文章目录
- 一. Kappa架构
- 1. Speed Layer (Stream Layer) - The Foundation of Kappa Architecture
- 2. Stream Processing: The Heart of Kappa Architecture
- 二. Benefits of Kappa and Streaming Architecture
- 1. Simplicity and Streamlined Pipeline
- 2. High-Throughput Processing of Historical Data(高吞吐处理历史数据)
- 3. Optimizing Storage with Tiered Approach(通过分层来优化存储)
- 三、Challenges of Implementing Kappa Architecture
- 1. Complexity of Setup and Maintenance
- 2. Cost and Scalability Considerations
- 3. Managing Data Streams for Integrity, Correctness, and Consistency
一. Kappa架构
Kappa 架构代表了处理数据处理架构方式的转变。作为对 Lambda 架构提出的挑战的回应,Kappa 提出了一种更简单、更流畅的方法。Kappa 架构的主要目标是以一种能够及时提供洞察、减少系统复杂性并确保数据一致性的方式处理流数据。它通过专注于一个核心原则实现这一目标:将所有数据作为流。
1. Speed Layer (Stream Layer) - The Foundation of Kappa Architecture
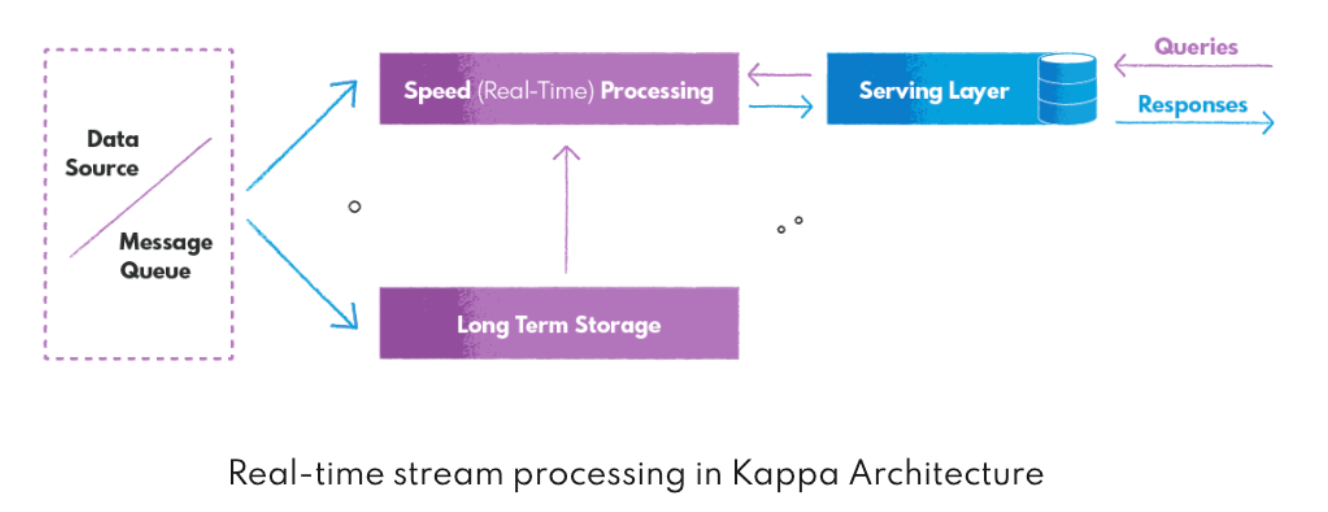
在kappa架构中,LA的速度层是kappa的基础。与将数据处理拆分为两个独立层(批处理和实时处理)不同。kappa关注实时到来的数据,历史数据在kappa中只是数据流中比较老的数据,他和新到来的数据处理方式(实际上,Flink的批处理模式较流模式模型是不同的,效率会比流模式高 参考:execution_mode)是一样的。流层读取到来的数据,处理并将数据发送到下游进行存储或者进一步分析。此层提供了数据处理的低延迟。
2. Stream Processing: The Heart of Kappa Architecture
kappa架构的本质是流处理,kappa进行不断的流查询。这使得实时分析、模式检测、决策、系统监控等变成现实。如下流处理过程:
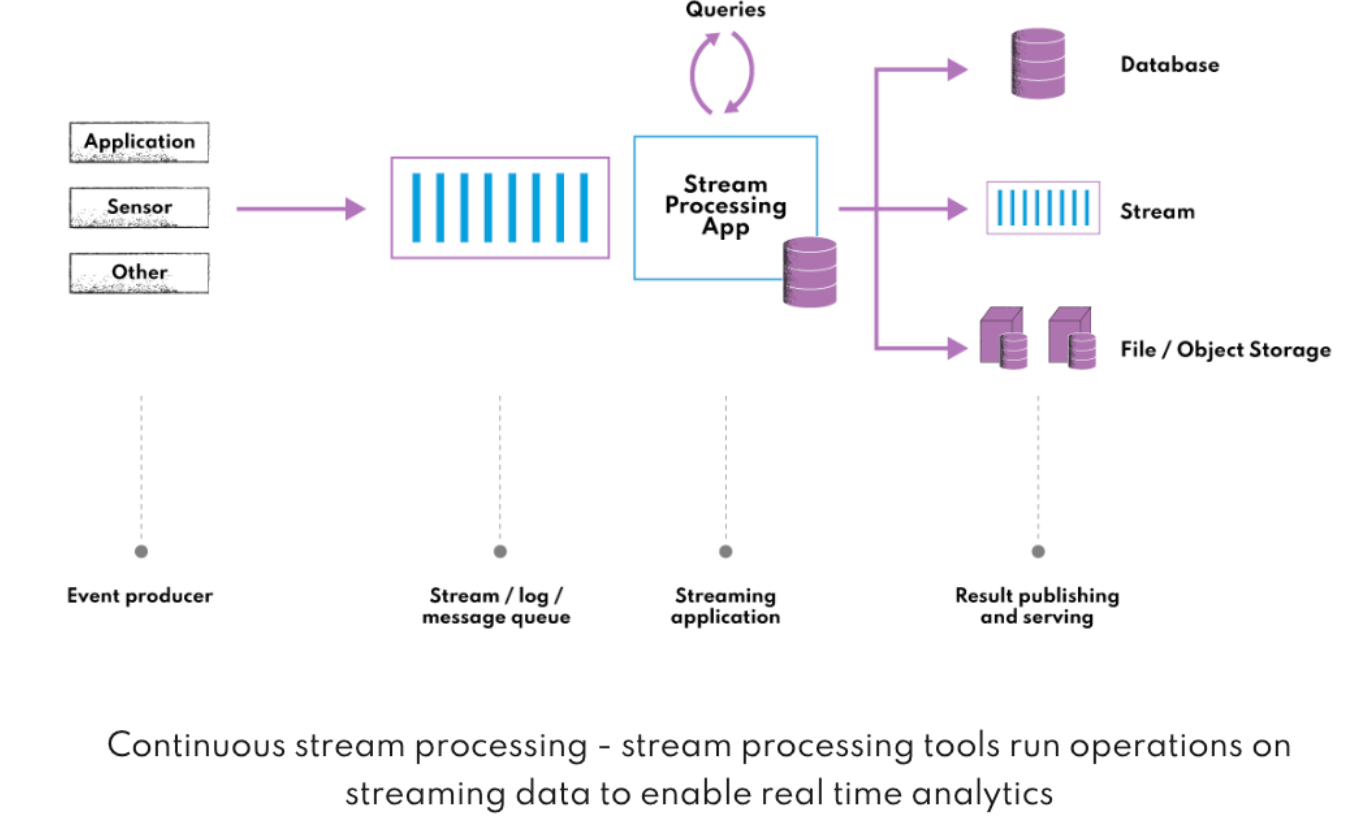
流处理层有两个关键组件:数据摄取部分、数据处理部分。
数据摄取组件
此组件用于捕获和存储raw data从例如日志文件、传感器数据和API。数据的流动是实时的,被存储在例如消息队列、nosql等分布式文件系统中。数据处理组件
用于处理数据,并存储到分布式文件系统中。使用FLink或storm管理大量的数据流,并迅速的给出可靠的查询结果。
在kappa架构中,服务层没有独立出来,而是通过流式系统中的子系统(connector?)将查询结果实时的发送给用户。
kappa架构简化了数据处理管道。通过去除批处理层,kappa简化了系统复杂性,带来了更容易维护和拓展的架构。
二. Benefits of Kappa and Streaming Architecture
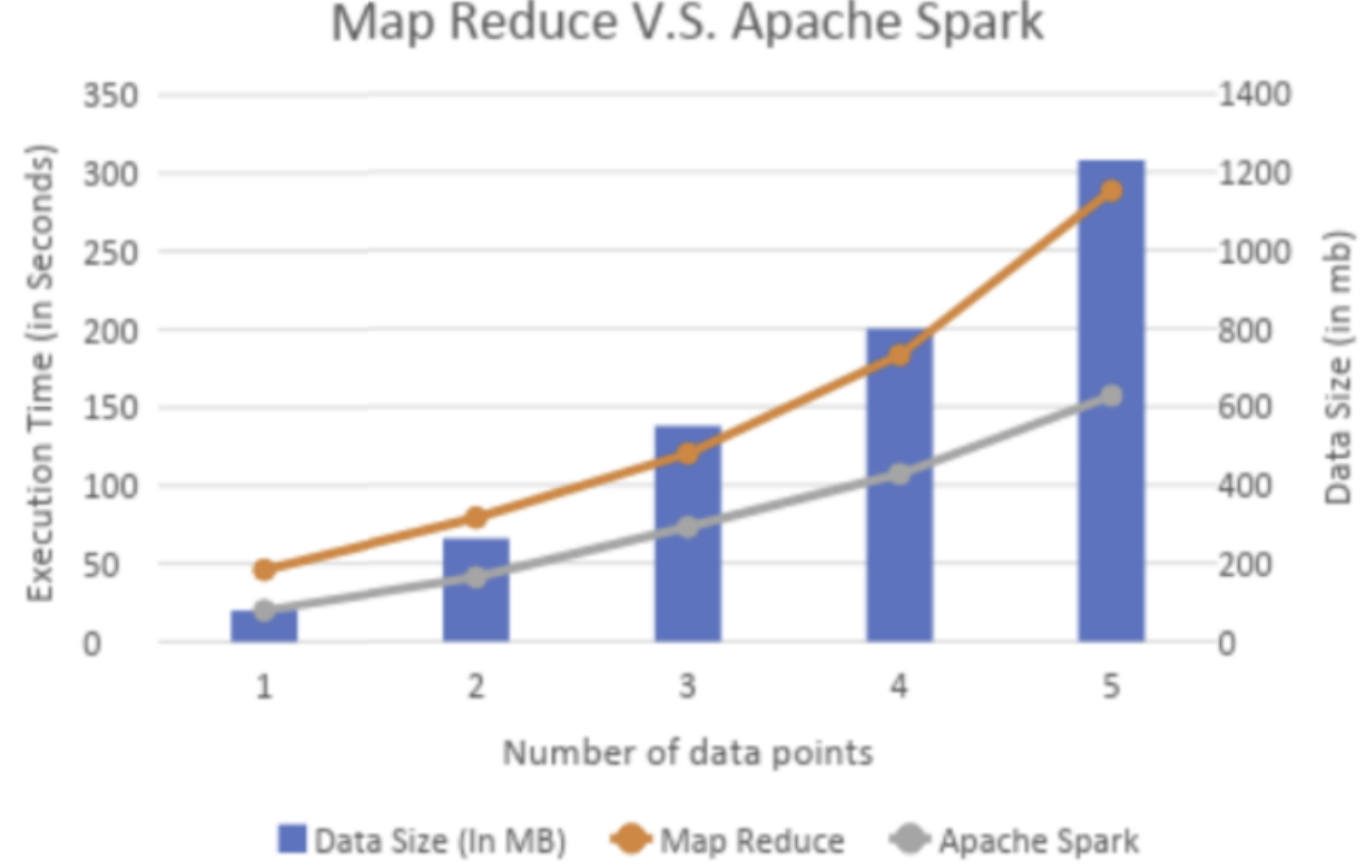
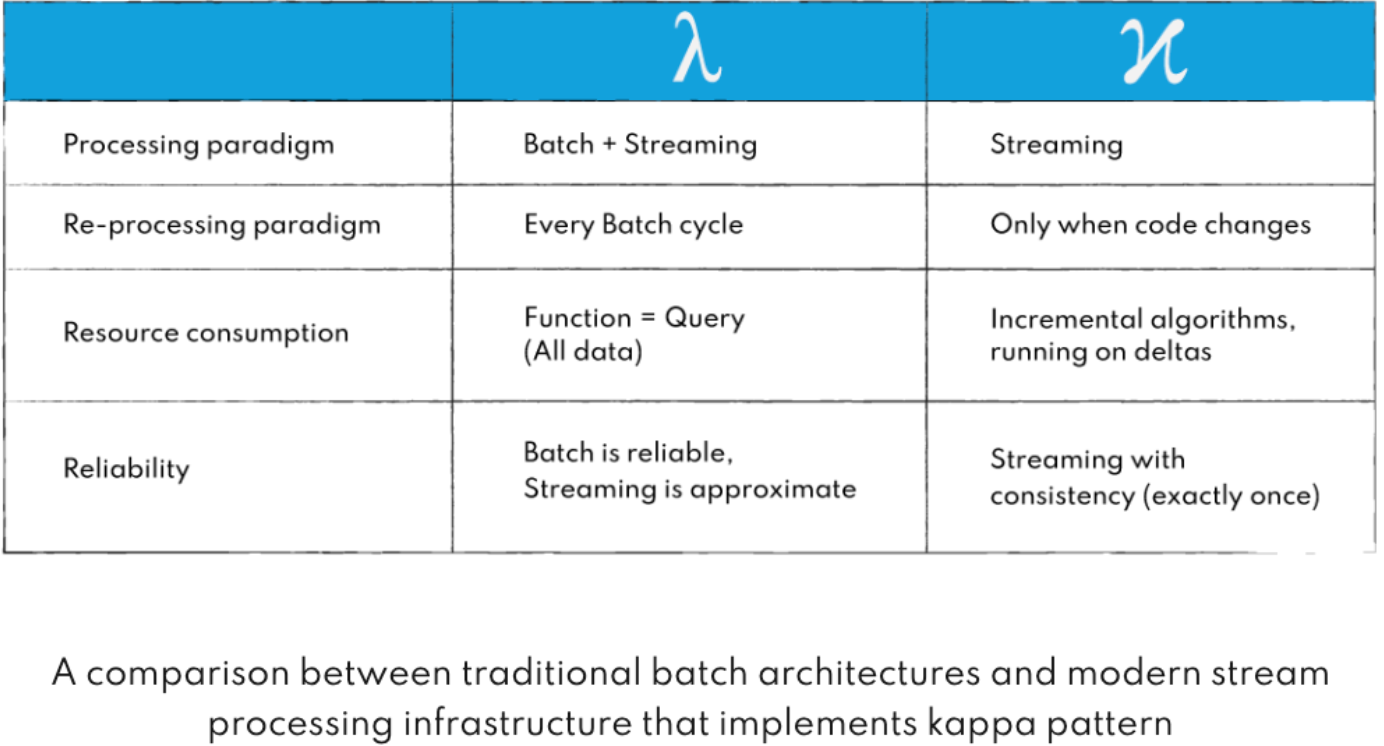
Lamba和kappa架构对比图
1. Simplicity and Streamlined Pipeline
kappa将所有的输入源数据作为流,无论它来自历史或实时数据源。数据处理的统一减少了复杂性和编码开销,使得数据管道更容易管理、优化和分级。
2. High-Throughput Processing of Historical Data(高吞吐处理历史数据)
虽然看起来kappa主要处理实时任务,但对于处理高吞吐的历史数据也非常优雅。你只需要将所有的流数据,作为有界流处理即可处理批任务。
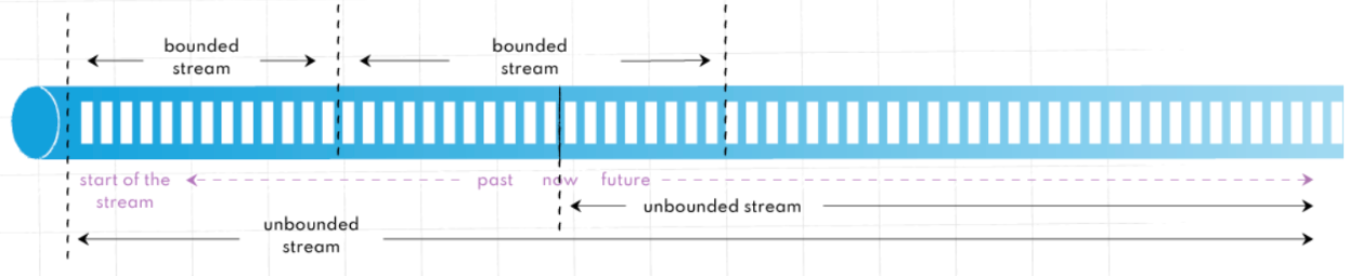
3. Optimizing Storage with Tiered Approach(通过分层来优化存储)
在 Kappa 架构中使用分层存储可以通过采用分层存储来实现成本效益和性能。虽然分层存储不是 Kappa 架构的核心概念,但它可以无缝地融入其框架中。
例如,企业可以将数据存储在成本较低、容错性强的分布式存储层,比如对象存储,同时将实时数据分配到性能更高的层,比如分布式缓存或 NoSQL 数据库。这种对流数据存储的战略性方法使得对数据湖的高效管理成为可能。
三、Challenges of Implementing Kappa Architecture
1. Complexity of Setup and Maintenance
尽管kappa比Lamba简化,但安装和维护kappa架构仍然有一定的复杂性,尤其是对于那些对流处理框架尚不熟悉的组织。理解流处理器内部工作机制,管理输入源、处理复杂的流事件,需要专家和踩坑。
2. Cost and Scalability Considerations
在实施 Kappa 架构时,更为明显的一个问题是与在事件流处理平台上存储大数据相关的成本。针对这一挑战的一个潜在解决方案是采用云存储服务(如 AWS S3 或 Google Cloud Storage)提供的数据湖方法。这些服务可以提供可扩展且高效的存储解决方案,能够处理通常与流数据架构相关的大量数据。
将“流数据湖”纳入数据流架构是另一种可行的方法。这涉及使用 Apache Kafka 作为流层,同时与对象存储结合进行长期数据存储。这种设置可以创建一个可扩展且成本效益高的基础架构,但需要仔细的规划和执行,以避免可扩展性问题和不必要的花费。
3. Managing Data Streams for Integrity, Correctness, and Consistency
由于传入数据的连续和并发特性,流系统本质上无法保证事件顺序。这个特性在处理延迟数据时需要进行一些权衡。
流数据架构通常通过采用诸如事件时间窗口和水印等策略来解决这个问题。这些策略使系统能够高效地处理乱序事件。然而,它们可能会引入不准确性,因为在水印之后到达的事件可能会被丢弃,从而在数据中产生轻微的不一致。
为了应对这些挑战,像 Uber 这样的公司创新地设计了他们的 Kappa 架构,以便使用统一的代码库来支持流式结果的回填。
回填管道在一定时间窗口后
重新计算数据,以处理迟到和乱序事件。例如,如果乘客延迟对司机进行评分,直到他们的下一次Uber应用程序会话,这个事件可能会被流水线错过。然而,具有几天延迟的回填管道可以正确将这个事件归因于其正确的会话。通过这种方式,回填管道可以应对延迟,并修补由流水线引起的轻微不一致。
参考:
https://nexocode.com/blog/posts/kappa-architecture/
![[vscode] 1. 在编辑器的标签页下显示文件目录(标签页显示面包屑) 2. 在标题栏上显示当前文件的完整路径](https://img-blog.csdnimg.cn/direct/30566a1eb352438daac2757a7366bd4d.png)