不知道大家是否听说过联合体这个名词。但其实大家不用觉得联合体有多特殊,大家可以想象结构体是一栋楼,里面有很多房间,住了形形色色的住户(不用或者相同的数据)。但联合体只有一个房间,所有的住户都挤在这个房间里面。但是这个房间的大小是以最大数据类型来决定的。比如说我们创建了一个联合体,里面放置了int类型和char类型。那么这个联合体大小计算int类型的大小了。
联合体声明
上面我们也说过了,联合体与结构体一样都是多个成员构成的,这些成员可以不同的型。但是编译器只为最⼤的成员分配⾜够的内存空间。联合体的特点是所有成员共⽤同⼀块内存空间。所
以联合体也叫:共⽤体。但是给联合体最大⼀个成员赋值,那么联合体会至少将最大的成员赋值处理,有多余空间在处理其他的成员,这也是与结构体的一个区别。那么大家看一下下面的照片,就知道

大家看到了吧,联合体是用union+名字。联合体的内容与结构体是一样写的。然后联合体的初始化与结构体也是一样的。但是结构体是给内容分别赋值的。但联合体是定义一个全部都定义的了。 当然在创建联合体的时候可以同时定义。当然我们也可以像结构体一样省略联合体名:

但是嘞,省略联合体名虽然看起来更加简洁了,但是因为没有了名字,后面就不能用该联合体定义新的变量。然后我们使用typedf将联合体改个名字如:

使用看了上面的资料大家应该差不多了解了,联合体声明方法了吧。
验证联合体的特点
大家知道,我在上面写了联合体是将所有的类型装在一个房子里面,并且会保证联合体最大的大小。那么我们看下面的两个代码。首先我们来确定所以类型是住在最大的那个房间里面的(就是类型最大的空间)
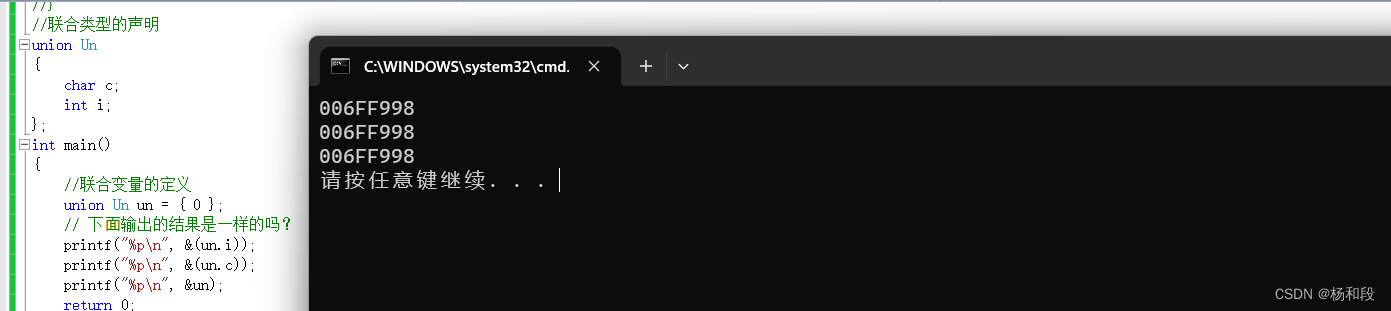 这样大家可以看到打印的地址都是一样的。那么接下来验证这个房间是最大的那个类型:
这样大家可以看到打印的地址都是一样的。那么接下来验证这个房间是最大的那个类型:
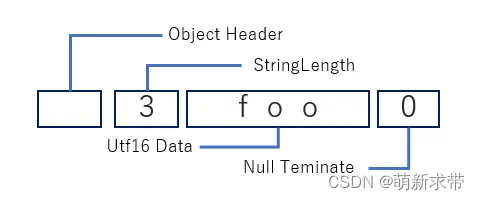
 这里大家可以看到,我们明明是先个i赋的0x11223344。然后给c赋的0x55.然后我们打印i确实0x11223355。这就是联合体的另外一个特点。最少会保证最大联合体成员,然后有空间再处理其他的。那我们看一个示意图来辅助理解
这里大家可以看到,我们明明是先个i赋的0x11223344。然后给c赋的0x55.然后我们打印i确实0x11223355。这就是联合体的另外一个特点。最少会保证最大联合体成员,然后有空间再处理其他的。那我们看一个示意图来辅助理解

联合体与结构体内存对比
当然我们看了联合体内存分布那么我们直接与结构体内存分布对比,这样的话,可以加深我们对两种结构体的内存分布的印象。我们都将两种初始化且赋为0。


计算联合体的大小
我们在前面说过联合体与结构体有差异,但也有相同之处。如也可以使用#pragma pack(value) ,来修改对齐数。但当没有定义 #pragma pack(value) 这种指定 value 字节进行对齐时,它的计算规则是:联合体中最大成员所占内存的大小且必须为最大类型所占字节的最小倍数。举例如下:
首先我们看第一个联合体。我们创建的联合体成员中char a[5]是最大的那么应该首先是5个字节,但是因为int类型是4个字节那么5不是4的倍数,并且5超过4了,那么只有8是复合计算规则的,使用计算的第一个联合体大小是8。
第二个代码,我们可以看到short数组有7的元素,那么就是14个字节。但是int是4个字节呀。4>2,并且14最接近且大于14的41的倍数,只有16了。那么第二个联合体的大小就是16了。这样普通的联合体大小大家应该就可以计算了吧。
接下来我我们看一下结构体嵌套联合体的大小是如何计算的。当然结构体嵌套联合体计算大小肯定也是有计算规则的,毕竟无规矩不成方圆嘛。那么嵌套的话规则是什么样的嘞:它的计算规则是,联合体按照最大成员所占字节且为最大数据类型所对应的字节的最小整数倍的原则进行计算,它所占的字节数与结构体中其他成员所占字节的总和应为结构体中最大数据类型所对应的字节的最小倍数。那我们如何理解嘞,我们来看一下下面的代码:
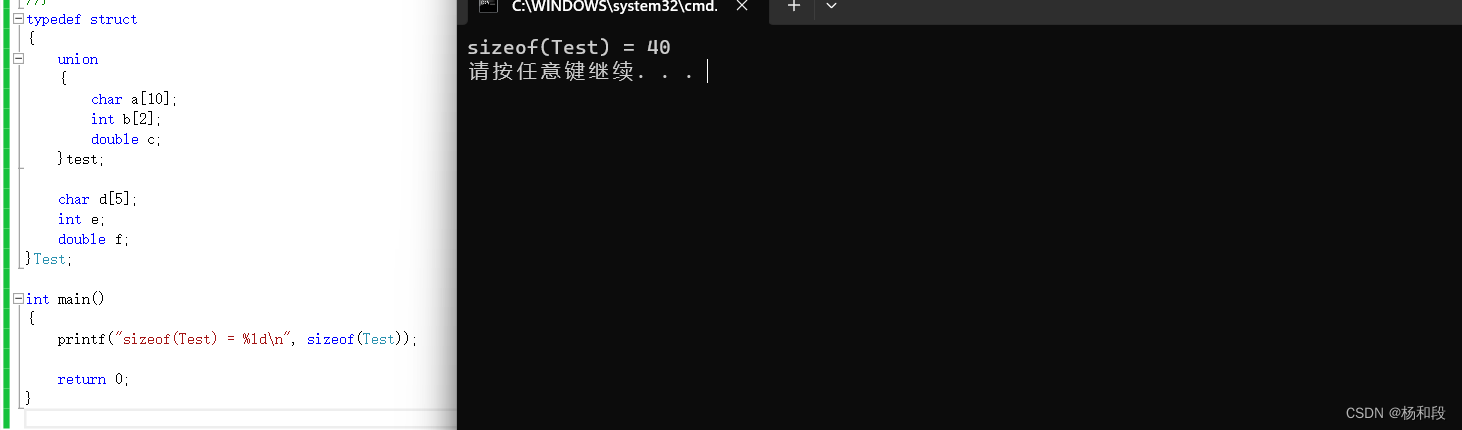
先计算联合体中,最大char a[10]占10字节,但又要为8的最小倍数,因此联合体占16字节。
然后结构体中其余5+4+8=17 字节,不是结构体中最大数据类型 double 所对应的字节数 8的最小倍数,补齐到24字节。所以,综合起来整个结构体大小:16(联合体所占字节)+ 24字节=40字节。
那当我们定义了对其数的话会稍微改变一点:

联合体最大占10字节,且为2的最小倍数,因此联合体占10字节,然后10+5+4+8=27字节,但不是 2的最小倍数,因此如需满足上述规则,该结构体的大小应为:10(联合体所占字节) +5+1(空字节)+4+8=28 字节。
联合体使用举例
大家看到上面后,可能会想,讲这么多,联合体的实际使用方法来个呗,我也好有个心理预期。将来联合体怎么用。那好我们就来个比较简单的联合体使用方法。大家还记得我们前段时间讲过的大小端问题嘛。并且看了上面的知识后我们知道,联合体的存储是优先最大的。那么如果我给最大的赋值1,然后打印最大,那么如果是0这就是大端,如果是1的话那么就是小端了。
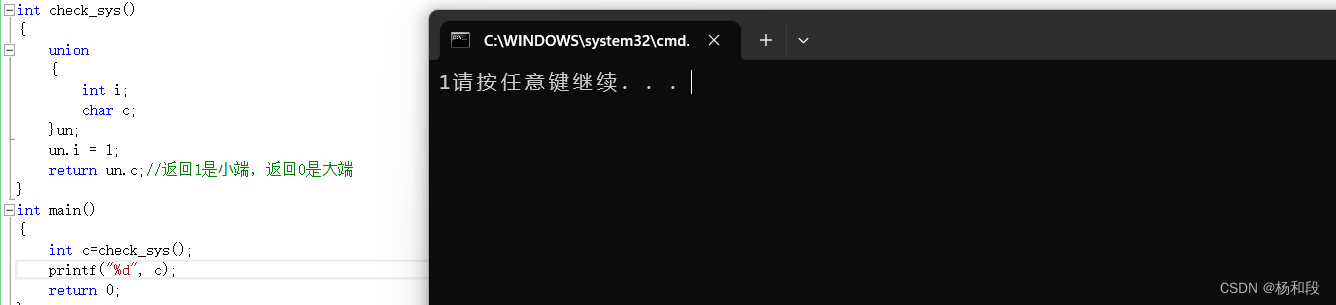
这样大家应该清楚利用联合体来计算我们需要的数据了吧。