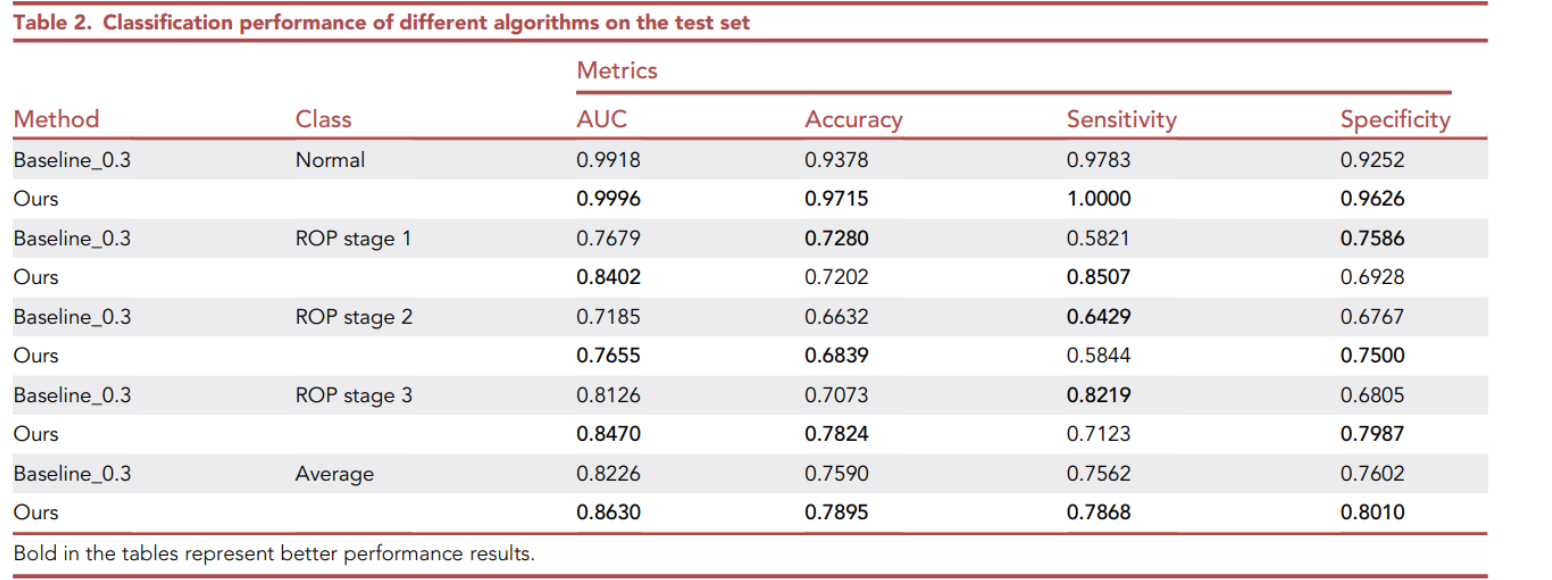
零.前言:
本文章借鉴:Python爬虫实战(五):根据关键字爬取某度图片批量下载到本地(附上完整源码)_python爬虫下载图片-CSDN博客
大佬的文章里面有API的获取,在这里我就不赘述了。
一.实战目标:
对百度的图片进行爬取,利用代理IP实现批量下载。
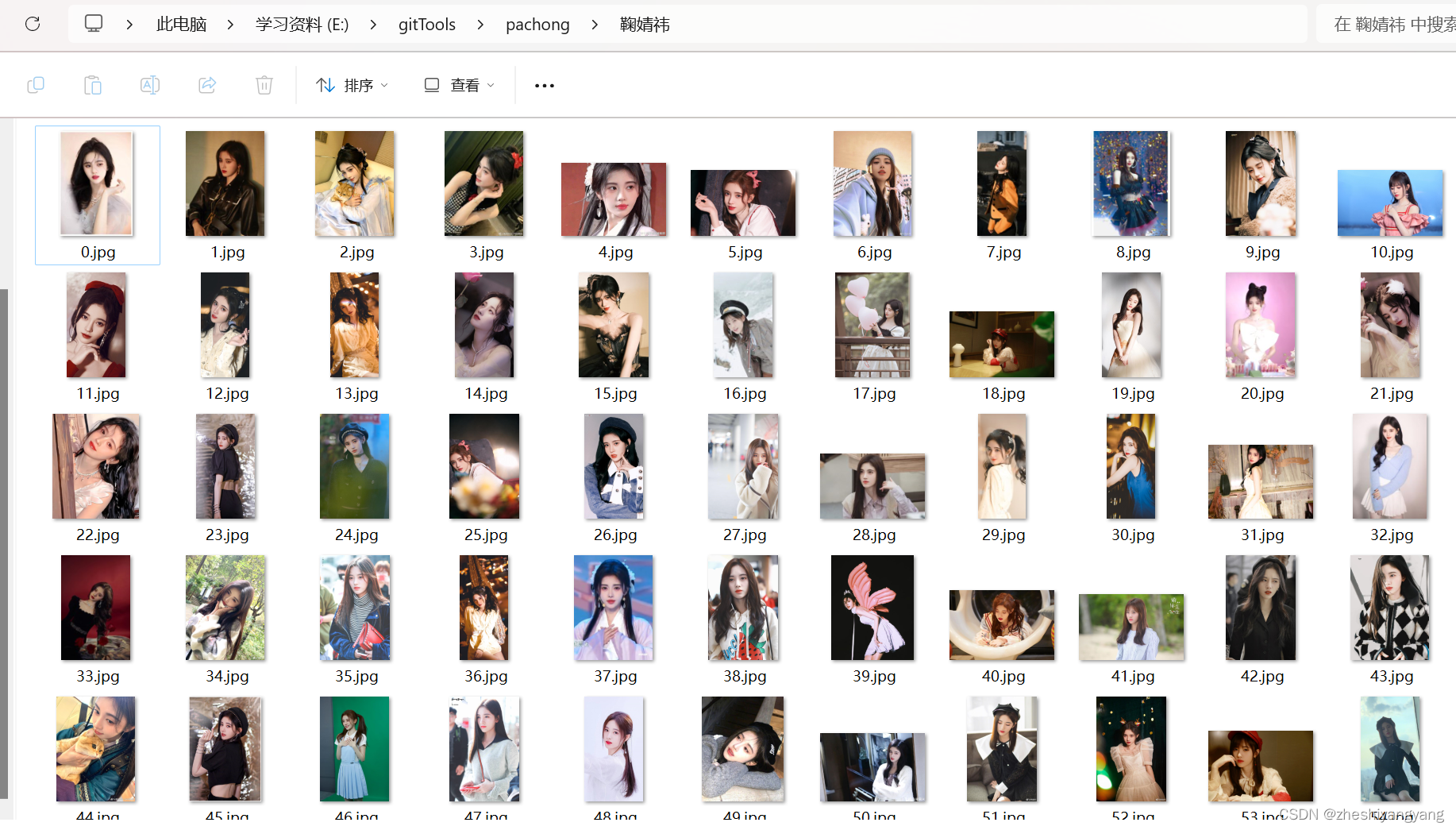
二.实现效果:
实现批量下载指定内容的图片,存放到指定文件夹中:
三.代码实现
3.1分析网页
右键网页,点击检查,进入我们的Google开发者工具。
筛选出我们需要的文件(通过查找载荷寻找)
接下来,只需要构建我们的载荷:
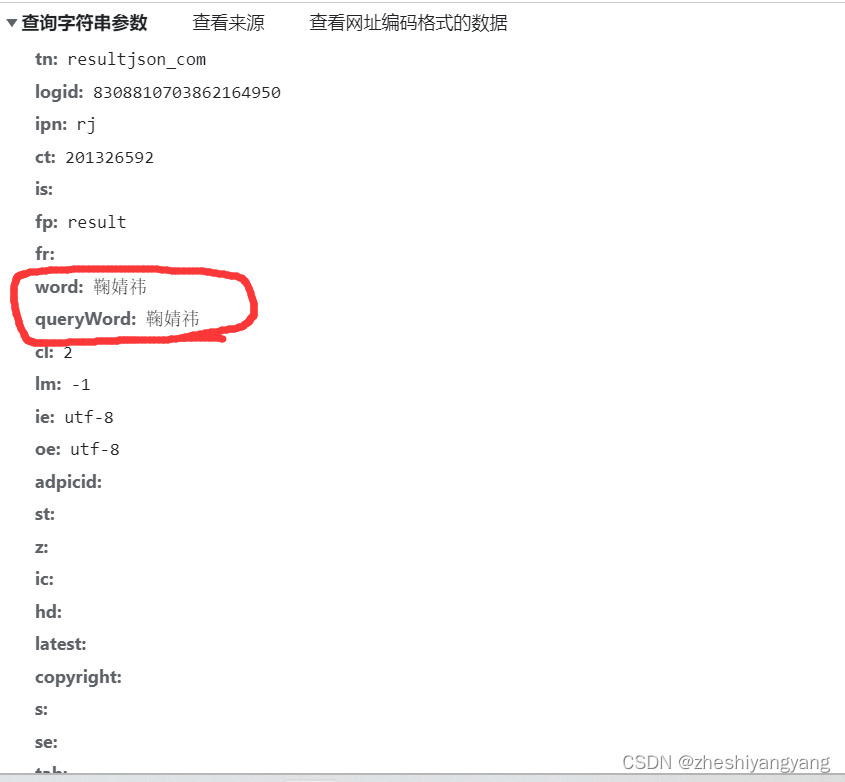
3.2获取图片的URL链接
def get_img_url(keyword):
#接口连接
url = "https://image.baidu.com/search/acjson"
#请求头
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
#params参数
params = {
"tn": "resultjson_com",
"logid": "7831763171415538646",
"ipn": "rj",
"ct": "201326592",
"is":"",
"fp":"result",
"fr":"",
"word":f"{keyword}",
"queryWord":f"{keyword}",
"cl":"2",
"lm":"-1",
"ie":"utf - 8",
"oe":"utf - 8",
"adpicid":"",
"st":"",
"z":"",
"ic":"",
"hd":"",
"latest":"",
"copyright":"",
"s":"",
"se":"",
"tab":"",
"width":"",
"height":"",
"face":"",
"istype":"",
"qc":"",
"nc":"1",
"expermode":"",
"nojc":"",
"isAsync":"",
"pn":"1",
"rn":"100",
"gsm":"78",
"1709030173834":""
}
#创建get请求
r = requests.get(url=url,params=params,headers=header)
#切换编码格式
r.encoding = "utf-8"
json_dict = r.json()
#定位数据
data_list = json_dict["data"]
#存储链接
url_list = []
#循环取链接
for i in data_list:
if i:
u = i["thumbURL"]
url_list.append(u)
return url_list结果:
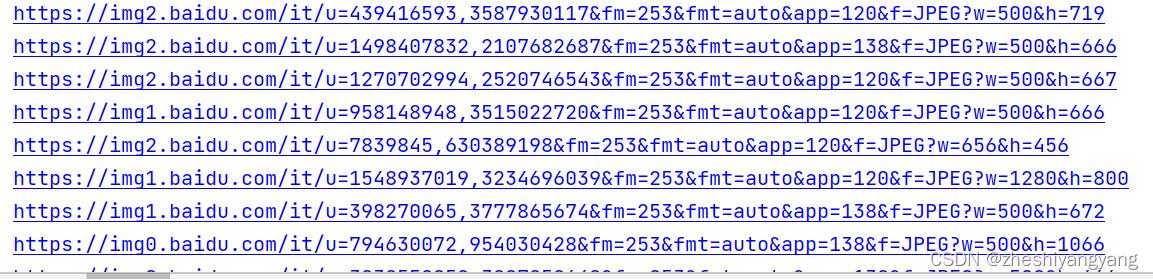
3.3实现代理
def get_ip():
#代理API
url = "你的代理API"
while 1:
try:
r = requests.get(url,timeout=10)
except:
continue
ip = r.text.strip()
if "请求过于频繁" in ip:
print("IP请求频繁")
time.sleep(1)
continue
break
proxies = {
"https": f"{ip}"
}
return proxies效果:

3.4实现爬虫
def get_down_img(img_url_list):
#创建文件夹
if not os.path.isdir("鞠婧祎"):
os.mkdir("鞠婧祎")
#定义图片编号
n = 0
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
times = 0
while times < len(img_url_list):
#获取代理IP
proxies = get_ip()
try:
img_data = requests.get(url=img_url_list[times],headers=header,proxies=proxies,timeout=2)
except Exception as e:
print(e)
continue
#拼接图片存放地址和名字
img_path = "鞠婧祎/" + str(n) + ".jpg"
#写入图片
with open(img_path,"wb") as f:
f.write(img_data.content)
n = n + 1
times += 1四、优化
上面基本实现了批量爬取图片的目的,但是在实际使用中可能会因为代理IP的质量问题,网络问题,导致爬取效率低下,在这里作者给出几点优化的空间:
1.设置timeout超时时间(秒/S)
2.使用requests.sessions类,构建一个sessions对象,设置连接重试次数。
3.使用多线程,分批爬取
具体实现,可以等作者后面慢慢更新,挖个大坑,记得催更。。。
五、全部代码
import requests
import time
import os
def get_img_url(keyword):
#接口连接
url = "https://image.baidu.com/search/acjson"
#请求头
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
#params参数
params = {
"tn": "resultjson_com",
"logid": "7831763171415538646",
"ipn": "rj",
"ct": "201326592",
"is":"",
"fp":"result",
"fr":"",
"word":f"{keyword}",
"queryWord":f"{keyword}",
"cl":"2",
"lm":"-1",
"ie":"utf - 8",
"oe":"utf - 8",
"adpicid":"",
"st":"",
"z":"",
"ic":"",
"hd":"",
"latest":"",
"copyright":"",
"s":"",
"se":"",
"tab":"",
"width":"",
"height":"",
"face":"",
"istype":"",
"qc":"",
"nc":"1",
"expermode":"",
"nojc":"",
"isAsync":"",
"pn":"1",
"rn":"100",
"gsm":"78",
"1709030173834":""
}
#创建get请求
r = requests.get(url=url,params=params,headers=header)
#切换编码格式
r.encoding = "utf-8"
json_dict = r.json()
#定位数据
data_list = json_dict["data"]
#存储链接
url_list = []
#循环取链接
for i in data_list:
if i:
u = i["thumbURL"]
url_list.append(u)
print(u)
return url_list
def get_ip():
#代理API
url = "你的API"
while 1:
try:
r = requests.get(url,timeout=10)
except:
continue
ip = r.text.strip()
if "请求过于频繁" in ip:
print("IP请求频繁")
time.sleep(1)
continue
break
proxies = {
"https": f"{ip}"
}
return proxies
def get_down_img(img_url_list):
#创建文件夹
if not os.path.isdir("鞠婧祎"):
os.mkdir("鞠婧祎")
#定义图片编号
n = 0
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
times = 0
while times < len(img_url_list):
#获取代理IP
proxies = get_ip()
try:
img_data = requests.get(url=img_url_list[times],headers=header,proxies=proxies,timeout=2)
except Exception as e:
print(e)
continue
#拼接图片存放地址和名字
img_path = "鞠婧祎/" + str(n) + ".jpg"
#写入图片
with open(img_path,"wb") as f:
f.write(img_data.content)
n = n + 1
times += 1
if __name__ == "__main__":
url_list = get_img_url("鞠婧祎")
get_down_img(url_list)六、前置文章
有些读者可能不太懂一些爬虫的知识,在这里作者给出部分文章,方便读者理解:
关于Cookie的浅谈-CSDN博客
JSON简介以及如何在Python中使用JSON-CSDN博客
Python爬虫实战第一例【一】-CSDN博客