深度学习
深度学习是加深了层的深度神经网络
加深网络
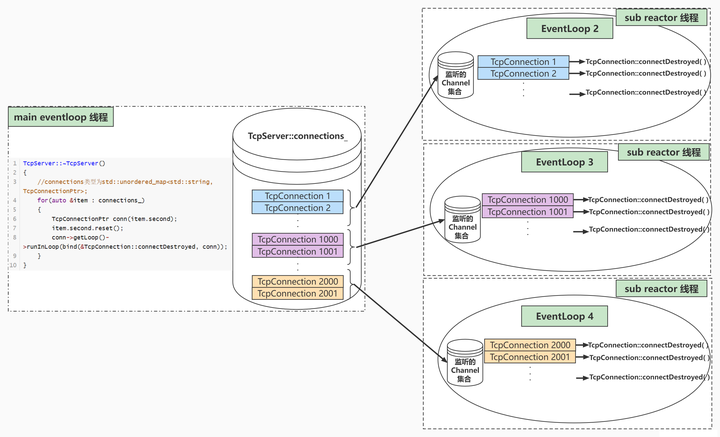
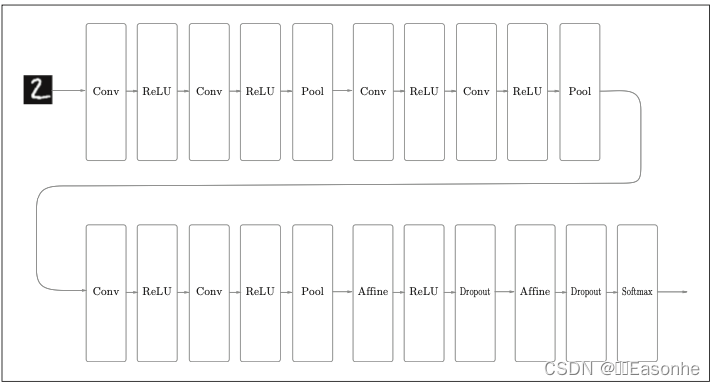
本节我们将这些已经学过的技术汇总起来,创建一个深度网络,挑战 MNIST 数据集的手写数字识别
向更深的网络出发
- 基于3×3的小型滤波器的卷积层。
- 激活函数是ReLU。
- 全连接层的后面使用Dropout层。
- 基于Adam的最优化。
- 使用He初始值作为权重初始值。
进一步提高识别精度
可以发现进一步提高识别精度的技术和 线索。比如,集成学习、学习率衰减、Data Augmentation(数据扩充)等都有 助于提高识别精度。尤其是Data Augmentation,虽然方法很简单,但在提高 识别精度上效果显著,Data Augmentation基于算法“人为地”扩充输入图像(训练图像)
加深层的动机
这种比赛的结果显示,最近前几名 的方法多是基于深度学习的,并且有逐渐加深网络的层的趋势。也就是说, 可以看到层越深,识别性能也越高。
加深层的好处:
- 可以减少网络的参数数量。
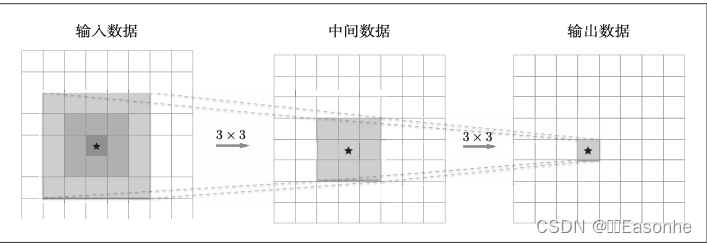
一次 5 × 5 的卷积运算的区域可以由两次 3 × 3 的卷积运算抵充。并且, 相对于前者的参数数量 25(5 × 5),后者(反向)一共是 18(2 × 3 × 3),通过叠加卷 积层,参数数量减少了。而且,这个参数数量之差会随着层的加深而变大。 比如,重复三次 3 × 3 的卷积运算时,参数的数量总共是 27。而为了用一次 卷积运算“观察”与之相同的区域,需要一个 7 × 7 的滤波器,此时的参数数 量是 49。
- 使学习更加高效。
通过加深层,可以分层次地传递信息,这一点也很重要。比如,因为提 取了边缘的层的下一层能够使用边缘的信息,所以应该能够高效地学习更加 高级的模式。也就是说,通过加深层,可以将各层要学习的问题分解成容易 解决的简单问题,从而可以进行高效的学习。
深度学习的小历史
一般认为,现在深度学习之所以受到大量关注,其契机是 2012 年举办 的大规模图像识别大赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)。在那年的比赛中,基于深度学习的方法(通称 AlexNet)以压倒 性的优势胜出,彻底颠覆了以往的图像识别方法。2012 年深度学习的这场逆袭成为一个转折点,在之后的比赛中,深度学习一直活跃在舞台中央。
ImageNet
ImageNet 是拥有超过 100 万张图像的数据集。如图 8-7 所示,它包含 了各种各样的图像,并且每张图像都被关联了标签(类别名)。每年都会举办 使用这个巨大数据集的 ILSVRC 图像识别大赛。

这些年深度学习取得了不斐的成绩,其中 VGG、GoogLeNet、ResNet深度学习 已广为人知,在与深度学习有关的各种场合都会遇到这些网络
VGG
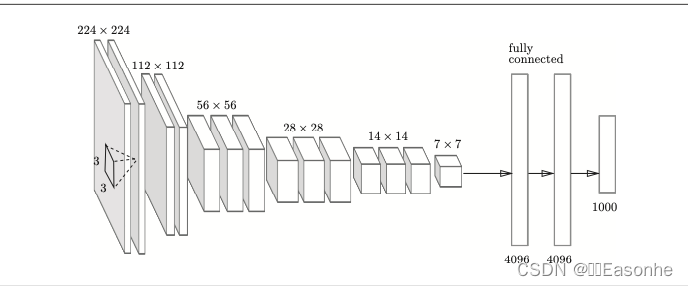
VGG 是由卷积层和池化层构成的基础的 CNN,它的特点在于将有权重的层(卷积层或者全连接层)叠加至 16 层(或者 19 层), 具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。
于 3×3 的小型滤波器的卷积层的运算是 连续进行的。重复进行“卷积层重叠 2 次到 4 次,再通过池化 层将大小减半”的处理,最后经由全连接层输出结果。
GoogLeNet
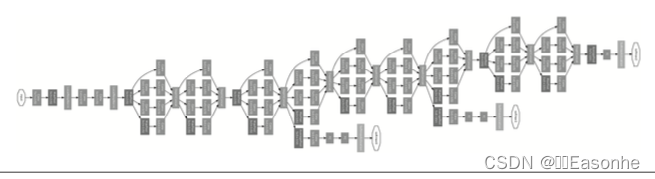
GoogLeNet 的特征是,网络不仅 在纵向上有深度,在横向上也有深度(广度),GoogLeNet 在横向上有“宽度”,这称为“Inception 结构”
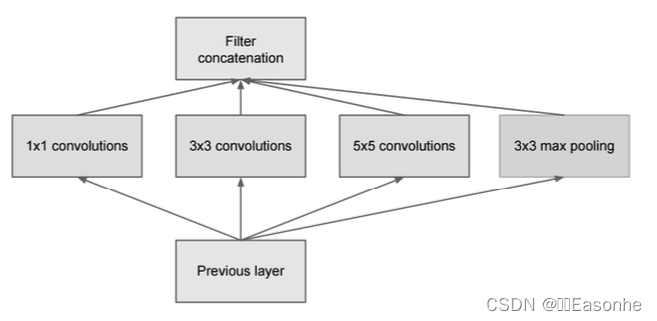
Inception 结构使用了多个大小不同的滤波器(和池化), 最后再合并它们的结果。GoogLeNet 的特征就是将这个 Inception 结构用作 一个构件(构成元素),很多地方都使用了大小为1 × 1 的滤波器的卷积层。这个 1 × 1 的卷积运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理
ResNet
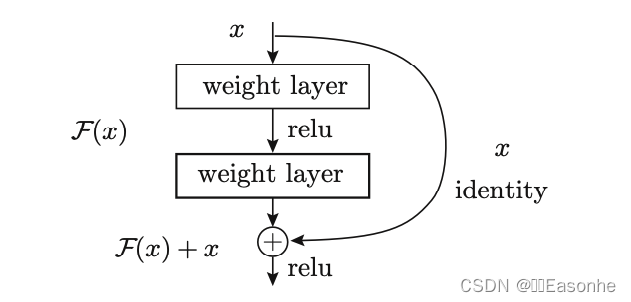
我们已经知道加深层对于提升性能很重要。但是,在深度学习中,过度 加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。ResNet 中, 为了解决这类问题,导入了“快捷结构”(也称为“捷径”或“小路”)。导入这 个快捷结构后,就可以随着层的加深而不断提高性能了(当然,层的加深也 是有限度的)。
在连续 2 层的卷积层中,将输入 x 跳着连接至 2 层后的输出。 这里的重点是,通过快捷结构,原来的 2 层卷积层的输出 F(x) 变成了 F(x) + x。 通过引入这种快捷结构,即使加深层,也能高效地学习。这是因为,通过快 捷结构,反向传播时信号可以无衰减地传递。
深度学习的高速化
大多数深度学习的框架都支持 GPU(Graphics Processing Unit),可以高速地处理大量的运算。另外,最 近的框架也开始支持多个 GPU 或多台机器上的分布式学习
需要努力解决的问题
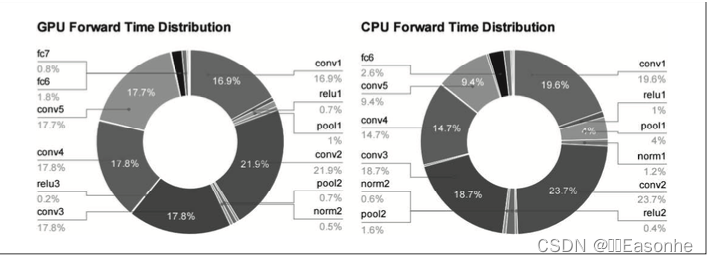
从图中可知,AlexNex 中,大多数时间都被耗费在卷积层上。实际上, 卷积层的处理时间加起来占 GPU 整体的 95%,占 CPU 整体的 89% !因此, 如何高速、高效地进行卷积层中的运算是深度学习的一大课题
基于 GPU 的高速化
GPU 原本是作为图像专用的显卡使用的,但最近不仅用于图像处理, 也用于通用的数值计算。由于 GPU 可以高速地进行并行数值计算,因此 GPU 计算的目标就是将这种压倒性的计算能力用于各种用途
分布式学习
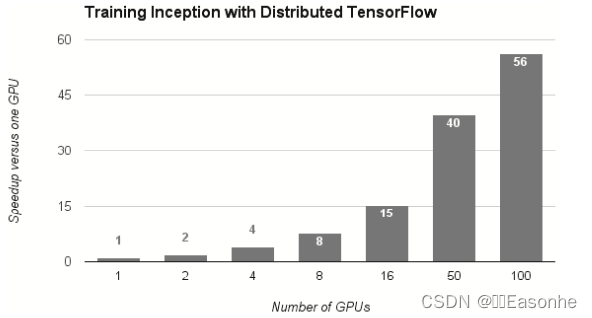
为了进一步提高深度学习所需的计算的速度,可以考虑在多个 GPU 或者多台机器上进行分布式计算。现在的深度学习框架中,出现了好几个支持 多 GPU 或者多机器的分布式学习的框架。其中,Google 的 TensorFlow、微 软的CNTK(Computational Network Toolki)在开发过程中高度重视分布式 学习。以大型数据中心的低延迟·高吞吐网络作为支撑,基于这些框架的分 布式学习呈现出惊人的效果。
基于TensorFlow的分布式学习的效果:横轴是GPU的个数,纵轴是与单个 GPU 相比时的高速化率
关于分布式学习,“如何进行分布式计算”是一个非常难的课题。它包 含了机器间的通信、数据的同步等多个无法轻易解决的问题。可以将这些难 题都交给 TensorFlow 等优秀的框架
运算精度的位数缩减
在深度学习的高速化中,除了计算量之外,内存容量、总线带宽等也有 可能成为瓶颈。关于内存容量,需要考虑将大量的权重参数或中间数据放在 内存中。关于总线带宽,当流经 GPU(或者 CPU)总线的数据超过某个限制时, 就会成为瓶颈。考虑到这些情况,我们希望尽可能减少流经网络的数据的位数。计算机中表示小数时,有 32 位的单精度浮点数和 64 位的双精度浮点数 等格式。根据以往的实验结果,在深度学习中,即便是 16 位的半精度浮点 数(half float),也可以顺利地进行学习,由此可以认为今后半精度浮点数将被作为标准使用。特别是在面向 嵌入式应用程序中使用深度学习时,位数缩减非常重要。
深度学习的应用案例
深度学习在图像、语音、自然语言等各个不同 的领域,深度学习都展现了优异的性能。以计算机视觉这个领域为中 心,介绍几个深度学习能做的事情(应用)
物体检测
物体检测是从图像中确定物体的位置,并进行分类的问题
物体检测是比物体识别更难的问题。之前介绍的物体 识别是以整个图像为对象的,但是物体检测需要从图像中确定类别的位置, 而且还有可能存在多个物体。

在使用 CNN 进行物体检测的方法中,有一个叫作 R-CNN 的有名的方法
图像分割
图像分割是指在像素水平上对图像进行分类
使用以像 素为单位对各个对象分别着色的监督数据进行学习。然后,在推理时,对输 入图像的所有像素进行分类。

要基于神经网络进行图像分割,最简单的方法是以所有像素为对象,对每个像素执行推理处理
有人提出了一个名为FCN(Fully Convolutional Network)[37] 的方法。该方法通过一次 forward 处理,对所有像素进行分类。
FCN 的字面意思是“全部由卷积层构成的网络”。相对于一般的 CNN 包 含全连接层,FCN 将全连接层替换成发挥相同作用的卷积层。
图像标题的生成
一个基于深度学习生成图像标题的代表性方法是被称为 NIC(Neural Image Caption)的模型,NIC由深层的CNN和处理自然语 言的RNN(Recurrent Neural Network)构成。RNN是呈递归式连接的网络, 经常被用于自然语言、时间序列数据等连续性的数据上。我们将组合图像和自然语言等多种信息进行的处理称为多模态处理
深度学习的未来
介绍几个揭示了深度学习的可能性和未来的研究
图像风格变换
如果指定将梵高的绘画风格应用于内容图像,深度学习 就会按照指示绘制出新的画作

图像的生成
DCGAN 中使用了深度学习,其技术要点是使用了 Generator(生成者) 和 Discriminator(识别者)这两个神经网络。Generator 生成近似真品的图 像,Discriminator 判别它是不是真图像(是 Generator 生成的图像还是实际 拍摄的图像)。像这样,通过让两者以竞争的方式学习,Generator 会学习到 更加精妙的图像作假技术,Discriminator 则会成长为能以更高精度辨别真假 的鉴定师。两者互相切磋、共同成长,这是GAN(Generative Adversarial Network)这个技术的有趣之处。在这样的切磋中成长起来的 Generator 最终
会掌握画出足以以假乱真的图像的能力(或者说有这样的可能)。
没有给出监督数据的问题称为无监督学习
前面我们学习的神经网络都有对应的监督数据称为监督学习
自动驾驶
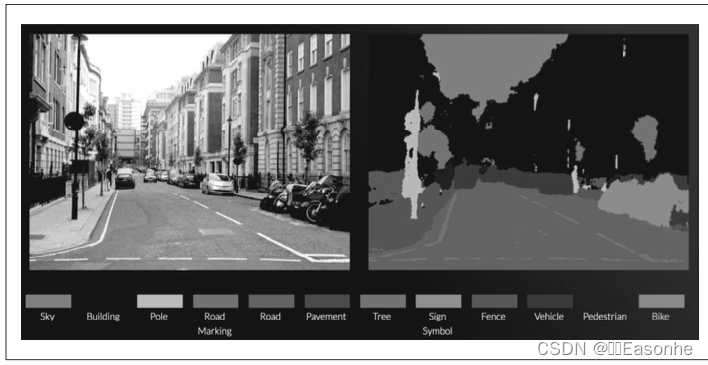
在识别周围环境的技术中,深度学习的力量备受期待。比如,基于 CNN 的神经网络 SegNet,可以像图 8-25 那样高精度 地识别行驶环境。
基于深度学习的图像分割的例子:道路、车辆、建筑物、人行道等被高精度地识 别了出来
Deep Q-Network(强化学习)
就像人类通过摸索试验来学习一样(比如骑自行车),让计算机也在摸索 试验的过程中自主学习,这称为强化学习(reinforcement learning)。强化学 习和有“教师”在身边教的“监督学习”有所不同。 强化学习的基本框架是,代理(Agent)根据环境选择行动,然后通过这 个行动改变环境。根据环境的变化,代理获得某种报酬。强化学习的目的是 决定代理的行动方针,以获得更好的报酬。报酬并不是 确定的,只是“预期报酬”。比如,在《超级马里奥兄弟》这款电子游戏中, 让马里奥向右移动能获得多少报酬不一定是明确的。这时需要从游戏得分(获 得的硬币、消灭的敌人等)或者游戏结束等明确的指标来反向计算,决定“预 期报酬”。如果是监督学习的话,每个行动都可以从“教师”那里获得正确的评价。
在 Q 学习中,为了确定最合适的行动,需要确定一个被称为最优行动价值函数的函数。为了近似这个函数,DQN 使用了深度学习 (CNN)。
小结
深度学习领域还有很多尚未揭晓的东西,新的研究正一个接一个地出现。 今后,全世界的研究者和技术专家也将继续积极从事这方面的研究,一定能 实现目前无法想象的技术。
- 对于大多数的问题,都可以期待通过加深网络来提高性能。
- 在最近的图像识别大赛ILSVRC中,基于深度学习的方法独占鳌头,使用的网络也在深化。
- VGG、GoogLeNet、ResNet等是几个著名的网络。
- 基于GPU、分布式学习、位数精度的缩减,可以实现深度学习的高速化。
- 深度学习(神经网络)不仅可以用于物体识别,还可以用于物体检测、图像分割。
- 深度学习的应用包括图像标题的生成、图像的生成、强化学习等。最近,深度学习在自动驾驶上的应用也备受期待。
end
内容来自《深度学习入门:基于Python的理论与实现》