本笔记来源:开源组织Datawhale24年组队学习
笔记链接:https://datawhaler.feishu.cn/wiki/LxSCw0EyRidru1kFkttc1jNQnnh
直播回看:https://www.bilibili.com/video/BV1wm411f7gf/
For the learner for the dreamer
Sora技术原理解析
Sora具体内容就不在此过多介绍了,用一张直播PPT简单总结下

Sora相关论文
https://datawhaler.feishu.cn/wiki/RKrCw5YY1iNXDHkeYA5cOF4qnkb
上述文章列了Sora技术实现相关的论文,感兴趣的可以点进去慢慢探索,我看了如何将训练数据Patches的
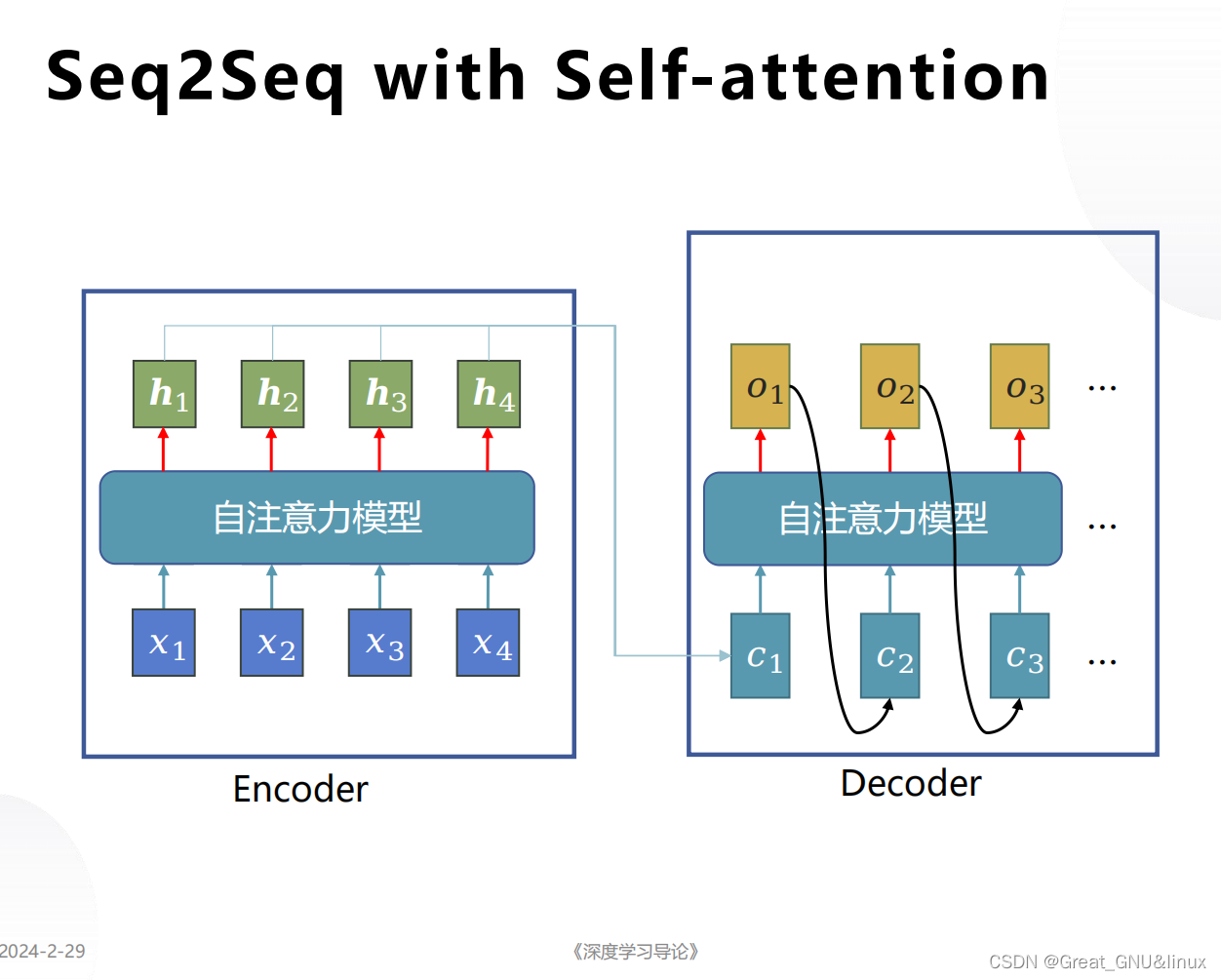
ViT
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,ViT中提到,当使用足够庞大的数据进行预训练的时候,训练效果将得到显著提升
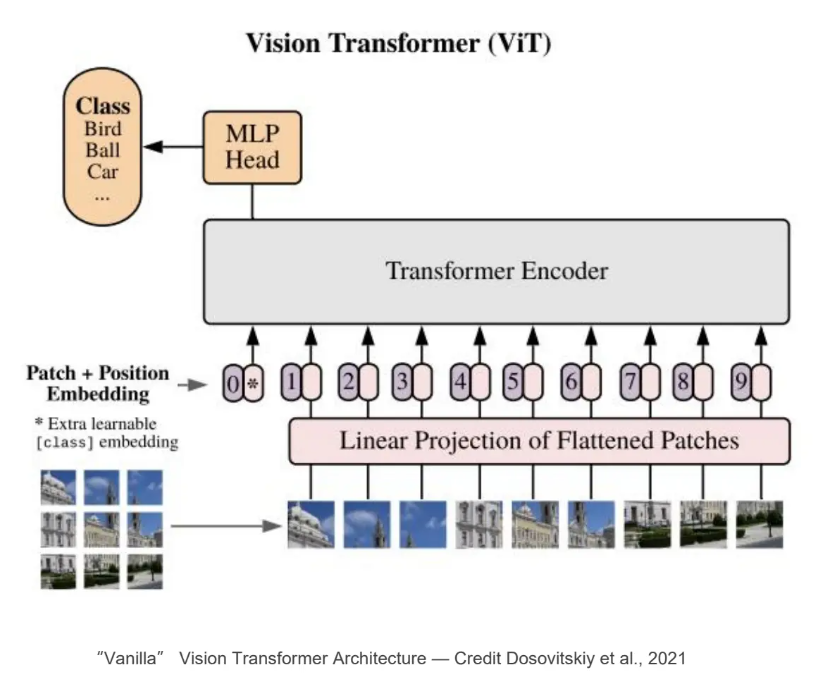
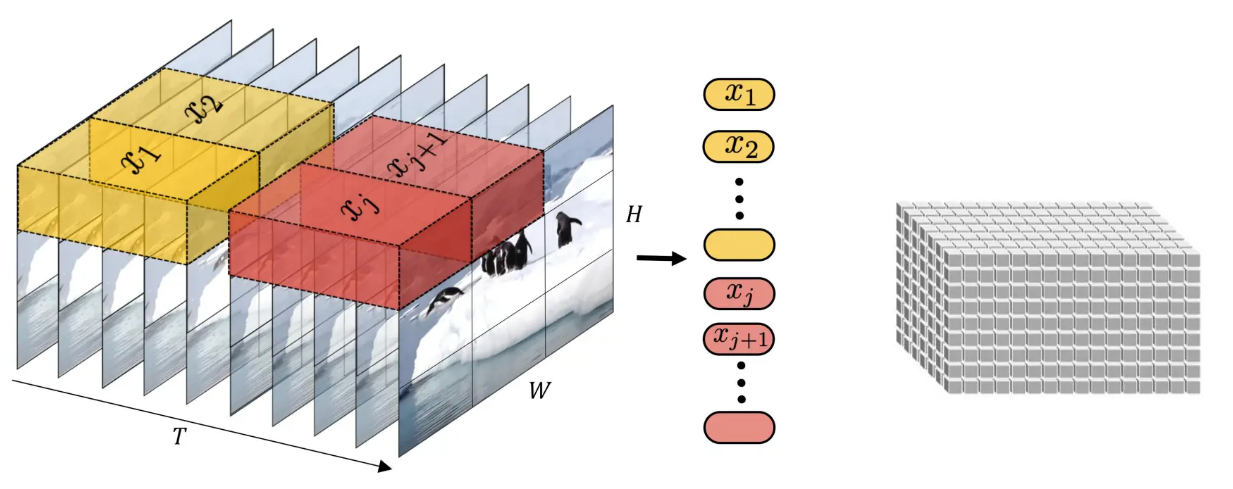
相较于LLM的语料(文本信息)统一化,Sora是将视频的每一帧进行结构的统一化,产生了视觉上的时空的概念。
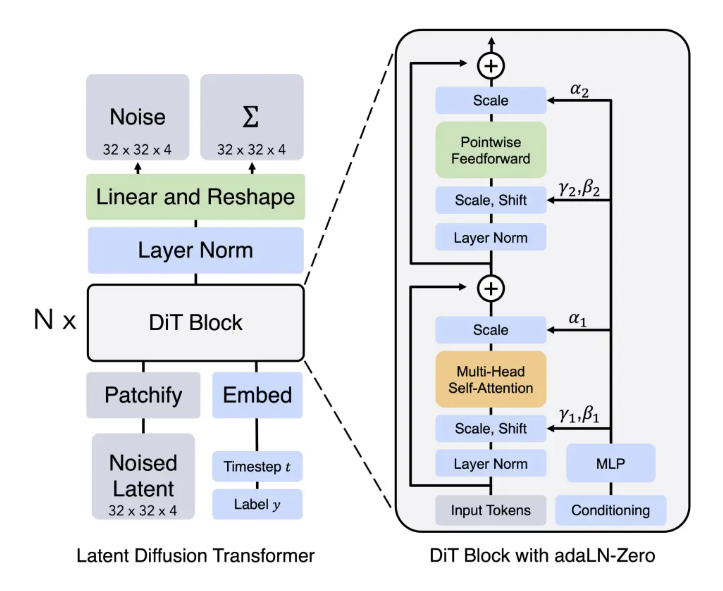
DiT
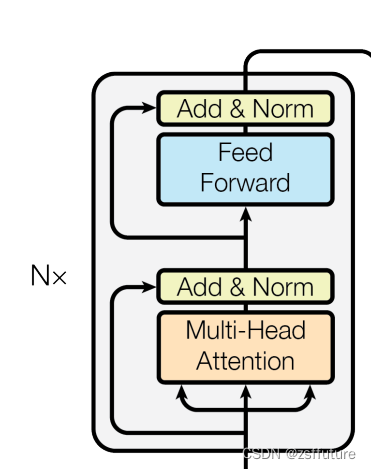
将Transformer架构代替掉扩散模型中的U-net架构的一种扩散模型。