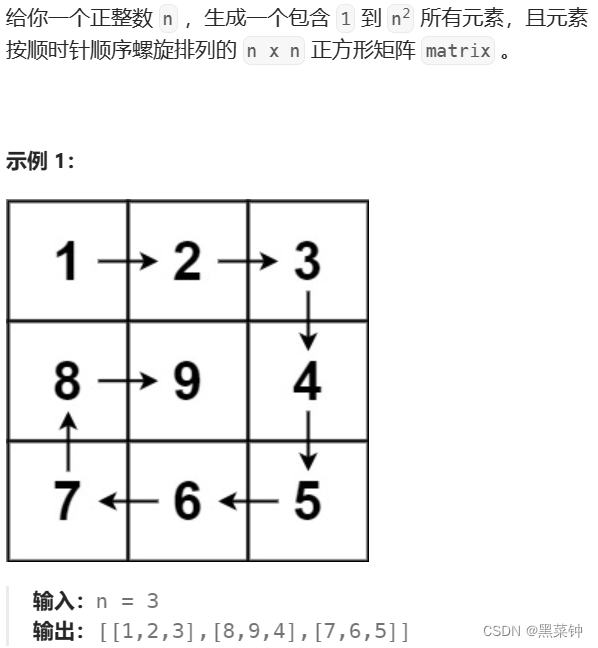
一、线性代数
- 向量的
L
2
L_2
L2范数(Euclidean范数/Frobenius范数)&矩阵的元素形式范数
- 向量的 L 2 L_2 L2范数: ∣ ∣ x ∣ ∣ 2 = ( ∣ x 1 ∣ 2 + ⋯ + ∣ x m ∣ 2 ) 1 2 ||x||_2=(|x_1|^2+\cdots+|x_m|^2)^{\frac12} ∣∣x∣∣2=(∣x1∣2+⋯+∣xm∣2)21
- 矩阵的元素形式范数:将
m
×
n
m\times n
m×n矩阵按照列堆栈的形式排列成
m
n
×
1
mn \times 1
mn×1的向量,然后采用向量范数的定义,即可得到矩阵的范数:
∣
∣
x
∣
∣
p
=
(
∑
i
=
1
m
∑
j
=
1
n
∣
a
i
j
∣
p
)
1
p
||x||_p=\left(\sum_{i=1}^m\sum_{j=1}^n|a_{ij}|^p\right)^{\frac1p}
∣∣x∣∣p=(∑i=1m∑j=1n∣aij∣p)p1
- 其中Frobenius范数(p=2)为: ∣ ∣ A ∣ ∣ F = ( ∑ i = 1 m ∑ j = 1 n ∣ a i j ∣ 2 ) 1 2 ||A||_F=\left(\sum_{i=1}^m\sum_{j=1}^n|a_{ij}|^2\right)^{\frac12} ∣∣A∣∣F=(∑i=1m∑j=1n∣aij∣2)21,也可以写成迹函数的形式: ∣ ∣ A ∣ ∣ F = < A , A > 1 2 = t r ( A H A ) ||A||_F=<A,A>^{\frac12}=\sqrt{tr(A^HA)} ∣∣A∣∣F=<A,A>21=tr(AHA)。也可称为Euclidean范数、Schur范数、Hilbert-Schmidt范数或者L2范数。
- 两个矩阵按元素的乘法称为“哈达玛积”(Hadamard product)数学符号为
⊙
\odot
⊙。在Pytorch中,两个形状相同的张量按元素相乘表示为:
A*B - 两个向量的点积表示为:
torch.dot(x, y),结果为tensor类型 - 矩阵向量积
A
x
Ax
Ax表示为:
torch.mv(A, x),mv=matrix vector multiplication - 矩阵和矩阵的乘积表示为:
torch.mm(A, B) - 向量的
L
1
L_1
L1范数(元素的绝对值之和)表示为:
torch.abs(x).sum() - 向量的
L
2
L_2
L2范数表示为:
torch.norm(x),结果为tensor类型。注意❗需要将tensor的元素类型转换为float类型,x=x.float() - 矩阵的
F
F
F范数(弗罗贝尼乌斯范数)表示为:
torch.norm(A)
二、矩阵运算(矩阵求导)
- 当y是标量,x是列向量时, ∂ y ∂ x \frac{\partial y}{\partial \boldsymbol{x}} ∂x∂y是行向量, ∂ y ∂ x = [ ∂ y ∂ x 1 , ∂ y ∂ x 2 , . . . , ∂ y ∂ x n ] \frac{\partial y}{\partial \boldsymbol{x}}=\left[ \frac{\partial y}{\partial x_1},\frac{\partial y}{\partial x_2},...,\frac{\partial y}{\partial x_n} \right] ∂x∂y=[∂x1∂y,∂x2∂y,...,∂xn∂y] 。梯度和等高线正交,指向该点处。值变换最大的方向。
- 当y是列向量,x是标量时, ∂ y ∂ x \frac{\partial \boldsymbol{y}}{\partial x} ∂x∂y是列向量, ∂ y ∂ x = [ ∂ y 1 ∂ x ∂ y 2 ∂ x ⋮ ∂ y m ∂ x ] \frac{\partial\mathbf{y}}{\partial x}=\begin{bmatrix}\frac{\partial y_1}{\partial x}\\\frac{\partial y_2}{\partial x}\\\vdots\\\frac{\partial y_m}{\partial x}\end{bmatrix} ∂x∂y= ∂x∂y1∂x∂y2⋮∂x∂ym 。
- 当y是列向量,x是列向量时,
∂
y
∂
x
\frac{\partial \boldsymbol{y}}{\partial \boldsymbol{x}}
∂x∂y是矩阵,
∂
y
∂
x
=
[
∂
y
1
∂
x
∂
y
2
∂
x
⋮
∂
y
m
∂
x
]
=
[
∂
y
1
∂
x
1
,
∂
y
1
∂
x
2
,
…
,
∂
y
1
∂
x
n
∂
y
2
∂
x
1
,
∂
y
2
∂
x
2
,
…
,
∂
y
2
∂
x
n
⋮
∂
y
m
∂
x
1
,
∂
y
m
∂
x
2
,
…
,
∂
y
m
∂
x
n
]
\frac{\partial\mathbf{y}}{\partial\mathbf{x}}=\begin{bmatrix}\frac{\partial\mathbf{y}_1}{\partial\mathbf{x}}\\\frac{\partial\mathbf{y}_2}{\partial\mathbf{x}}\\\vdots\\\frac{\partial\mathbf{y}_m}{\partial\mathbf{x}}\end{bmatrix}=\begin{bmatrix}\frac{\partial\mathbf{y}_1}{\partial x_1},\frac{\partial\mathbf{y}_1}{\partial x_2},\ldots,\frac{\partial\mathbf{y}_1}{\partial x_n}\\\frac{\partial\mathbf{y}_2}{\partial x_1},\frac{\partial\mathbf{y}_2}{\partial x_2},\ldots,\frac{\partial\mathbf{y}_2}{\partial x_n}\\\vdots\\\frac{\partial\mathbf{y}_m}{\partial x_1},\frac{\partial\mathbf{y}_m}{\partial x_2},\ldots,\frac{\partial\mathbf{y}_m}{\partial x_n}\end{bmatrix}
∂x∂y=
∂x∂y1∂x∂y2⋮∂x∂ym
=
∂x1∂y1,∂x2∂y1,…,∂xn∂y1∂x1∂y2,∂x2∂y2,…,∂xn∂y2⋮∂x1∂ym,∂x2∂ym,…,∂xn∂ym
。
- ∂ ( A x ) ∂ x = A \frac{\partial \left( A\boldsymbol{x} \right)}{\partial \boldsymbol{x}}=A ∂x∂(Ax)=A
-
∂
(
x
T
A
)
∂
x
=
A
T
\frac{\partial \left( \boldsymbol{x}^TA \right)}{\partial \boldsymbol{x}}=A^T
∂x∂(xTA)=AT→
∂
<
x
,
w
>
∂
w
=
x
T
\frac{\partial \left< \boldsymbol{x,w} \right>}{\partial \boldsymbol{w}}=\boldsymbol{x}^T
∂w∂⟨x,w⟩=xT,注意分子求内积运算,x和w都是列向量,求内积时表示为
x
T
w
\boldsymbol{x}^T \boldsymbol{w}
xTw。

三、自动求导
标量的链式法则同样可以扩展到向量,注意形状。
链式求导简单举例:

Ⅰ自动求导
(1)相关概念
自动求导指计算一个函数在指定值上的导数。有别于符号求导和数值求导。
-
符号求导(Symbolic Differentiation): 符号求导是基于数学规则(如链式法则、幂规则、导数的乘积规则等)进行的求导过程,它能产生导数的精确解析表达式。例如,使用符号计算软件如 MATLAB 的 Symbolic Math Toolbox 或 Mathematica,用户可以输入一个数学函数并得到它的精确导数公式。这种方法的优点是可以提供清晰的数学表达式,有助于深入理解函数行为和优化算法的设计,但它对函数形式有一定要求,不适合处理复杂的非结构化或动态变化的函数。
-
数值求导(Numerical Differentiation): 数值求导是一种近似求导的方法,它不寻找导数的封闭形式表达式,而是通过对函数在相邻点的值进行差分来估计导数。例如,使用有限差分方法(如前向差分、后向差分或中心差分)来计算某一点处的导数值。这种方法适用性广泛,能够处理任意可计算的函数,但求得的是导数的近似值,且误差与步长的选择有关,过大的步长可能导致较大的误差,过小的步长则可能受到浮点计算精度的影响。
给任何f(x),不需要知道形式,可以通过数值去拟合导数: ∂ f ( x ) ∂ x = lim h → 0 f ( x + h ) − f ( x ) h \frac{\partial f(x)}{\partial x}=\lim_{h\to0}\frac{f(x+h)-f(x)}{h} ∂x∂f(x)=limh→0hf(x+h)−f(x)
-
自动求导(Automatic Differentiation,AD): 自动求导是一种结合了符号和数值求导特点的技术,它基于链式法则和逆向传播的思想,追踪并累加每个计算步骤的微小导数贡献。在现代机器学习和深度学习框架(如 TensorFlow、PyTorch、Theano 等)中广泛应用。自动求导分为前向模式(Forward Mode)和反向模式(Reverse Mode,又称 Backpropagation),其中反向模式尤为适合大型神经网络中梯度的高效计算。自动求导既能给出精确的导数值,又能处理复杂的、非结构化的函数甚至是包含循环和条件语句的程序,而且相比于纯符号求导,它更适合于动态生成的计算图或大规模优化问题。
(2)计算图
等价于用链式法则的计算过程。计算图(Computation Graph)是一种用于表示数学运算和变量之间依赖关系的数据结构,将计算表示成了一个无环图,特别在机器学习和深度学习领域应用广泛。它通过节点(nodes)和边(edges)构建,其中节点代表数学运算或者变量值,边则代表这些运算或变量之间的数据流动路径,以及它们相互间的依赖关系。
-
在计算图中:
- 节点(Operations / Functions):每个节点执行特定的数学运算,比如加法、乘法、激活函数(如sigmoid、ReLU)、矩阵运算,或者是更复杂的层操作如卷积层或全连接层等。节点没有具体的数值,直到给定所有输入值时才会进行计算。
- 边(Edges / Tensors):边连接着不同的节点,代表了数据从一个运算传递到另一个运算的过程。边携带的是参与运算的数据,通常表现为多维数组(即张量)。在机器学习中,这些张量通常是权重、偏置、输入特征或是中间层的输出。
- 变量(Variables):计算图中的变量是具有持久状态的节点,它们存储了模型参数或需要在整个训练过程中更新的中间结果。
- 反向传播(Backpropagation):当计算图用于训练神经网络时,反向传播利用自动求导技术来高效地计算整个图中所有参数的梯度,这使得我们可以更新网络权重以最小化损失函数。
-
计算图的构造有两种主要方式:显式构造(Explicit Construction)和隐式构造(Implicit Construction)。
(1)显式构造(Explicit Construction)Tensorflow/Theano/MXNet
在显式构造的计算图中,程序员明确地定义了计算图的结构,也就是预先确定了哪些操作(operations)将被执行以及它们之间的依赖关系。程序员通常需要手动构建图的节点和边,所有的计算都被组织成一个固定结构的图,只有在图构建完成后才能执行计算。
例如,在TensorFlow 1.x版本中,用户需要通过
tf.Session()和tf.Graph()明确地创建计算图,并通过tf.Variable()和tf.Operation()等API来显式地添加节点。执行时,数据通过计算图从输入流向输出,而梯度计算(如反向传播)则沿着相反的方向进行。(2)隐式构造(Implicit Construction)PyTorch/MXNet
在隐式构造(或动态构造)的计算图中,计算图是在运行时动态构建的,这意味着每次执行操作时都会实时创建和更新计算图。程序员无需预先声明完整的计算图结构,而是通过直接操作张量(tensor)来进行计算,框架会在背后自动构建和管理计算图。
例如,在PyTorch中,计算图是在运行时逐行代码构建的,当调用一个操作(如加法、矩阵乘法等)时,相应的计算节点和边会立即加入到计算图中。这种动态特性使得代码更加直观易读,便于调试和实验。
总结起来,显式构造和隐式构造的主要区别在于构建和执行计算图的时机和方式:
- 显式构造要求提前定义完整的计算图结构,执行时按图进行计算;
- 隐式构造则允许在运行时动态构建和更新计算图,代码执行与计算图构建同步进行,灵活性更高。
参考文章:
机器学习入门(10)— 浅显易懂的计算图、链式法则讲解_请画出该函数的计算图,请用方形节点表示-CSDN博客
(先这样简单地了解一下是什么,后续可能实际构造会用到……)
(3)两种求导模式

- 正向累积:执行图,存储中间结果
- 反向累积:从相反方向执行图,可以去除不需要的枝
- 复杂度
- n为操作子个数
- 计算复杂度:正反向代价类似,都为 O ( n ) O(n) O(n)
- 内存复杂度:
- 反向累积: O ( n ) O(n) O(n),因为需要存储正向所有中间结果(深度神经网络求梯度耗GPU资源)
- 正向累积: O ( 1 ) O(1) O(1),不需要存储中间结果
Ⅱ自动求导的实现
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图(computational graph), 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
- 自动计算导数的思想:首先将梯度附加到想要对其计算偏导数的变量上,然后记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
假设相对函数 y = 2 x T x y=2\boldsymbol{x}^T\boldsymbol{x} y=2xTx关于列向量 x \boldsymbol{x} x求导,运算结果应该为 4 x 4\boldsymbol{x} 4x【数学情况下应该是 4 x T 4\boldsymbol{x}^T 4xT,但是由于1维的tensor没有行列之分,所以也等于 4 x 4\boldsymbol{x} 4x】:
import torch
x = torch.arange(4.0) # 创建变量x并对其分配初始值
x.requires_grad_(True) # 等价于 x = torch.arange(4.0, requires_grad = True)
y = 2 * torch.dot(x, x) # 结果为tensor(28., grad_fn=<MulBackward0>)
y.backward() # 启动反向传播过程
print(x.grad) # tensor([ 0., 4., 8., 12.])
-
torch.arange()函数本身生成的是一维张量(tensor),而不是严格意义上的行向量或列向量。这个一维张量可以看作是一个数列,不具备明确的行或列属性。可以通过reshape()方法将其转换为行向量或列向量【二维张量】,或者使用torch.transpose(x1, 0, 1)进行转置。
-
x.requires_grad_(True)用于启用张量x上的梯度计算的功能。当一个张量的requires_grad属性被设置为True时,意味着在其上的任何操作都会被跟踪并记录到计算图中,以便在反向传播过程中计算梯度。 -
grad_fn=<MulBackward0>表明这个张量是由其他张量经过运算(在这个例子中是乘法操作,由MulBackward0指代)产生的,并且参与了反向传播过程,因此它有梯度信息。这意味着如果对该张量求梯度,框架能够追溯到之前的运算步骤以计算梯度。如果前面没有设置启用梯度计算的功能,则不会显示该属性。叶子节点通常为None,只有结果节点的grad_fn才有效,用于指示梯度函数是哪种类型。
-
在PyTorch中,
y.backward()是用于启动反向传播过程的函数调用,以计算张量y相关的所有梯度。当我们处理神经网络或者其他需要梯度计算的任务时,常常会在前向传播阶段结束并计算出损失函数值后,调用此函数。y.backward() == torch.autograd.backward(y) -
多次执行
y.backward()会报如下错误:
在PyTorch中,每次调用
.backward()方法执行反向传播时,默认情况下会释放中间计算结果以节省内存。当你再次调用.backward()时,先前的计算图已经清理掉了,无法再次进行反向传播。因此,如果你需要在同一个计算图上多次执行反向传播,你需要在.backward()调用时添加参数retain_graph=True,这样PyTorch就会保留计算图,直到显式清除它为止。但是频繁地保留计算图可能会占用大量的内存资源,尤其是在复杂的模型中。通常,你应在完成多次反向传播之后手动清空不需要的梯度,以避免内存泄漏:
x.grad.zero_(),得到一个全零张量。如果不调用清除梯度值的函数,当我们调用
y.backward(retain_graph=True)并且多次执行时,x.grad会不断变化的原因在于每次执行反向传播时,新的梯度会累积到现有的梯度之上。由于设置了retain_graph=True,即使在多次调用.backward()后,也不会清除原有的计算图,使得可以不断地在原有基础上累加梯度。例如,假设第一次执行反向传播时,计算出
x对y的梯度为dx1,第二次反向传播时,又计算出梯度为dx2,那么两次之后x.grad将会是dx1 + dx2。 -
backward()的作用一直都是求出某个张量对于某些标量节点的梯度。注意非标量变量反向传播的计算,注意backward()中的参数:Pytorch autograd,backward详解
分离计算
有时,我们希望将某些计算移动到记录的计算图之外。 例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 当我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
这里可以使用u=y.detach()分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。 因此,下面的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理, 而不是z=x*x*x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach() #用于从计算图中分离一个张量,这意味着对 .detach() 后得到的新张量所做的任何操作都不会影响原始计算图中的梯度计算。
# u 是 y 的副本,但它与原来的计算图断开了联系,即 u 的梯度不会回传到 x
z = u * x
z.sum().backward()
x.grad == u # tensor([True, True, True, True])
计算二阶导的参考方法:
在 PyTorch 中,虽然自动求导机制主要用于一阶导数的计算,但通过组合现有的一阶导数和 PyTorch 提供的功能,可以间接计算二阶导数,即 Hessian 矩阵或其他二阶导数相关的信息。
对于一个可微分函数
f(x),如果你有一个张量x并且x.requires_grad=True,你可以先通过.backward()计算一阶导数(梯度)。然后,如果你想计算二阶导数(例如 Hessian 矩阵),通常需要执行以下步骤:
计算一阶导数:
x = torch.randn(size=(n,), requires_grad=True) y = f(x)# 假设 f 是基于 x 的某些操作组成的函数 y.backward()# 计算 y 关于 x 的梯度,存储在 x.grad 中保存一阶导数: 在计算二阶导数之前,你需要保存第一次求导得到的一阶导数,因为接下来的第二次求导会覆盖这些值。
first_derivative = x.grad.clone().detach()计算二阶导数: 对于每个元素的 Hessian 矩阵,可以通过对一阶导数再次求导来获得。但在实际操作中,由于内存限制和计算效率问题,直接计算整个 Hessian 矩阵通常是不可行的,尤其是对于大规模神经网络。因此,常常采用逐元素或者稀疏的方式估算 Hessian-vector 乘积,或者采用近似方法(如有限差分法)。
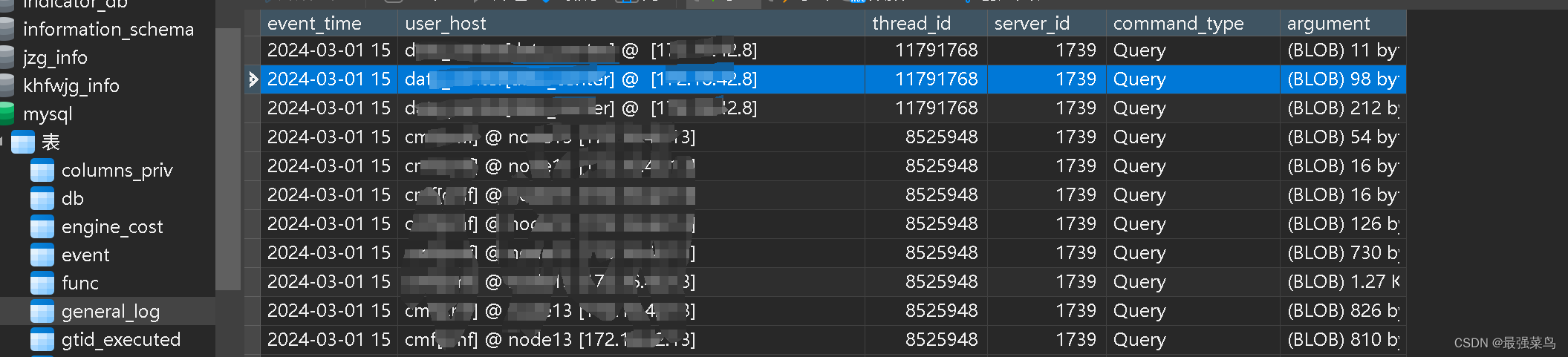
# 创建一个与 x 形状相同的张量作为“方向向量” v = torch.randn_like(x, requires_grad=False) # 将一阶导数当作中间变量,并计算关于它的梯度 # 这里是对一阶导数求导,相当于得到 Hessian-vector 乘积 x.grad.zero_() torch.autograd.grad(outputs=first_derivative, inputs=x, grad_outputs=v, retain_graph=True, create_graph=True)[0].view_as(v)上述代码中的
retain_graph=True参数确保在计算完成后原始计算图不会被释放,以便进行多次反向传播。而create_graph=True则意味着在进行这次反向传播时也记录新的计算图,使得能够对新得到的梯度再求导。如果确实需要计算完整的 Hessian 矩阵,可能需要借助第三方库,或者编写循环结构来分别计算每一项。不过请注意,这样的操作在计算资源和时间开销上往往非常昂贵,特别是在高维度情况下。对于大型模型,研究者更倾向于使用更有效率的二阶优化方法或二阶信息的近似。

👌使f(x)=sin(x),绘制f(x)和df(x)/dx的图像:
import torch
import matplotlib.pyplot as plt
# 创建可微分的张量
x = torch.arange(0., 10., 0.1, requires_grad=True)
y = torch.sin(x)
# 计算 y 的总和,并反向传播得到 dy/dx
y_sum = y.sum()
y_sum.backward()
# 将 PyTorch 张量转换为 NumPy 数组以便 Matplotlib 绘图
x_np = x.detach().numpy()
y_np = y.detach().numpy()
# 不能将具有 requires_grad=True 属性的 PyTorch 张量直接转换为 NumPy 数组。
# 在需要进行反向传播的计算过程中,这样的张量不能直接转换成 NumPy 数组,因为它们包含了梯度信息。
# 解决这个问题的方法是在转换之前使用 .detach() 方法断开张量与计算图的连接,使其不再跟踪梯度。
dy_dx_np = x.grad.numpy()
# 分别绘制正弦函数和它的导数
plt.plot(x_np, y_np, label='y')
plt.plot(x_np, dy_dx_np, label='dy/dx')
# 添加图例和显示图形
plt.legend()
plt.show()