早产儿视网膜病变 ROP 分期
- 提出背景
- 解法框架
- 解法步骤
- 一致性正则化
- 算法构建思路
- 实验
提出背景
论文:https://www.cell.com/action/showPdf?pii=S2589-0042%2823%2902593-2
早产儿视网膜病变(ROP)目前是全球婴儿失明的主要原因之一。
- 这是一种影响早产儿视网膜的疾病,特别是在婴儿出生时体重非常轻或出生时非常早的婴儿中。
- 可以导致视力下降甚至失明。
最近,在基于深度学习的计算机辅助诊断方法方面取得了显著进展。
然而,深度学习通常需要大量标注数据来优化模型,但这在临床场景中需要经验丰富的医生投入大量时间。
相比之下,获取大量未标注图像相对容易。
在本文中,我们提出了一个新的半监督学习框架,以降低自动ROP分期的注释成本。
我们设计了两种一致性正则化策略,预测一致性损失和语义结构一致性损失,这可以帮助模型从未标注数据中挖掘有用的区分信息,从而提高分类模型的泛化性能。
在真实临床数据集上的广泛实验表明,所提出的方法有望在保持良好分类性能的同时,大大减少临床场景中的标记需求。
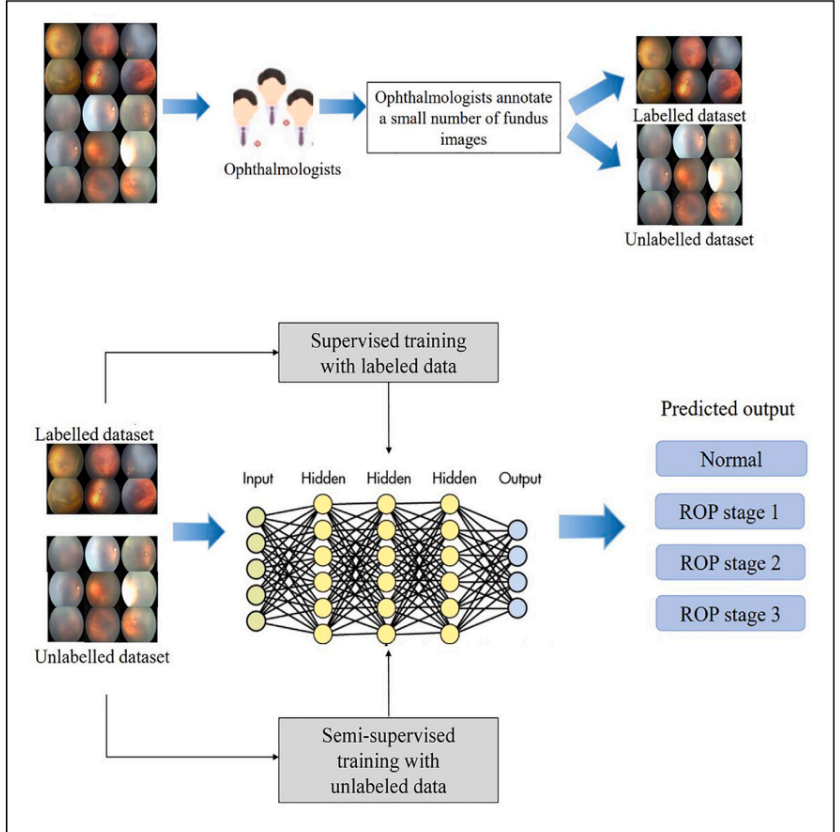
这张图是半监督深度学习模型的开发与验证流程,用于自动化地对早产儿视网膜病变(Retinopathy of Prematurity,简称ROP)进行分期。
整个流程分为:
-
数据准备:
- 有一组由眼科医生标注的眼底照片(即标签数据集),这些照片作为有监督学习的基础。
- 另一组未标注的眼底照片(即无标签数据集),将在半监督学习中使用。
-
有监督学习:
- 使用标注的数据集进行训练,这是传统的机器学习方法,模型通过已标记的数据学习并预测结果。
-
半监督学习:
- 利用未标注的数据集来提高模型的性能,这个方法允许模型从未标注的数据中学习,增强其预测能力。
-
神经网络结构:
- 一种典型的深度学习模型,包含输入层、多个隐藏层和输出层。
- 输入层接收眼底照片的数据,隐藏层进行数据处理,输出层给出ROP分期的预测结果。
-
预测输出:
- 模型的输出结果是ROP的几个不同阶段:正常、ROP 1期、ROP 2期和ROP 3期。
研究的亮点:
- 开发了一种新的半监督分类模型来利用未标签的数据进行ROP分期。
- 提出了两种一致性损失方法来有效地从未标签数据中提取信息。
- 通过实验验证了这种方法可以提高分类性能。
总结,用深度学习,特别是半监督学习,来提高自动化医学图像分析的准确性和效率。
通过结合标注和未标注数据,研究者们能够开发出更精确的ROP分期模型。
解法框架
-
子问题1:ROP分期诊断的主观性和诊断差异
- 子解法1:深度学习模型 - 利用深度学习技术进行特征提取和分类以辅助诊断。
-
子问题2:大量手动图像读取的工作量
- 子解法2:半监督学习 - 使用标记有限的数据和大量未标记数据进行模型训练,以减少人工读取工作量。
-
子问题3:标记数据获取困难和耗时
- 子解法3:一致性正则化策略 - 不依赖数据标签,通过约束数据不同扰动下模型预测的一致性来提升分类性能。
历史问题及其背景:之所以用这些子问题和子解法,是因为以下背景:
-
之所以用深度学习模型,是因为ROP分期诊断具有主观性和诊断变异性。深度学习可以提供更一致和标准化的分析。
-
之所以用半监督学习,是因为大量标记数据的获取既困难又耗时。通过利用未标记数据,可以显著减少对昂贵且稀缺的医学专家时间的依赖。
-
之所以用一致性正则化策略,是因为在实际的临床场景中,标记数据有限,而未标记数据相对容易获取。该策略通过利用大量未标记的数据,提高了模型利用有限标记数据的能力。
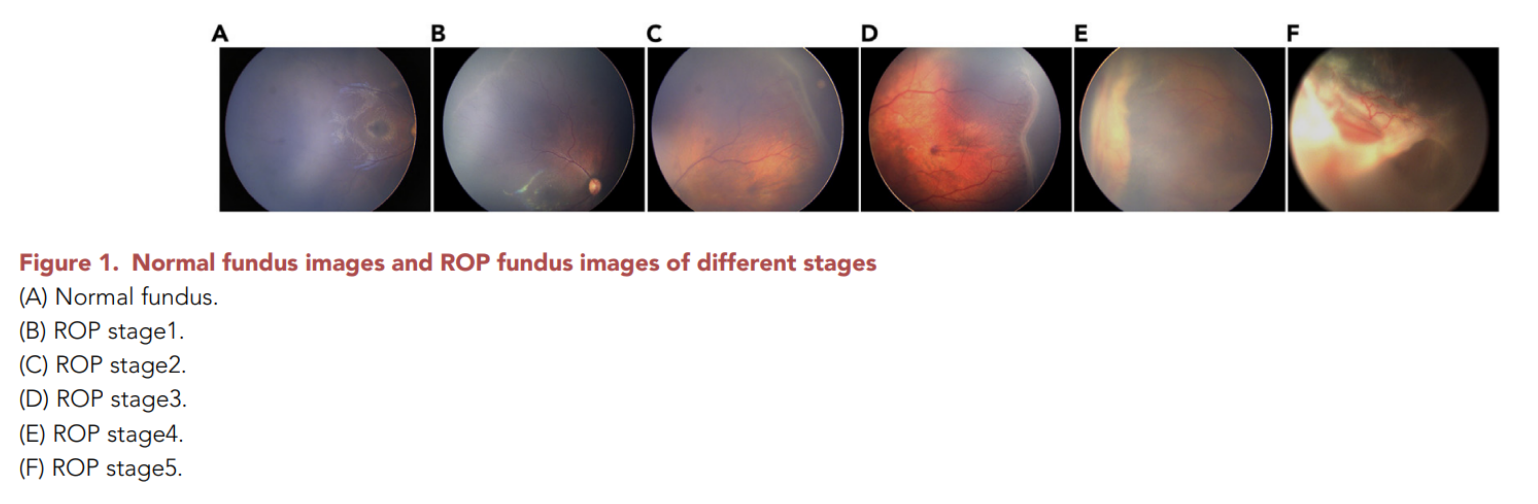
这张图是正常眼底图片和不同阶段的早产儿视网膜病变(ROP)眼底图片。
- A:正常眼底。
- B:ROP第一阶段。
- C:ROP第二阶段。
- D:ROP第三阶段。
- E:ROP第四阶段。
- F:ROP第五阶段。
每张图片显示了ROP病变发展过程中眼底的变化。
随着ROP的进展,可以看到视网膜的结构和血管的明显变化:
- 第一阶段通常表现为视网膜后极部血管和非血管区域之间的白色分界线。
- 第二阶段展示了分界线的进一步加宽和抬高,以及脊状隆起。
- 第三阶段中,脊状隆起变得更加明显,并伴有新生血管。
- 第四和第五阶段通常显示进一步的视网膜脱离,可能需要进行眼部超声波检查。
这些图片是理解和诊断ROP不同阶段的重要资源,也是深度学习模型训练中使用的重要数据。
解法步骤
解法:构建一个半监督深度学习分类模型,该模型结合了学生模型与教师模型,通过标记数据的监督损失和未标记数据的一致性损失进行优化。
-
子解法1:利用标记数据的监督损失优化学生模型。
这种损失是通过有标签数据计算的交叉熵损失函数来实现,直接教导模型识别已知的ROP阶段。
-
子解法2:利用未标记数据的一致性损失优化模型。
包括预测一致性损失和语义结构一致性损失。预测一致性损失通过鼓励学生模型和教师模型对相同图片(即使进行了不同的数据增强处理)给出相同的输出,从而提高模型的泛化能力。
语义结构一致性损失则进一步鼓励模型在数据增强后保持相同的语义结构,利用未标记图像中的信息来提升分类性能。
之所以采用预测一致性损失和语义结构一致性损失,是因为ROP的不同阶段之间存在一定的语义相关性,这种相关性可以被模型利用来提升分类性能,尤其是在标签数据有限的情况下。
通过结合两种一致性损失,模型可以更好地利用未标记数据,提高分类的准确性和鲁棒性。
分类具体步骤:
-
标记数据的学习(子解法1):
- 初始阶段,使用有标签的数据集对学生模型进行训练。
- 计算交叉熵损失函数,这是一个监督损失,它衡量模型预测的概率分布与真实标签的概率分布之间的差异。
- 使用优化算法(如SGD、Adam等)来更新学生模型的参数,以最小化这个损失。
-
教师模型的更新:
- 教师模型通常是学生模型的一个移动平均版本,它代表了学生模型在过去几个迭代中性能的稳定表现。
- 通过对学生模型参数进行指数移动平均(EMA)来更新教师模型的参数。
-
未标记数据的学习(子解法2):
- 对于未标记的数据,分别通过学生模型和教师模型进行预测。
- 对未标记数据应用数据增强,如旋转、缩放、色彩变换等,以生成变换后的图像。
- 预测一致性损失要求学生模型和教师模型对原始未标记图像及其增强版本给出相似的预测。
- 语义结构一致性损失进一步确保了即使在数据增强后,模型仍能保持对图像语义结构的正确理解。
-
损失函数的结合和优化:
- 综合监督损失和一致性损失,形成总损失函数。
- 使用总损失函数来更新学生模型的参数,同时间接地更新教师模型的参数。
-
迭代训练和评估:
- 迭代地进行上述步骤,每次迭代都使用有标签和无标签的数据来更新模型。
- 定期在验证集上评估模型的性能,监控分类准确率和模型的泛化能力。
-
终止条件:
- 当模型在验证集上的性能不再提升或达到预定的迭代次数后,停止训练。
- 可能会使用早停法(early stopping)来防止过拟合。
一致性正则化
一致性正则化策略是一种用于半监督学习的技术。
它基于这样一个假设:即使输入数据经过轻微的、随机的变换,一个良好的模型应该也能输出相同或者非常相似的预测。
这种策略主要解决的问题是如何利用未标记的数据来提高模型的泛化能力,尤其是在标记数据稀缺的情况下。
解决的问题:
- 标记数据的稀缺性:在很多实际应用中,尤其是医学图像处理领域,标记数据往往难以获取,因为需要专家的时间和精力进行注释。
- 利用未标记数据:大量可用的未标记数据未被充分利用,一致性正则化允许模型从这些数据中学习并提高其性能。
一致性正则化的要素拆解:
-
数据扰动:
- 模型应对输入数据的轻微变换保持一致的响应。
- 这些变换可能包括图像的旋转、翻转、缩放、色彩扭曲等。
-
一致性损失:
- 用来度量模型对原始输入数据和扰动后数据的输出差异的损失函数。
- 目标是最小化这种差异。
-
模型的平滑性:
- 一致性正则化隐式地鼓励模型在输入空间中的行为更加平滑,这是因为对输入的小变化不应该导致输出的大变化。
-
教师-学生架构:
- 在某些一致性正则化方法中,使用一个教师模型来生成对未标记数据的软标签,学生模型被训练以预测与教师模型相同的输出。
-
半监督训练循环:
- 结合有标签数据的监督学习和无标签数据的一致性学习,通过迭代过程逐步提升模型的性能。
-
正则化的权衡:
- 一致性正则化的权重是一个超参数,需要仔细调整,以平衡监督损失和一致性损失之间的关系。
-
多样性的引入:
- 通过数据增强或其他方法引入变化,以防止模型过于依赖数据中的特定模式,促进模型泛化能力的提升。
-
监督信号的强化:
- 即使在一致性正则化下,模型也需要足够的有标签数据来学习正确的决策边界。
-
网络架构和优化算法:
- 选择合适的神经网络架构和优化算法来支持一致性正则化的训练过程。
一致性正则化策略将上述要素结合起来,以使得模型能够更好地从未标记数据中学习,同时保持对有标记数据的准确预测,最终达到提高整体模型性能的目的。
算法构建思路
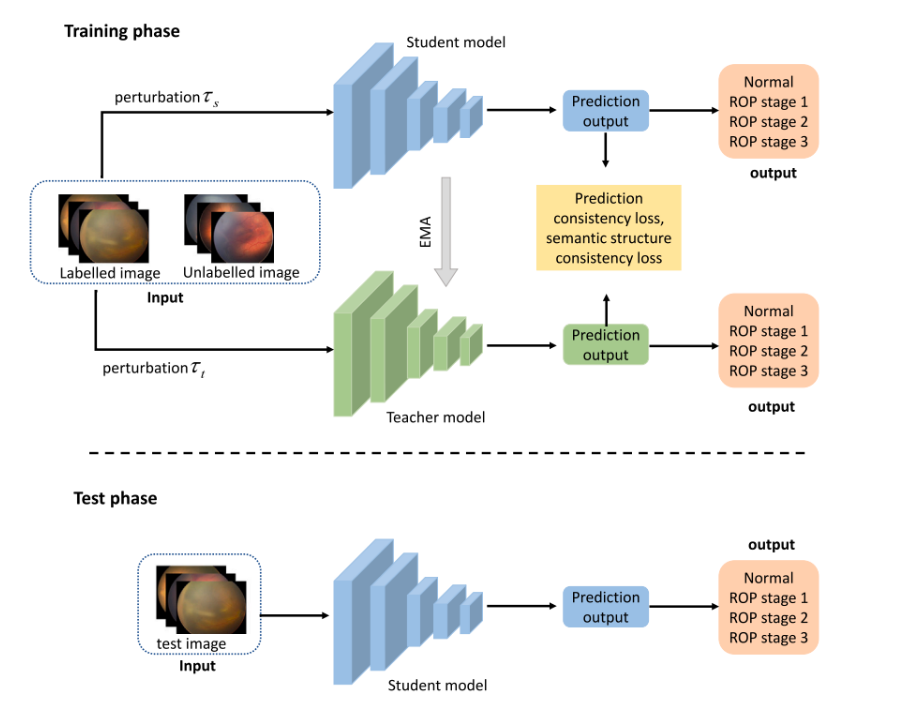
训练阶段
-
输入:模型同时接收标记和未标记的图像。这允许模型在有限的标记数据下利用未标记数据进行训练。
-
扰动:对学生模型和教师模型输入的图像进行扰动。这通常用于增加模型的鲁棒性,减少过拟合的风险。
-
学生模型和教师模型:学生模型直接从数据中学习,而教师模型则是对学生模型的预测进行时间平均(EMA)得到的。EMA可以平滑预测结果,减少噪声的影响。
-
预测输出:学生模型和教师模型都会对输入的图像给出预测。
-
损失函数:通过比较学生模型和教师模型的预测输出来计算一致性损失,包括预测一致性损失和语义结构一致性损失。这有助于确保两个模型的预测在未标记数据上保持一致性。
测试阶段
-
输入:在测试阶段,只有学生模型被用来对新的测试图像进行推理。
-
输出:学生模型提供最终的预测输出,通常是类别概率。
这个框架通过教师模型指导学生模型以及两者之间的一致性损失来优化学生模型的性能。
教师模型作为一个参考,通过EMA平滑学生模型的预测,而一致性损失确保学生模型可以在没有标签的数据上进行鲁棒的学习。
通过这种方式,模型可以更好地泛化到未见过的数据,即使在标记数据有限的情况下。
学生模型与教师模型:构建两个模型,学生模型用于学习和预测,教师模型用于生成稳定的目标输出,指导学生模型学习。
监督损失:利用标记数据和交叉熵损失函数指导学生模型学习正确的分类。
一致性损失:利用未标记数据,通过比较学生模型和教师模型对相同输入的输出,引入一致性损失来正则化模型。
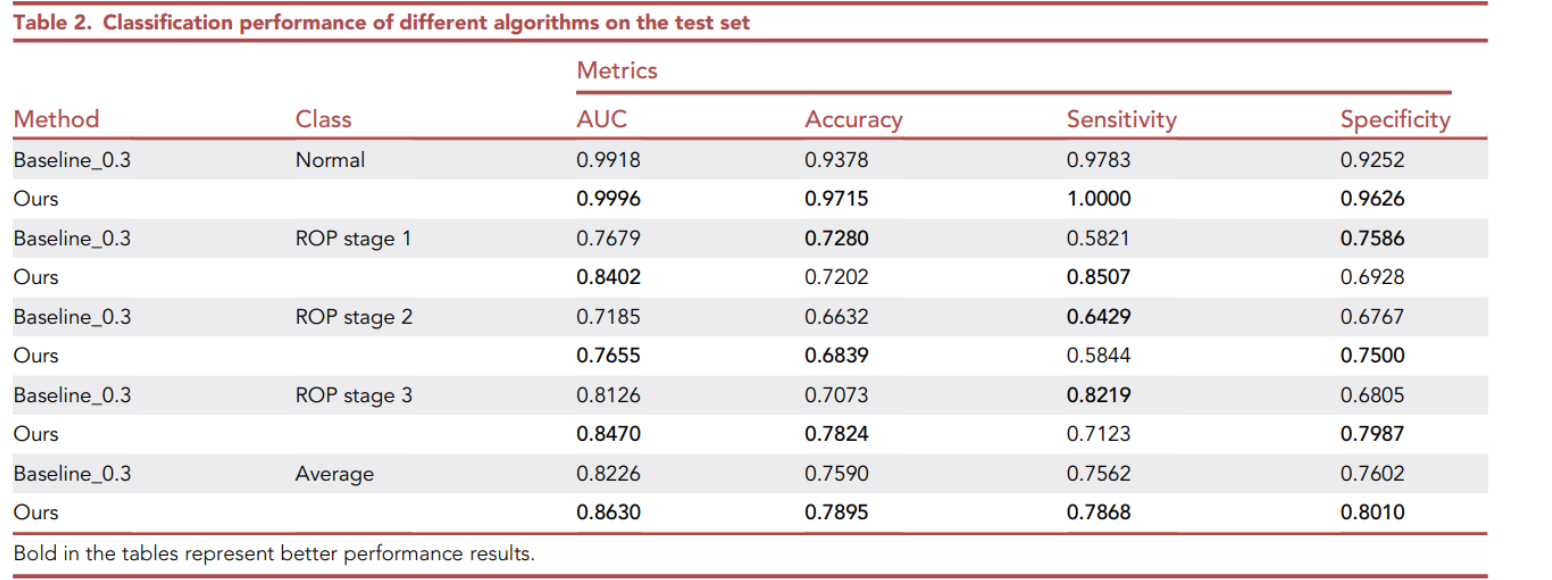
实验
模型诊断标准:
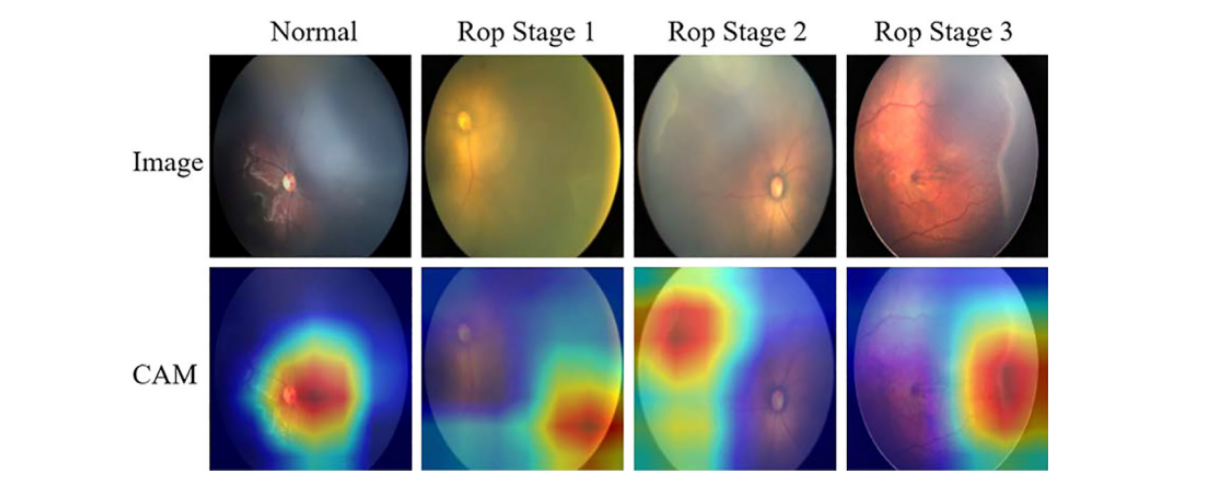
训练数据:

使用的技术:
Semi-supervised deep learning classification model: 本研究中开发的模型,如果希望获得这个模型,可以通过邮件联系主要负责人(电子邮件地址hjq1010@126.com),仅限于非商业的研究目的使用。
测试分数: