文章目录
- Tokenizer
- 分词
- 1.单词分词法
- 2.单字符分词法
- 3.子词分词法
- BPE(字节对编码,Byte Pair Encoding)
- WordPiece
- Unigram Language Model(ULM)
- embedding的本质
- 推理时的一些指标
- 参考链接
Tokenizer
在使用模型前,都需要将sequence过一遍Tokenizer,进去的是word序列(句子级),出来的是number序列。事实上,HuggingFace的tokenizer总体上做了三件事情:
- 分词。将字符串分为一些
sub-word token string。再将token string映射到ID,并保留来回映射的mapping。从string映射到ID为tokenizer encode过程,从ID映射回token string 为tokenizer decode过程。映射方法有很多,如BERT用的是WordPiece,GPT-2和RoERTa用的是BPE。 - 扩展词汇表。部分
tokenizer会用一种统一的方法将训练语料中出现的但是词汇表中本来没有的token加入词汇表。 - 识别并处理特殊token。特殊token包括[MASK],等。
tokenzier会将它们加入词汇表中,并且保证它们在模型中不被切成sub-word,而是完整保留。
分词
从本质来说,文本数据整体上先是文档集合,然后是每一篇文档,然后是每一个段落,然后是每一个句子,然后是每一个短语,然后是每一个词,然后是每一个子词,最后是每一个字符。
不同的分词粒度,会导致分词的结果不同,当然也就影响了网络最终的输出结果。下面我们一一介绍。
1.单词分词法
最直观的分词是单词级分词法。单词分词法将一个word作为最小单元,也就是根据空格或者标点分词。
例如Today is Sunday.使用word-base来进行分词会变成['Today','is','Sunday','.']。这种分词方法简单容易理解,每个word都分配一个ID,则所需要的Vocabulary根据语料大小而不同,而且这种分词方式,会将两个本身意思一致的词分成两个毫不相同的ID,例如:cat,cats。
2.单字符分词法
最细粒度的分词方法是单字符分词法(character-base)。它会穷举所有出现的字符,所以是最完整的。在上面的例子中,单字符分词法会生成['T','o','d','a','y',...,'a','y','.']。
这种分词方式会导致Vocabulary相对小的多,但分词后的每个字符是毫无意义的,而且输出长度变长不少,只有组装后才有意义。这种分词在模型的初始character embedding是毫无意义的。英文中尤为明显,但是中文却是较为合理,中文中用此种方式较多。
3.子词分词法
这是一种最常用的,介于以上两种方法之间的分词方法,我们称为子词分词法。
子词分词法会把上面的句子分成最小可分的子词['To','day','is','S','un','day','.']。子词分词法有很多种取得最小可分子词的方法,例如BPE,WordPiece,SentencePiece,Unigram等等。
BPE(字节对编码,Byte Pair Encoding)
这是目前应用最多的分词方法,GPT以及Llama系列都在使用这种分词方法。具体过程请参考这篇博客。
完成了上述的BPE训练过程,我们就会得到一个词表(vocabulary),但是如何对输入语句进行编码(也就是BPE分词)呢?
- 将词表按照其中token的长度,从长到短进行排列;
例如排序好之后的词表为:
[“errrr</w>”, “tain</w>”, “moun”, “est</w>”, “high”, “the</w>”, “a</w>”]
- 对输入语句word-level的分词结果进行转化,例如输入语句为:
[“the</w>”, “highest</w>”, “mountain</w>”]
则转化为:
"the</w>" -> ["the</w>"]
"highest</w>" -> ["high", "est</w>"]
"mountain</w>" -> ["moun", "tain</w>"]
注:在编码过程结束后,如果输入语句中仍然有子字符串没被替但是词表中的所有token都已经迭代完毕,则将剩余的子词替换为特殊的token,如< unk >。原则上< unk >这个token出现的越少越好,我们也往往用< unk >的数量来评价一个tokenizer的好坏程度,这个token出现的越少,tokenizer的效果往往越好。
那么如何对网络的输出进行解码呢?将所有的tokens拼在一起即可,例如:
# 网络输出
["the</w>", "high", "est</w>", "moun", "tain</w>"]
# 解码序列
"the</w> highest</w> mountain</w>"
BPE是一种贪婪算法,因为它一直在搜索,知道遇到终止条件才会停止。
WordPiece
WordPiece是BERT使用的分词方法,可以看作是BPE的变种。两者很重要的区别是如何选择两个子词进行合并:WordPiece选择能够提升语言模型概率最大的相邻子词构造词表,但是BPE选择频数最高的相邻子词合并。大致的数学原理请参考这篇博客。
Unigram Language Model(ULM)
ULM与上面的两种分词方法相比,不同之处在于BPE和WordPiece算法的词表都是从小到大变化,属于增量法,而ULM则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词汇,直到满足限定条件。
embedding的本质
我们知道tokenization后就要进行embedding,它的表象是将one-hot的高维向量转为更密集的低维向量的过程,数学上就是对one-hot向量乘以一个矩阵。参考这篇博客,在其中说明了embedding矩阵的本质是什么。在其中指出,Embedding矩阵的本质是一个查找表,由于输入向量是one-hot的,embedding矩阵中有且仅有一行被激活。 博客中作者给出的图如下所示:
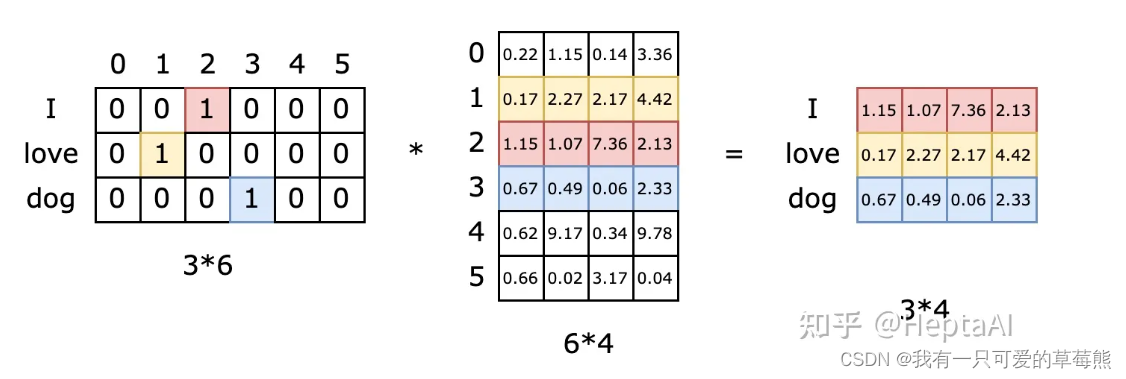
对于第一个单词"I",one-hot编码为[0,0,1,0,0],将其与embedding矩阵相乘,相当于去除embedding矩阵的第3行(index为2),其他的同理。每个单词会定位这个表中的每一行,而这一行就是这个单词学习到的在**嵌入空间(低维密集空间)**的语义。
推理时的一些指标
- First Token Latency(首字延迟):指的是当一批用户进入推理系统之后,用户完成prefill阶段(有关prefill的内容参考这篇博客)的过程需要花费多长时间,也称为首个词元生成时间(Time To First Token,简称TTFT)。这也是系统生成第一个字符所需要的响应时间,希望用户在系统上输入问题后得到回答的时间小于2~3秒。
- Throughput(吞吐量):当系统的负载达到最大的时候,单位时间内,能够执行多少个Decode,即生成多少个字符。
- 单个输出词元的生成时间(Time Per Output Token,简称TOPT):为每个用户生成一个输出词元所需要的时间。
- 时延:系统为用户生成完整相应的总时间。整体 相应时延可使用下面的计算方式:时延=TTFT + TPOT*待生成的词元数。
参考链接
- https://zhuanlan.zhihu.com/p/360290118
- https://martinlwx.github.io/zh-cn/the-bpe-tokenizer/
- https://zhuanlan.zhihu.com/p/631463712
- https://zhuanlan.zhihu.com/p/198964217
- https://www.zhihu.com/question/595001160/answer/3401487634
- https://zhuanlan.zhihu.com/p/663282469








![[AutoSar]BSW_Com03 DBC详解 (一)](https://img-blog.csdnimg.cn/direct/418aa8b67bd741d7b04ab4c22a2b5837.png)