习,这个提示图连接了提示示例和查询。然后又提出了一个图神经网络架构的提示图和相应的上下文预训练目标组件。这样,PRODIGY预训练模型可以通过上下文学习直接在看不见的图上执行新的下游分类任务。
3、挑战
挑战1:如何用统一的任务设计和表示结点,边和图级任务,使模型能够解决不同的任务,而不需重新训练或调整参数。关键是如何设计图上的Prompt。
挑战2:如何设计模型结构和预训练目标,使模型在统一任务表示中的不同任务和不同图上实现上下文学习能力。
现有的图预训练方法,目的是学习一个好的图编码器,在面对不同任务时需要进行微调。而图上的元学习方法目的时在同一个图上实现对不同任务的处理。实现情境学习需要解决在没有微调的情况下概括图和任务描述。
针对上面的两个挑战,作者提出一个通用的方法用于图上分类任务:
(1)prompt graph——一个上下文图任务表示
提示图对各种结点,边和图级机器学习任务提供统一的表示方式。提示图首先对我们做预测的输入结点/边”上下文化“,然后与额外的标签结点相连,这样提示示例与查询相互关联(方法论部分会详细介绍)。这种统一的表示允许将不同的机器学习任务指定给同一个模型,而不管图的大小。
(2)Pretraining Over Diverse In-Context Graph Systems(PRODIGY)——在提示图上预训练上下文学习器的框架
基于提示图上下文任务,设计模型架构和预训练目标,使模型可以预先训练,然后解决各种图中的任务,开箱即用。
模型架构利用GNNs学习结点/边的表征,并通过一个注意力机制在提示图上信息交换。此外又在提示图上提出一组上下文预训练目标,包括自监督预训练任务,邻居匹配(分类一个结点/边属于哪个邻域)。
4、准备
4.1、图上分类任务
首先,定义一个图 G = ( V , E , R ) \mathcal{G}=(\mathcal{V},\mathcal{E},\mathcal{R}) G=(V,E,R), V , E , R \mathcal{V},\mathcal{E},\mathcal{R} V,E,R分别表示结点集合,边集合和关系集合。一条边 e = ( u , r , v ) ∈ E e=(u,r,v)\in \mathcal{E} e=(u,r,v)∈E包含主(subject)结点 u ∈ V u\in \mathcal{V} u∈V,关系 r ∈ R r\in \mathcal{R} r∈R和次(object)结点 v ∈ V v \in \mathcal{V} v∈V。
对于给定的类别集合 Y \mathcal{Y} Y,标准的分类任务是预测每一个输入 x ∈ X x\in\mathcal{X} x∈X的标签 y ∈ Y y\in\mathcal{Y} y∈Y。结点级分类任务类似,但每个输入是图中的结点,即 X = V \mathcal{X}=\mathcal{V} X=V,和额外的辅助信息,图 G \mathcal{G} G。
边级分类任务是预测任意结点对可能形成边的最匹配标签,即 X = V × V \mathcal{X}=\mathcal{V}\times \mathcal{V} X=V×V。特殊的一个例子就是类别等于关系 Y = R \mathcal{Y}=\mathcal{R} Y=R
类似的,这个定义也可以拓展到子图和图级分类任务,输入数据 x x x可能包含更多的结点和边。如何表示?留下疑问。
本文主要关注于用少样本提示的图上进行结点分类和边分类的上下文学习任务。
由于本篇文章关注不同类型/级别的任务,需要设计一个统一的形式:输入空间 X \mathcal{X} X包含多个图(graphs),即, x i ∈ X , x i = ( V i , E i , R i ) x_i\in\mathcal{X},x_i=(\mathcal{V}_i,\mathcal{E}_i,\mathcal{R}_i) xi∈X,xi=(Vi,Ei,Ri)。对于结点分类任务, G i \mathcal{G}_i Gi仅仅包含我们要预测的输入结点,即 ∣ V i ∣ = 1 |\mathcal{V}_i|=1 ∣Vi∣=1且 ∣ E i ∣ = 0 |\mathcal{E}_i|=0 ∣Ei∣=0;对于边分类任务,它包含(subject,object)结点对,即 ∣ V i ∣ = 2 |\mathcal{V}_i|=2 ∣Vi∣=2且 ∣ E i ∣ = 0 |\mathcal{E}_i|=0 ∣Ei∣=0(为什么边集合为空?)
4.2、少样本提示
这里定义了具有few-shot prompting的图上分类任务的上下文学习的设置。
对于下游任务是m-way的分类任务( ∣ Y ∣ = m |\mathcal{Y}|=m ∣Y∣=m)的k-shot 提示,使用少量的input-label对 S = { ( x i , y i ) } i = 1 m ⋅ k \mathcal{S}=\{(x_i,y_i)\}^{m·k}_{i=1} S={(xi,yi)}i=1m⋅k作为任务说明的提示示例。模型的查询集合——我们想要预测标签的,定义为 Q = { x i } i = 1 n \mathcal{Q}=\{x_i\}^n_{i=1} Q={xi}i=1n。
图上分了任务与自然语言和其他模态的一个重要区别是,由于所有的输入数据点都是来自较大的source graph G \mathcal{G} G,因此该图 G \mathcal{G} G包含了关键信息并提供了输入的上下文,例如我们要预测结点的局部邻域。因此,在prompt中除了 S \mathcal{S} S和 Q \mathcal{Q} Q,我们也需要包含source graph G \mathcal{G} G。
在下一小节,将会介绍如何将上述信息统一为一个有效的输入形式。
4.3、提示图表示
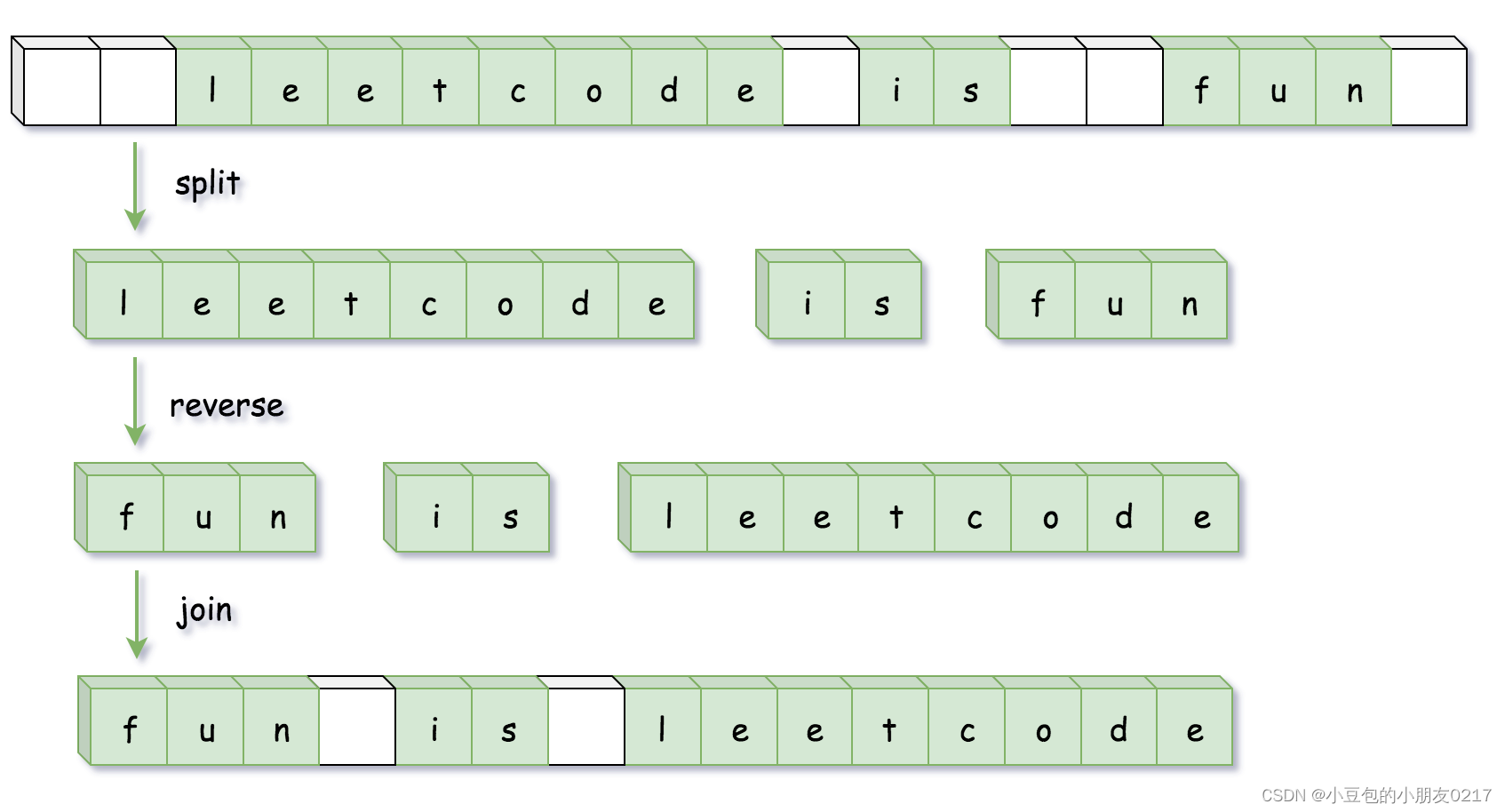
一个提示图由两个部分组成,data graph 和 task graph。提示图,通过data graph,task graph中的数据节点和标签结点,捕获输入数据与标签之间的关系。
4.3.1、Data graph G D \mathcal{G}^D GD
首先对source graph G \mathcal{G} G中的 S \mathcal{S} S和 Q \mathcal{Q} Q中的数据点 x i = ( V i , E i , R i ) x_i=(\mathcal{V}_i,\mathcal{E}_i,\mathcal{R}_i) xi=(Vi,Ei,Ri)执行上下文化,上下文化的目的就是从source graph G \mathcal{G} G中收集更多的关于 x i x_i xi的信息,而不必显示的表示整个source graph。
本文通过对source graph
G
\mathcal{G}
G中的顶点集
V
i
\mathcal{V}_i
Vi采样k-hop邻域构建data graph
G
i
D
\mathcal{G}^D_i
GiD,换句话说,
G
i
D
=
(
V
i
D
,
E
i
D
,
R
i
D
)
∼
⊕
i
=
0
k
Neighbor
(
V
i
,
G
,
i
)
\mathcal{G}^D_i=(\mathcal{V}_i^D,\mathcal{E}_i^D,\mathcal{R}_i^D) \sim \oplus^k_{i=0} \text{Neighbor}(\mathcal{V}_i,\mathcal{G},i)
GiD=(ViD,EiD,RiD)∼⊕i=0kNeighbor(Vi,G,i)
其中
V
i
⊆
V
i
D
⊆
V
,
E
i
⊆
E
i
D
⊆
E
,
R
i
⊆
R
i
D
⊆
R
\mathcal{V}_i\subseteq\mathcal{V}_i^{\mathrm{D}}\subseteq\mathcal{V},\mathcal{E}_i\subseteq\mathcal{E}_i^{\mathrm{D}}\subseteq\mathcal{E},\mathcal{R}_i\subseteq\mathcal{R}_i^{\mathrm{D}}\subseteq\mathcal{R}
Vi⊆ViD⊆V,Ei⊆EiD⊆E,Ri⊆RiD⊆R,
Neighbor
\text{Neighbor}
Neighbor是一个函数,返回集合
V
i
\mathcal{V}_i
Vi中每个结点的i-hop邻居。
4.3.2、task graph G T \mathcal{G}^T GT
任务图更好的捕获输入和标签之间的连接和关系。
对于每个数据图 G i D \mathcal{G}_i^D GiD,对应数据结点(data node) v x i v_{x_i} vxi表示每个输入,对于每个标签,有标签结点(label node) v y i v_{y_i} vyi,所以一个任务图有m*k+n个结点(figure 1中如何计算)。
task graph G T \mathcal{G}^T GT:在数据结点和标签结点之间添加边,对于查询结合,我们不知道每个图的标签,将来自所有标签结点的单向边与查询集中的每个数据点相连,即所有的标签结点与每个查询数据结点 v x i v_{x_i} vxi相连;对于提示集合,每个数据结点与所有的标签结点相连,具有真实标签的边被标记为T,而其他边被标记为F。
5、方法论
上一节,给出了一个用于图上分类任务的几个提示,以及定义了提示图的表示方法,用来捕获了提示示例,查询和标签之间的关系。现在需要设计一个预训练策略,它可以预训练一个能够在上下文中学习的可推广的模型。
假设访问预训练图 G pretrain \mathcal{G}_{\text{pretrain}} Gpretrain,该预训练图 G pretrain \mathcal{G}_{\text{pretrain}} Gpretrain独立于下游任务的source graph G \mathcal{G} G。下面介绍PRODIGY,这是一个基于 G pretrain \mathcal{G}_{\text{pretrain}} Gpretrain的通用预训练框架,专门用于在下游分类任务中实现上下文学习,而无需在任意图上进行任何额外的微调步骤。
PRODIGY框架主要包含两个组件:提示图上的模型架构和上下文预训练目标。
5.1、提示图上的信息传播架构
模型架构包含两个子模块,数据图信息传播和任务图信息传播。下面分别介绍。
5.1.1、Data graph Message Passing
首先,对于每个数据图
G
D
\mathcal{G}^D
GD应用一个信息传播GNN模块
M
D
M_D
MD学习结点表征:
E
∈
R
∣
V
D
∣
×
d
=
M
D
(
G
D
)
E\in\mathcal{R}^{|\mathcal{V}^D|\times d}=M_D(\mathcal{G}^D)
E∈R∣VD∣×d=MD(GD)
其中,
d
d
d是嵌入维度,
M
D
M_D
MD可以是GCN也可以是GAT。
每个数据图读出单一的嵌入
G
i
G_i
Gi,执行一个聚合步骤pool节点嵌入。对于结点分类任务,采用要预测的单个输入节点的更新节点表示:
G
i
=
E
V
i
G_i = E_{\mathcal{V}_i}
Gi=EVi
对于链接预测任务,拼接要预测链接的节点对,和所有节点表示上的最大池化,最优有个一个线性变换层,转换嵌入维度为
d
d
d:
G
i
=
W
T
(
E
v
1
∈
V
i
∣
∣
E
v
2
∈
V
i
∣
∣
m
a
x
(
E
i
)
)
+
b
G_{i}=W^{T}(E_{v_{1}\in\mathcal{V}_{i}}||E_{v_{2}\in\mathcal{V}_{i}}||\mathrm{max}(E_{i}))+b
Gi=WT(Ev1∈Vi∣∣Ev2∈Vi∣∣max(Ei))+b
其中,||为拼接操作,
W
∈
R
3
d
×
d
W\in \mathcal{R}^{3d\times d}
W∈R3d×d是可学习的权重矩阵,
b
b
b是可学习的偏置。
5.1.2、Task graph Message Passing
在上一步中,提示集合 S \mathcal{S} S和查询集合 Q \mathcal{Q} Q中的不同数据点之间没有交流。希望通过在任务图 G T \mathcal{G}^T GT上消息传递实现它们之间的通信。
提示图的邻接矩阵非对称
首先,在任务图上应用一个GNN模块
M
T
M_T
MT获取数据结点和标签结点跟新后的表征:
H
=
M
T
(
G
T
)
H=M_T(\mathcal{G}^T)
H=MT(GT)
其中,
H
\text{H}
H为得到的每个结点的嵌入。数据节点
v
x
i
v_{x_i}
vxi最初的嵌入为
G
i
G_i
Gi;标签结点
v
y
i
v_{y_i}
vyi的嵌入可以用随机高斯或者是与标签相关的信息初始化。每条边上也有两个二值特征
e
i
j
e_{ij}
eij指示1)边来自提示示例还是查询;2)边的类型是T还是F。
M
T
M_T
MT为基于注意力的GNN,其中每个节点执行对每个层处的其它节点的关注,具体形式如下:
β i j = M L P ( W q T H i l ∣ ∣ W k T H j l ∣ ∣ e i j ) α i j = exp ( β i j ) ∑ k ∈ N ( i ) ∪ { i } exp ( β i k ) H i l + 1 = R e L U ( B N ( H i l + W o T ∑ j ∈ N ( i ) ∪ { i } α i j W v T H j l ) ) \begin{aligned} \beta_{ij}& =MLP\big(W_{q}^{T}H_{i}^{l}||W_{k}^{T}H_{j}^{l}||e_{ij}\big) \\ \alpha_{ij}& =\frac{\exp(\beta_{ij})}{\sum_{k\in\mathcal{N}(i)\cup\{i\}}\exp(\beta_{ik})} \\ H_{i}^{l+1}& =ReLU\left(BN\left(H_{i}^{l}+W_{o}^{T}\sum_{j\in\mathcal{N}(i)\cup\{i\}}\alpha_{ij}W_{v}^{T}H_{j}^{l}\right)\right) \end{aligned} βijαijHil+1=MLP(WqTHil∣∣WkTHjl∣∣eij)=∑k∈N(i)∪{i}exp(βik)exp(βij)=ReLU BN Hil+WoTj∈N(i)∪{i}∑αijWvTHjl
这步的目标是使用支持示例(support example)学习标签节点的表征,并将标签信息传播回支持和查询图表征,以用于特定任务的图表示。
5.1.3、Prediction Read out
最终的预测结果通过余弦相似度计算(cosine similarity)。通过在查询图表征和标签表征之间计算余弦相似度来的出分类结果
O
i
O_i
Oi:
O
i
=
[
cosine_similarity
(
H
x
i
,
H
y
)
,
∀
y
∈
Y
]
O_i=[\begin{matrix}\text{cosine\_similarity}(H_{x_i},H_y),\forall y\in\mathcal{Y}\end{matrix}]
Oi=[cosine_similarity(Hxi,Hy),∀y∈Y]
在多轮中执行两个消息传递步骤,以便在
X
i
X_i
Xi之间进行更多的通信,并学习更好的表示。
5.2、In-context Pretraining Objectives
为了对模型进行预训练,以解决上下文中的下游图任务,作者提出了一组上下文预训练目标。使用独立于下游任务图source graph的大的预训练图 G pretrain G_{\text{pretrain}} Gpretrain来预训练图模型。这样之后,模型可以直接应用于具有上下文学习的下游任务中。
我们以提示图的形式显式地构建上下文预训练任务,并对模型进行预训练,以使用相同的权重在上下文中解决不同的任务,这样它就可以直接在下游任务上执行上下文学习
下面开始介绍作者提出的上下文预训练目标的三个组成部分:1)预训练任务生成,包含少样本提示和对应的标签;2)将生成的few-shot提示转换为提示图格式;3)生成提示图的预训练损失。
5.2.1、Pretraining Task Generation
本文提出两种方法以少样本提示的方法从预训练图
G
pretrain
\mathcal{G}_{\text{pretrain}}
Gpretrain生成预训练任务:邻居匹配(neighbor matching)和多任务(multi-task)
(1)neighbor matching
给定预训练图,构建自监督上下文预训练任务,目标是分类结点属于哪个局部邻域,每个局部邻域由该邻域的example结点定义。预训练图
G
pretrain
\mathcal{G}_{\text{pretrain}}
Gpretrain中采样多个子图作为局部邻域。如果一个结点在采样的子图中,那么它就属于这个邻域。
首先,定义一个采样器,
NM
k
,
m
\text{NM}_{k,m}
NMk,m,生成m-way邻域匹配任务(m个类别),每个包含k个提示(
G
pretrain
,
S
N
M
,
Q
N
M
\mathcal{G}_{\text{pretrain}},\mathcal{S}_{NM},\mathcal{Q}_{NM}
Gpretrain,SNM,QNM)和查询的标签。为了简化表示,在
Q
N
M
\mathcal{Q}_{NM}
QNM中包含与输入匹配的标签:
(
G
pretrain
,
S
NM
,
Q
NM
)
∼
NM
k
,
m
(
G
pretrain
)
(\mathcal{G}_{\text{pretrain}},\mathcal{S}_{\text{NM}},\mathcal{Q}_{\text{NM}})\sim\text{NM}_{k,m}(\mathcal{G}_{\text{pretrain}})
(Gpretrain,SNM,QNM)∼NMk,m(Gpretrain)
具体来说,首先从预训练图
G
pretrain
\mathcal{G}_{\text{pretrain}}
Gpretrain中采样m个结点,每个采样的结点对应一个类别:
C
=
{
c
i
}
i
=
1
m
c
i
∼
U
n
i
f
o
r
m
(
V
pretrain
)
\mathcal{C}=\{c_{i}\}_{i=1}^{m}\quad c_{i}\sim Uniform(\mathcal{V}_{\text{pretrain}})
C={ci}i=1mci∼Uniform(Vpretrain)
对于每个采样结点/类别
c
i
c_i
ci,从他的l-hop邻域中采样k个不同的结点。这k个结点视作标签
c
i
c_i
ci的提示示例(example),同时采样额外的
⌈
n
m
⌉
\lceil\frac{n}{m}\rceil
⌈mn⌉个结点作为标签
c
i
c_i
ci的查询集合:
N
i
=
Neighbor
(
c
i
,
G
pretrain
,
l
)
S
i
=
{
(
x
j
,
y
j
=
c
i
)
}
j
=
1
k
x
j
∼
U
n
i
f
o
r
m
(
N
i
)
Q
i
=
{
(
x
j
,
y
j
=
c
i
)
}
j
=
1
⌈
n
m
⌉
x
j
∼
U
n
i
f
o
r
m
(
N
i
)
\begin{aligned}N_i=&\text{Neighbor}(c_i,\mathcal{G}_\text{pretrain},l)\\\mathcal{S}_i=&\{(x_j,y_j=c_i)\}_{j=1}^k&x_j\sim Uniform(N_i)\\\mathcal{Q}_i=&\{(x_j,y_j=c_i)\}_{j=1}^{\lceil\frac n m\rceil}&x_j\sim Uniform(N_i)\end{aligned}
Ni=Si=Qi=Neighbor(ci,Gpretrain,l){(xj,yj=ci)}j=1k{(xj,yj=ci)}j=1⌈mn⌉xj∼Uniform(Ni)xj∼Uniform(Ni)
通过这种方式,我们构建了一个以少量提示形式的邻居匹配预训练任务样本 ( G p r e t r a i n , S N M = ⋃ S i , Q N M = ⋃ Q i ) (\mathcal{G}_{\mathrm{pretrain}},\mathcal{S}_{\mathrm{NM}}=\bigcup\mathcal{S}_{i},\mathcal{Q}_{\mathrm{NM}}=\bigcup\mathcal{Q}_{i}) (Gpretrain,SNM=⋃Si,QNM=⋃Qi)。
上述的构建方法还是基于同质性假设,相邻的结点信息可能类似。
上面这个方法适用于结点分类任务。针对于链接预测,首先随机采样包含输入结点 x i x_i xi的边将每个采样的输入结点 x i x_i xi扩展到边,邻域匹配任务则变为分类查询集和中的边属于哪个邻域。(讲的不是很明白!)
(2)multi-task
(这一步在干什么?有什么作用?)
对于一些输入 x i ∈ V pretrain or E pretrain x_i \in \mathcal{V}_{\text{pretrain}}\; \text{or} \;\mathcal{E}_{\text{pretrain}} xi∈VpretrainorEpretrain,预训练图中可能包含结点级 或 边级标签 f ( x i ) = y i ∈ Y f(x_i)=y_i\in\mathcal{Y} f(xi)=yi∈Y。 可以进一步利用这个信号来执行监督预训练。与邻居匹配类似,关键是以少量提示和相应标签的格式构建这种监督预训练任务。
( G p r e t r a i n , S M T , Q M T ) ∼ M T k , m ( G p r e t r a i n , f ) (\mathcal{G}_{\mathrm{pretrain}},\mathcal{S}_{\mathrm{MT}},\mathcal{Q}_{\mathrm{MT}})\sim\mathrm{MT}_{k,m}(\mathcal{G}_{\mathrm{pretrain}},f) (Gpretrain,SMT,QMT)∼MTk,m(Gpretrain,f)
对于结点分类任务,首先,从整个标签集采样m个标签,然后对于每个标签,直接采样k个结点作为support examples并采样
⌈
n
m
⌉
\lceil\frac{n}{m}\rceil
⌈mn⌉个具有标签的结点作为query examples。
C
=
{
c
i
}
i
=
1
m
c
i
∼
U
n
i
f
o
r
m
(
Y
)
S
i
=
{
(
x
j
,
y
j
=
c
i
)
}
j
=
1
k
x
j
∼
U
n
i
f
o
r
m
(
{
x
i
∣
f
(
x
i
)
=
c
i
}
)
Q
i
=
{
(
x
j
,
y
j
=
c
i
)
}
j
=
1
⌈
n
m
⌉
x
j
∼
U
n
i
f
o
r
m
(
{
x
i
∣
f
(
x
i
)
=
c
i
}
)
\begin{aligned}\mathcal{C}&=\{c_i\}_{i=1}^m\quad c_i\sim Uniform(\mathcal{Y})\\\mathcal{S}_i&=\{(x_j,y_j=c_i)\}_{j=1}^k\quad x_j\sim Uniform(\{x_i|f(x_i)=c_i\})\\\mathcal{Q}_i&=\{(x_j,y_j=c_i)\}_{j=1}^{\lceil\frac{n}{m}\rceil}\quad x_j\sim Uniform(\{x_i|f(x_i)=c_i\})\end{aligned}
CSiQi={ci}i=1mci∼Uniform(Y)={(xj,yj=ci)}j=1kxj∼Uniform({xi∣f(xi)=ci})={(xj,yj=ci)}j=1⌈mn⌉xj∼Uniform({xi∣f(xi)=ci})
然后构建具有少样本提示的任务, ( G pretrain , S MT = ⋃ S i , Q MT = ⋃ Q i ) (\mathcal{G}_\text{pretrain},\mathcal{S}_\text{MT}=\bigcup\mathcal{S}_i,\mathcal{Q}_\text{MT}=\bigcup\mathcal{Q}_i) (Gpretrain,SMT=⋃Si,QMT=⋃Qi)。
(链路预测这里讲的也不是很明白)
对于链接预测,直接用边类型函数
f
f
f,即
f
(
(
v
1
,
v
2
)
)
=
r
⟺
(
v
1
,
r
,
v
2
)
∈
E
f((v_{1},v_{2}))=r\Longleftrightarrow(v_{1},r,v_{2})\in\mathcal{E}
f((v1,v2))=r⟺(v1,r,v2)∈E。有了这个
f
f
f,我们可以直接对边类型进行采样,并以类似于上面的方式构建预训练任务。
这种有监督的预训练目标的好处是,与邻居匹配目标相比,它可以直接类似于下游任务的格式,而邻居匹配目标只能作为替代。然而,如果 f f f不是 G p r e t r a i n \mathcal{G}_{\mathrm{pretrain}} Gpretrain的一部分,则需要额外的标签,例如,对于某些预训练图可能不存在的节点分类标签。
5.2.2、用增广生成提示图
在我们获得这两个任务(NeighborMatching and multi-task)中任何一个的少量提示和标签之后,需要构建提示图用于预训练。除了4.3节提出的标准的构建过程,受对比学习启发,增加了一个额外的增广步骤增广数据图。
关键是corrupt data graph,使得预训练的模型学习对各种破坏不变的表示。
下面介绍如何从 G p r e t r a i n \mathcal{G}_{\mathrm{pretrain}} Gpretrain生成的少样本提示构建提示图的过程采用图增广技术。首先,在提示示例和查询中,对每个采样 G i \mathcal{G}_i Gi采样k-hop邻域子图: G i D ∼ ⨁ j = 1 k Neighbor ( G i , G pretrain , j ) \mathcal{G}_i^\text{D}\sim\bigoplus_{j=1}^k\text{Neighbor}(\mathcal{G}_i,\mathcal{G}_{\text{pretrain}},j) GiD∼⨁j=1kNeighbor(Gi,Gpretrain,j)。然后采用两个增广技术创建增广后的data graph G i a u g \mathcal{G}_i^{aug} Giaug:node dropping 和node feature masking。对于node dropping ,随机的从k-hop邻域子图中随机丢弃结点,并将剩余的图记为 G i a u g = DropNode ( G i D ) \mathcal{G}_i^{aug}=\text{DropNode}(\mathcal{G}_i^{D}) Giaug=DropNode(GiD)。对于node feature masking,用零值随机地掩盖节点子集的特征,以创建 G i a u g = MaskNode ( G i D ) \mathcal{G}_i^{aug}=\text{MaskNode}(\mathcal{G}_i^{D}) Giaug=MaskNode(GiD)。类似于4.3节提到的,利用提示示例和查询中的每个数据点的增强数据图,可以相应地通过为每个增强数据图创建数据节点 v x i v_{x_i} vxi和标签节点 v y i v_{y_i} vyi来构建任务图 G T \mathcal{G}^T GT。将数据图和任务图相结合,得到了少样本提示的增广后的提示图。
5.2.3、Pretraining Loss
最后,在生成的提示图上使用交叉熵损失函数对模型进行预训练:
( G pretrain , S NM , Q N M ) ∼ N M k , m ( G pretrain ) ( G p r e t r a i n , S M T , Q M T ) ∼ M T k , m ( G p r e t r a i n , f ) L = E x i ∈ Q N M C E ( O N M , i , y N M , i ) + E x i ∈ Q M T ( O M T , i , y M T , i ) \begin{gathered} (\mathcal{G}_\text{pretrain}{ , \mathcal{S}_\text{NM}{ , \mathcal{Q}_{NM}}}){\sim}\mathrm{NM}_{k,m}(\mathcal{G}_{\text{pretrain}} ) \\ (\mathcal{G}_{\mathrm{pretrain}},\mathcal{S}_{\mathrm{MT}},\mathcal{Q}_{\mathrm{MT}})\sim\mathsf{MT}_{k,m}(\mathcal{G}_{\mathrm{pretrain}},f) \\ \mathcal{L}=\underset{x_{i}\in\mathcal{Q}_{\mathrm{NM}}}{\mathbb{E}}\mathrm{CE}(O_{\mathrm{NM},i},y_{\mathrm{NM},i})+\underset{x_{i}\in\mathcal{Q}_{\mathrm{MT}}}{\mathbb{E}}(O_{\mathrm{MT},i},y_{\mathrm{MT},i}) \end{gathered} (Gpretrain,SNM,QNM)∼NMk,m(Gpretrain)(Gpretrain,SMT,QMT)∼MTk,m(Gpretrain,f)L=xi∈QNMECE(ONM,i,yNM,i)+xi∈QMTE(OMT,i,yMT,i)
其中, O N M , i O_{NM,i} ONM,i是模型在 G i a u g \mathcal{G}^{aug}_i Giaug和 Q N M \mathcal{Q}_{NM} QNM产生的 G T G^T GT的输入上产生的logit,如5.1节所述; y N M , i y_{NM,i} yNM,i是 Q N M \mathcal{Q}_{NM} QNM中 x i x_i xi的相应标签; MT \text{MT} MT项类似。
模型框架如下图所示:

6、实验
下图分别是节点分类和链接预测的实验结果,此外作者还做了消融实验和参数敏感性分析。