CRUD:Create(创建),Retrieve(读取),Update(更新),Delete(删除)。
一、Create
insert [into] table_name [(column [, column] ...)] values (value_list) [, (value_list)] ...
value_list: value, [, value] ...
values 左侧括号内是列属性,右侧括号内是列属性对应的内容,必须在类型和数值上一一对应。
若忽略 values 左侧括号内的内容,则称为全列插入,否则成为按列插入。
创建一张学生表:

1、单行数据 + 全列插入
- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致。
- 注意,这里在插入时,也可以不用指定 id(当然,那时候就需要明确插入数据到哪些列了),那么 MySQL 会使用默认的值进行自增。
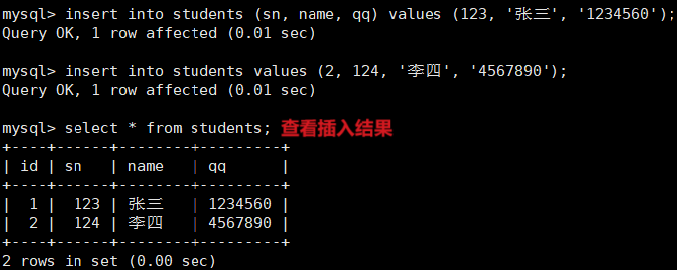
2、多行数据 + 指定列插入

3、插入是否更新

insert ... on duplicate key update column=value [, column = value] ...

- 0 row affected:表中有冲突数据,但冲突数据的值和 update 的值相等。
- 1 row affected:表中没有冲突数据,数据被插入。
- 2 row affected:表中有冲突数据,并且数据已经被更新。
4、替换

- 主键 / 唯一键没有冲突,则直接插入。
- 主键 / 唯一键如果冲突,则删除后再插入。

- 1 row affected:表中没有冲突数据,数据被插入。
- 2 row affected:表中有冲突数据,删除后重新插入。
二、Retrieve
select [distinct] {* | {column [, column] ...} [from table_name] [where ...] [order by column [asc | desc], ...] limit ...
1、SELECT 列
(1)全列查询
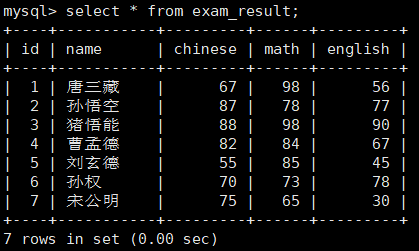
- 查询的列越多,意味着需要传输的数据量越大。
- 可能会影响到索引的使用。
通常情况下不建议使用 * 进行全列查询。
(2)指定列查询

指定列的顺序不需要按定义表的顺序来。
(3)查询字段为表达式
a. 表达式不包含字段

b. 表达式包含多个字段

(4)为查询结果指定别名
select column [as] alias_name [...] from table_name;

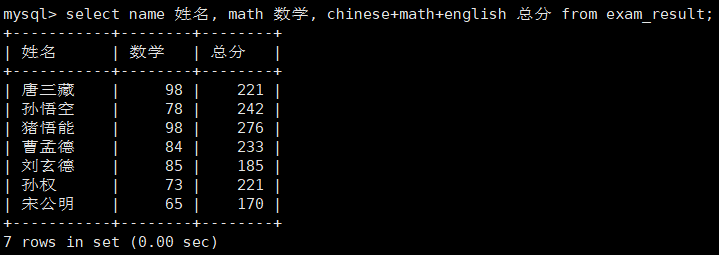
(5)结果去重

2、WHERE 条件
(1)比较运算符



注意:在 MySQL 中, 用 = 来判断两个 字符串或数字 是否相等,与 C/C++ 不同。用 = 判断是否等于 NULL 这样做是不安全的,因为 NULL 和 0 本身表示的含义不同,NULL 表示空,0 表示数字 0。
(2)逻辑运算符

⚪练习
a. 练习一 —— 英语不及格的同学及英语成绩

b. 练习二 —— 语文成绩在 [80, 90] 分的同学及语文成绩
写法一:
- 使用 and 进行条件连接

-
使用 between ... and ... 条件

c. 练习三 —— 数学成绩是 58 / 59 / 98 / 99 分的同学及数学成绩
- 使用 or 进行条件连接

- 使用 in 条件

d. 练习四 —— 姓孙的同学及孙某同学
- % 匹配任意多个(包括 0 个)任意字符
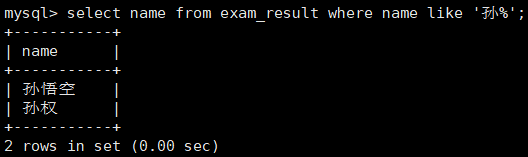
-
_ 匹配严格的一个任意字符
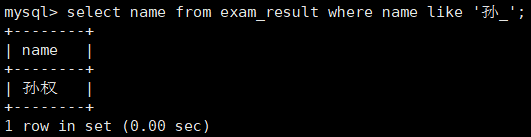
e. 练习五 —— 语文成绩好于英语成绩的同学
- where 条件中比较运算符两侧都是字段

f. 练习六 —— 总分在 200 分以下的同学

where 条件中使用表达式,别名不能用在 where 条件中。
错误写法:
![]()
g. 练习七 —— 语文成绩 > 80 并且不姓孙的同学
- and 与 not 的使用

h. 练习八 —— 孙某同学,否则要求总成绩>200 并且 语文成绩<数学成绩 并且 英语成绩>80
-
综合性查询

i. 练习九 —— NULL 的查询

-
分别查询姓名为空、为空字符串、不为空的



-
NULL 和 NULL 的比较,= 和 <=> 的区别

-
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0

(3)结果排序
- ASC 为升序(从小到大)
- DESC 为降序(从大到小)
默认为 ASC。
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
select ... from table_name [where ...] order by column [asc|desc], [...] ;
⚪练习
a. 练习一 —— 同学及数学成绩,按数学成绩升序显示

b. 练习二 —— 同学名字,按名字排序显示
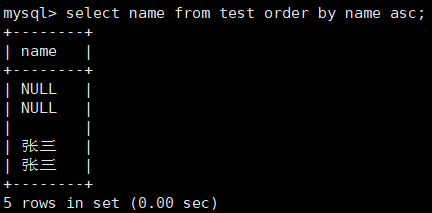

- NULL 视为比任何值都小,升序出现在最上面。
- NULL 视为比任何值都小,降序出现在最下面。
c. 练习三 —— 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
- 多字段排序,排序优先级随书写顺序

asc 可以省略不写,但不建议。
d. 练习四 —— 查询同学及总分,由高到低
为什么在这里又能够使用别名了呢?

能否使用别名完全取决于当前 sql 子句的执行顺序。
order by 中可以使用表达式。
e. 练习五 —— 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
-
结合 where 子句 和 order by 子句

order by 子句的执行顺序晚于 where 子句。
(4)筛选分页结果
- 从 0 开始,筛选 n 条结果
select ... from table_name [where ...] [order by ...] limit n; 3:从表开始()开始连续读取 3 行。
3:从表开始()开始连续读取 3 行。
从 s 开始,筛选 n 条结果select ... from table_name [where ...] [order by ...] limit s, n; 1:开始位置(下标从 0 开始)。3:步长,从指定位置开始,连续读取 3 条记录。
1:开始位置(下标从 0 开始)。3:步长,从指定位置开始,连续读取 3 条记录。
从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用select ... from table_name [where ...] [order by ...] limit n offset s; 4:步长,从指定位置开始,连续读取 4 条记录。1:开始位置(下标从 0 开始)。注意 :起始下标为 0。
4:步长,从指定位置开始,连续读取 4 条记录。1:开始位置(下标从 0 开始)。注意 :起始下标为 0。

只有数据准备好了,才要显示,limit 的本质功能是 “显示”。
得先有数据,才能 “显示”,“显示” 时,limit 只是告诉 MySQL,显示时只显示从哪里开始,从开始位置显示几行。
limit 不是条件筛选,本质就是把数据准备好,排好序,然后再 limit,执行阶段更靠后。
三、Update
update table_name set column=expr [, column = expr ...] [where ...] [order by ...] [limit ...]
对查询到的结果进行列值更新。
⚪练习
(1)练习一 —— 将孙悟空同学的数学成绩变更为 80 分
- 数据更新

(2)练习二 —— 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
- 一次更新多个列

(3)练习三 —— 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
- 更新值为原值基础上变更
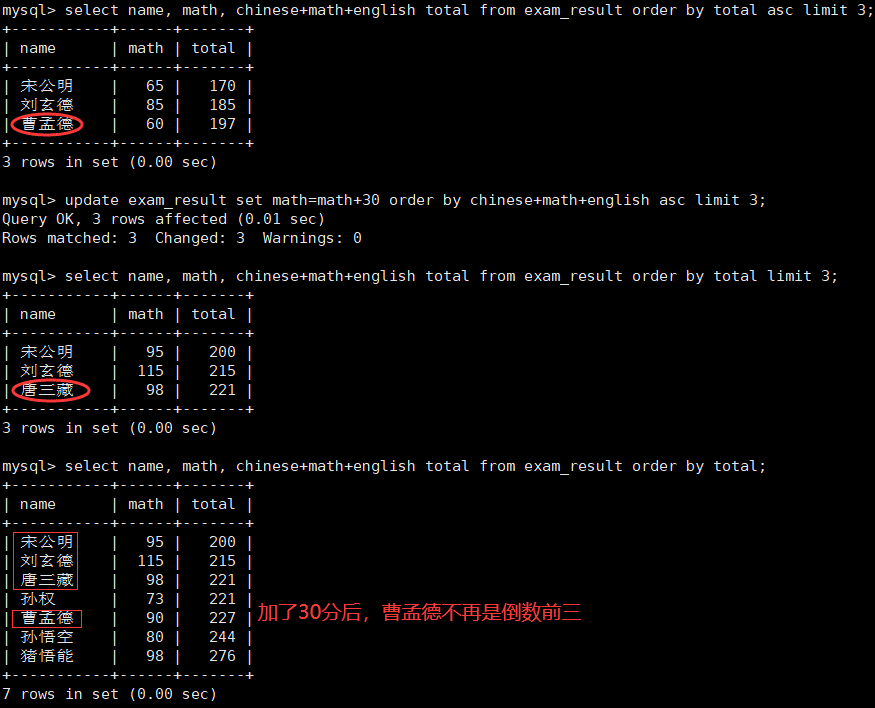
注意:别名可以在 order by 中使用 。
(4)练习四 —— 将所有同学的语文成绩更新为原来的 2 倍
- 没有 where 子句,则更新全表。

注意 :更新全表的语句慎用。
四、Delete
1、删除数据
delete from table_name [where ...] [order by ...] [limit ...];
⚪练习
a. 练习一 —— 删除孙悟空同学的考试成绩
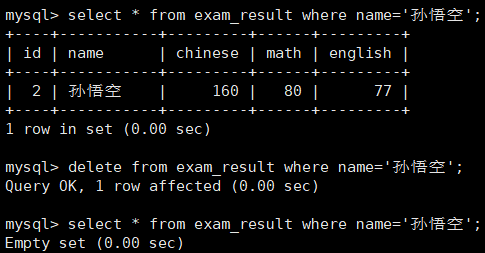
b. 练习二 —— 删除整张表数据



![]()
注意 :删除整表操作要慎用。
2、截断表
truncate [table] table_name;
![]()
-
截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
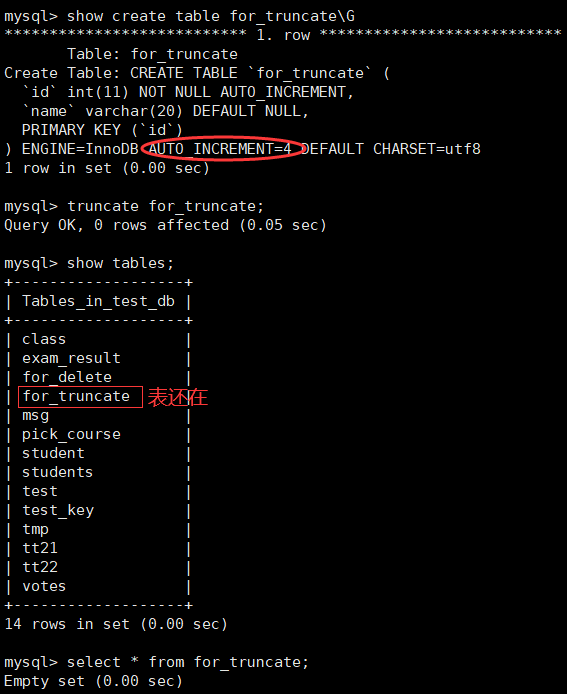
-
再插入一条数据,自增 id 再重新增长

delete 和 truncate 的区别:
- 都可以清空表中的数据。
- delete from 是传统的删除,不会对计数器进行清空或重新置位,而 truncate 清空表会重置 auto_increment 项。
- truncate 是直接将表中数据清空,它不走事务,而 delete from 以及之前学的 sql 最终在运行时都要以事务的方式被包装,然后再让 MySQL 去运行。
- 只能对整表操作,不能像 delete 一样针对部分数据操作。
- 实际上 MySQL 不对数据操作,所以比 delete 更快,但是 truncate 在删除数据时,并不经过真正的事物,所以无法回滚。
- 会重置 auto_increment 项。
五、插入查询结果
insert into table_name [(column [, column ...])] select ...;
⚪练习
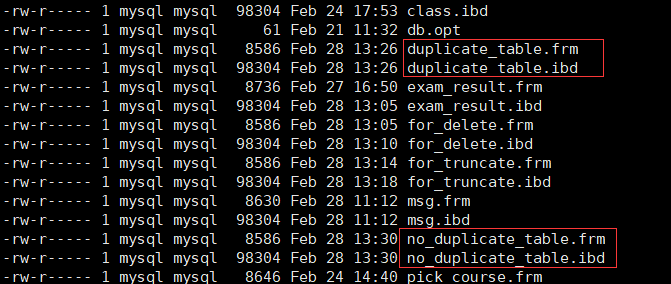
(1)练习一 —— 删除表中的的重复复记录,重复的数据只能有一份

错误思路:
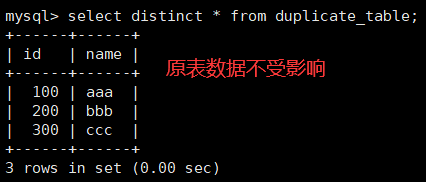
-
创建一张空表(no_duplicate_table,结构和 duplicate_table 一样)
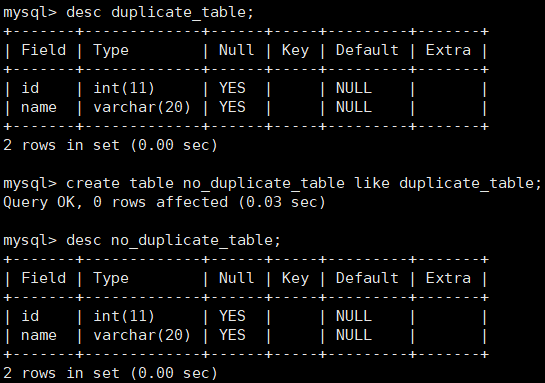
-
将 duplicate_table 的去重数据插入到 no_duplicate_table

-
通过重命名表,实现原子的去重操作

为什么最后是通过 rename 方式进行的?
就是单纯的想等一切都就绪了,然后统一放入、更新、生效等。
六、聚合函数

⚪练习
(1)练习一 —— 统计班级共有多少同学
- 使用 * 做统计,不受 NULL 影响
- 使用表达式做统计

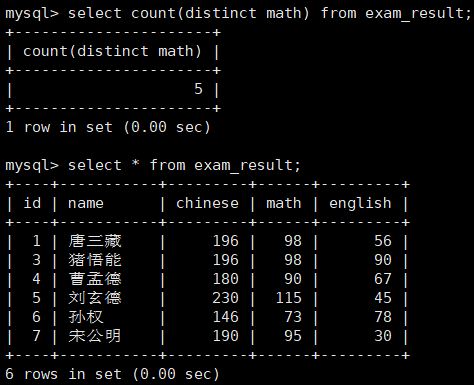
(2)练习二 —— 统计本次考试的数学成绩分数个数
-
count(math) 统计的是全部成绩

- count(distinct math) 统计的是去重成绩数量
注意:
distinct 要写在括号内,因为我们是要对 math 去重,而不是对 count() 的结果去重。
NULL 不会计入结果。
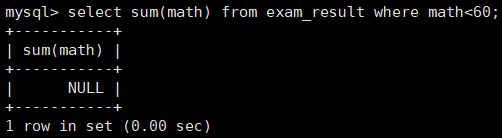
(3)练习三 —— 统计数学成绩总分

- 不及格 < 60 的总分,没有结果,返回 NULL
- 数学的平均成绩

(4)练习四 —— 统计平均总分

(5)练习五 —— 返回英语最高分

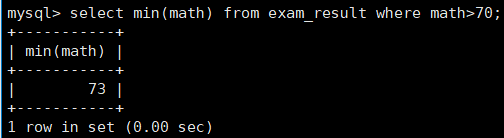
(6)练习六 —— 返回 > 70 分以上的数学最低分
七、group by 子句的使用
分组的目的:为了进行分组后,方便进行聚合统计。
在 select 中使用 group by 子句可以对指定列进行分组查询:
select column1, column2, .. from table group by column;
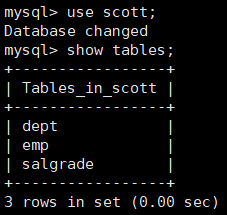
1、准备工作,创建一个雇员信息表(来自 Oracle 9i 的经典测试表)
- emp 员工表
-
dept 部门表

-
salgrade 工资等级表
2、如何显示每个部门的平均工资和最高工资
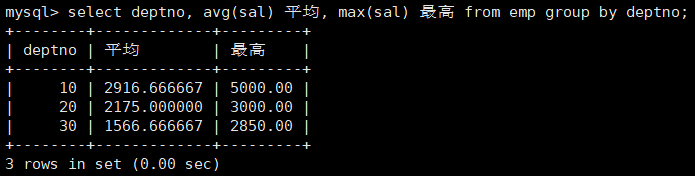
指定列名,实际分组是用该列不同的行数来进行分组的。
分组的 deptno,组内一定是相同的。说明可以被聚合压缩。
分组就是把一组按照条件拆分成了多个组,进行各自组内的统计。
分组(“分表”),就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计。
3、显示每个部门的每种岗位的平均工资和最低工资

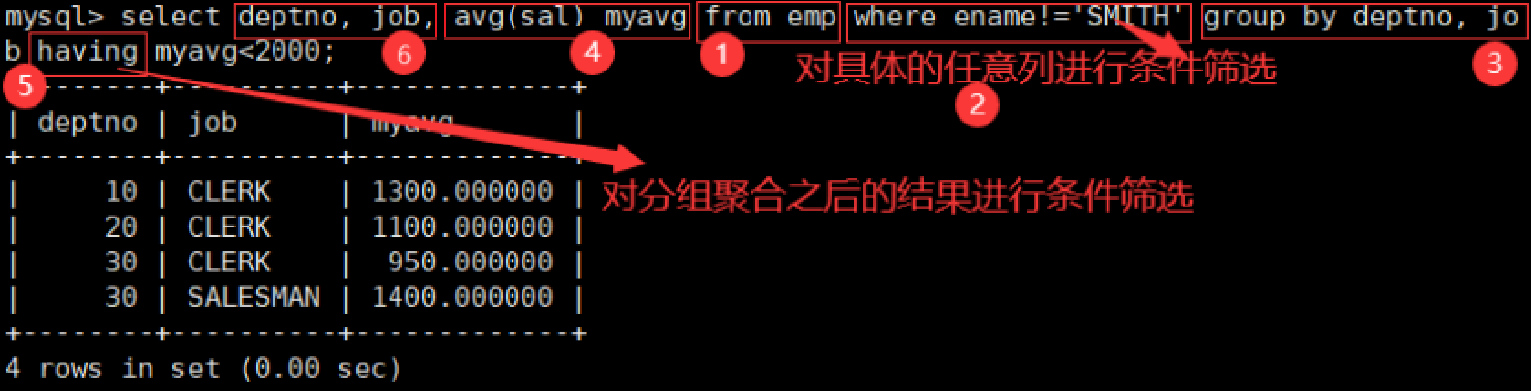
4、显示平均工资低于 2000 的部门和它的平均工资
(1)统计出每一个部门的平均工资(结果先聚合出来)
![]()
(2)having 和 group by 配合使用,对 group by 结果进行过滤(对聚合的结果进行判断)
having 和 group by 的语义是一样的,having 相当于是对分组聚合统计后的数据,进行条件筛选。

having 经常和 group by 搭配使用,作用是对分组进行筛选,作用有些像 where。
having VS where 的区别与执行顺序是什么?
都能够做条件筛选,这是它们的共性。
但它们是完全不同的条件筛选,它们的条件筛选的阶段是不同的。

补充:不要单纯的认为,只有在磁盘上将表结构导入到 MySQL,真实存在的表才叫表。
中间筛选出来的,包括最终结果,全都是逻辑上的表。(MySQL 一切皆表)
只要我们能够处理好单表的 CURD,所有的 sql 场景就都能用统一的方式进行。
5、补充
SQL 查询中各个关键字的执行先后顺序:
from > on > join > where > group by > with > having > select > distinct > order by > limit