一、作者
Xiaoyi Bao、Wang Zhongqing、 Xiaotong Jiang、 Rong Xiao、Shoushan Li
Natural Language Processing Lab, Soochow University, Suzhou, China
Alibaba Group, Hangzhou, China
二、背景
作为细粒度的情感分析任务,ABSA 涉及了多个基本情感元素,包括方面项(aspect term)、意见项(opinion term)、方面类别(aspect category)和情感极性(sentiment polarity)。现有的 ABSA 研究主要集中在情感元素的识别上,例如方面术语的提取以及情感极性分类,ABSA 任务也往往会被表示为序列级或 token 级的分类问题。然而,因为这些模型的整体预测能力取决于每一步的准确性,因此它们会受到错误传播(error propagation)的严重影响。此外,这些方法由于在训练时将标签简单视为数字索引,往往会忽视标签语义。
因此,一些研究开始借助于联合的生成式方法来解决 ABSA 问题,这些模型虽然能够通过将自然语言标签编码到目标输出中来利用丰富的标签语义,但它们无法有效捕获方面词和意见词之间的语义结构。
三、创新点
对于上述生成式方法无法捕获语义结构的问题,作者认为可以通过显式构造语义信息的结构表示来进行解决,该表示将方面词和意见词视为节点,并在节点之间建立结构关系。
作者由此提出了一个意见树生成模型,旨在针对给定的句子联合检测树中的所有情感元素。意见树可以看作是一种语义表示,使用有根有向无环图来对句子进行建模,能够有效突出方面词和意见词之间的语义联系。

四、具体实现
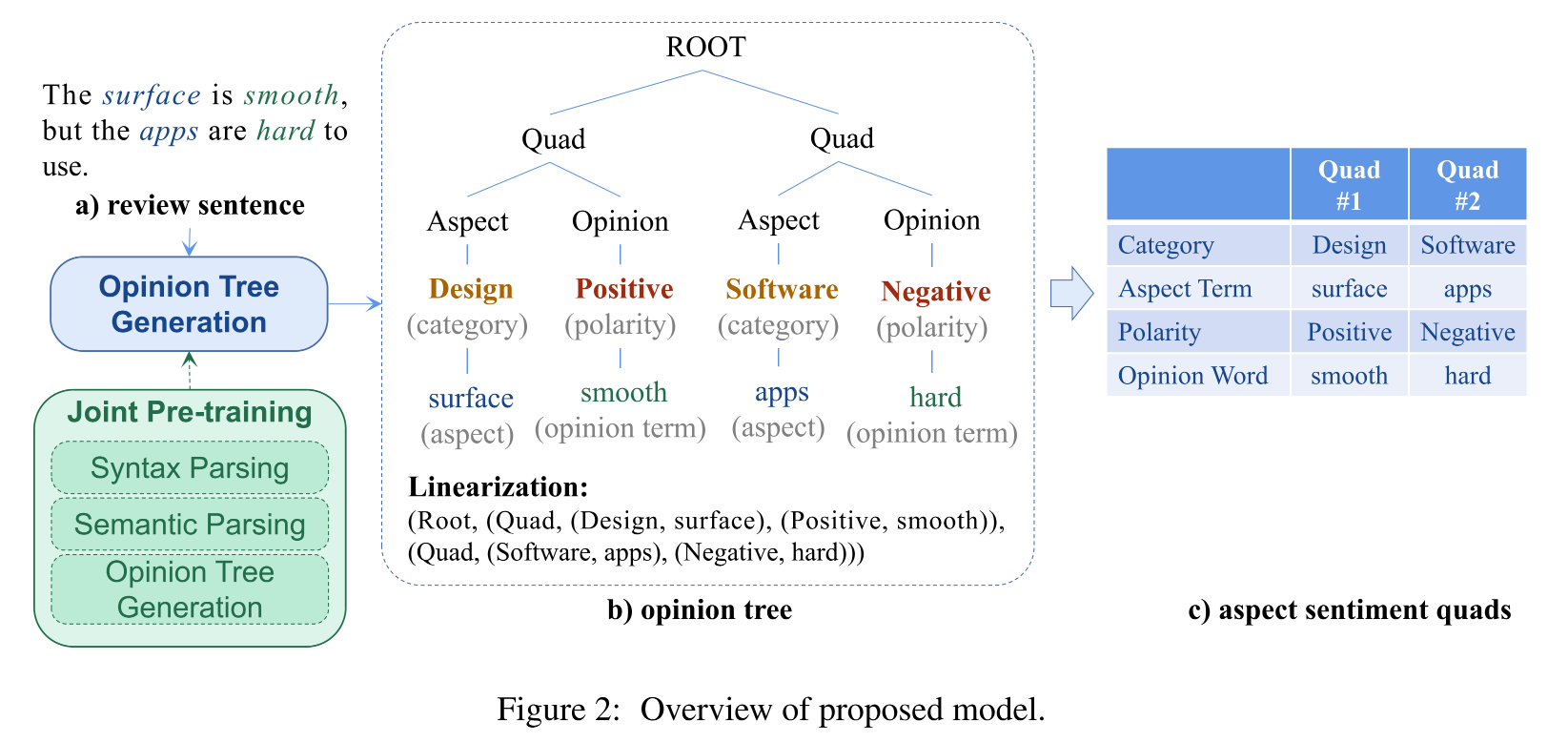
1.意见树的构造和线性化
意见树使用有根有向无环图来对句子进行建模,对于一个句子,可以按照如下方式将方面情感四元组(aspect sentiment quads)转换为一棵意见树。
- 首先创建一个 quda 节点来表示方面情感四元组,所有的 quda 节点都会与一个虚拟根节点(ROOT)相连。
- aspect 节点和 opinion 节点会与相应的 quda 节点进行连接。
- 方面类别会连接到 aspect 节点上,情感极性会与 opinion 节点相连。
- 句子中的方面词和意见词会被作为叶子节点连接到方面类别节点和情感极性节点上。
对于一棵意见树,通过深度优先遍历即可将其转化为 token 序列,并通过 "(" 和 ")" 来标识结构。
2.树生成模型
树生成模型用于从句子中生成线性化的意见树,由于线性化后的意见树中的所有标记仍然为自然语言单词,所以作者采用 T5模型来作为树生成模型,这样就能够直接对生成的文本进行复用。
总的来说,对于给定的输入 token 序列 x = x 1 , … , x ∣ x ∣ x = x_1, \dots, x_{|x|} x=x1,…,x∣x∣,树生成模型最终能生成线性表示的意见树 y = y 1 , … , y ∣ y ∣ y = y_1, \dots, y_{|y|} y=y1,…,y∣y∣。具体来说,模型编码器首先会通过输入序列计算出句子的隐藏向量表示 H = h 1 , … , h ∣ x ∣ H = h_1, \dots, h_{|x|} H=h1,…,h∣x∣,计算过程可以表示为 H = E n c o d e r ( x 1 , … , x ∣ x ∣ ) H = \mathrm{Encoder}(x_1, \dots, x_{|x|}) H=Encoder(x1,…,x∣x∣),其中编码器的每一层都是一个具有多头注意力机制的 transformer 块。编码结束后,解码器会基于 H H H 来逐个 token 地预测输出结构,预测过程可以表示为 y i , h i d = D e c o d e r ( [ H ; h 1 d , … , h i − 1 d ] , y i − 1 ) y_i, h_i^d = \mathrm{Decoder}([H; h_1^d, \dots, h_{i - 1}^d], y_{i - 1}) yi,hid=Decoder([H;h1d,…,hi−1d],yi−1),其中解码器的每一层都是包含解码器状态 h i d h_i^d hid 的自注意力和编码器状态 H H H 的交叉注意力的 transformer 块。整个输出序列的条件概率 p ( y ∣ x ) p(y|x) p(y∣x) 则会基于每一步的概率逐步生成,生成过程表示为 p ( y ∣ x ) = ∏ i = 1 ∣ y ∣ p ( y i ∣ y < i , x ) p(y|x) = \displaystyle{\prod_{i = 1}^{|y|}}p(y_i|y_{<i}, x) p(y∣x)=i=1∏∣y∣p(yi∣y<i,x),其中 y < i = y 1 , … , y i − 1 y_{<i} = y_1, \dots, y_{i - 1} y<i=y1,…,yi−1,而 p ( y i ∣ y < i , x ) p(y_i|y_{<i}, x) p(yi∣y<i,x) 则表示通过 s o f t m a x \mathrm{softmax} softmax 正则化后的目标词汇表 V V V 概率。
3.通过意见约束进行解码
在树生成模型的解码阶段,目标词汇表
V
V
V 的生成是通过基于字典树的约束解码算法来实现的。具体来说,在约束解码的过程中, **意见模式知识(opinion schema knowledge)会被作为提示注入到解码器中,用来帮助解码器根据当前的生成状态(generated state)**来选择和修剪候选词汇表
V
t
V_t
Vt。其中候选词汇表可以分为三类:1.意见模式,包括预定义的种类和极性标签;2.意见字符串,包括原始输入中的方面词和意见词;3.结构指示器,包括用来结合意见模式和意见字符串的 "(" 和 ")"。
这里需要注意的是,由于字典树的特殊结构,在生成步骤
t
t
t,候选词汇表
V
t
V_t
Vt 是最后生成的节点的子节点,而非父节点。例如,在生成 "("的生成步骤,候选词表
V
t
V_t
Vt 为 {"(",")"},因此可以将解码过程看作是对字典树中某一节点子树的搜索。