Kubernetes剖析
前言
容器技术这样一个新生事物,完全重塑了整个云计算市场的形态。它不仅催生出了一批年轻有为的容器技术人,更培育出了一个具有相当规模的开源基础设施技术市场。
在这个市场里,不仅有 Google、Microsoft 等技术巨擘们厮杀至今,更有无数的国内外创业公司前仆后继。而在国内,甚至连以前对开源基础设施领域涉足不多的 BAT、蚂蚁、滴滴这样的巨头们,也都从 AI、云计算、微服务、基础设施等维度多管齐下,争相把容器和 Kubernetes 项目树立为战略重心之一。
就在这场因“容器”而起的技术变革中,Kubernetes 项目已然成为容器技术的事实标准,重新定义了基础设施领域对应用编排与管理的种种可能。
- 容器技术的兴起源于 PaaS 技术的普及;
- Docker 公司发布的 Docker 项目具有里程碑式的意义;
- Docker 项目通过“容器镜像”,解决了应用打包这个根本性难题。
容器本身没有价值,有价值的是“容器编排”
写在前面
本文划分四大模块
-
“白话”容器技术基础:
梳理容器技术生态的发展脉络,用最通俗易懂的语言描述容器底层技术的实现方式,知其然,也知其所以然。
-
Kubernetes 集群的搭建与实践:
Kubernetes 集群号称“非常复杂”,但是如果明白了其中的架构和原理,选择了正确的工具和方法,它的搭建却也可以“一键安装”,它的应用部署也可以浅显易懂。
-
容器编排与 Kubernetes 核心特性剖析:
“编排”永远都是容器云项目的灵魂所在,也是 Kubernetes 社区持久生命力的源泉。在这一模块,从分布式系统设计的视角出发,抽象和归纳出这些特性中体现出来的普遍方法,然后带着这些指导思想去逐一阐述 Kubernetes 项目关于编排、调度和作业管理的各项核心特性。“不识庐山真面目,只缘身在此山中”,希望这样一个与众不同的角度,能够给你以全新的启发。
-
Kubernetes 开源社区与生态:
“开源生态”永远都是容器技术和 Kubernetes 项目成功的关键。在这个模块,我会和你一起探讨,容器社区在开源软件工程指导下的演进之路;带你思考,如何同团队一起平衡内外部需求,让自己逐渐成为社区中不可或缺的一员。
容器技术入门篇
一、 从进程说开去
容器,就是一种沙盒技术。顾名思义,沙盒就是能够像一个集装箱一样,把应用“装”起来,这样一来应用与应用之间就有了边界而互不干扰。
“边界”的实现手段尤为重要。
假如,现在你要写一个计算加法的小程序,这个程序需要的输入来自于一个文件,计算完成后的结果则输出到另一个文件中。由于计算机只认识 0 和 1,所以无论用哪种语言编写这段代码,最后都需要通过某种方式翻译成二进制文件,才能在计算机操作系统中运行起来。而为了能够让这些代码正常运行,我们往往还要给它提供数据,比如我们这个加法程序所需要的输入文件。这些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”,也叫代码的可执行镜像(executable image)。
然后,我们就可以在计算机上运行这个“程序”了。首先,操作系统从“程序”中发现输入数据保存在一个文件中,所以这些数据就会被加载到内存中待命。同时,操作系统又读取到了计算加法的指令,这时,它就需要指示 CPU 完成加法操作。而 CPU 与内存协作进行加法计算,又会使用寄存器存放数值、内存堆栈保存执行的命令和变量。同时,计算机里还有被打开的文件,以及各种各样的 I/O 设备在不断地调用中修改自己的状态。就这样,一旦“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
像这样一个程序运行起来后的计算机执行环境的总和,就是我们今天的主角:进程。
进程:
- 静态表现: 安安静静地待在磁盘
- 动态表现: 计算机里的数据和状态的总和
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”
对于 Docker 等大多数 Linux 容器来说
Cgroups 技术是用来制造约束的主要手段Namespace 技术则是用来修改进程视图的主要方法。
$ docker run -it busybox /bin/sh
/ #
// -it 参数告诉了 Docker 项目在启动容器后,需要给我们分配一个文本输入 / 输出环境,也就是 TTY,跟容器的标准输入相关联,这样我们就可以和这个 Docker 容器进行交互了。
// /bin/sh 就是我们要在 Docker 容器里运行的程序
上面这条指令翻译成人类的语言就是:请帮我启动一个容器,在容器里执行 /bin/sh,并且给我分配一个命令行终端跟这个容器交互.
这样,你的mac OR Linux服务器变成一个宿主机, 在宿主机上跑着一个容器
在容器里执行ps命令:
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
7 root 0:00 ps
可以看到,我们在 Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
本来,每当我们在宿主机上运行了一个 /bin/sh 程序,操作系统都会给它分配一个进程编号,比如 PID=100。这个编号是进程的唯一标识,就像员工的工牌一样。所以 PID=100,可以粗略地理解为这个 /bin/sh 是我们公司里的第 100 号员工,而第 1 号员工就自然是比尔 · 盖茨这样统领全局的人物。而现在,我们要通过 Docker 把这个 /bin/sh 程序运行在一个容器当中。这时候,Docker 就会在这个第 100 号员工入职时给他施一个“障眼法”,让他永远看不到前面的其他 99 个员工,更看不到比尔 · 盖茨。这样,他就会错误地以为自己就是公司里的第 1 号员工。
这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号,比如 PID=1。可实际上,他们在宿主机的操作系统里,还是原来的第 100 号进程。
Linux Namespace
这种技术,就是 Linux 里面的 Namespace 机制。而 Namespace 的使用方式也非常有意思:它其实只是 Linux 创建新进程的一个可选参数。我们知道,在 Linux 系统中创建进程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
// 这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
// 可以在参数中指定 CLONE_NEWPID 参数
通过CLONE_NEWPID参数新创建的进程会“看到”一个全新的进程空间,它的PID为1。当然,我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID Namespace 里的具体情况
除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作
eg:
Mount Namespace用于让被隔离进程只看到当前Namespace里的挂载点信息Network Namespace用于让被隔离进程看到当前Namespace里的网络设备和配置
Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
所以说,容器,其实是一种特殊的进程而已。
总结:
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别
二、 隔离与限制
有利就有弊,基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底
既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核
尽管你可以在容器里通过 Mount Namespace 单独挂载其他不同版本的操作系统文件,比如 CentOS 或者 Ubuntu,但这并不能改变共享宿主机内核的事实。这意味着,如果你要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本的 Linux 容器,都是行不通的
在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间
如果你的容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改,这显然不符合用户的预期。相比于在虚拟机里面可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的一个问题
在第一部分中的PID Namespace例子中, 虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/misc type cgroup (rw,nosuid,nodev,noexec,relatime,misc)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu/
cgroup.clone_children cpuacct.usage_percpu_sys cpu.latency onion/
cgroup.id cpuacct.usage_percpu_user cpu.offline release_agent
cgroup.procs cpuacct.usage_sys cpu.pressure sap2000/
cgroup.sane_behavior cpuacct.usage_user cpu.rt_period_us sap2000exec/
cpuacct.stat cpu.bt_shares cpu.rt_runtime_us system.slice/
cpuacct.uptime cpu.bt_suppress_percent cpu.shares tagent/
cpuacct.usage cpu.cfs_burst_us cpu.stat tasks
cpuacct.usage_all cpu.cfs_period_us docker/ user.slice/
cpuacct.usage_percpu cpu.cfs_quota_us notify_on_release
如果熟悉 Linux CPU 管理的话,你就会在它的输出里注意到 cfs_period 和 cfs_quota 这样的关键词。这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间
配置上述的限制: 在对应的子系统下面创建一个目录, 这个目录被称为一个“控制组”。 创建后就可以发现操作系统在新建目录下自动生成该子系统对应的资源限制文件
[root@host /sys/fs/cgroup/cpu]# mkdir container
[root@host /sys/fs/cgroup/cpu]# ls container/
cgroup.clone_children cpuacct.uptime cpu.bt_shares cpu.pressure
cgroup.id cpuacct.usage cpu.bt_suppress_percent cpu.quota_aware
cgroup.priority cpuacct.usage_all cpu.cfs_burst_us cpu.rt_period_us
cgroup.procs cpuacct.usage_percpu cpu.cfs_period_us cpu.rt_runtime_us
cpuacct.mbuf cpuacct.usage_percpu_sys cpu.cfs_quota_us cpu.shares
cpuacct.sli cpuacct.usage_percpu_user cpu.ht_sensi_type cpu.stat
cpuacct.sli_max cpuacct.usage_sys cpu.latency notify_on_release
cpuacct.stat cpuacct.usage_user cpu.offline tasks
执行一个死循环脚本, 将cpu吃到100%,其对应PID进程号为26760
# while : ; do : ; done &
[1] 26760
# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
26760 root 20 0 123304 3184 1476 R 100.0 0.0 0:22.13 bash
可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us)
[root@host /sys/fs/cgroup/cpu]# cat container/cpu.cfs_quota_us
-1
[root@host /sys/fs/cgroup/cpu]# cat container/cpu.cfs_period_us
100000
向 container 组里的 cfs_quota 文件写入 20 ms(20000 us)。它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽
[root@host /sys/fs/cgroup/cpu]# echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
[root@host /sys/fs/cgroup/cpu]# cat container/cpu.cfs_quota_us
20000
接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了(这里不需要额外执行死循环脚本,直接top查看26760进程即可)
[root@host /sys/fs/cgroup/cpu/container]# echo 26760 > /sys/fs/cgroup/cpu/container/tasks
# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
26760 root 20 0 123304 3184 1476 R 20.0 0.0 5:55.13 bash
除 CPU 子系统外,Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了
[root@host /sys/fs/cgroup/cpu]# docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
root@e8c88e839a79:/# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
root@e8c88e839a79:/# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
20000
总结:
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。容器是一个“单进程”模型
三、 深入理解容器镜像
Namespace 的作用是“隔离”,它让应用进程只能看到该 Namespace 内的“世界”;而 Cgroups 的作用是“限制”,它给这个“世界”围上了一圈看不见的墙。这么一折腾,进程就真的被“装”在了一个与世隔绝的房间里,而这些房间就是 PaaS 项目赖以生存的应用“沙盒”。 但是, 这个房间四周虽然有了墙,但是如果容器进程低头一看地面,又是怎样一副景象呢。
容器里的进程看到的文件系统又是什么样子的呢?
Mount Namespace
“左耳朵耗子”叔在多年前写的一篇关于 Docker 基础知识的博客里,曾经介绍过一段小程序。这段小程序的作用是,在创建子进程时开启指定的 Namespace。
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | SIGCHLD , NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
这段代码的功能非常简单:在 main 函数里,我们通过 clone() 系统调用创建了一个新的子进程 container_main,并且声明要为它启用 Mount Namespace(即:CLONE_NEWNS 标志)。而这个子进程执行的,是一个“/bin/bash”程序,也就是一个 shell。所以这个 shell 就运行在了 Mount Namespace 的隔离环境中。
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
这样,我们就进入了这个“容器”当中。可是,如果在“容器”里执行一下 ls 指令的话,我们就会发现一个有趣的现象: /tmp 目录下的内容跟宿主机的内容是一样的。
$ ls /tmp
# 你会看到好多宿主机的文件
即使开启了 Mount Namespace,容器进程看到的文件系统也跟宿主机完全一样
原因:Mount Namespace 修改的,是容器进程对文件系统“挂载点”的认知。这也就意味着,只有在“挂载”这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
这时,你可能已经想到了一个解决办法:创建新进程时,除了声明要启用 Mount Namespace 之外,我们还可以告诉容器进程,有哪些目录需要重新挂载,就比如这个 /tmp 目录。于是,我们在容器进程执行前可以添加一步重新挂载 /tmp 目录的操作:
int container_main(void* arg)
{
printf("Container - inside the container!\n");
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录
// mount("", "/", NULL, MS_PRIVATE, "");
mount("none", "/tmp", "tmpfs", 0, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
可以看到,在修改后的代码里,我在容器进程启动之前,加上了一句 mount(“none”, “/tmp”, “tmpfs”, 0, “”) 语句。就这样,我告诉了容器以 tmpfs(内存盘)格式,重新挂载了 /tmp 目录。
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
$ ls /tmp
可以看到,这次 /tmp 变成了一个空目录,这意味着重新挂载生效了。我们可以用 mount -l 检查一下
$ mount -l | grep tmpfs
none on /tmp type tmpfs (rw,relatime)
可以看到,容器里的 /tmp 目录是以 tmpfs 方式单独挂载的。
更重要的是,因为我们创建的新进程启用了 Mount Namespace,所以这次重新挂载的操作,只在容器进程的 Mount Namespace 中有效。如果在宿主机上用 mount -l 来检查一下这个挂载,你会发现它是不存在的:
# 在宿主机上
$ mount -l | grep tmpfs
这就是 Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
可是,作为一个普通用户,我们希望的是一个更友好的情况:每当创建一个新容器时,我希望容器进程看到的文件系统就是一个独立的隔离环境,而不是继承自宿主机的文件系统。怎么才能做到这一点呢?不难想到,我们可以在容器进程启动之前重新挂载它的整个根目录“/”。而由于 Mount Namespace 的存在,这个挂载对宿主机不可见,所以容器进程就可以在里面随便折腾了。
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在 shell 中方便地完成这个工作。顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的位置。它的用法也非常简单。
假设,我们现在有一个 $HOME/test 目录,想要把它作为一个 /bin/bash 进程的根目录。
创建一个 test 目录和几个 lib 文件夹;把 bash 命令拷贝到 test 目录对应的 bin 路径下;接下来,把 bash 命令需要的所有 so 文件,也拷贝到 test 目录对应的 lib 路径下。找到 so 文件可以用 ldd 命令;最后,执行 chroot 命令,告诉操作系统,我们将使用 $HOME/test 目录作为 /bin/bash 进程的根目录
$ mkdir -p $HOME/test
$ mkdir -p $HOME/test/{bin,lib64,lib}
$ cd $T
$ cp -v /bin/{bash,ls} $HOME/test/bin
$ T=$HOME/test
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${T}${i}"; done
$ chroot $HOME/test /bin/bash
这时,你如果执行 “ls /”,就会看到,它返回的都是 $HOME/test 目录下面的内容,而不是宿主机的内容。更重要的是,对于被 chroot 的进程来说,它并不会感受到自己的根目录已经被“修改”成 $HOME/test 了。
这种视图被修改的原理跟 Linux Namespace 很类似。
实际上,Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
rootfs
所以,一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程
- 启用 Linux Namespace 配置
- 设置指定的 Cgroups 参数
- 切换进程的根目录(Change Root)
需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像
所以说,rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”。
实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核
正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性
由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
事实上,对于大多数开发者而言,他们对应用依赖的理解,一直局限在编程语言层面。比如 Golang 的 Godeps.json。但实际上,一个一直以来很容易被忽视的事实是,对一个应用来说,操作系统本身才是它运行所需要的最完整的“依赖库”。
有了容器镜像“打包操作系统”的能力,这个最基础的依赖环境也终于变成了应用沙盒的一部分。这就赋予了容器所谓的一致性:无论在本地、云端,还是在一台任何地方的机器上,用户只需要解压打包好的容器镜像,那么这个应用运行所需要的完整的执行环境就被重现出来了。
一种比较直观的解决办法是,我在制作 rootfs 的时候,每做一步“有意义”的操作,就保存一个 rootfs 出来,这样其他同事就可以按需求去用他需要的 rootfs 了。
但是,这个解决办法并不具备推广性。原因在于,一旦你的同事们修改了这个 rootfs,新旧两个 rootfs 之间就没有任何关系了。这样做的结果就是极度的碎片化。
那么,既然这些修改都基于一个旧的 rootfs,我们能不能以增量的方式去做这些修改呢?这样做的好处是,所有人都只需要维护相对于 base rootfs 修改的增量内容,而不是每次修改都制造一个“fork”。
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union File System)的能力。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。比如,我现在有两个目录 A 和 B,它们分别有两个文件:
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
使用联合挂载的方式,将这两个目录挂载到一个公共的目录 C 上:
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
$ tree ./C
./C
├── a
├── b
└── x
可以看到,在这个合并后的目录 C 里,有 a、b、x 三个文件,并且 x 文件只有一份。这,就是“合并”的含义。此外,如果你在目录 C 里对 a、b、x 文件做修改,这些修改也会在对应的目录 A、B 中生效。
在 Docker 项目中,又是如何使用这种 Union File System 的呢?————AuFS
AuFS 的全称是 Another UnionFS,后改名为 Alternative UnionFS,再后来干脆改名叫作 Advance UnionFS
对于 AuFS 来说,它最关键的目录结构在 /var/lib/docker 路径下的 diff 目录:
/var/lib/docker/aufs/diff/<layer_id>
而这个目录的作用,我们不妨通过一个具体例子来看一下。
现在,我们启动一个容器
$ docker run -d ubuntu:latest sleep 3600
// 从 Docker Hub 上拉取一个 Ubuntu 镜像到本地
// 这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
这个挂载点就是 /var/lib/docker/aufs/mnt/,比如:
/var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
// 不出意外的,这个目录里面正是一个完整的 Ubuntu 操作系统
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
那么,前面提到的五个镜像层,又是如何被联合挂载成这样一个完整的 Ubuntu 文件系统的呢?
这个信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面。
首先,通过查看 AuFS 的挂载信息,我们可以找到这个目录对应的 AuFS 的内部 ID(也叫:si)
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba,dio,dirperm1 0 0
即,si=972c6d361e6b32ba。
然后使用这个 ID,你就可以在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
从这些信息里,我们可以看到,镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面。
而且,从这个结构可以看出来,这个容器的 rootfs 由如下图所示的三部分组成:
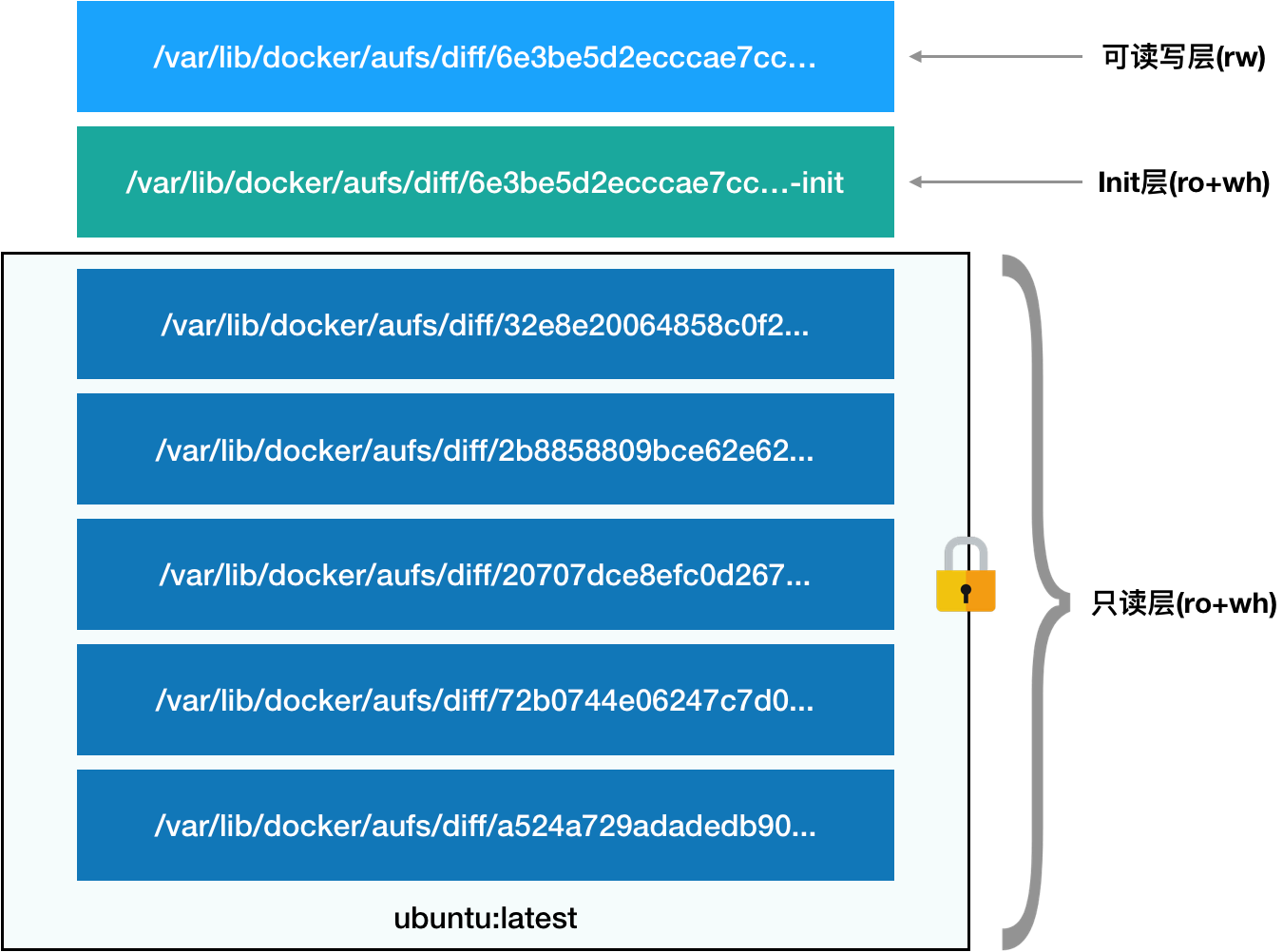
第一部分,只读层。
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout,至于什么是 whiteout,我下面马上会讲到)。
这时,我们可以分别查看一下这些层的内容:
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
etc sbin usr var
$ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
run
$ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
可以看到,这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
第二部分,可读写层。
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处。
第三部分,Init 层。
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
总结:
通过结合使用 Mount Namespace 和 rootfs,容器就能够为进程构建出一个完善的文件系统隔离环境。当然,这个功能的实现还必须感谢 chroot 和 pivot_root 这两个系统调用切换进程根目录的能力
在 rootfs 的基础上,Docker 公司创新性地提出了使用多个增量 rootfs 联合挂载一个完整 rootfs 的方案,这就是容器镜像中“层”的概念
四、 重新认识Docker容器
Dockerfile
将一个应用容器化的第一步,是制作容器镜像。
相较于之前介绍的制作 rootfs 的过程,Docker 提供了一种更便捷的方式,叫作 Dockerfile。
# 使用官方提供的Python开发镜像作为基础镜像
FROM python:2.7-slim
# 将工作目录切换为/app
WORKDIR /app
# 将当前目录下的所有内容复制到/app下
ADD . /app
# 使用pip命令安装这个应用所需要的依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 允许外界访问容器的80端口
EXPOSE 80
# 设置环境变量
ENV NAME World
# 设置容器进程为:python app.py,即:这个Python应用的启动命令
CMD ["python", "app.py"]
通过这个文件的内容,你可以看到 Dockerfile 的设计思想,是使用一些标准的原语(即大写高亮的词语),描述要构建的 Docker 镜像。并且这些原语,都是按顺序处理的
- FROM:指定官方维护的基础镜像,从而免去按照python等语言环境的操作
- WORKDIR:Dockerfile后面的操作都以这一句制定的/app目录作为当前目录
- CMD:Dockerfile指定python app.py为这个容器的进程。 等价于
docker run <image> python app.py - 默认情况下,Docker会提供一个隐含的ENTRYPOINT,即: /bin/sh -c
- 实际上运行在容器里的完整进程是
/bin/sh -c "python app.py",即CMD的内容是ENTRYPOINT的参数
- 实际上运行在容器里的完整进程是
统一称Docker容器的启动进程为ENTRYPOINT,而不是CMD
需要注意的是,Dockerfile 中的每个原语执行后,都会生成一个对应的镜像层。即使原语本身并没有明显地修改文件的操作(比如,ENV 原语),它对应的层也会存在。只不过在外界看来,这个层是空的。
docker exec如何进入到容器中
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d
25686
$ ls -l /proc/25686/ns
total 0
lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]
可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。
有了这样一个可以“hold 住”所有 Linux Namespace 的文件,我们就可以对 Namespace 做一些很有意义事情了,比如:加入到一个已经存在的 Namespace 当中。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。—— 依赖setns()的Linux系统调用
Volume
Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作
当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
注意:这里提到的"容器进程",是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程
在一个正确的时机,进行一次绑定挂载,Docker 就可以成功地将一个宿主机上的目录或文件,不动声色地挂载到容器中
在docker容器中 /test目录下 创建一个demo.txt文件
宿主机:
-
/var/lib/docker/volumes/{volume_id}/_data/ 目录下存在demo.txt
-
/var/lib/docker/aufs/mnt/{可读写层id}/ 可看到/test目录,但内容为空
总结:
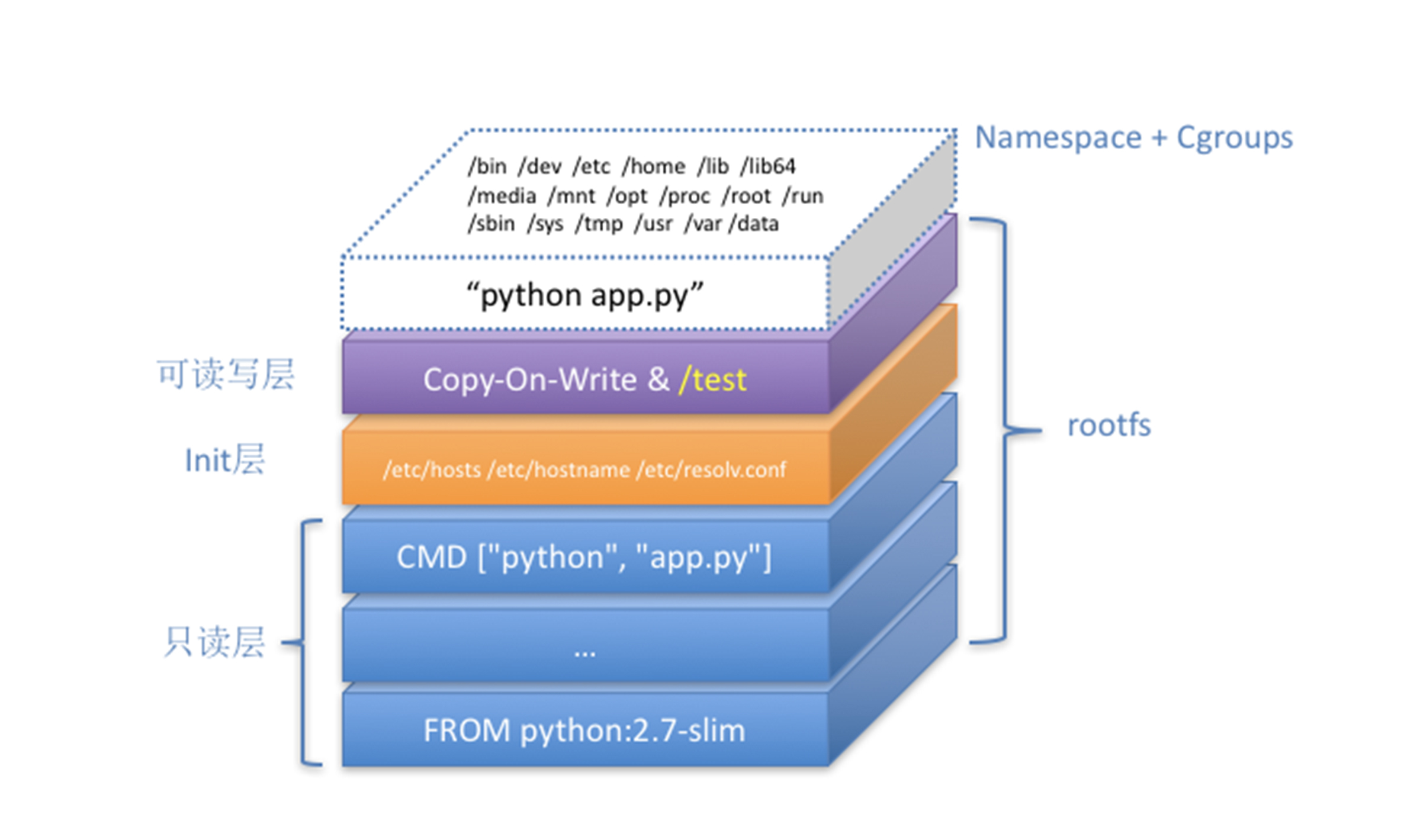
- 容器进程运行在由
Linux Namespace、Cgroups构成的隔离环境中 - 运行所需要的各种文件以及操作系统文件,则由多个联合挂载在一起的
rootfs层提供- 只读层: 基础镜像的资源
- Init层: 被临时修改过的/etc/hosts等文件
- 可读写层:以Copy-on-Write方式存放任何对只读层的修改,容器声明的
Volume的挂载点存在于此
Kubernetes的本质
一个容器,实际上是一个由Linux Namespace、Linux Cgroups和rootfs三种技术构建出来的进程的隔离环境
- 静态视图:容器镜像(Container Image),一组联合挂载在/var/lib/docker/aufs/mnt上的rootfs
- 动态视图:容器运行时(Container Runtime),一个由Namespace+Cgroups构成的隔离环境
Kubernetes项目要解决的问题是什么
编排?调度?容器云?还是集群管理?提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力?
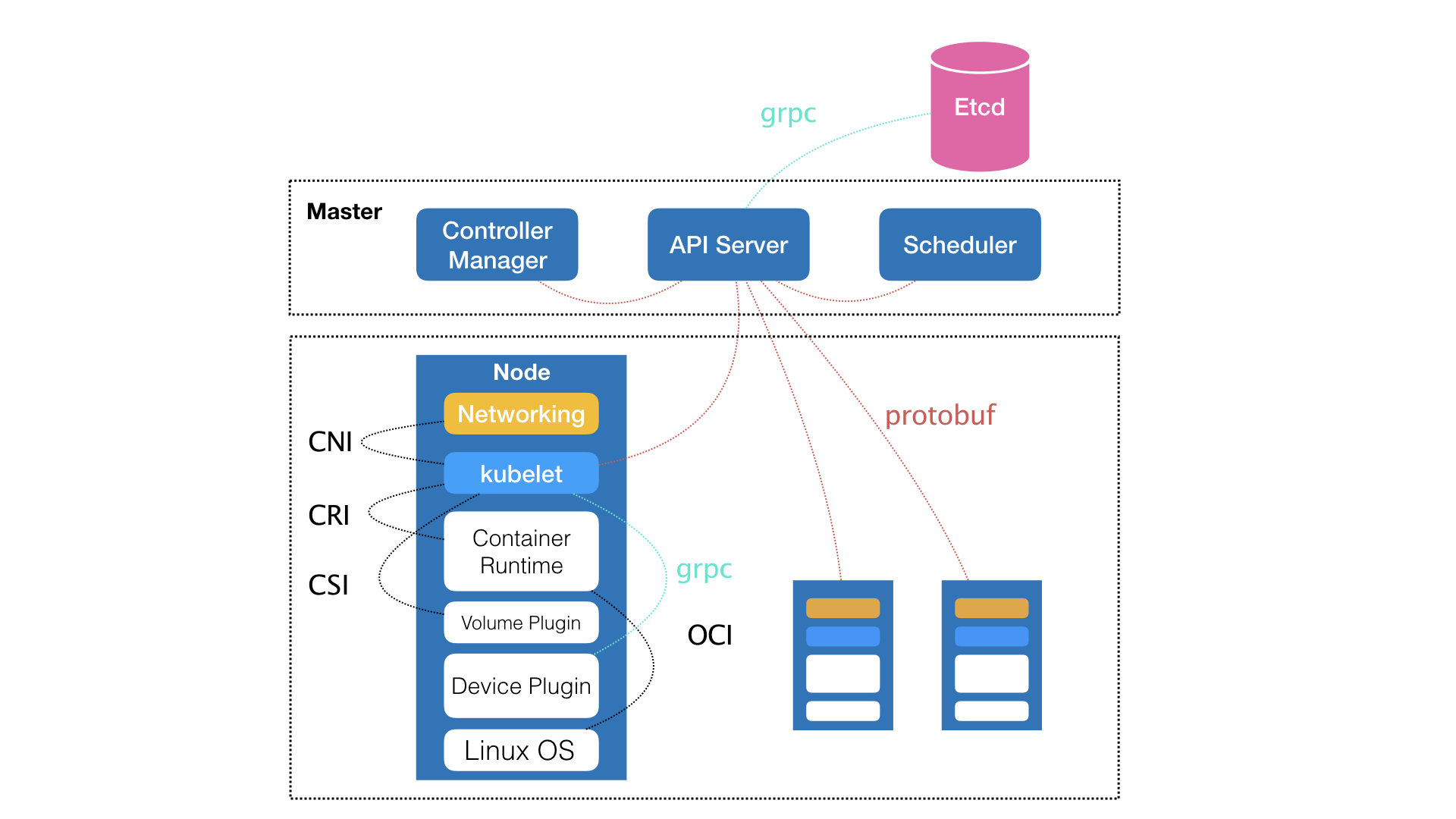
- Kubernetes项目的架构,由Master和Node两种节点组成,分别对应着控制节点和计算节点
- Master控制节点,由三个紧密协作的独立组件组合而成
- kube-apiserver: 负责API服务
- kube-scheduler:负责调度
- kube-controller-manager:负责容器编排
- 整个集群的持久化数据,则由kube-apiserver处理后保存在Etcd中
- Node计算节点
- kubelet:负责同容器运行时(比如docker项目)打交道
- CRI(Cotainer Runtime Interface)
- 是同容器运行时交互的依赖
- 接口定义了容器运行时的各项核心操作,比如启动一个容器需要的所有参数
- 通过OCI(Open Container Initiative)规范同底层的Linux操作系统进行交互,即把CRI请求翻译成对Linux操作系统的调用(操作Linux Namespace和Cgroupsdeng)
- Device Plugin插件
- 通过gRPC协议进行交互
- 是用于管理GPU等宿主机物理设备的主要组件
- 进行机器学习训练、高性能作业支持等工作必须关注的功能
- CNI(Container Networking Interface)
- 调用网络插件为容器配置网络
- CSI(Container Storage Interface)
- 调用存储插件为容器作持久化存储
- CRI(Cotainer Runtime Interface)
- kubelet:负责同容器运行时(比如docker项目)打交道
Borg对于Kubernetes项目的指导作用的体现之处——Master节点
Borg 系统,一直以来都被誉为 Google 公司内部最强大的“秘密武器”。Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层
虽然在 Master 节点的实现细节上 Borg 项目与 Kubernetes 项目不尽相同,但它们的出发点却高度一致,即:如何编排、管理、调度用户提交的作业
Kubernetes设计理念
从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地
在常规环境下,这些应用往往会被直接部署在同一台机器上,通过 Localhost 通信,通过本地磁盘目录交换文件。而在 Kubernetes 项目中,这些容器则会被划分为一个“Pod”,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。
而对于另外一种更为常见的需求,比如 Web 应用与数据库之间的访问关系,Kubernetes 项目则提供了一种叫作“Service”的服务。像这样的两个应用,往往故意不部署在同一台机器上,这样即使 Web 应用所在的机器宕机了,数据库也完全不受影响。可是,我们知道,对于一个容器来说,它的 IP 地址等信息不是固定的,那么 Web 应用又怎么找到数据库容器的 Pod 呢?
Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个Service 服务的主要作用,就是 作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址
Kubernetes 项目核心功能的“全景图”
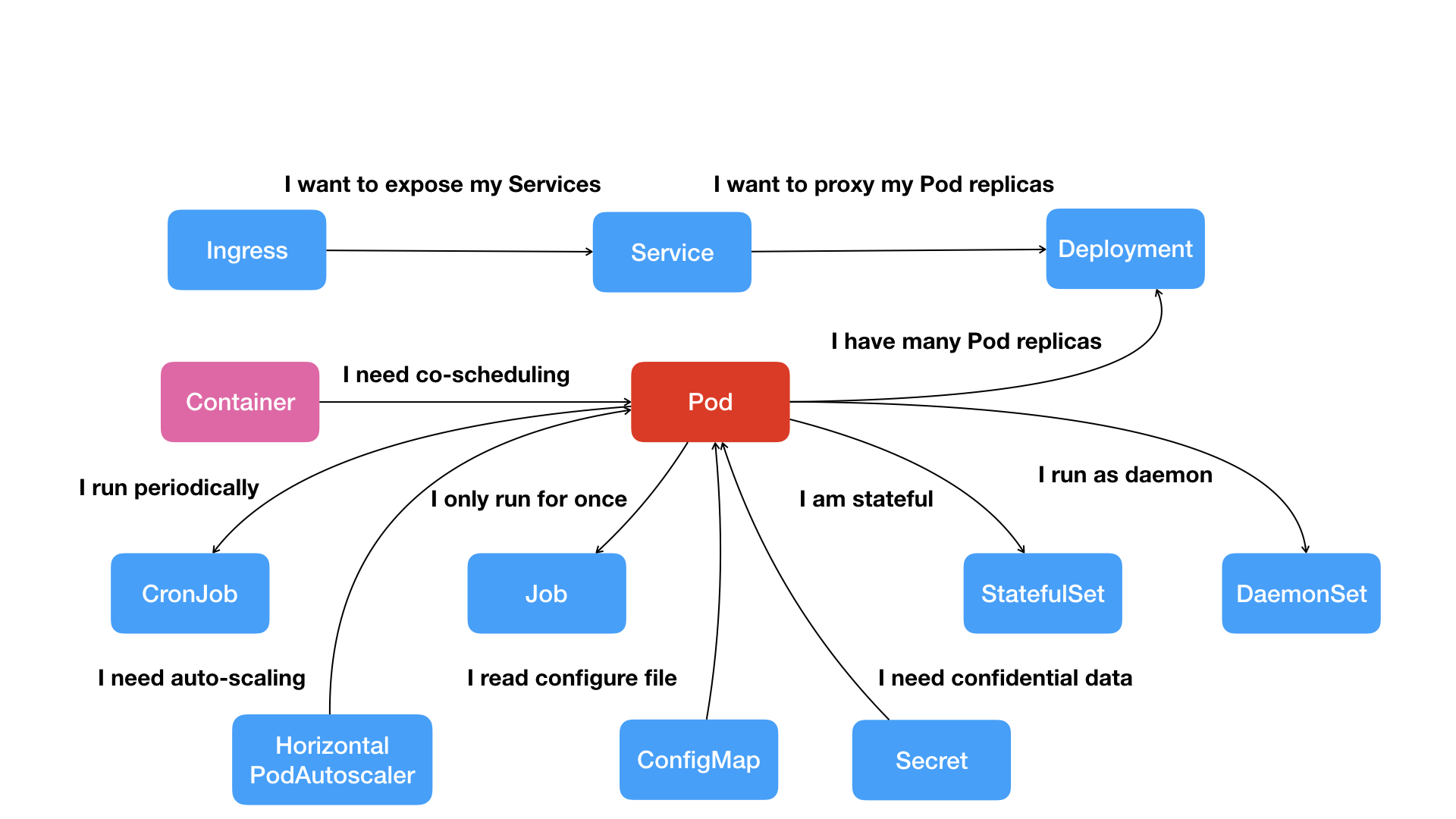
- Pod: 容器间“紧密协作”关系
- Deployment: 多实例管理器,一次启动多个应用的实例
- Service: 通过一个固定的IP地址和端口以负载均衡的方式访问一组相同的Pod
- Secret:是一个保存在Etcd里的键值对数据
- 将Credential(数据库的用户名和密码)信息以Secret方式存在Etcd中
- Kubernetes会在指定Pod启动时,将Secret的数据以Volume方式挂载到容器
- 解决问题:两个不同Pod之间不仅有“访问关系”,还要求在发起时加上授权信息。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素
- 基于Pod改进后的对象
- Job:描述一次性运行的Pod(比如大数据任务)
- DaemonSet:描述每个宿主机上必须且只能运行一个副本的守护进程服务
- CronJob:描述定时任务
在Kubernetes项目中,推崇的使用方法是
- 通过一个“编排对象”(Pod、Job、CronJob等)来描述你试图管理的应用
- 为它定义一些“服务对象”,比如Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)
- 这些对象会负责具体的平台级功能
这种使用方法,就是所谓的**“声明式 API”**。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。
Kubernetes项目如何启动一个容器化任务
需求:有一个Nginx容器镜像,要求平台运行两个完全相同的Nginx副本,以负载均衡的方式共同对外提供服务
个人DIY:两台虚拟机分别安装两个Nginx,使用keepalived为两个虚拟机做一个虚拟ip
使用Kubernetes项目:编写一个Yaml文件——nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在上面这个 YAML 文件中,我们定义了一个 Deployment 对象,它的主体部分(spec.template 部分)是一个使用 Nginx 镜像的 Pod,而这个 Pod 的副本数是 2(replicas=2)
$ kubectl create -f nginx-deployment.yaml
总结:
Kubernetes 项目的架构使用“声明式 API”来描述容器化业务和容器间关系
调度功能:把一个容器,按照某种规则,放置在某个最佳节点上运行起来
编排功能:按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系
Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具