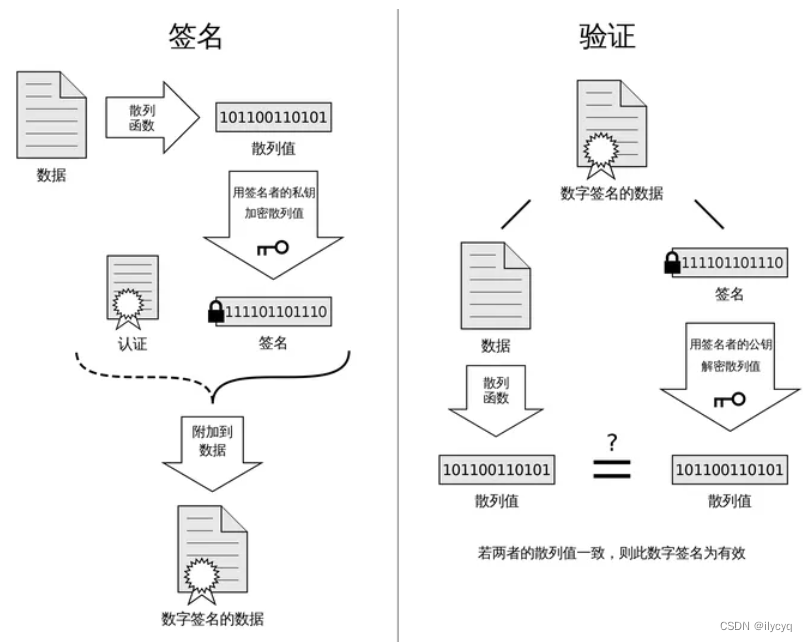
前馈全连接层
什么是前馈全连接层:
在Transformer中前馈全连接层就是具有两层线性层的全连接网络
前馈全连接层的作用:
考虑注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力
code
# 前馈全连接层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff,drop=0.1) -> None:
"""
d_mode :第一个线下层的输入维度
d_ff :隐藏层的维度
drop :
"""
super(PositionwiseFeedForward,self).__init__()
self.line1 = nn.Linear(d_model,d_ff)
self.line2 = nn.Linear(d_ff,d_model)
self.dropout = nn.Dropout(dropout)
def forward(self,x):
return self.line2(self.dropout(F.relu(self.line1(x))))测试:
输出
ff_result.shape = torch.Size([2, 4, 512])
ff_result = tensor([[[-0.0589, -1.3885, -0.8852, ..., -0.4463, -0.9892, 2.7384],
[ 0.2426, -1.1040, -1.1298, ..., -0.9296, -1.5262, 1.0632],
[ 0.0318, -0.8362, -0.9389, ..., -1.6359, -1.8531, -0.1163],
[ 1.1119, -1.2007, -1.5487, ..., -0.8869, 0.1711, 1.7431]],
[[-0.2358, -0.9319, 0.8866, ..., -1.2987, 0.2001, 1.5415],
[-0.1448, -0.7505, -0.3023, ..., -0.2585, -0.8902, 0.6206],
[ 1.8106, -0.8460, 1.6487, ..., -1.1931, 0.0535, 0.8415],
[ 0.2669, -0.3897, 1.1560, ..., 0.1138, -0.2795, 1.8780]]],
grad_fn=<ViewBackward0>)规范化层
规范化层的作用:
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢,因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内.
code
class LayerNorm(nn.Module):
def __init__(self,features,eps=1e-6) -> None:
# features 词嵌入的维度
# eps 足够小的数据,防止除0,放到分母上
super(LayerNorm,self).__init__()
# 规范化层的参数,后续训练使用的
self.w = nn.parameter(torch.ones(features))
self.b = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1,keepdim=True)
stddev = x.std(-1,keepdim=True)
# * 代表对应位置进行相乘,不是点积
return self.w*(x-mean)/(stddev,self.eps) + self.btest
输出:
ln_result.shape = torch.Size([2, 4, 512])
ln_result = tensor([[[ 1.3255e+00, 7.7968e-02, -1.7036e+00, ..., -1.3097e-01,
4.9385e-01, 1.3975e-03],
[-1.0717e-01, -1.8999e-01, -1.0603e+00, ..., 2.9285e-01,
1.0337e+00, 1.0597e+00],
[ 1.0801e+00, -1.5308e+00, -1.6577e+00, ..., -1.0050e-01,
-3.7577e-02, 4.1453e-01],
[ 4.2174e-01, -1.1476e-01, -5.9897e-01, ..., -8.2557e-01,
1.2285e+00, 2.2961e-01]],
[[-1.3024e-01, -6.9125e-01, -8.4373e-01, ..., -4.7106e-01,
2.3697e-01, 2.4667e+00],
[-1.8319e-01, -5.0278e-01, -6.6853e-01, ..., -3.3992e-02,
-4.8510e-02, 2.3002e+00],
[-5.7036e-01, -1.4439e+00, -2.9533e-01, ..., -4.9297e-01,
9.9002e-01, 9.1294e-01],
[ 2.8479e-02, -1.2107e+00, -4.9597e-01, ..., -6.0751e-01,
3.1257e-01, 1.7796e+00]]], grad_fn=<AddBackward0>)子层连接结构
什么是子层连接结构:
如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.


code
# 子层连接结构
class SublayerConnection(nn.Module):
def __init__(self,size,dropout=0.1) -> None:
"""
size : 词嵌入的维度
"""
super(SublayerConnection,self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# sublayer 子层结构或者函数
# x+ 跳跃层
return x+self.dropout(sublayer(self.norm(x)))测试代码 放到最后
输出:
sc_result.sahpe = torch.Size([2, 4, 512])
sc_result = tensor([[[-1.8123e+00, -2.2030e+01, 3.1459e+00, ..., -1.3725e+01,
-6.1578e+00, 2.2611e+01],
[ 4.1956e+00, 1.9670e+01, 0.0000e+00, ..., 2.3616e+01,
3.8118e+00, 6.4224e+01],
[-7.8954e+00, 8.5818e+00, -7.8634e+00, ..., 1.5810e+01,
3.5864e-01, 1.8220e+01],
[-2.5320e+01, -2.8745e+01, -3.6269e+01, ..., -1.8110e+01,
-1.7574e+01, 2.9502e+01]],
[[-9.3402e+00, 1.0549e+01, -9.0477e+00, ..., 1.5789e+01,
2.6289e-01, 1.8317e+01],
[-4.0251e+01, 1.5518e+01, 1.9928e+01, ..., -1.4024e+01,
-3.4640e-02, 1.8811e-01],
[-2.6166e+01, 2.1279e+01, -1.1375e+01, ..., -1.9781e+00,
-6.4913e+00, -3.8984e+01],
[ 2.1043e+01, -3.5800e+01, 6.4603e+01, ..., 2.2372e+01,
3.0018e+01, -3.0919e+01]]], grad_fn=<AddBackward0>)编码器层
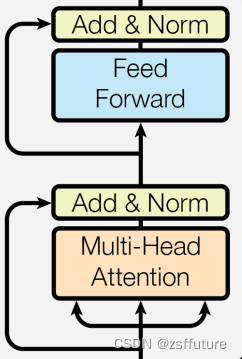
编码器层的作用:
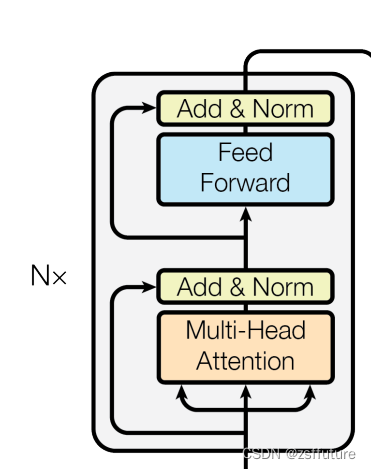
作为编码器的组成单元,每个编码器层完成一次对输入的特征提取过程,即编码过程,如下图
code
# 编码器层
class EncoderLayer(nn.Module):
def __init__(self,size,self_attn, feed_forward,dropout) -> None:
"""
size : 词嵌入维度
self_attn: 多头自注意力子层实例化对象
fee_forward: 前馈全连接层网络
"""
super(EncoderLayer,self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# 编码器中有两个子层结构,所以使用clone实现
self.sublayer = clones(SublayerConnection(size, dropout),2)
self.size = size
def forward(self,x,mask):
x = self.sublayer[0](x, lambda x: self_attn(x,x,x,mask))
return self.sublayer[1](x,self.feed_forward)
测试代码放到最后
输出
el_result.shape = torch.Size([2, 4, 512])
el_result = tensor([[[-1.4834e+01, -4.3176e+00, 1.2379e+01, ..., -1.0715e+01,
-6.8350e-01, -5.2663e+00],
[-1.7895e+01, -5.9179e+01, 1.0283e+01, ..., 9.7986e+00,
2.2730e+01, 1.6832e+01],
[ 5.0309e+00, -6.9362e+00, -2.6385e-01, ..., -1.2178e+01,
3.1495e+01, -1.9781e-02],
[ 1.6883e+00, 3.9012e+01, 3.2095e-01, ..., -6.1469e-01,
3.8988e+01, 2.2591e+01]],
[[ 4.8033e+00, -5.5316e+00, 1.4400e+01, ..., -1.1599e+01,
3.1904e+01, -1.4026e+01],
[ 8.6239e+00, 1.3545e+01, 3.9492e+01, ..., -8.3500e+00,
2.6721e+01, 4.4794e+00],
[-2.0212e+01, 1.6034e+01, -1.9680e+01, ..., -4.7649e+00,
-1.1372e+01, -3.3566e+01],
[ 1.0816e+01, -1.7987e+01, 2.0039e+01, ..., -4.7768e+00,
-1.9426e+01, 2.7683e+01]]], grad_fn=<AddBackward0>)编码器
编码器的作用:
编码器用于对输入进行指定的特征提取过程,也称为编码,由N个编码器层堆叠而成
code
# 编码器
class Encoder(nn.Module):
def __init__(self, layer,N) -> None:
super(Encoder,self).__init__()
self.layers = clones(layer,N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"""forward函数的输入和编码器层相同,x代表上一层的输出,mask代表掩码张量"""
# 首先就是对我们克隆的编码器层进行循环,每次都会得到一个新的x,
# 这个循环的过程,就相当于输出的x经过了N个编码器层的处理,
# 最后再通过规范化层的对象self.norm进行处理,最后返回结果
for layre in self.layers:
x = layre(x,mask)
return self.norm(x)测试代码在下面:
输出:
en_result.shape : torch.Size([2, 4, 512])
en_result : tensor([[[-2.7477e-01, -1.1117e+00, 6.1682e-02, ..., 6.7421e-01,
-6.2473e-02, -4.6477e-02],
[-7.7232e-01, -7.6969e-01, -2.0160e-01, ..., 2.6131e+00,
-1.9882e+00, 1.3715e+00],
[-1.4178e+00, 2.6184e-01, 1.1888e-01, ..., -9.9172e-01,
1.3337e-01, 1.3132e+00],
[-1.3268e+00, -1.1559e+00, -1.1774e+00, ..., -8.1548e-01,
-2.8089e-02, 1.4730e-03]],
[[-1.3472e+00, 4.4969e-01, -4.3498e-02, ..., -9.8910e-01,
7.4551e-02, 1.1824e+00],
[-2.2395e-02, 3.1730e-01, 6.8652e-02, ..., 4.3939e-01,
2.8600e+00, 3.2169e-01],
[-7.2252e-01, -7.6787e-01, -7.5412e-01, ..., 6.3915e-02,
1.2210e+00, -2.3871e+00],
[ 1.6294e-02, -4.8995e-02, -2.2887e-02, ..., -7.7798e-01,
4.4148e+00, 1.7802e-01]]], grad_fn=<AddBackward0>)测试代码
from inputs import Embeddings,PositionalEncoding
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
import math
import copy
def subsequent_mask(size):
"""
生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,
他们最好会形成一个方阵
"""
attn_shape = (1,size,size)
# 使用np.ones方法向这个形状中添加1元素,形成上三角阵
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor,内部做一个1-的操作,
# 在这个其实是做了一个三角阵的反转,subsequent_mask中的每个元素都会被1减
# 如果是0,subsequent_mask中的该位置由0变成1
# 如果是1,subsequent_mask中的该位置由1变成0
return torch.from_numpy(1-subsequent_mask)
def attention(query, key, value, mask=None, dropout=None):
""" 注意力机制的实现,输入分别是query、key、value,mask
此时输入的query、key、value的形状应该是 batch * number_token * embeding
"""
# 获取词嵌入的维度
d_k = query.size(-1)
# 根据注意力公示,将query和key的转置相乘,然后乘上缩放系数得到评分,这里为什么需要转置?
# batch * number_token * embeding X batch * embeding * number_token = batch * number_token * number_token
# 结果是个方阵
scores = torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_k)
# 判断是否使用mask
if mask is not None:
scores = scores.masked_fill(mask==0,-1e9)
# scores 的最后一维进行softmax操作,为什么是最后一维?
# 因为scores是方阵,每行的所有列代表当前token和全体token的相似度值,
# 因此需要在列维度上进行softmax
p_attn = F.softmax(scores,dim=-1) # 这个就是最终的注意力张量
# 之后判断是否使用dropout 进行随机置0
if dropout is not None:
p_attn = dropout(p_attn)
# 最后,根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量
# 计算后的 维度是多少呢?
# batch * number_token * number_token X batch * number_token * embeding =
# batch * number_token * embeding
return torch.matmul(p_attn,value), p_attn
def clones(module, N):
"""用于生成相同网络层的克隆函数,N代表克隆的数量"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, head,embedding_dim,dropout=0.1) -> None:
""" head 代表头的数量, embedding_dim 词嵌入的维度 """
super(MultiHeadedAttention,self).__init__()
# 因为多头是指对embedding的向量进行切分,因此头的数量需要整除embedding
assert embedding_dim % head == 0
# 计算每个头获得分割词向量维度d_k
self.d_k = embedding_dim // head
# 传入头数
self.head = head
# 获得线形层对象,因为线性层是不分割词向量的,同时需要保证线性层输出和词向量维度相同
# 因此线形层权重是方阵
self.linears = clones(nn.Linear(embedding_dim,embedding_dim),4)
# 注意力张量
self.attn = None
# dropout
self.dropout = nn.Dropout(p=dropout)
def forward(self,query,key,value,mask=None):
if mask is not None:
# 拓展维度,因为有多头了
mask = mask.unsqueeze(0)
batch_size = query.size(0)
# 输入先经过线形层,首先使用zip将网络层和输入数据连接一起,
# 模型的输出利用view和transpose进行维度和形状的变换
# (query,key,value) 分别对应一个线形层,经过线形层输出后,立刻对其进行切分,注意这里切分是对query经过线形层输出后进行切分,key经过线性层进行切分,value进行线性层进行切分,在这里才是多头的由来
query,key,value = \
[model(x).view(batch_size, -1, self.head,self.d_k).transpose(1,2) for model,x in zip(self.linears,(query,key,value))]
# 将每个头的输出传入注意力层
x,self.attn = attention(query,key,value,mask,self.dropout)
# 得到每个头的计算结果是4维张量,需要进行形状的转换
x = x.transpose(1,2).contiguous().view(batch_size,-1,self.head*self.d_k)
return self.linears[-1](x)
# 前馈全连接层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff,drop=0.1) -> None:
"""
d_mode :第一个线下层的输入维度
d_ff :隐藏层的维度
drop :
"""
super(PositionwiseFeedForward,self).__init__()
self.line1 = nn.Linear(d_model,d_ff)
self.line2 = nn.Linear(d_ff,d_model)
self.dropout = nn.Dropout(dropout)
def forward(self,x):
return self.line2(self.dropout(F.relu(self.line1(x))))
# 规范化层
class LayerNorm(nn.Module):
def __init__(self,features,eps=1e-6) -> None:
# features 词嵌入的维度
# eps 足够小的数据,防止除0,放到分母上
super(LayerNorm,self).__init__()
# 规范化层的参数,后续训练使用的
self.w = nn.Parameter(torch.ones(features))
self.b = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1,keepdim=True)
stddev = x.std(-1,keepdim=True)
# * 代表对应位置进行相乘,不是点积
return self.w*(x-mean)/(stddev+self.eps) + self.b
# 子层连接结构
class SublayerConnection(nn.Module):
def __init__(self,size,dropout=0.1) -> None:
"""
size : 词嵌入的维度
"""
super(SublayerConnection,self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# sublayer 子层结构或者函数
# x+ 跳跃层
return x+self.dropout(sublayer(self.norm(x)))
# 编码器层
class EncoderLayer(nn.Module):
def __init__(self,size,self_attn, feed_forward,dropout) -> None:
"""
size : 词嵌入维度
self_attn: 多头自注意力子层实例化对象
fee_forward: 前馈全连接层网络
"""
super(EncoderLayer,self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# 编码器中有两个子层结构,所以使用clone实现
self.sublayer = clones(SublayerConnection(size, dropout),2)
self.size = size
def forward(self,x,mask):
x = self.sublayer[0](x, lambda x: self_attn(x,x,x,mask))
return self.sublayer[1](x,self.feed_forward)
# 编码器
class Encoder(nn.Module):
def __init__(self, layer,N) -> None:
super(Encoder,self).__init__()
self.layers = clones(layer,N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"""forward函数的输入和编码器层相同,x代表上一层的输出,mask代表掩码张量"""
# 首先就是对我们克隆的编码器层进行循环,每次都会得到一个新的x,
# 这个循环的过程,就相当于输出的x经过了N个编码器层的处理,
# 最后再通过规范化层的对象self.norm进行处理,最后返回结果
for layre in self.layers:
x = layre(x,mask)
return self.norm(x)
if __name__ == "__main__":
# size = 5
# sm = subsequent_mask(size)
# print("sm: \n",sm.data.numpy())
# plt.figure(figsize=(5,5))
# plt.imshow(subsequent_mask(20)[0])
# plt.waitforbuttonpress()
# 词嵌入
dim = 512
vocab =1000
emb = Embeddings(dim,vocab)
x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
embr =emb(x)
print("embr.shape = ",embr.shape)
# 位置编码
pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0
pe_result = pe(embr)
print("pe_result.shape = ",pe_result.shape)
# 获取注意力值
# query = key = value = pe_result
# attn,p_attn = attention(query,key,value)
# print("attn.shape = ",attn.shape)
# print("p_attn.shape = ",p_attn.shape)
# print("attn: ",attn)
# print("p_attn: ",p_attn)
# # 带mask
# mask = torch.zeros(2,4,4)
# attn,p_attn = attention(query,key,value,mask)
# print("mask attn.shape = ",attn.shape)
# print("mask p_attn.shape = ",p_attn.shape)
# print("mask attn: ",attn)
# print("mask p_attn: ",p_attn)
# 多头注意力测试
head = 8
embedding_dim = 512
dropout = 0.2
query = key = value = pe_result
# mask 是给计算出来的点积矩阵使用的,这个矩阵是方阵,token
mask = torch.zeros(8,4,4)
mha = MultiHeadedAttention(head,embedding_dim,dropout)
mha_result = mha(query,key,value,mask)
print("mha_result.shape = ",mha_result.shape)
print("mha_result: ",mha_result)
# 前馈全连接层 测试
x = mha_result
d_model =512
d_ff=128
dropout = 0.2
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)
print("ff_result.shape = ",ff_result.shape)
print("ff_result = ",ff_result)
# 规范化层测试
features = d_model = 512
esp = 1e-6
ln = LayerNorm(features,esp)
ln_result = ln(ff_result)
print("ln_result.shape = ",ln_result.shape)
print("ln_result = ",ln_result)
# 子层连接结构 测试
size = 512
dropout=0.2
head=8
d_model=512
x = pe_result
mask = torch.zeros(8,4,4)
self_attn = MultiHeadedAttention(head,d_model,dropout)
sublayer = lambda x:self_attn(x,x,x,mask) # 子层函数
sc = SublayerConnection(size,dropout)
sc_result = sc(x,sublayer)
print("sc_result.sahpe = ", sc_result.shape)
print("sc_result = ", sc_result)
# 编码器层 测试
size = 512
dropout=0.2
head=8
d_model=512
d_ff = 64
x = pe_result
mask = torch.zeros(8,4,4)
self_attn = MultiHeadedAttention(head,d_model,dropout)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
mask = torch.zeros(8,4,4)
el = EncoderLayer(size,self_attn,ff,dropout)
el_result = el(x,mask)
print("el_result.shape = ", el_result.shape)
print("el_result = ", el_result)
# 编码器测试
size = 512
dropout=0.2
head=8
d_model=512
d_ff = 64
c = copy.deepcopy
x = pe_result
self_attn = MultiHeadedAttention(head,d_model,dropout)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
# 编码器层不是共享的,因此需要深度拷贝
layer= EncoderLayer(size,c(self_attn),c(ff),dropout)
N=8
mask = torch.zeros(8,4,4)
en = Encoder(layer,N)
en_result = en(x,mask)
print("en_result.shape : ",en_result.shape)
print("en_result : ",en_result)