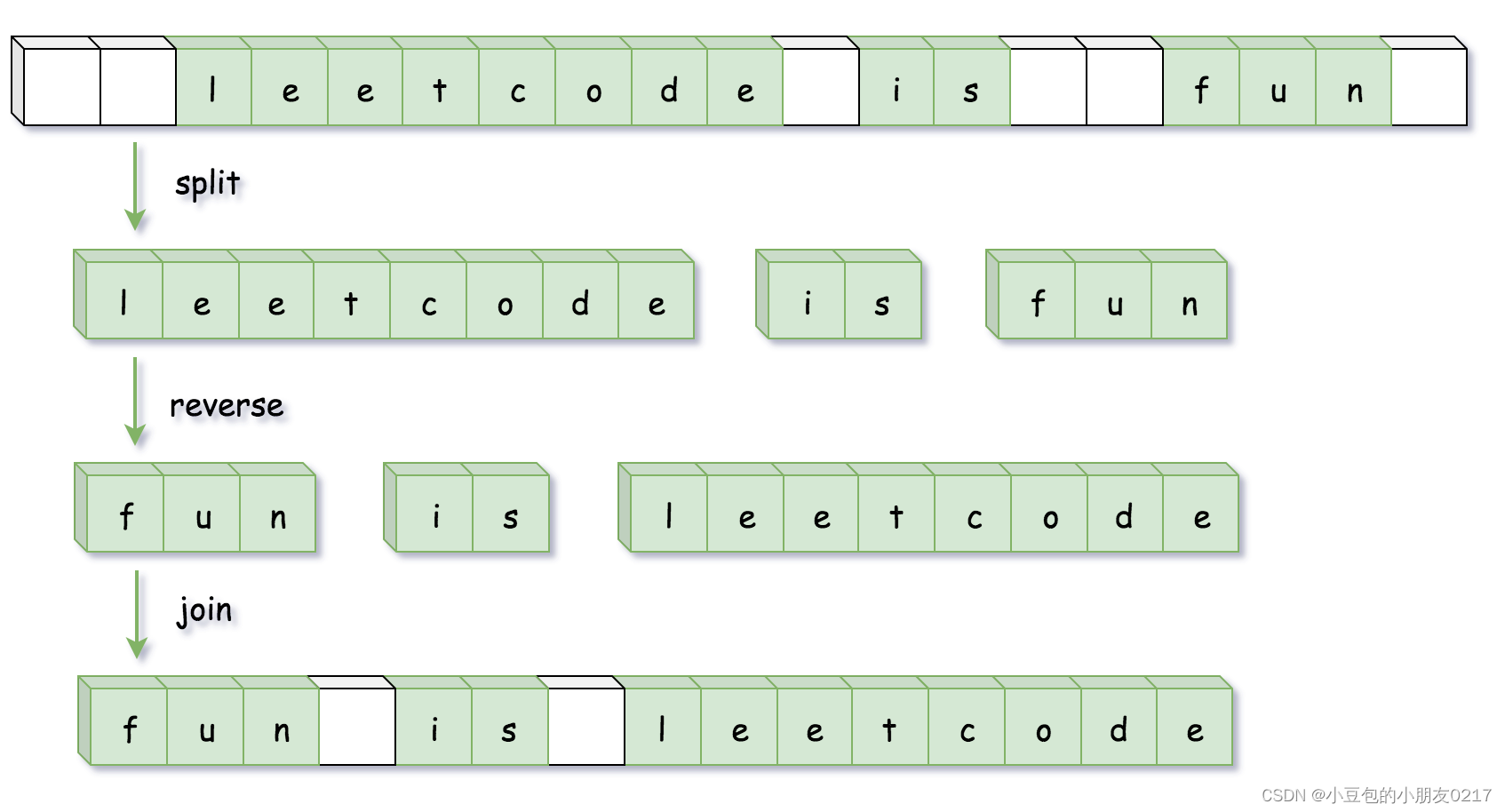
今天分享的这篇文章来自于上海人工智能实验室,论文的Title为:Latte: Latent Diffusion Transformer for Video Generation。该方法探索如何有效的对视频中的时间、空间信息进行建模,将视频信息有效的处理成连续的tokens。另外在如何提高视频生成质量上,也做了非常多的实验。 项目已开源,相关实验结果可以借鉴~
- 标题: Latte: Latent Diffusion Transformer for Video Generation
- URL: https://arxiv.org/abs/2401.03048v1
- 代码: https://github.com/Vchitect/Latte
- 作者: Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, Yu Qiao
一、概述
1 Motivation
- 视频生成技术如何提高生成质量是一个难题,如何更好的挖掘时序、空间的信息?采用何种架构对模型进行建模?这些都值得探索。
- 本文提出了一个全新的Latent Diffusion Transformer,名为Latte,用于视频生成。其目标是在潜在空间中对视频分布进行建模,并提高生成视频的质量。
2 Methods
方法概述:
Latte首先从输入视频中提取spatio-temporal tokens(空间-时间标记),然后采用一系列的Transformer块来在潜在空间对视频分布进行建模。
这里有两个难题,一个是如何充分挖掘视频的时间和空间维度的信息,从视频中抽取出连续的tokens。 本文对比了四种高效的模型变体来探索最优处理视频输入的方式。
另外一个难题是如何提升视频生成质量。 本文在模型变种 (Model Variants)、timestep-class information injection (时间步长类信息注入)、temporal positional embedding (时间位置嵌入)、and learning strategies (学习策略)等方面进行了充分的实验,来探索最优提升质量的方法。
2.1 The model variants of Latte
为了对从视频中提取的spatio-temporal information进行建模,我们从分解输入视频的空间和时间维度的角度引入了四种高效的变体。这些变体旨在通过不同的方式分解输入视频的空间和时间维度,以提高视频生成的质量。以下是这四种模型变体的详细介绍:
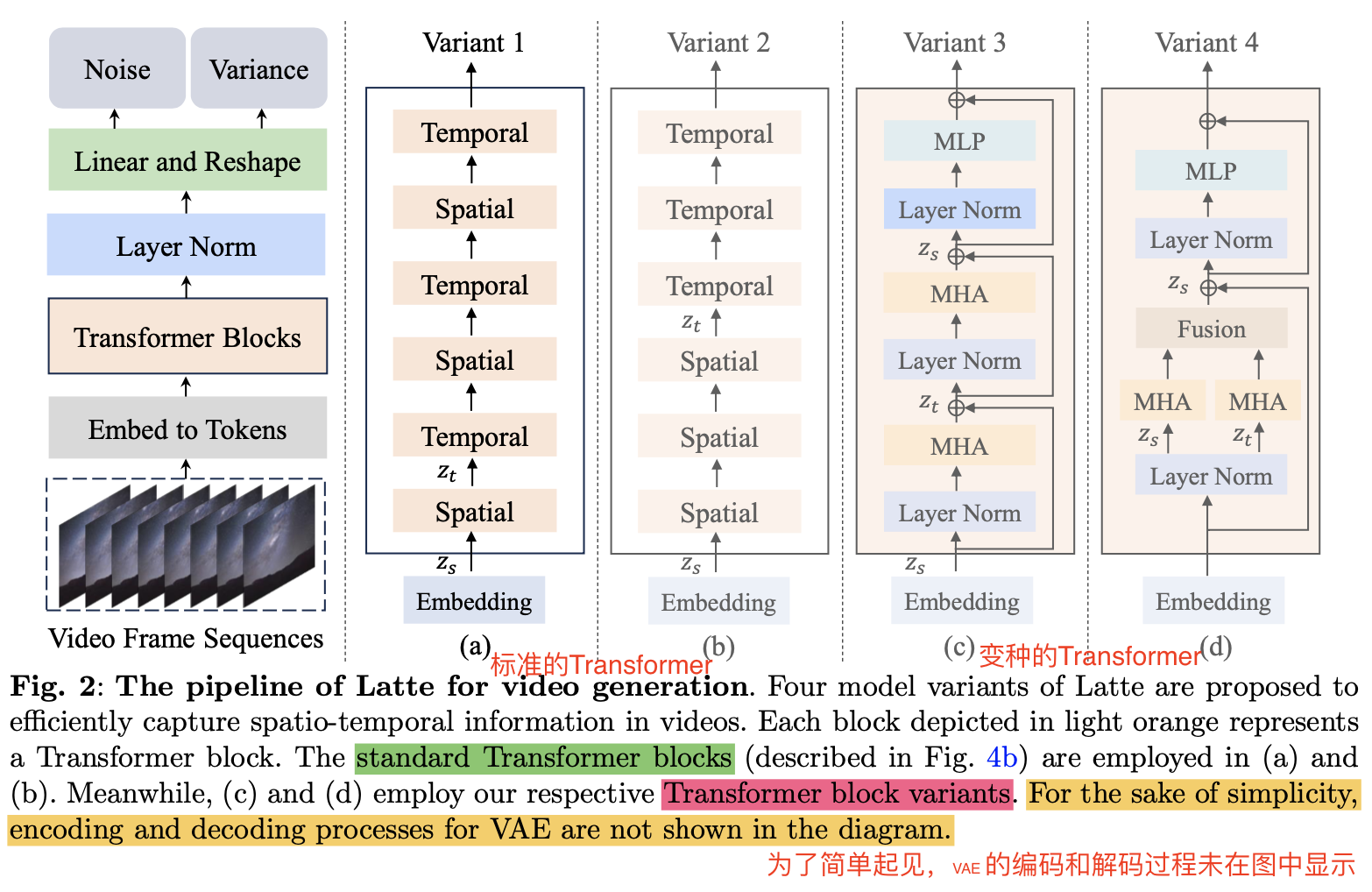
- Variant 1:这个变体的Transformer骨干由两种不同类型的Transformer块组成:空间Transformer块和时间Transformer块。空间Transformer块专注于在具有相同时间索引的token之间捕捉空间信息,而时间Transformer块则以“交错融合”的方式在时间维度上捕捉信息。
- Variant 2:与Variant 1中的“交错融合”设计不同,Variant 2采用了“后期融合”方法来结合时空信息。这个变体同样包含与Variant 1相同数量的Transformer块,输入形状与Variant 1相似,但融合时空信息的方式不同。
- Variant 3:专注于分解Transformer块中的多头注意力(multi-head attention)。这个变体首先在空间维度上计算自注意力,然后是时间维度,从而每个Transformer块都能捕捉到时空信息。
- Variant 4:多头注意力(MHA)被分解为两个组件,每个组件使用一半的注意力头。不同的组件分别处理空间和时间维度的token。两个不同的注意力操作计算完成后,时间维度的token被重塑并添加到空间维度的token中,然后作为Transformer块下一个模块的输入。
这些模型变体的设计旨在通过不同的策略来优化视频生成过程中的时空信息处理 ,以期达到更好的视频生成效果。在实验部分,作者通过综合分析这些变体,确定了最佳的实践方法,包括视频片段嵌入、模型变体、时间步长-类别信息注入、时间位置嵌入和学习策略,以实现高质量的视频生成。
2.2 The empirical analysis of Latte
为了提高生成视频的质量 ,我们通过严格的实验分析确定了 Latte 的最佳实验,包括video clip patch embedding(视频剪辑补丁嵌入)、model variants(模型变体)、timestep-class information injection,(时间步长-类信息注入)、temporal positional embedding(时间位置嵌入和学习策略),以下是这一节内容的详细介绍:
-
Latent video clip patch embedding:

- 作者探索了两种视频片段嵌入方法:均匀帧补丁嵌入(uniform frame patch embedding)和压缩帧补丁嵌入(compression frame patch embedding)。
- 均匀帧补丁嵌入是将每个视频帧单独嵌入到token中,类似于ViT(Vision Transformer)的方法。
- 考虑捕获时间信息,然后将 ViT patch 嵌入方法从 2D 扩展到 3D,随后沿着时间维度提取,通过按一定步长提取时间序列中的“管状”结构,然后映射到token。
-
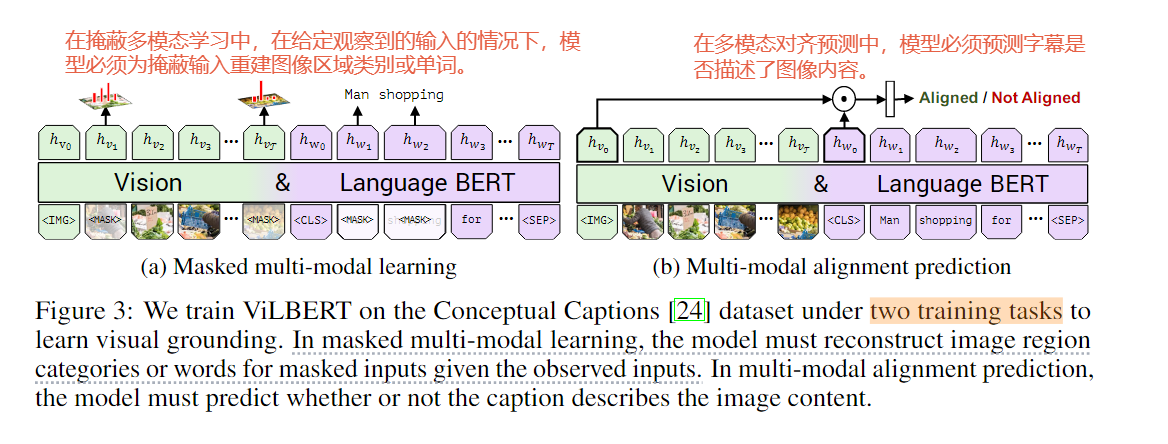
Timestep-class information injection:

图 4:(a)第 3.3.2 节中描述的 S-AdaLN 架构。(b)图 2(a)和(b)中使用的 vanilla transformer 块的架构。MLP 和 MHA 分别表示多层感知层和多头注意力。
- 为了将时间步长或类别信息集成到模型中,作者尝试了两种方法:将信息作为token处理(all tokens),以及采用可扩展自适应层归一化(S-AdaLN)。
- S-AdaLN通过线性回归计算γc和βc,然后应用到Transformer块的隐藏嵌入上,以适应性地编码时间步长或类别信息。
-
Temporal positional embedding:
- 为了使模型理解时间信号,作者探索了两种时间位置嵌入方法:绝对位置编码(absolute positional encoding)和相对位置编码(relative positional encoding)。
- 绝对位置编码使用不同频率的正弦和余弦函数,而相对位置编码则使用旋转位置编码(RoPE)来捕捉连续帧之间的时间关系。
-
Enhancing video generation with learning strategies:
- 作者研究了两种学习策略:使用预训练模型(ImageNet预训练)和图像-视频联合训练(image-video joint training)。
- 使用预训练模型可以利用ImageNet上学习到的图像生成知识,而图像-视频联合训练则通过在每个视频样本后附加随机选择的视频帧来提高模型的多样性和性能。
通过这些实证分析,作者确定了最佳的模型配置和训练策略,使得Latte模型能够在多个标准视频生成数据集上实现最先进的性能。这些分析结果对于理解如何将Transformer架构有效地集成到扩散模型中,以及如何优化视频生成过程具有重要意义。
3 Conclusion
- Latte模型在四个标准视频生成数据集(FaceForensics, SkyTimelapse, UCF101和Taichi-HD)上展示了其最先进的性能。
- Latte还被扩展到了文本到视频的生成任务上,并取得了与最新T2V模型相媲美的结果。
二、详细内容
1 在4个不同数据集上的视频生成效果
定性:
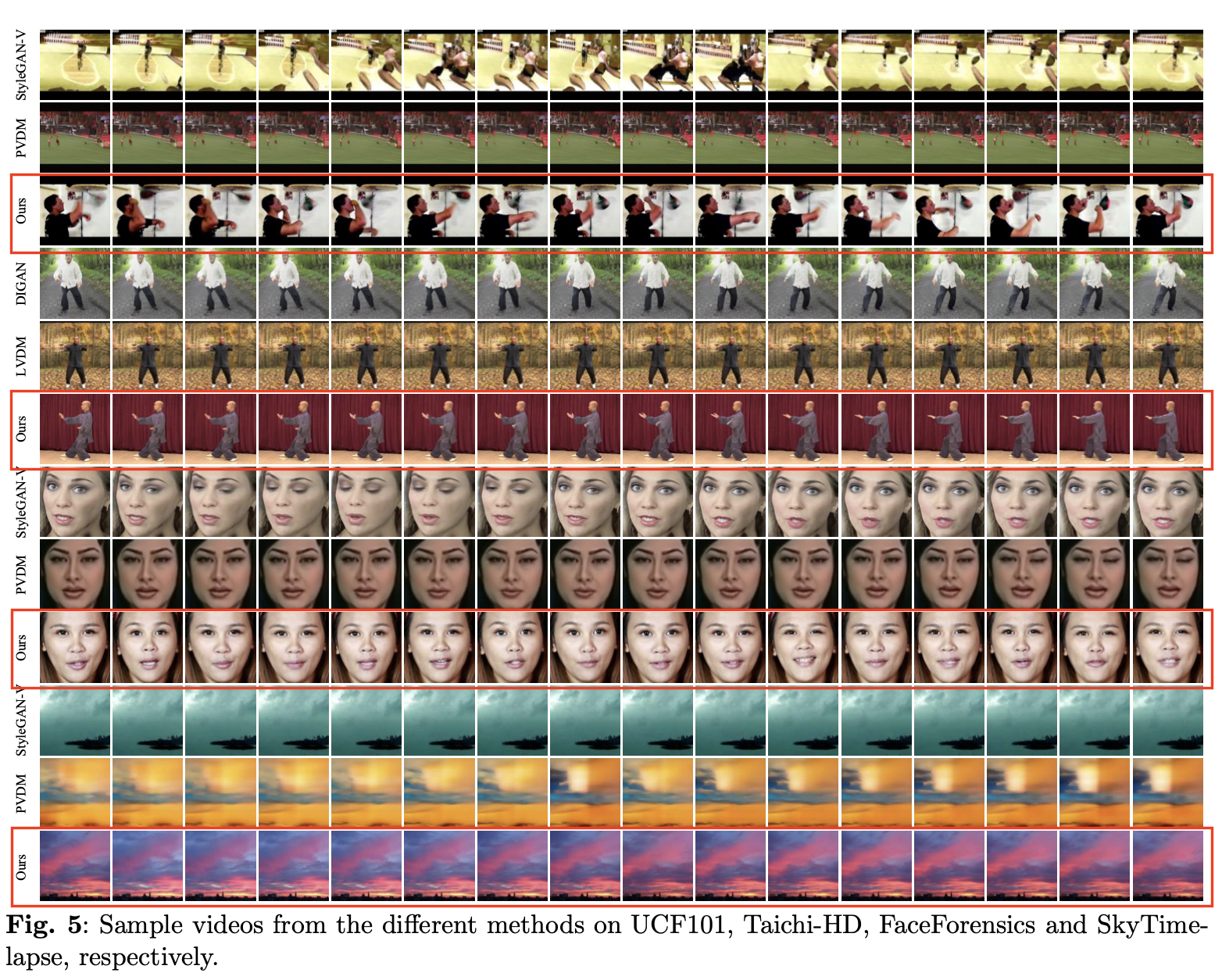
- 在具有挑战性的 UCF101 数据集内合成高质量视频方面表现出色,而其他方法往往在这项任务中失败。
定量:
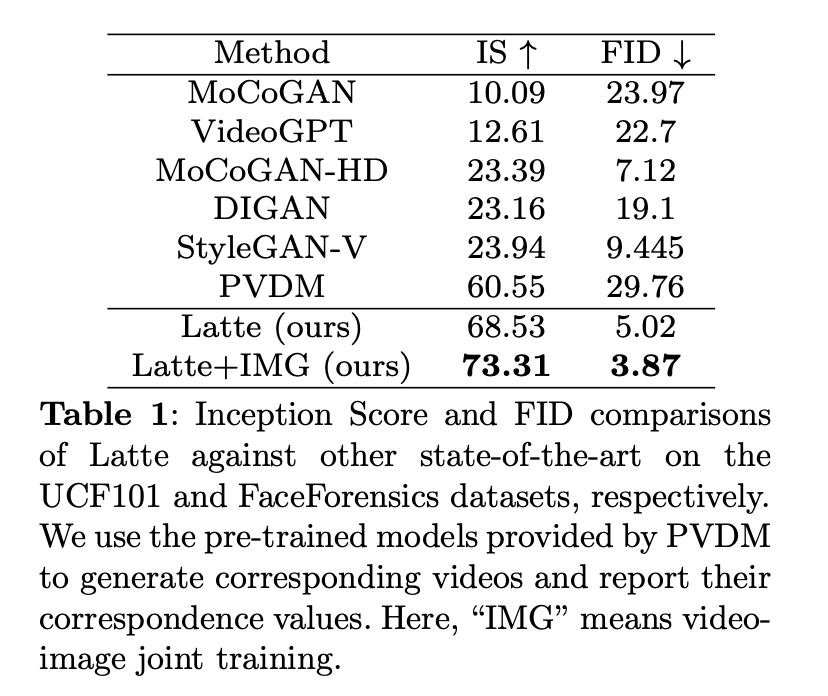

数据集选择:
- 实验主要在四个公开的视频数据集上进行:FaceForensics、SkyTimelapse、UCF101 和 Taichi-HD。
- 这些数据集用于训练和测试模型,以生成具有高分辨率(256×256像素)的视频。
评估指标:
- 评估指标:Fréchet Video Distance (FVD),FVD是一种评估视频生成质量的指标,它衡量生成视频与真实视频之间的相似度。
- FID和IS则用于评估视频帧的质量。
基线比较:
- 与当前最先进的视频生成方法进行了比较,包括MoCoGAN、VideoGPT、MoCoGAN-HD、DIGAN、StyleGAN-V、PVDM、MoStGAN-V 和 LVDM。
- Latte(本文提出的方法)
- Latte+IMG(本文提出的方法,结合了图像-视频联合训练):放方法在4项任务中,都取得了sota。
2 消融实验
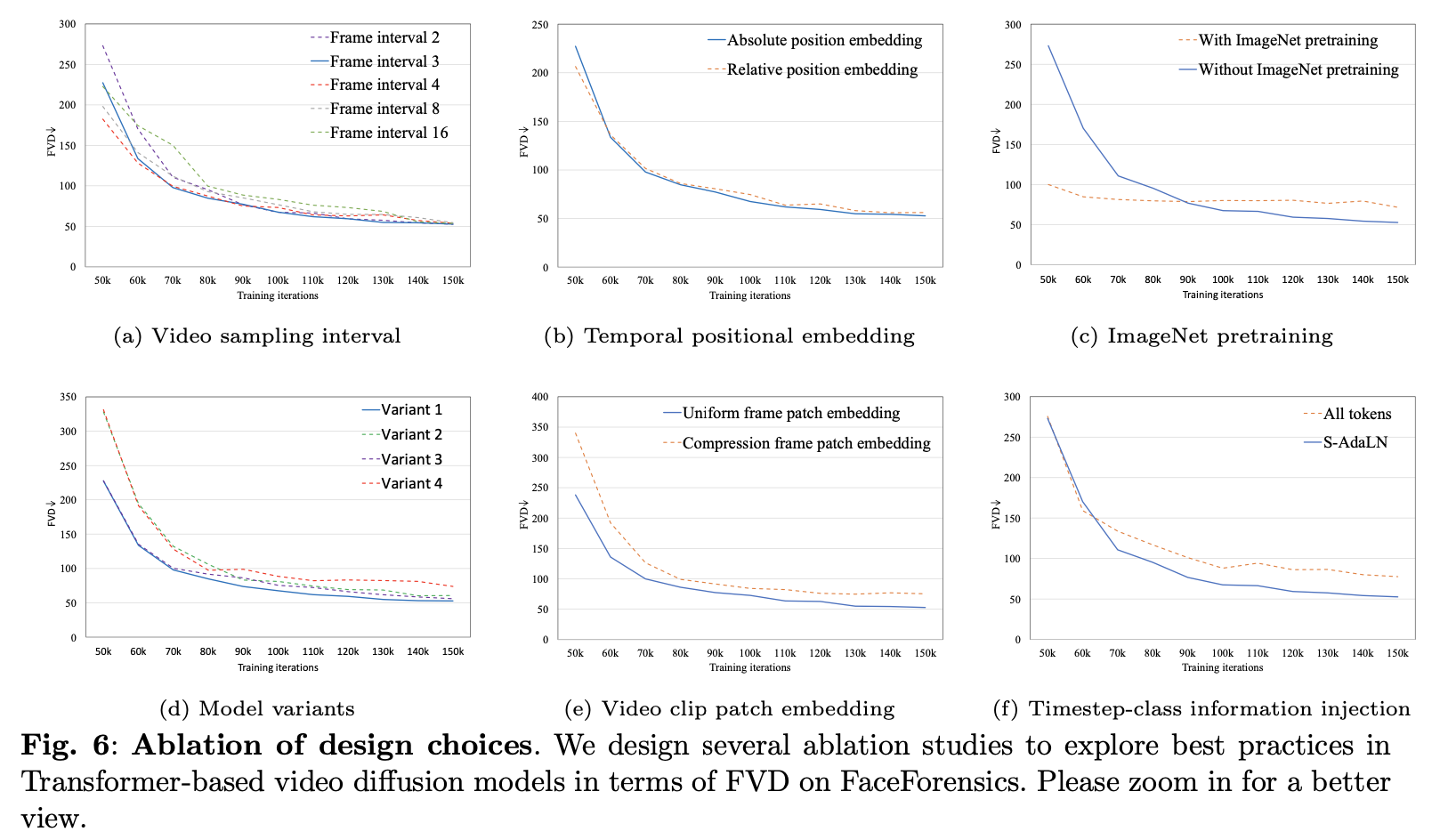
- Video sampling interval:研究不同的视频采样间隔对模型性能的影响。
- Temporal positional embedding:比较绝对位置编码和相对位置编码对模型性能的影响。
- ImageNet pretraining: 比较是否在ImageNet数据上进行预训练对实验结果的影响。
- Model variants:比较Latte模型的不同变体(Variant 1, Variant 2, Variant 3, Variant 4)在FVD上的表现。
- Video clip patch embedding:研究不同的视频片段嵌入方法对FVD的影响,例如均匀帧补丁嵌入与压缩帧补丁嵌入。
- Timestep-class information injection:分析将时间步长或类别信息以不同方式注入模型(如所有token或可扩展自适应层归一化S-AdaLN)对FVD的影响。
结论:
- Video sampling interval:不同的采样间隔在训练初期对性能有显著影响,但随着训练的进行,这些影响逐渐减小。
- Temporal positional embedding:绝对位置编码在某些情况下能提供稍微更好的结果。
- ImageNet pretraining: 使用在ImageNet上预训练的模型作为初始权重可以帮助视频生成模型更快地学习,但随着训练的进行,模型可能会遇到适应特定视频数据集分布的挑战。这可能导致性能在达到一定水平后趋于稳定,不再显著提高。
- Model variants:Variant 1在迭代增加时表现最佳,而Variant 4由于计算效率较高,尽管性能稍逊,但在资源受限的情况下可能是一个不错的选择。
- Video clip patch embedding:均匀帧补丁嵌入在某些情况下表现更好,因为它可能更好地保留了视频的时空信息。
- Timestep-class information injection:S-AdaLN方法更有效地将信息传递给模型,从而提高了性能。
3 模型大小对性能的影响
模型参数设置:
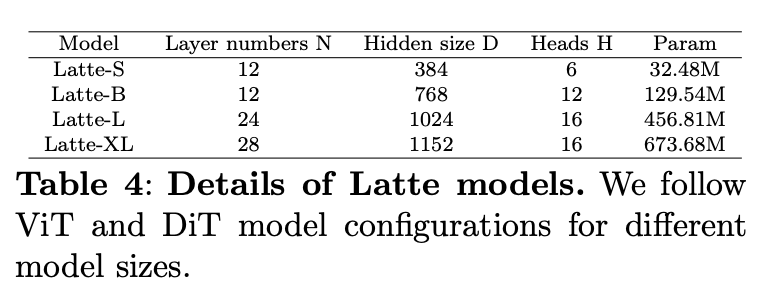
不同参数模型效果:
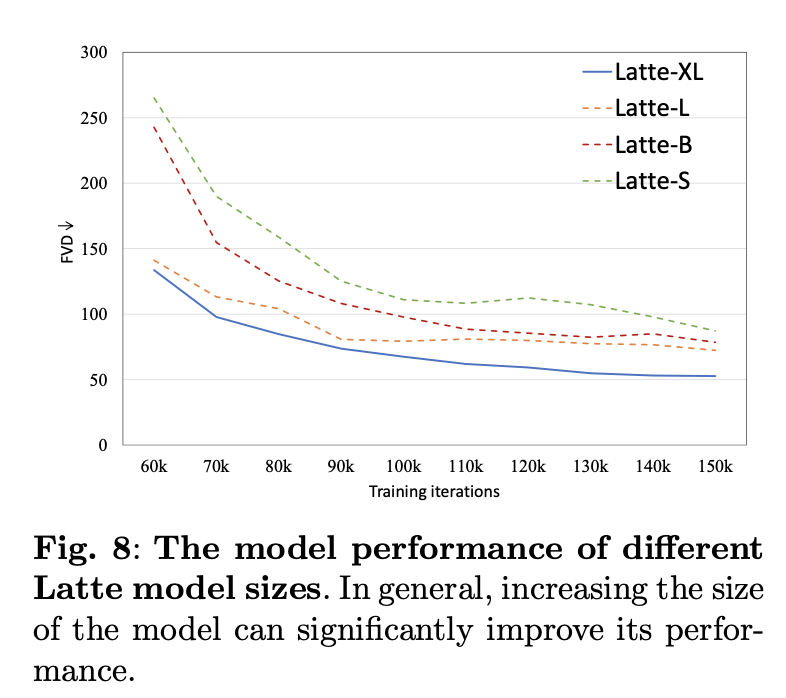
图表可能显示随着模型大小的增加,模型在视频生成任务上的性能(如FVD分数)通常会有所提高。这表明更大的模型能够捕捉更复杂的视频特征,从而生成更高质量的视频。
4 文本到视频生成(T2V)任务的表现

结论:Latte文生图能力也能与当前领先的VideoFusion和Align your Latents T2V模型相比了。
三、总结
亮点总结:
- Latte采用Transformer技术实现了视频生成的模型革新。 创新性地提取空间-时间标记并在潜在空间建模视频,效果在多个视频生成数据集上取得sota。
- 四种效率变体的引入允许更灵活地处理视频数据。 模型内部transformer结构上,探索了多种变体用于处理视频的时间、空间信息。
- 丰富的实验和分析确保了最佳实践的确定。 为了提升视频生成质量,在多个方面进行详细的实验与结果分析,相关经验都可借鉴!
应用价值和行业影响:
- Latte模型极具潜力,能够在视频生成和相关领域如自动动画制作、虚拟现实内容创建等方面发挥重大作用。
- 文本到视频的生成能力显示Latte在跨媒体内容生成领域的广泛适用性,对未来研究影响深远。
目前代码已经开源,相关代码实现和实验经验,可以给大家做一个有效的参考!
欢迎关注公众号: NLP PaperWeekly,后台回复Latte领取原始论文!
进技术交流群请添加我微信(id: FlyShines)
请备注昵称+公司/学校+研究方向,否则不予通过