一、Spring Cloud Stream介绍
Spring Cloud Stream是一个框架,用于构建与共享消息系统连接的高度可扩展的事件驱动微服务。该框架提供了一个灵活的编程模型,该模型建立在已经建立和熟悉的Spring习惯用法和最佳实践之上,包括对持久发布/子语义、使用者组和有状态分区的支持。
它可以基于 Spring Boot来创建独立的、可用于生产的 Spring应用程序,Spring Cloud Stream为一些供应商的消息 中间件产品提供了个性化的自动化配置实现,并引入了发布-订阅、消费组、分区这三个核心概念。通 过使用 Spring Cloud Stream ,可以有效简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。目前 Spring Cloud Stream 支持 RabbitMQ 、 Kafka 自动化配置。
目前Spring Cloud Stream只适配以下中间件信息:

二、Spring Cloud Stream 工作流程
Spring Cloud Stream应用程序由一个与中间件无关的核心组成。应用程序通过在外部代理公开的目的地和代码中的输入/输出参数之间建立绑定来与外部世界通信。建立绑定所需的特定于Broker的详细信息由特定于中间件的Binder实现来处理。

通过Stream可以很好的屏蔽各个中间件的API差异,它统一了API,生产者通过OUTPUT向消息中间件发 送消息,此时并不需要关心消息中间件是Kafka还是RabbitMQ,不需要关注他们的API,只需要用到Stream的API,这样可以降低学习成本。消费方通过INPUT消费指定的消息,也不需要关注消息中间件 的API,架构图如上图:
我们对上图的对象进行说明:
- Application Core:生产者、消费者;
- inputs:消费者;
- ouputs:生产者;
- Binder:绑定器,主要和消息中间件进行绑定操作;
- Middleware:消息中间件服务;

我们项目中真正应用到Stream,只需要按照如上流程图操作即可;
生产者:
1:使用Source绑定消息的输出管道。
2:通过MessageChannel输出消息。
3:通过@EnableBinding开启binder,将生产者绑定到指定的MQ服务。
消费者:
1:通过@EnableBinding绑定到MQ。
2:通过Sink绑定到输入数据管道。
3:@StreamListener监听指定管道数据。
2.1 Spring Cloud Stream 实战

如上图,当用户行程结束,用户需进入支付操作,当用户支付完成时,我们需要更新订单状态,此时我 们可以让支付系统将支付状态发送到MQ中,订单系统订阅MQ消息,根据MQ消息修改订单状态。我们 将使用 SpringCloud Stream实现该功能。
2.1.1 生产者
1)引入依赖
在 hailtaxi-pay 中引入依赖:
<!--stream-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>2) 配置MQ服务
修改 hailtaxi-pay 的 application.yml 添加如下配置:
server:
port: 18083
spring:
application:
name: hailtaxi-pay
cloud:
#Consul配置
consul:
host: localhost
port: 8500
discovery:
#注册到Consul中的服务名字
service-name: ${spring.application.name}
#Stream
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: 192.168.211.145
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: payExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置3)消息输出管道绑定
/***
* 负责向MQ发送消息
*/
@EnableBinding(Source.class)
public class MessageSender {
@Resource
private MessageChannel output;//消息发送管道
/***
* 发送消息
* @param message
* @return
*/
public Boolean send(Object message) {
//消息发送
boolean bo = output.send(MessageBuilder.withPayload(message).build());
System.out.println("*******send message: "+message);
return bo;
}
}
参数说明:
Source.class:绑定一个输出消息管道Channel。
MessageChannel:发送消息对象,默认是DirectWithAttributesChannel,发消息在 AbstractMessageChannel中完成。
MessageBuilder.withPayload:构建消息。
此时大家可能会有一个疑问?如果我们多个channel,在rabbitMQ中就是说我一个服务有多个交换机该怎么办?
我们来看下 Source.class里面定义的内容是什么,定义的内容如下:
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}所以说如果此时我们要新的管道的话,我们就可以参考Source来定义新的类,然后OUTPUT就定义新的管道名称,然后再配置文件中我们就定义这个新的管道名称。
4)消息发送
在 com.itheima.pay.controller.TaxiPayController 中创建支付方法用于发送消息,代码如下:
/***
* 支付 http://localhost:18083/pay/wxpay/1
* @return
*/
@GetMapping(value = "/wxpay/{id}")
public TaxiPay pay(@PathVariable(value = "id")String id){
//支付操作
TaxiPay taxiPay = new TaxiPay(id,310,3);
//发送消息
messageSender.send(taxiPay);
return taxiPay;
}2.1.2 消费者
1)修改配置
修改 hailtaxi-order 的核心配置文件 application.yml ,在文件中配置要监听的MQ信息:
server:
port: 18082
spring:
application:
name: hailtaxi-order
zipkin:
#zipkin服务地址
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1 #采样值,0~1之间,1表示全部信息都手机,值越大,效率越低
cloud:
#Consul配置
consul:
host: localhost
port: 8500
discovery:
#注册到Consul中的服务名字
service-name: ${spring.application.name}
#Stream
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: 192.168.211.145
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: payExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
group: paygroup #所属分组2)消息监听
在 hailtaxi-order 中创建消息监听对象 com.itheima.order.mq.MessageReceiver ,代码如下:
@EnableBinding(Sink.class)
public class MessageReceiver {
@Value("${server.port}")
private String port;
/****
* 消息监听
* @param message
*/
@StreamListener(Sink.INPUT)
public void receive(String message) {
System.out.println("消息监听(增加用户积分、修改订单状态)-->" + message+"-->port:"+port);
}
}
参数说明:
Sink.class:绑定消费者管道。
@StreamListener(Sink.INPUT):监听消息配置,指定了消息为application中的input。
1.3 消息分组
消息分组有2个好处,分别是集群合理消费、数据持久化。
1.3.1集群消费下的分组
1)分组的意义
分组在项目中是有非常重大的意义,通常应用于消息并发高、消息堆积的场景,这些场景服务消费方通 常会做集群操作,一旦做集群操作,我们又需要项目中的消费者合理消费,比如用户打车支付完成后, 我们需要增加用户积分同时修改订单状态,如果集群环境中有2台服务器都执行该消费操作,此时用户 积分会增加两次,就会造成非幂等问题。

此时集群中相同服务应该属于同一个组,同一个组中只允许有一个足节点消费某一个信息,这样就可以 避免费幂等问题的出现。
2)分组实战
新增一个 hailtaxi-order消费者节点:
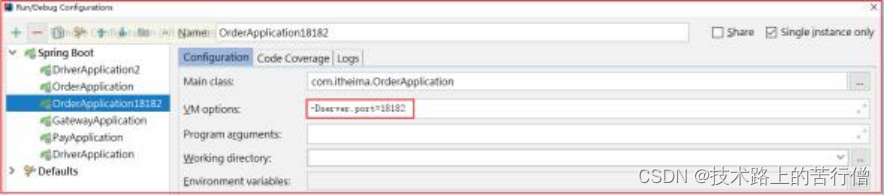
此时运行起来, 18082 和 18182 节点会同时消费所有数据。
修改 hailtaxi-order 的核心配置文件 application.yml ,添加分组:

此时再次测试,可以发现消费者不会重复消费数据。
1.3.2 数据持久化
我们把分组去掉,停掉 hailtaxi-order 服务,然后请求 http://localhost:18083/pay/wxpay/1发 送数据,发送完数据后,再启动 hailtaxi-order服务,此时发现没有数据可以消费,这是因为数据没 有持久化,是一种广播模式,如果需要数据持久化,得给每个消费节点添加group组即可。