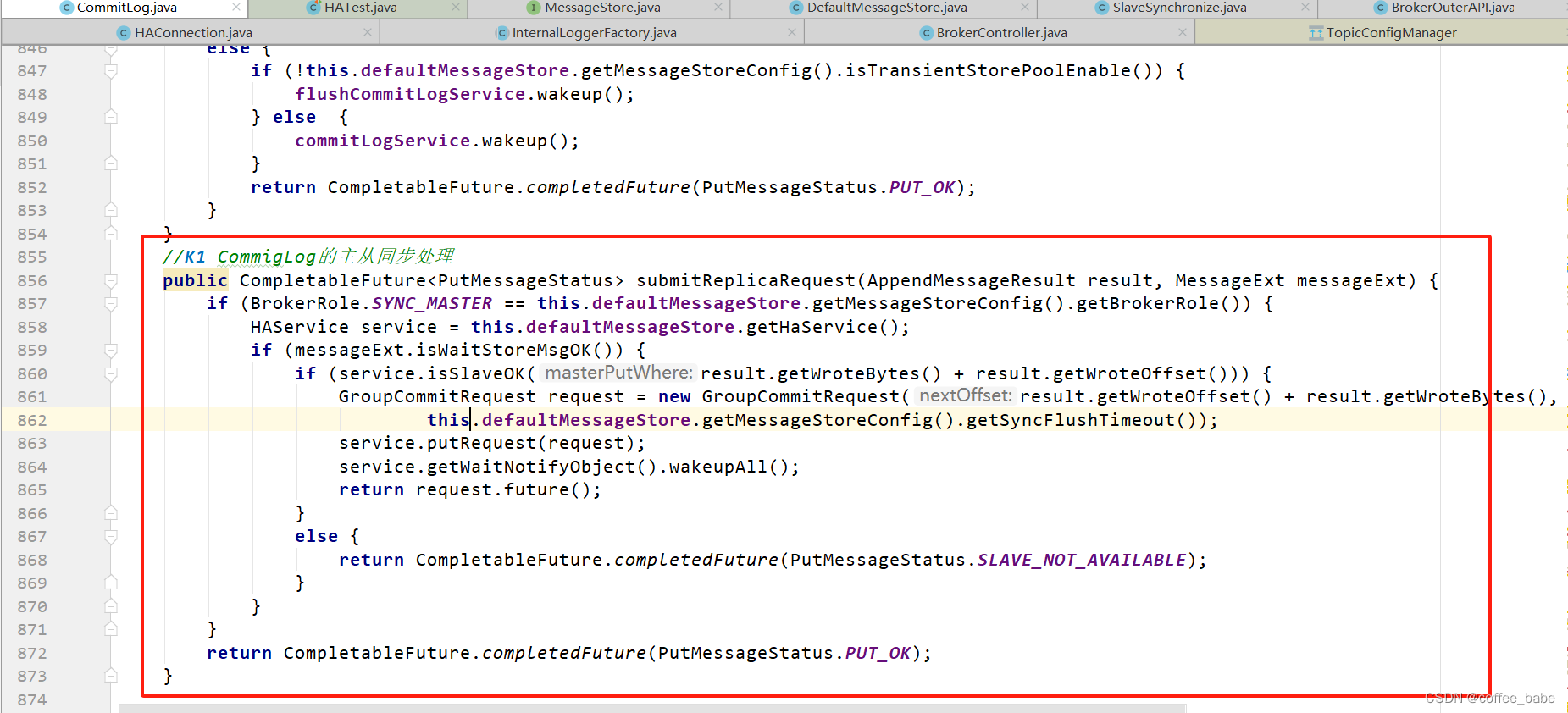
引言:大语言模型中的机器遗忘问题
在人工智能领域,大语言模型(LLMs)因其在文本生成、摘要、问答等任务中展现出的卓越能力而备受关注。然而,这些模型在训练过程中可能会记住大量数据,包括敏感或不当的信息,从而引发伦理和安全问题。为了解决这些问题,机器遗忘(Machine Unlearning,MU)技术应运而生,旨在从预训练模型中移除不良数据的影响及其相关模型能力,同时保持对其他信息的完整知识生成,而不影响因果无关的信息。机器遗忘在大语言模型的生命周期管理中扮演着关键角色,它不仅有助于构建安全、可信赖的生成型AI,还能在不需要完全重新训练的情况下提高资源效率。
论文标题:RETHINKING MACHINE UNLEARNING FOR LARGE LANGUAGE MODELS
公众号「夕小瑶科技说」后台回复“机器遗忘”获取论文pdf。
机器遗忘(MU)的定义与重要性
1. MU在大语言模型(LLM)中的应用
机器遗忘(Machine Unlearning, MU)是一种新兴的技术,旨在从预训练的大语言模型(LLM)中消除不良数据的影响,例如敏感或非法信息,同时保持对基础知识生成的完整性,并且不影响与之无关的信息。在大语言模型中,MU的应用包括但不限于文本生成、摘要、句子完成、改写和问答等生成性任务。例如,Eldan & Russinovich (2023) 使用MU策略来防止生成《哈利·波特》系列的版权材料。
2. 遗忘不良数据影响的必要性
大语言模型因其能够记忆大量文本而备受关注,但这也可能导致包括社会偏见、记忆个人和机密信息等道德和安全问题。因此,精确地遗忘这些不良数据对于确保LLM的安全性、可靠性和信任度至关重要。此外,考虑到LLM的训练成本高昂且耗时,重新训练以消除不良数据的影响通常是不切实际的,这使得MU成为一种可行的替代方案。
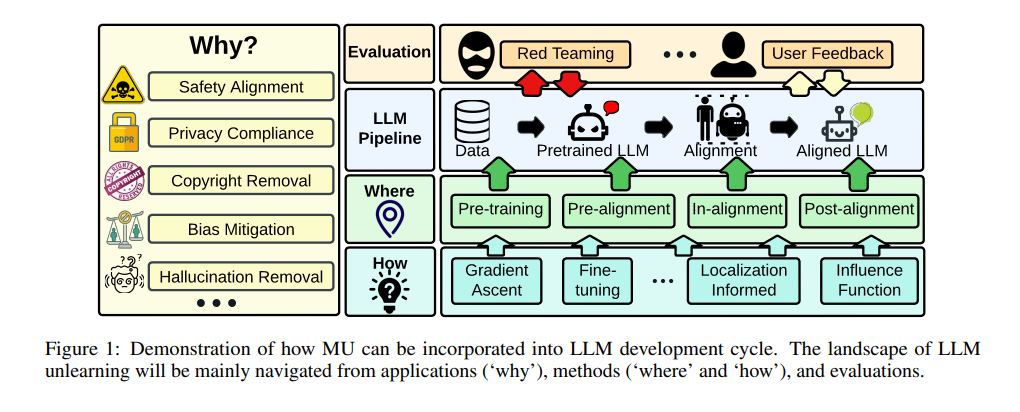
LLM遗忘的挑战与现状
1. 遗忘目标的界定问题
在LLM中精确定义和定位“遗忘目标”是一项挑战,因为这些目标可能是训练集的子集或需要被移除的知识概念。当前的研究通常是上下文和任务依赖的,缺乏标准化的语料库来进行LLM遗忘。
2. 数据与模型交互的复杂性
随着LLM的规模增长,开发可扩展和适应性强的MU技术变得更加复杂。这不仅影响性能评估,而且由于缺乏重新训练作为基准,评估的准确性也受到影响。例如,研究提出了上下文遗忘和虚构遗忘的方法,前者允许在黑盒模型上进行遗忘,后者提供了重新训练的替代方案。
3. 遗忘效果的多面性评估
遗忘的范围往往没有明确规定,这与模型编辑中面临的挑战相似。有效的遗忘应确保LLM删除目标数据的知识,同时保持对该范围之外数据的效用。此外,尽管LLM遗忘在多种应用中具有潜力,但目前缺乏全面和可靠的评估。
-
例如,最近的研究表明,即使在编辑模型以删除敏感信息的努力之后,这些信息仍可能从编辑后的模型中被逆向工程出来,这突显了进行彻底和对抗性评估的必要性,以及设计更多机械性方法以保证遗忘的真实性。
遗忘方法的探索与评估
1. 模型基方法与输入基方法
在探索大语言模型(LLMs)的遗忘方法时,研究者们主要集中在模型基方法和输入基方法两大类。
-
模型基方法涉及修改LLMs的权重或架构组件以实现遗忘目标,例如通过梯度上升或其变体来更新模型参数,使得模型对于遗忘集(Df)中的样本产生误预测的可能性最大化。

(图为基于模型的图像编码基本原理框架图)
-
输入基方法则设计输入指令,如上下文示例或提示,来引导原始LLM(无需参数更新)达到遗忘目标。
2. 影响函数与梯度上升变体
影响函数是评估数据移除对模型性能影响的标准方法,但在LLM遗忘的背景下并不常用,主要是因为涉及到求逆Hessian矩阵的计算复杂性,以及使用近似法导出影响函数时的准确性降低。
梯度上升(Gradient Ascent,GA)是一种直接的遗忘方法,通过最大化遗忘集Df中样本的误预测可能性来更新模型参数。GA的变体包括将其转换为梯度下降方法,目的是最小化重新标记遗忘数据上的预测可能性。
3. 本地化知识遗忘
本地化知识遗忘的目标是识别和定位对遗忘任务至关重要的模型单元(例如层、权重或神经元)。
-
例如,通过表示去噪或因果追踪来完成模型层的本地化,或者使用基于梯度的显著性来识别需要微调以实现遗忘目标的关键权重。
这种方法的目的是在保护模型对非遗忘目标数据的效用的同时,确保LLMs删除目标数据的知识。
遗忘效果的评估框架
1. 与重训练的比较
在传统的遗忘范式中,从头开始重训练模型并从原始训练集中移除被遗忘的数据被视为精确遗忘。然而,由于重训练LLMs的可扩展性挑战,很难建立评估LLM遗忘性能的上限。最近的解决方案是引入虚构数据(合成作者档案)到模型训练范式中,模拟在新引入的集合上的重训练过程。
2. 鲁棒性评估与“硬”范围内的例子
遗忘的有效性指标之一是确保对于遗忘范围内的例子,即使是那些与遗忘目标直接相关的“硬”例子,也能实现遗忘。评估“硬”范围内的例子可以通过技术如改写LLMs打算遗忘的内容或创建多跳问题来实现。
3. 训练数据检测与隐私保护
成员推断攻击(Membership Inference Attack,MIA)旨在检测数据点是否是受害模型训练集的一部分,这是评估机器遗忘方法的一个关键隐私揭示指标。在LLM遗忘的背景下,特别是当重训练不是一个选项时,这一概念变得更加重要。
LLM遗忘的应用领域
1. 版权与隐私保护
在LLM遗忘的应用中,版权与隐私保护占据了重要的位置。
-
例如,机器遗忘(MU)被用于防止生成哈利波特系列的版权材料(Eldan & Russinovich, 2023)。

这一应用不仅涉及法律和伦理考量,还涉及到数据的合法使用。在美国,联邦贸易委员会(FTC)要求一家公司彻底销毁因未经合法同意而训练的模型,这一做法被称为算法性吐露(algorithmic disgorgement)。LLM遗忘提供了一种可行的替代方法,可以通过移除非法数据的影响来避免完全销毁模型。
版权保护内容的删除与确定训练数据的确切来源需要删除的问题相关,这引发了数据归属问题。
-
例如,与哈利波特系列相关的泄露可能有多种原因,例如书籍被用于LLM的训练数据,或者训练数据包含与系列相关的在线讨论,或者LLM使用检索增强生成(retrieval-augmented generation),可能导致从搜索结果中泄露信息。
除了从训练数据中删除版权信息外,还有防止LLM泄露用户隐私的场景,特别是个人识别信息(PII)。这一关切与LLM记忆和训练数据提取密切相关。
2. 社会技术伤害减少
LLM遗忘的另一个应用是对齐(alignment),旨在使LLM与人类指令对齐,并确保生成的文本符合人类价值观。遗忘可以用来忘记有害行为,如产生有毒、歧视性、非法或道德上不可取的输出。遗忘作为安全对齐工具,可以在LLM开发的不同阶段进行。目前的研究主要集中在“预对齐”阶段(Yao et al., 2023),但在其他阶段可能存在未开发的机会。例如在对齐之前、期间或之后。
幻觉是LLM面临的一个重大挑战,它涉及生成虚假或不准确的内容,这些内容可能看起来是合理的。先前的研究表明,遗忘可以通过针对特定问题并遗忘事实上不正确的回应来减少LLM的幻觉(Yao et al., 2023)。由于幻觉可能由多个来源引起,可能的用途是遗忘作为常见幻觉或误解来源的事实上不正确的数据。
LLM也被认为会产生偏见的决策和输出。
-
在视觉领域,遗忘已被证明是减少歧视以实现公平决策的有效工具。
-
在语言领域,遗忘已被应用于减轻性别-职业偏见(Yu et al., 2023)和许多其他公平问题。
-
然而,更多的机会存在,例如遗忘训练数据中的刻板印象。
LLM也被认为容易受到越狱攻击(jailbreaking attacks),即,故意设计的提示导致LLM生成不希望的输出)以及投毒/后门攻击。鉴于遗忘在其他领域作为对抗攻击防御的成功,遗忘可以成为这两种类型攻击的自然解决方案。
总结与未来展望
1. LLM遗忘的挑战与机遇
LLM遗忘面临的挑战包括确保遗忘目标的普遍性、适应各种模型设置(包括白盒和黑盒场景)以及考虑遗忘方法的具体性。LLM遗忘应该专注于有效地移除数据影响和特定模型能力,以便在各种评估方法中,特别是在对抗性环境中验证遗忘的真实性。LLM遗忘还应该精确地定义遗忘范围,同时确保在这个遗忘范围之外保持一般语言建模性能。
通过审视当前的技术水平,我们获得了LLM遗忘未来发展的洞见。例如,基于定位的遗忘显示出效率和效果的双重优势。有效的遗忘需要仔细考虑数据-模型影响和对手。尽管LLM遗忘和模型编辑在其制定和方法设计上存在相似之处,但它们在目标和方法上有所不同。此外,从LLM遗忘的研究中获得的洞见可能会催生其他类型的基础模型(例如,大型视觉-语言模型)的技术进步。
2. 从遗忘到编辑:LLM的新方向
LLM遗忘与模型编辑紧密相关,模型编辑关注的是局部改变预训练模型的行为,以引入新知识或纠正不希望的行为。遗忘的目标有时与编辑的目标一致,尤其是当编辑被引入以擦除信息时。像遗忘范围一样,编辑范围也是确保在定义范围之外不影响模型生成能力的关键。遗忘和模型编辑都可以使用“先定位,然后编辑/遗忘”的原则来处理。
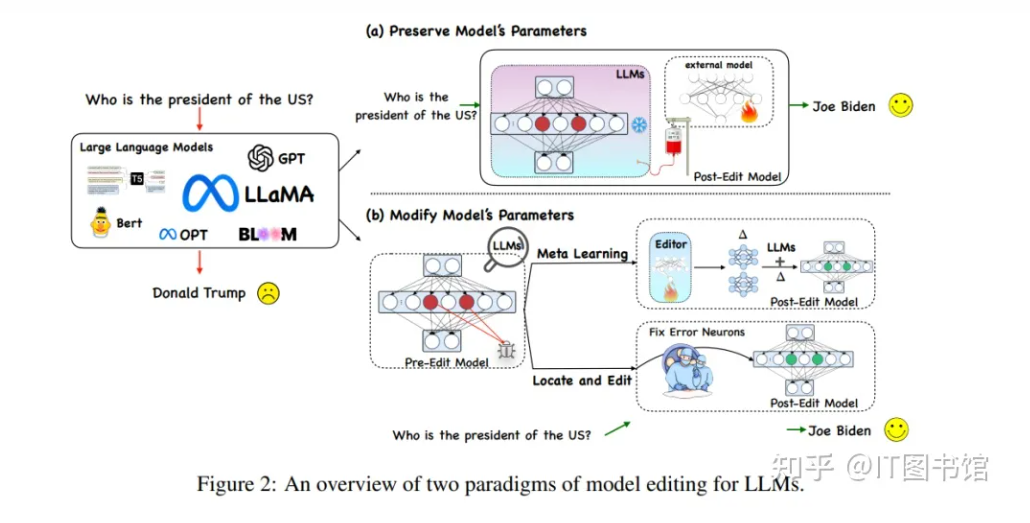
尽管存在上述联系,LLM遗忘和编辑之间有明显的区别。
-
首先,与编辑响应相比,遗忘响应有时是未知的。不正确或不当的遗忘响应的特定性可能被视为遗忘后的LLM幻觉。
-
其次,尽管遗忘和模型编辑可能共享一些共同的算法基础,但前者不创建新的答案映射。相反,其核心目标是全面消除归因于特定知识或概念的影响。
-
第三,我们可以从“工作记忆”的角度区分模型编辑和遗忘。已知在LLM中,工作记忆是通过神经元激活而不是基于权重的长期记忆来维持的。
因此,现有的基于记忆的模型编辑技术专注于更新短期工作记忆,而不是改变模型权重中封装的长期记忆。然而,研究者们认为遗忘需要更机械化的方法来促进对预训练LLM的“深层”修改。
论文的更广泛影响
1. 伦理与社会影响的讨论
在探讨大语言模型(LLMs)的机器遗忘(MU)时,我们不得不面对一系列伦理和社会问题。这些模型因其能够生成与人类创作内容极为相似的文本而备受关注,但它们对大量语料的记忆能力也可能导致伦理和安全问题。
例如,社会偏见、刻板印象、敏感或非法内容的生成、以及可能被用于发展网络攻击或生物武器的风险。这些问题强调了根据不同安全背景,灵活且高效地调整预训练LLMs的必要性,以满足用户和行业的特定需求。
机器遗忘作为一种替代方案,旨在从预训练模型中移除不良数据的影响及相关模型能力。例如,为了防止生成《哈利·波特》系列的版权材料,研究人员使用了机器遗忘策略。这些讨论不仅关系到技术的发展,也触及到如何在不损害模型整体知识生成能力的同时,确保数据隐私和版权的保护。
2. 机器遗忘在实际场景中的应用必要性
机器遗忘在实际应用中的必要性体现在多个方面。
-
首先,它有助于避免敏感或非法信息的传播,并且在不影响与遗忘目标无关信息的前提下,维护模型的完整性。
-
其次,考虑到LLMs的昂贵和漫长的训练周期,重新训练模型以消除不良数据效应通常是不切实际的。
因此,机器遗忘成为了一个可行的选择。
在实际应用中,机器遗忘可以用于版权和隐私保护,例如避免生成版权受保护的内容,或防止泄露用户的个人识别信息。此外,机器遗忘还可以用于社会技术性危害的减少,比如通过遗忘有害行为来使LLMs与人类指令和价值观保持一致,或者减少由于错误信息源导致的幻觉现象。
公众号「夕小瑶科技说」后台回复“机器遗忘”获取论文pdf。