note
- sora虽然未开源,但这个系列是学习常见text-to-video模型背后的原理
文章目录
- note
- 一、Sora是什么?
- 二、stable diffusion模型
- 1. 模型架构
- 2. Unet模型
- 三、视频生成技术
- 四、Sora相关技术和video caption
- 1. Vit模型
- 2.
- Reference
一、Sora是什么?
Sora是text-to-video模型 (可能是世界模型),OpenAl的研究人员选择这个名字,因为它“唤起了无限创造力潜能”,特点是: 创建最多60秒的视频,高度详细的场景,复杂的多相机视角以及富有情感的多角色。Sora官网链接:https://openai.com/sora
优点:
- 连续多帧的视频。
- 视频融合。
- 同一场景的多角度/多镜头的生成能力。
- 人和其他场景元素在三维空间中一致移动。
- 支持任意分辨率,宽高比的视频输出。
缺点:
- 对物理规律的理解仍然有限。
Sora能力总结:
- Text-to-video: 文生视频
- Image-to-video: 图生视频
- Video-to-video: 改变源视频风格or场景
- Extending video in time: 视频拓展(前后双向),比如通过prompt针对某个视频增加对应的前置视频等
- Create seamless loops. Tiled videos that seem like they never end
- lmage generation: 图片生成(size最高达到 2048x2048)
- Generate video in any format: From 1920 x 1080 to 1080x 1920 视频输出比例自定义
- Simulate virtual worlds:链接虚拟世界,游戏视频场景生成
- Create avideo:长达60s的视频并保持人物、场景一致性
训练过程:
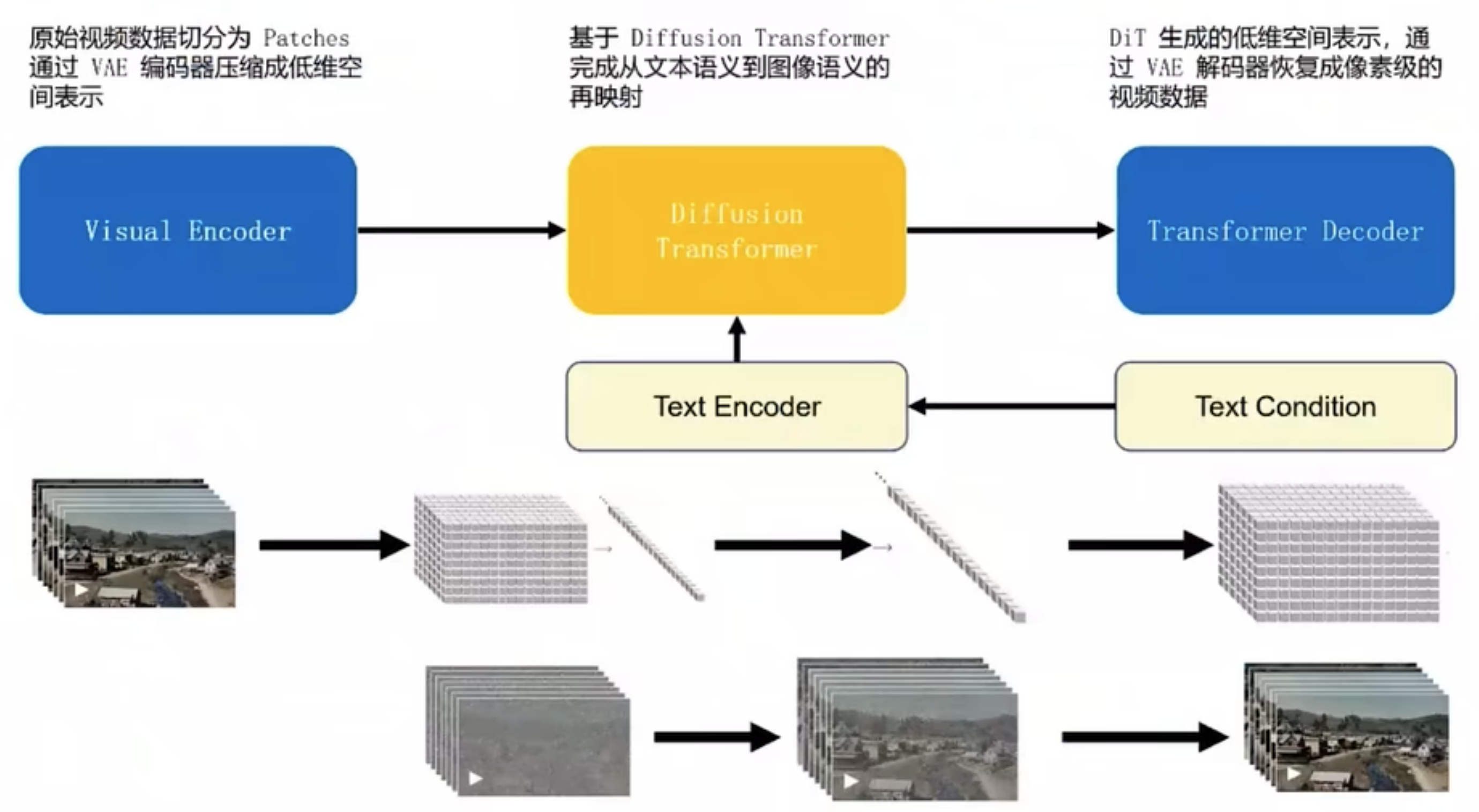
二、stable diffusion模型
1. 模型架构
2. Unet模型
三、视频生成技术
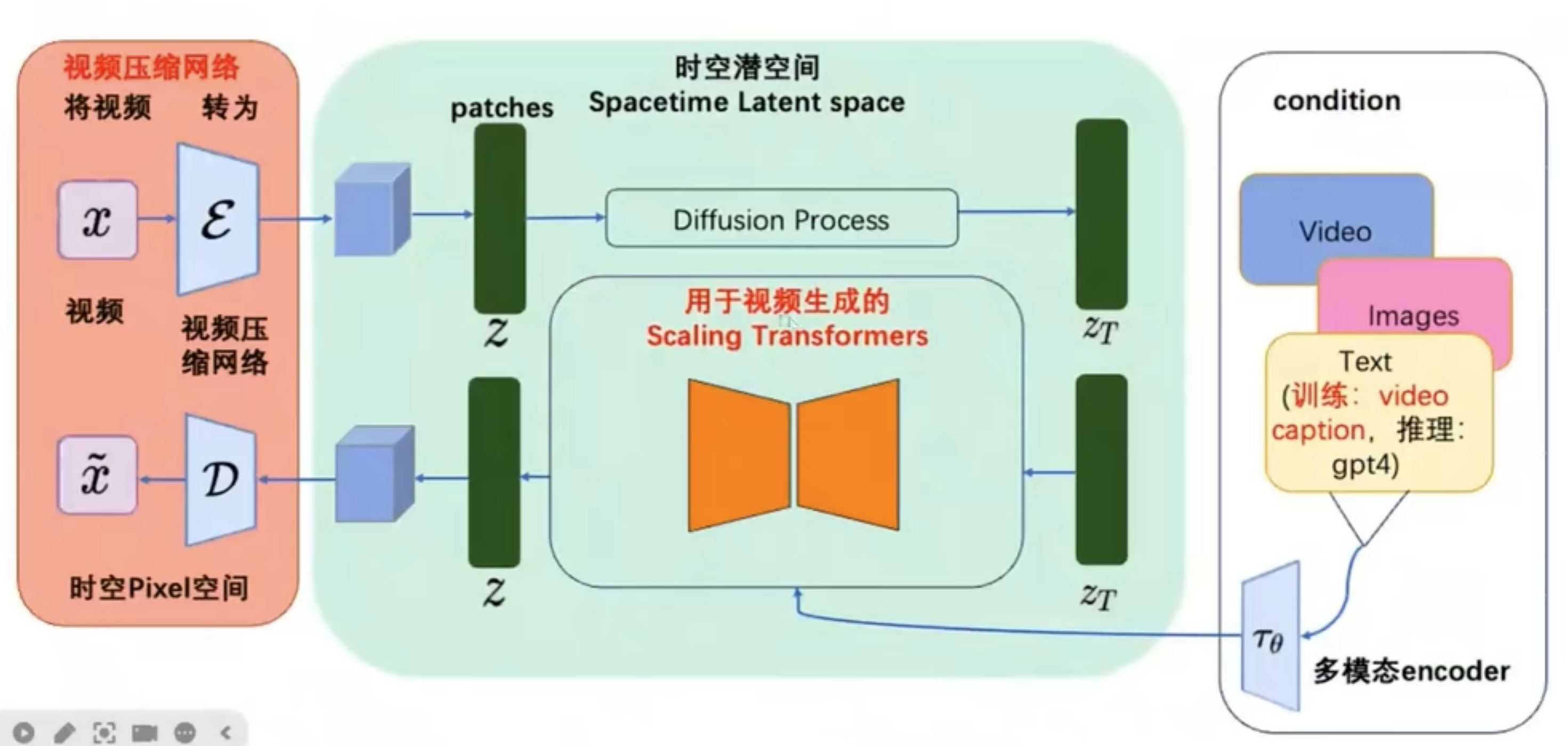
四、Sora相关技术和video caption
1. Vit模型
将视频分解为patch。
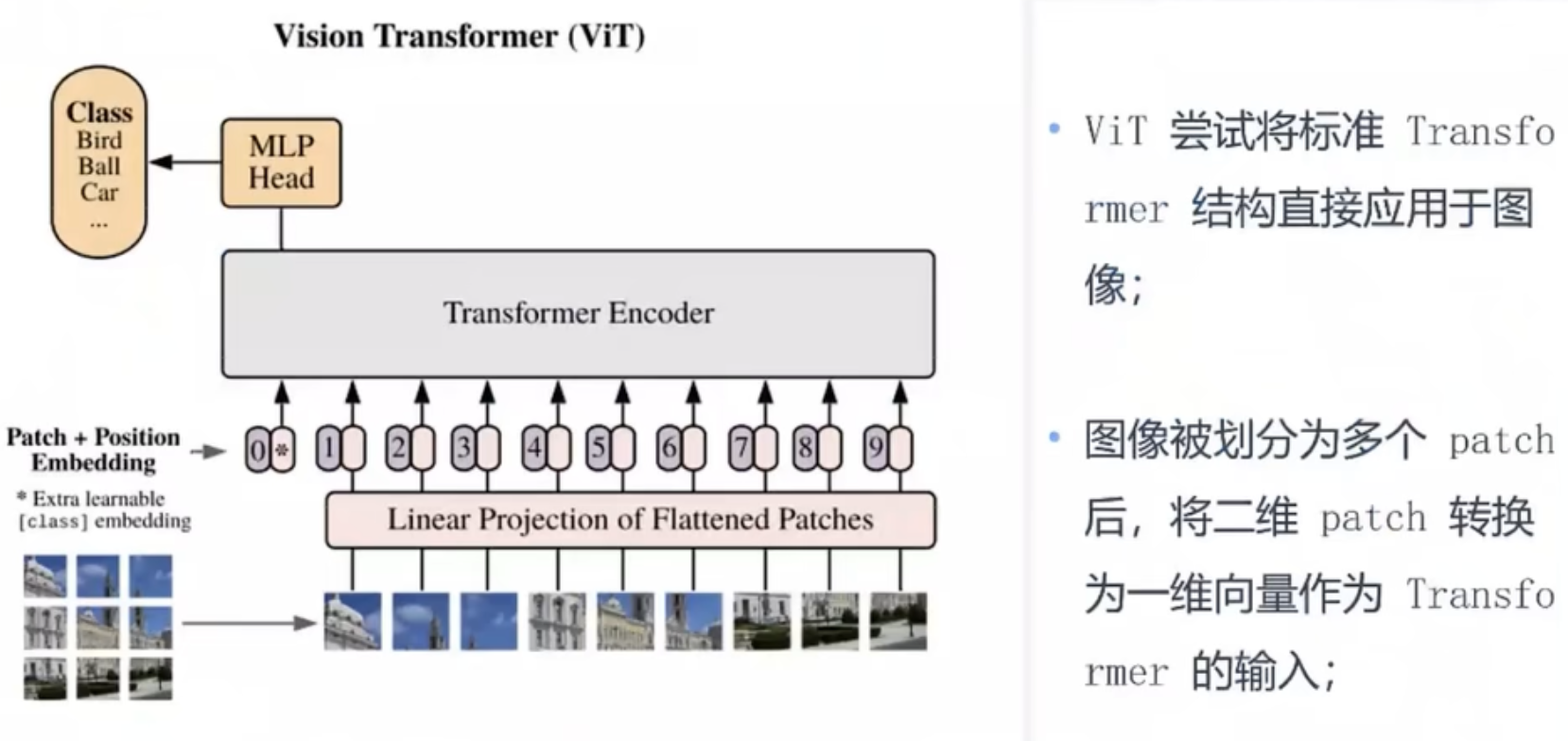
2.
Reference
[1] 【AI+X组队学习】Sora原理与技术实战:Sora技术路径详解
[2] 一文看Sora技术推演.阿里CV算法专家
[3] OpenAI王炸模型引爆科技圈,我们第一时间深读了官方技术报告.腾讯科技
[4] 魔搭社区基于ViT的扩散模型技术的开源教程: https://mp.weixin.qq.com/s/LQGwoU6xZJftmMtsQKde_w
[5] 复刻Sora有多难?一张图带你读懂Sora的技术路径.modelscope成晨
[6] https://datawhaler.feishu.cn/wiki/RKrCw5YY1iNXDHkeYA5cOF4qnkb?fromScene=spaceOverview#GWt8dCJcVodY0Nx6BdNcx2ohnif

![[设计模式Java实现附plantuml源码~行为型] 对象状态及其转换——状态模式](https://img-blog.csdnimg.cn/direct/38f6ea44761e4ea4988da9dbb6b53775.png)