一、引言
随着全球对环境保护意识的增强和技术的进步,新能源汽车作为一种环保、高效的交通工具,正逐渐受到人们的关注和青睐。在这个背景下,对汽车市场的数据进行分析和研究显得尤为重要。
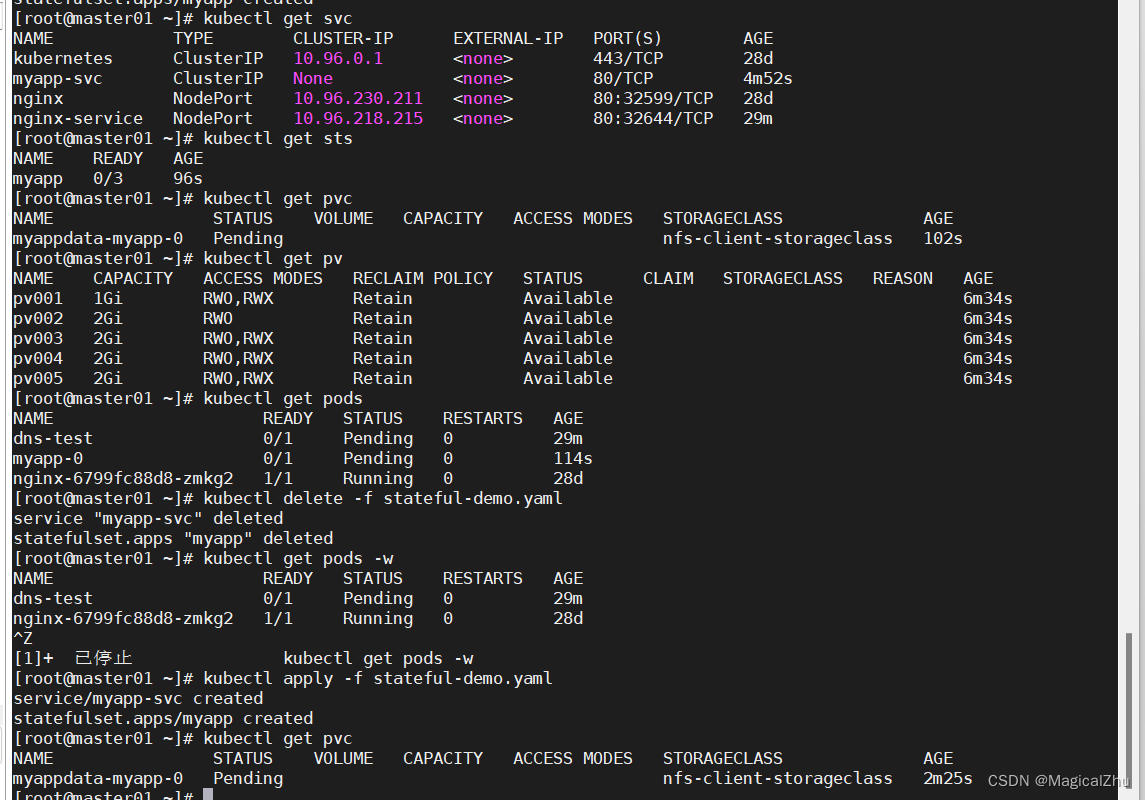
本文将介绍如何利用 Python 编程语言,结合网络爬虫技术,从汽车之家网站抓取数据,并通过数据分析和可视化来探索汽车市场的趋势和特点。我们将详细讨论采集工具的选择、采集流程设计以及代码实现示例,并最终展示结果与分析。
二、采集工具选择
在选择采集工具时,我们需要考虑到网站的结构、数据的格式以及采集的稳定性和效率。针对静态网页的数据采集,常用的工具包括 Python 的 requests 库和 BeautifulSoup 库;而对于动态网页,则需要使用 Selenium 等工具。
三、采集流程设计
- 确定采集目标: 确定需要采集的数据类型和内容,如汽车品牌、型号、价格、评分等。
- 确定采集URL: 分析汽车之家网站的结构,确定需要访问的页面URL。
- 发送HTTP请求: 使用 requests 库向目标URL发送HTTP请求,获取页面内容。
- 解析HTML页面: 使用 BeautifulSoup 库解析HTML页面,提取所需数据。
- CSS选择器或jQuery选择器: 使用 CSS 选择器或 jQuery 选择器定位和提取页面中的具体元素。
- 异常处理和日志记录: 添加异常处理机制,确保程序稳定运行,并记录日志以便后续排查问题。
四、代码实现示例
下面是一个简单的 Python 代码示例,用于从汽车之家网站抓取汽车品牌、价格和评分等数据:
import requests
from bs4 import BeautifulSoup
# 设置代理信息
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"
# 设置代理
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
"user": proxyUser,
"pass": proxyPass,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta,
}
url = 'http://www.autohome.com.cn/xxx' # 替换为汽车之家网站的实际链接
try:
response = requests.get(url, proxies=proxies)
response.raise_for_status() # 检查请求是否成功
soup = BeautifulSoup(response.text, 'html.parser')
# 解析页面,获取所需数据
data_list = []
cars = soup.find_all('div', class_='car-info')
for car in cars:
brand = car.find('h4').text
price = car.find('div', class_='price').text
score = car.find('span', class_='score').text
data_list.append([brand, price, score])
# 将数据保存到CSV文件中
import csv
with open('autohome_data.csv', 'w', encoding='utf-8', newline='') as file:
writer = csv.writer(file)
writer.writerow(['品牌', '价格', '评分'])
writer.writerows(data_list)
print("数据抓取成功并保存到autohome_data.csv文件中!")
except Exception as e:
print("数据抓取失败:", e)
五、评估与优化
- 评估模型性能: 在进行数据分析之前,我们通常需要建立一个模型,以更好地理解数据的关系。在这个阶段,我们需要评估模型的性能,看它是否能够准确地反映出汽车市场的趋势。
- 优化模型性能: 如果模型的性能不尽如人意,我们可能需要进行优化。这包括调整模型的参数、尝试不同的算法,甚至进行特征工程,以提高模型的预测准确性。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 假设 X 是特征,y 是目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')