内容安全
攻击可能只是一个点,防御需要全方面进行
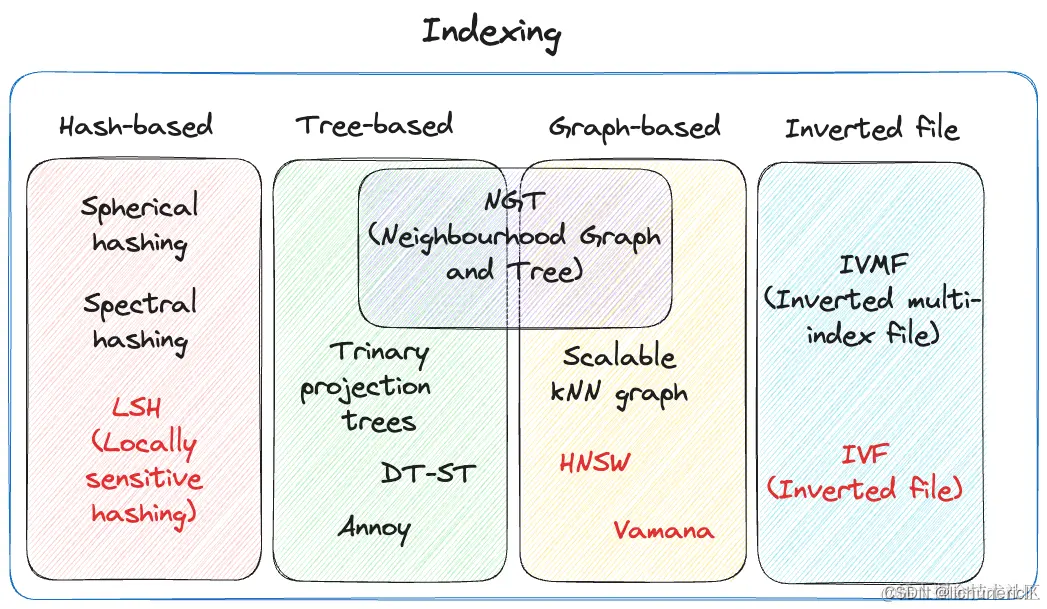
DFI和DPI技术 --- 深度检测技术

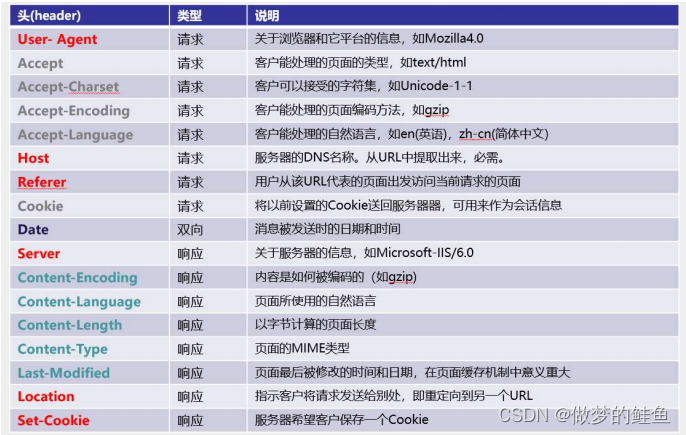
DPI --- 深度包检测技术 --- 主要针对完整的数据包(数据包分片,分段需要重组),之后对
数据包的内容进行识别。(应用层)

1. 基于“特征字”的检测技术 --- 最常用的识别手段,基于一些协议的字段来识别特征。

2. 基于应用网关的检测技术 --- 有些应用控制和数据传输是分离的,比如一些视频流。一开始需要TCP建立连接,协商参数,这一部分我们称为信令部分。之后,正式传输数据后,可能就通过UDP协议来传输,流量缺失可以识别的特征。所以,该技术就是基于前面信令部分的信息进行识别和控制。
3. 基于行为模式的检测技术 --- 比如我们需要拦截一些垃圾邮件,但是,从特征字中很难区分垃圾邮件和正常邮件,所以,我们可以基于行为来进行判断。比如,垃圾邮件可能存在高频,群发等特性,如果出现,我们可以将其认定为垃圾邮件,进行拦截,对IP进行封锁。
DFI --- 深度流检测技术 --- 一种基于流量行为的应用识别技术。这种方法比较适合判断P2P流
量。

结论:
1. DFI仅对流量进行分析,所以,只能对应用类型进行笼统的分类,无法识别出具体的应用;
DPI进行检测会更加精细和精准;
2. 如果数据包进行加密传输,则采用DPI方式将不能识别具体的应用,除非有解密手段;但是,加密并不会影响数据流本身的特征,所以,DFI的方式不受影响。
入侵防御(IPS)
IDS --- 侧重于风险管理的设备
IPS --- 侧重于风险控制的设备
IPS的优势:
1. 实时的阻断攻击;
2. 深层防护 --- 深入到应用层;
3. 全方位的防护 --- IPS可以针对各种常见威胁做出及时的防御,提供全方位的防护;
4. 内外兼防 --- 只要是通过设备的流量均可以进行检测,可以防止发自于内部的攻击。
5. 不断升级,精准防护
入侵检测的方法:
异常检测
误用检测
异常检测:
异常检测基于一个假定,即用户行为是可以预测的,遵循一致性模式的;
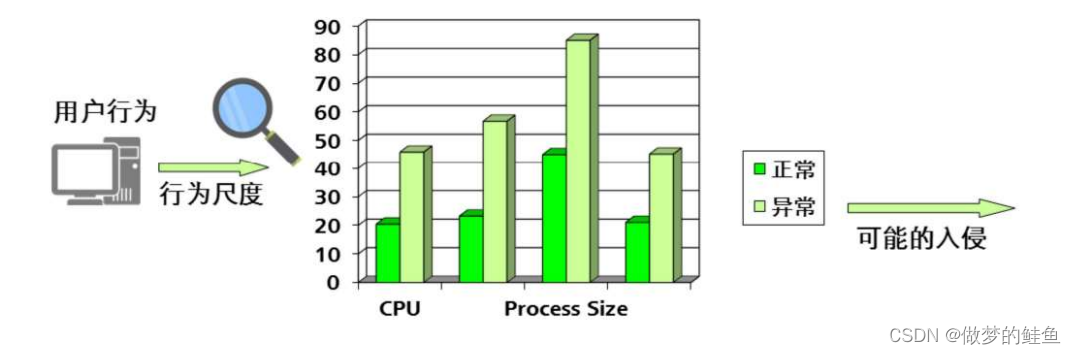
误用检测
误用检测其实就是创建了一个异常行为的特征库。我们将一些入侵行为记录下来,总结成
为特征,之后,检测流量和特征库进行对比,来发现威胁。

总结:
1. 在进行IPS模块检测之前,首先需要重组IP分片报文和TCP数据流; --- 增加检测的精准性
2. 在此之后需要进行应用协议的识别。这样做主要为了针对特定的应用进行对应精细的解码,并深入报文提取特征。
3. 最后,解析报文特征和
签名(特征库里的特征)
进行匹配。再根据命中与否做出对应预设的处理方案。
签名 --- 针对网络上的入侵行为特征的描述,将这些特征通过HASH后和我们报文进行比对。
签名:
预定义签名
--- 设备上自带的特征库,这个需要我们激活对应的License(许可证)后才能获取。--- 这个预定义签名库激活后,设备可以通过连接华为的安全中心进行升级。
自定义签名
--- 自己定义威胁特征。
自定义签名和预定义签名可以执行的动作
告警 --- 对命中签名的报文进行放行,但是会记录再日志中
阻断 --- 对命中签名的报文进行拦截,并记录日志
放行 --- 对命中签名的报文放行,不记录日志

注意
:这里在进行更改时,一定要注意提交,否则配置不生效。修改的配置需要在提交后重启模块后生效。


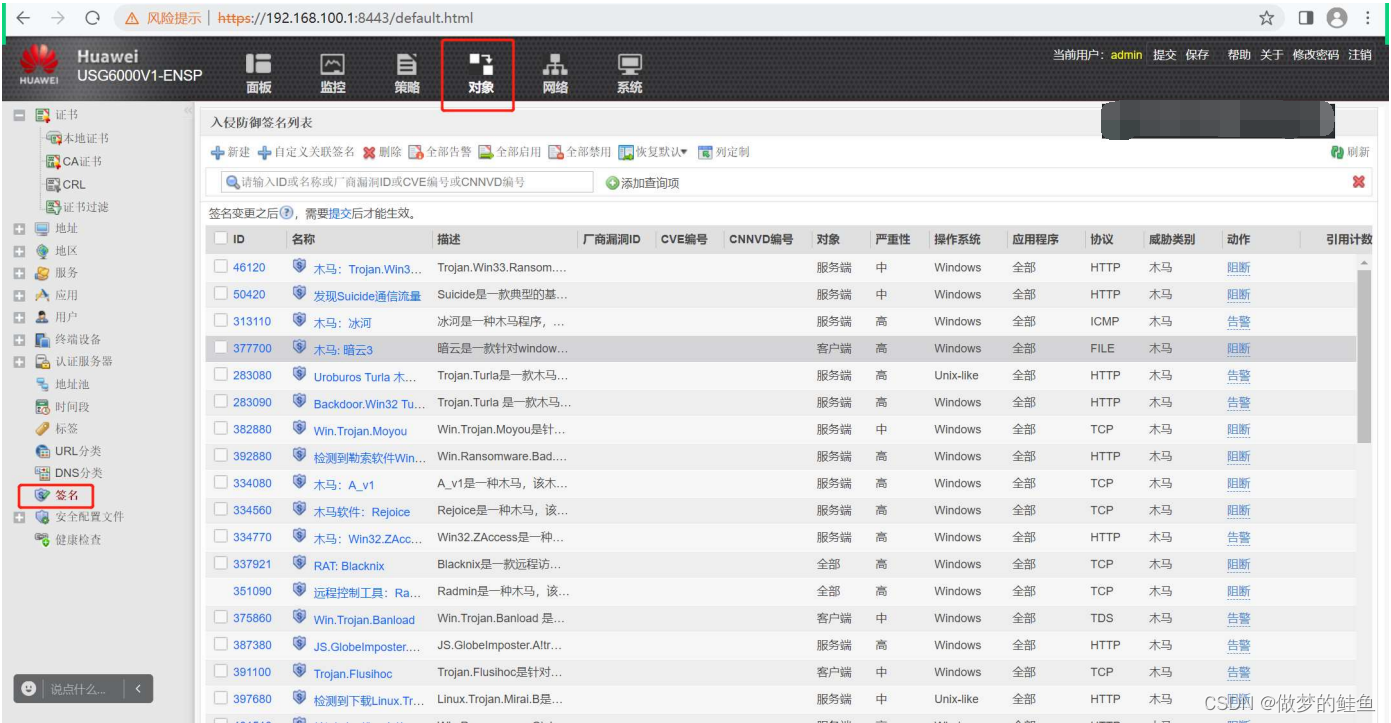
ID --- 签名的标识
对象 --- 服务端,客户端,服务端和客户端
服务端和客户端指的都是身份,一般将发起连接的一端称为客户端,接受连接提供服
务的称为服务端。
严重性:高,中,低 ,提示--- 用来标识该入侵行为的威胁程度
协议,应用程序 --- 指攻击报文所使用的协议或应用类型

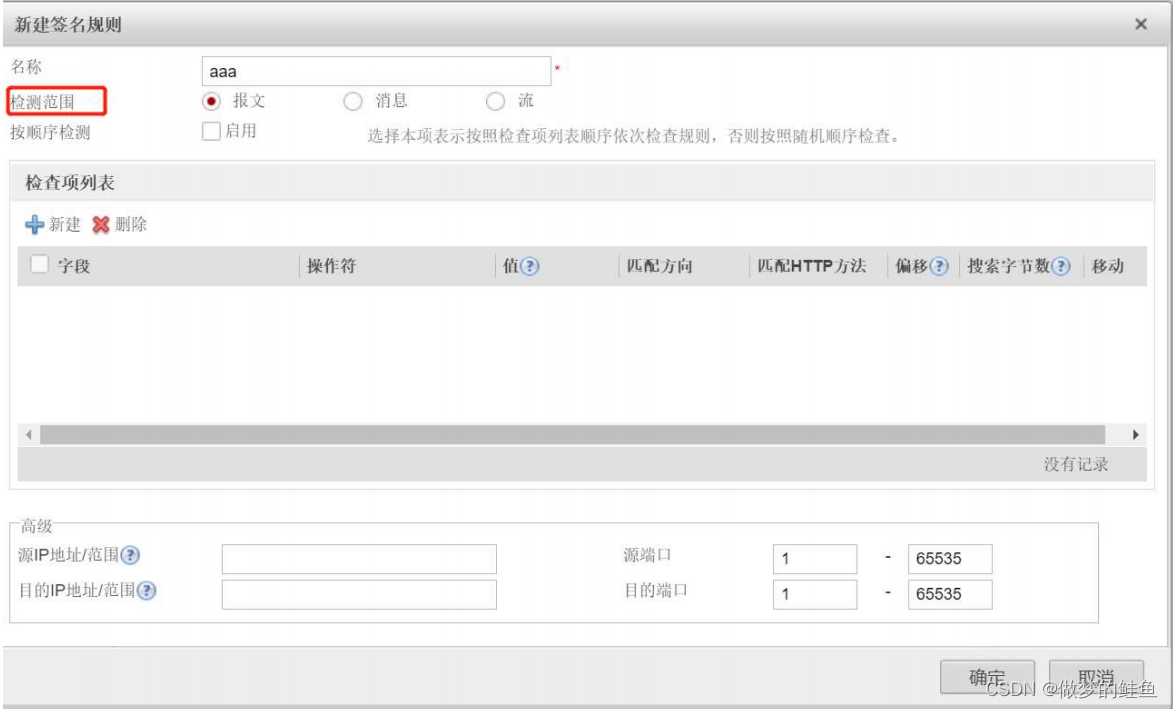
检测范围
报文 --- 逐包匹配
消息 --- 指基于完整的消息检测,如在TCP交互中,一个完整的请求或应答为一个消息。一个消息可能包含多个报文,一个报文也可能包含多个消息。
流 --- 基于数据流。
如果勾选该选项,则下面的“检查项列表”里面的规则将按自上而下,逐一匹配。如果匹配到了,则不再向下匹配;
如果不勾选,则下面所有规则为“且”的关系。
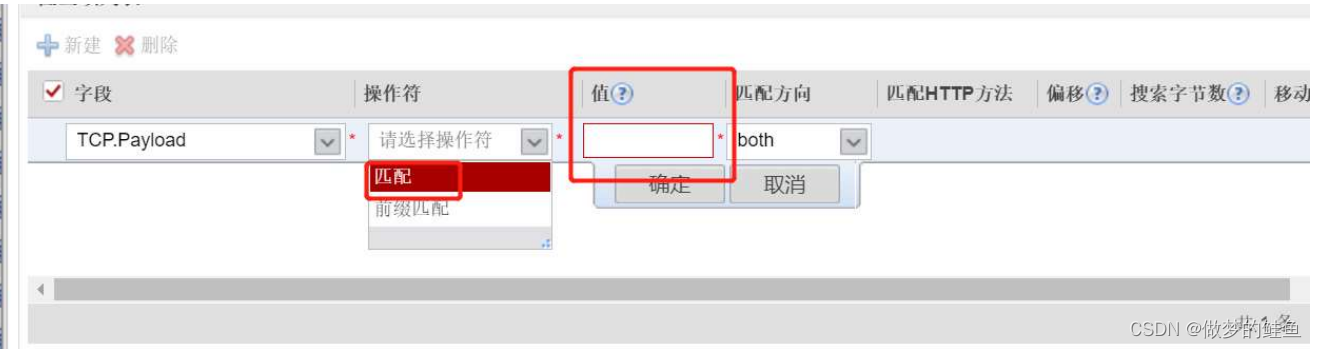
匹配 --- 在对应字段中,包含和后面“值”中内容相同的内容,则匹配成功
前缀匹配 --- 在对应字段中,包含和后面“值”中内容相同的内容开头的内容,则匹配成功
防病毒(AV)
传统的AV防病毒的方式是对文件进行查杀。
传统的防病毒的方式是通过将文件缓存之后,再进行特征库的比对,完成检测。但是,因为需
要缓存文件,则将占用设备资源并且,造成转发延迟,一些大文件可能无法缓存,所以,直接
放过可能造成安全风险。
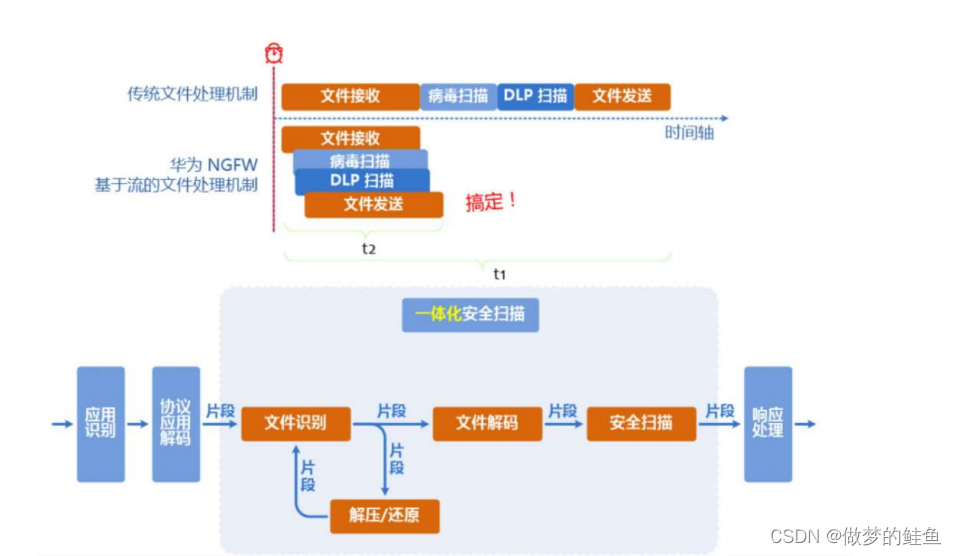
代理扫描 --- 文件需要全部缓存 --- 可以完成更多的如解压,脱壳之类的高级操作,并且,检测率高,但是,效率较低,占用资源较大。
流扫描 --- 基于文件片段进行扫描 --- 效率较高,但是这种方法检测率有限。
病毒简介
病毒分类

病毒杀链
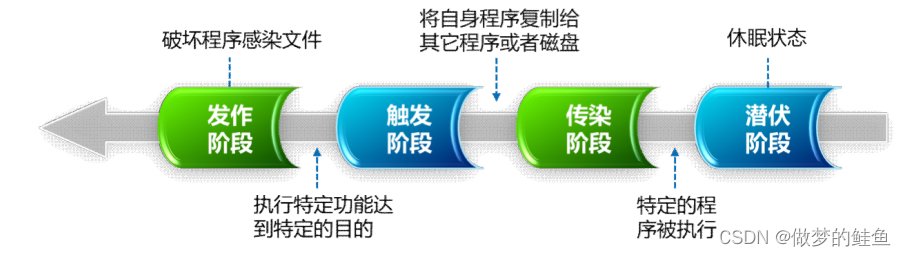
病毒的工作原理




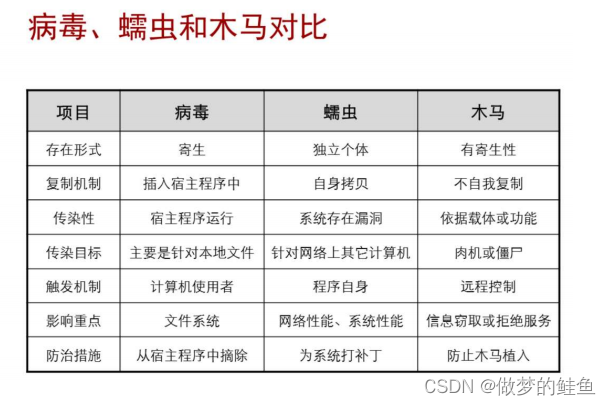
防病毒处理流量

1. 进行应用和协议的识别
2. 判断这个协议是否支持防病毒的检测,如果不是支持的防病毒协议,则文件将直接通过。

3. 之后,需要进行白名单的比对。如果命中白名单,则将不进行防病毒检测,可以同时进行
其他模块的检测。
4. 如果没有命中白名单,则将进行特征库的比对。如果比对上了,则需要进行后续处理。
如果没有比对上,则可以直接放行。
这个病毒库也是可以实时对接安全中心进行升级,但是,需要提前购买License进行激活。
5. 如果需要进行后续处理,首先进行“病毒例外“的检测。 --- 这个病毒例外,相当于是病
毒的一个白名单,如果是添加在病毒例外当中的病毒,比对上之后,将直接放通。 ---- 过渡
防护
6. 之后,进行应用例外的比对。 --- 类似于IPS模块中的例外签名。针对例外的应用执行和整
体配置不同的动作。
7. 如果没有匹配上前面两种例外,则将执行整体配置的动作。
宣告:仅针对邮件文件生效。仅支持SMTP和POP3协议。对于携带病毒的附件,设备允许
文件通过,但是,会在邮件正文中添加病毒的提示,并生成日志。
删除附件:仅针对邮件文件生效,仅支持SMTP和POP3协议。对于携带病毒的附件,设备
会删除掉邮件的附件,同时会在邮件正文中添加病毒的提示,并生成日志。
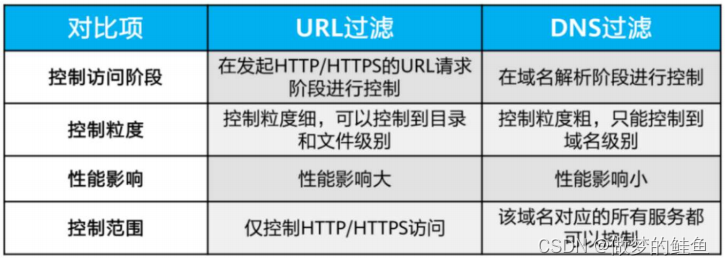
URL过滤
URL ---- 资源定位符

静态网页
动态网页 --- 需要于数据库进行结合
URI --- 统一资源标识符
URL过滤的方法---黑白名单
如果匹配白名单,则允许该URL请求;如果匹配黑名单,则将拒绝URL请求。
白名单的优先级高于黑名单。
预定义的URL分类
本地缓存查询
远程分类服务查询 --- 如果进行了远程的查询,则会将查询结果记录在本地的缓存中,方便后续的查询。 --- 需要购买license才能被激活。
自定义的URL分类 --- 自定义的优先级高于预定义的优先级的
如果远程分类服务查询也没有对应分类,则将其归类为“其他”,则按照其他的处理逻
辑执行。
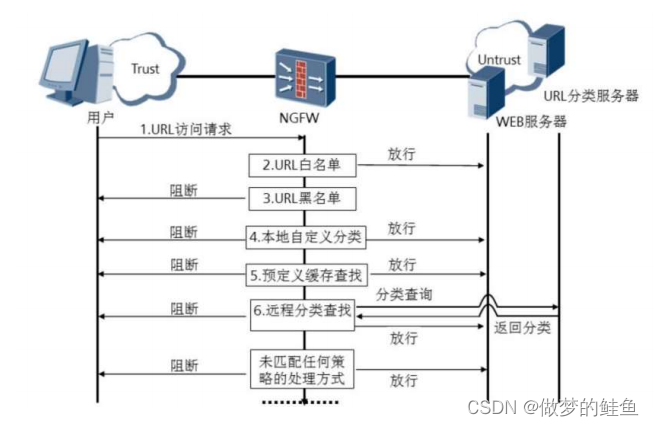
URL的识别方式
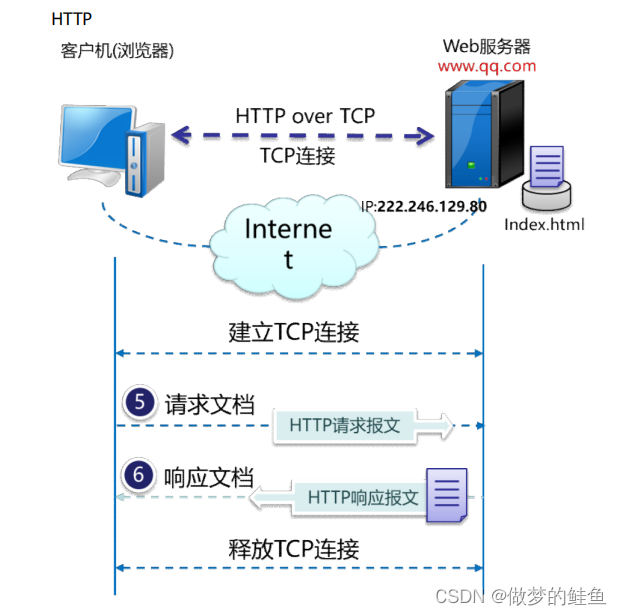
HTTPS
第一种:配置SSL解密功能

这种方法需要提前配置SSL的解密策略,因为需要防火墙在中间充当中间人,所以,性能消耗
较大,效率较低。
第二种方法:加密流量进行过滤

Server_name --- 域名信息
HTTP.request --- URL信息(HOST --- 域名信息,URI)
这种方法比较简单,性能更高,但是,这种信息仅能过滤到域名级别,不够精确。
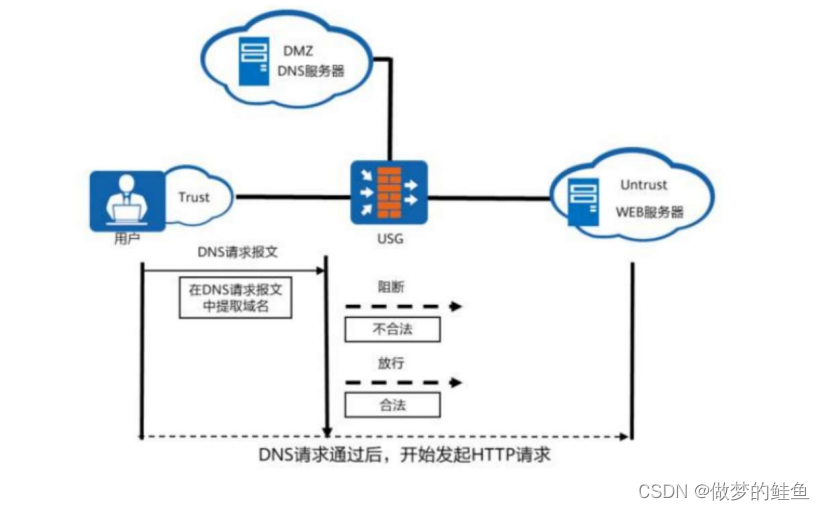
DNS过滤
内容过滤技术

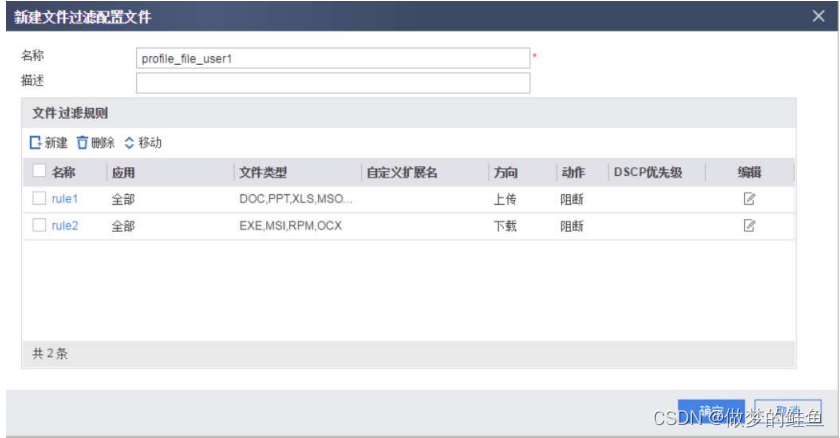
文件过滤技术
这里说的文件过滤技术,是指针对文件的类型进行的过滤,而不是文件的内容。
想要实现这个效果,我们的设备必须识别出:
承载文件的应用 --- 承载文件的协议很多,所以需要先识别出协议以及应用。
文件传输的方向 --- 上传,下载
文件的类型和拓展名 --- 设备可以识别出文件的真实类型,但是,如果文件的真实类型无法识别,则将基于后缀的拓展名来进行判断,主要为了减少一些绕过检测的伪装行为。
压缩
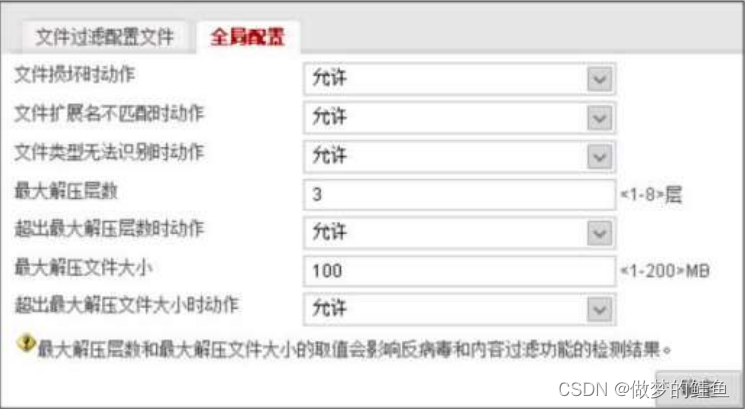

文件过滤技术的处理流程

IAE引擎
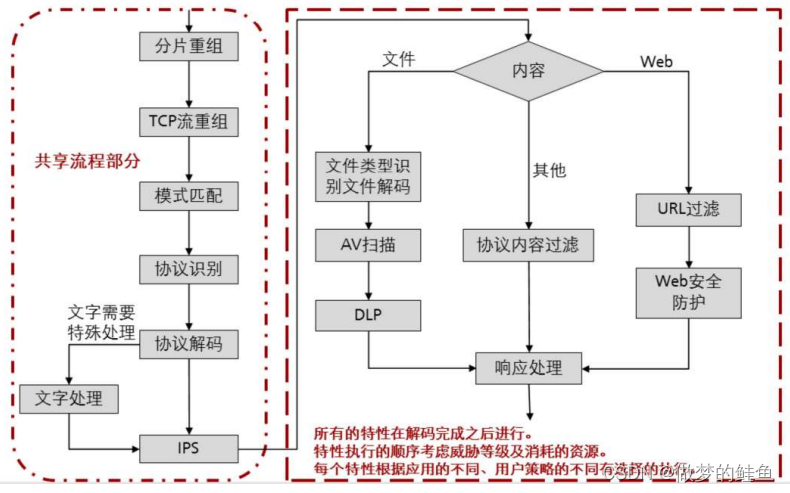
文件过滤的位置是在AV扫描之前,主要是可以提前过滤掉部分文件,减少AV扫描的工作
量,提高工作效率。



内容过滤技术
文件内容的过滤 --- 比如我们上传下载的文件中,包含某些关键字(可以进行精准的匹配,也可以通过正则表达式去实现范围的匹配。)
应用内容的过滤 --- 比如微博或者抖音提交帖子的时候,包括我们搜索某些内容的时候,其实质都是通过HTTP之类的协议中规定的动作来实现的,包括邮件附件名称,FTP传递的文件名称,这些都属于应用内容的过滤。
注意:对于一些加密的应用,比如我们HTTPS协议,则在进行内容识别的时候,需要配置SSL代理(中间人解密)才可以识别内容。但是,如果对于一些本身就加密了的文件,则无法进行内容识别。

内容识别的动作包括:告警,阻断,按权重操作:我们可以给每一个关键字设计一个权重值,如果检测到多个关键字的权重值超过预设值,则执行告警或者阻断的动作。
邮件过滤技术
SMTP --- 简单邮件传输协议,TCP 25,他主要定义了邮件该如何发送到邮件服务器中。
POP3 --- 邮局协议,TCP 110,他定义了邮件该如何从邮件服务器(邮局)中下载下来。
IMAP --- TCP 143,也是定义了邮件 该如何从邮件服务器中获取邮件。
(使用POP3则客户端会将邮件服务器中未读的邮件都下载到本地,之后进行操作。邮件服务器上会将这些邮件删除掉。如果是IMAP,用户可以直接对服务器上的邮件进行操作。而不需要将邮件下载到本地进行操作。)

邮件过滤技术主要是用来过滤
垃圾邮件
的。---所谓垃圾邮件,就是收件人事先没有提出要求或者同意接受的广告,电子刊物,各种形式的宣传的邮件。包括,一些携带病毒,木马的钓鱼邮件,也属于垃圾邮件。

统计法 --- 基于行为的深度检测技术
贝叶斯算法 --- 一种基于预测的过滤手段
基于带宽的统计 --- 统计单位时间内,某一个固定IP地址试图建立的连接数,限制单位时间内单个IP地址发送邮件的数量。
基于信誉评分 --- 一个邮件服务器如果发送垃圾邮件,则将降低信誉分,如果信誉比较差,则将其发出的邮件判定为垃圾邮件。
列表法 --- 黑,白名单
RBL(Real-time Blackhole List) --- 实时黑名单 --- RBL服务器所提供,这里面的内容会实时根据检测的结果进行更新。我们设备在接收到邮件时,可以找RBL服务器进行查询,如果发现垃圾邮件,则将进行告知。 --- 这种方法可能存在误报的情况,所以,谨慎选择丢弃动作。
源头法
SPF技术 --- 这是一种检测伪造邮件的技术。可以反向查询邮件的域名和IP地址是否对应。如果对应不上,则将判定为伪造邮件。
意图分析
通过分析邮件的目的特点,来进行过滤,称为意图分析。(结合内容过滤来进行。)

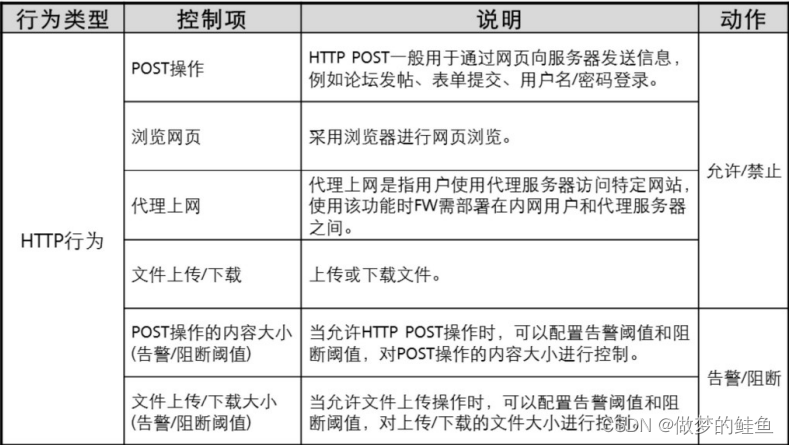
应用行为控制技术
主要针对HTTP和FTP协议。
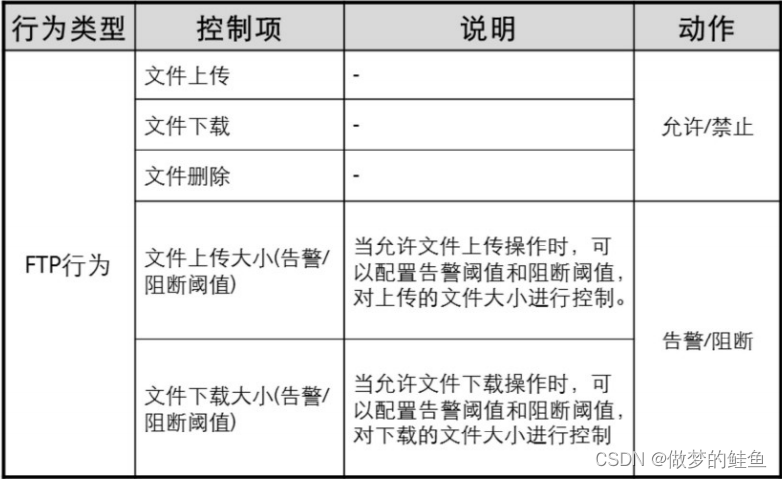
VPN的概述
VPN --- 虚拟专用网 --- 一般指依靠ISP或者其他NSP,也可以是企业自身,提供的一条虚拟网络专线。这个虚拟的专线是逻辑上的,而不是物理上的,所以称为虚拟专用网。

总结:
VPN诞生的原因
1. 物理网络不适用,成本太高,并且如果位置不固定,则无法构建物理专线
2. 公网安全无法保证。由于VPN的诞生,导致网络部署的灵活性大大提升。
VPN的分类
根据建设的单位不同分类
1. 企业自建的VPN专线:GRE,IPSEC,SSL VPN,L2TP --- 这种VPN构建成本较低,因为不需要支付专线的费用,仅需要承担购买VPN设备的费用。并且,在网络控制方面,也拥有更多的主动性。
2. 直接租用运营商的VPN专线:MPLS VPN。这种方式需要企业支付专线的租用费用,但是,控制,安全以及网速方面的问题都将由运营商来承担。MPLS VPN的优势在于,专线的租用成本低。
根据组网方式不同分类
1. Client to LAN(ACCESS VPN)
2. LAN to LAN

Intranet --- 内联网 --- 企业内部虚拟专网
Extranet --- 外联网 --- 拓展的企业内部虚拟专网
相较而言,外联网一般连接合作单位,而内联网一般连接分公司,所以,外联网的权限赋予会比较低,并且,安全把控方面会比较严格。
根据VPN技术实现的层次来进行分类

VPN的核心技术 --- 隧道技术
隧道技术 --- 封装技术
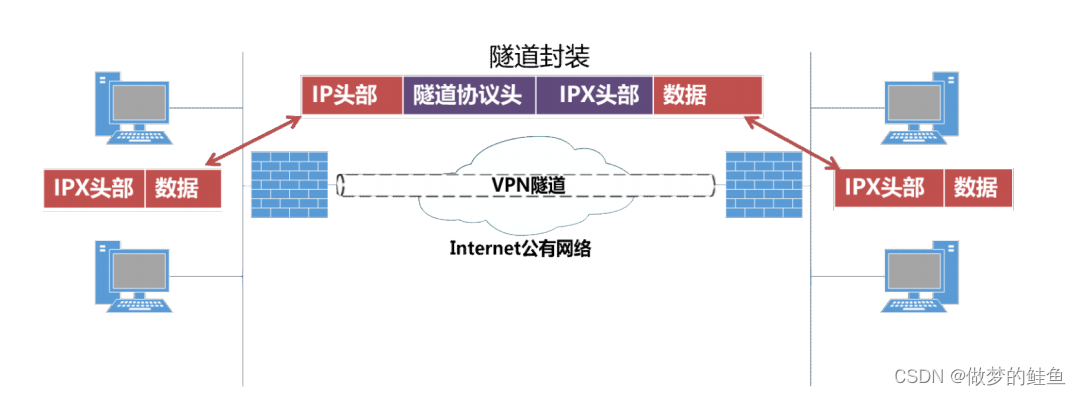
VPN通过封装本身就是对数据的一种保护,而工作在不同层次的VPN,其实质就是保护其所在层次即以上的数据。当然,这种保护在没有加密的情况下,并不代表安全。
我们一般网络封装协议都是由三部分组成的 --- 乘客协议,封装协议,运输协议。
VPN其他常用技术

身份认证技术 ---
身份认证是VPN技术的前提
。
GRE VPN --- 本身不支持身份认证的。(GRE里面有个“关键字”机制。类似于ospf的认证,商量一个口令,在GRE中该措施仅是用来区分通道的)
L2TP VPN--- 因为他后面的乘客协议是PPP协议,所以,L2TP可以依赖PPP提供的认证,比如PAP,CHAP。
IPSEC VPN和SSL VPN --- 都支持身份认证
加解密技术 --- 以此来抵抗网络中的一些被动攻击
注意:加解密技术使用的实质是一个双向函数,即一个可逆的过程。和HASH算法有本质的区别
加密技术也是安全通道的保障。
GRE VPN和L2TP VPN不支持加解密技术。通常可以结合IPSEC技术来实现加解密。
IPSEC VPN和SSL VPN都是支持加解密技术的。
数据认证技术 --- 验货 --- 保证数据的完整性
HASH --- 计算摘要值,之后,通过比对摘要值来保障完整性。
GRE VPN --- 可以加入校验和。但是,GRE的这种功能是可选的,两边开启之后,才会激活数据认证功能。
L2TP VPN --- 不支持数据认证
IPSEC VPN,SSL VPN都是支持数据认证的
密钥管理技术
密码学
近现代加密算法
古典加密技术 --- 算法保密原则
近,现代加密技术 --- 算法公开,密钥保密
对称加密算法,非对称加密算法
对称加密 --- 加密和解密的过程中使用的是同一把密钥。
所以,对称加密所使用的算法一定是一种双向函数,是可逆的。
异或运算 --- 相同为0,不同为1
流加密
主要是基于
明文流(数据流)
进行加密,在流加密中,我们需要使用的密钥是和明文流相同长度的一串密钥流。
目前比较常用的对称加密算法 --- DES/3DES,AES(高级加密标准)

1. 密钥共享
带外传输 --- 不方便
带内传输 --- 不安全
2. 密钥管理 --- N * N

非对称加密算法
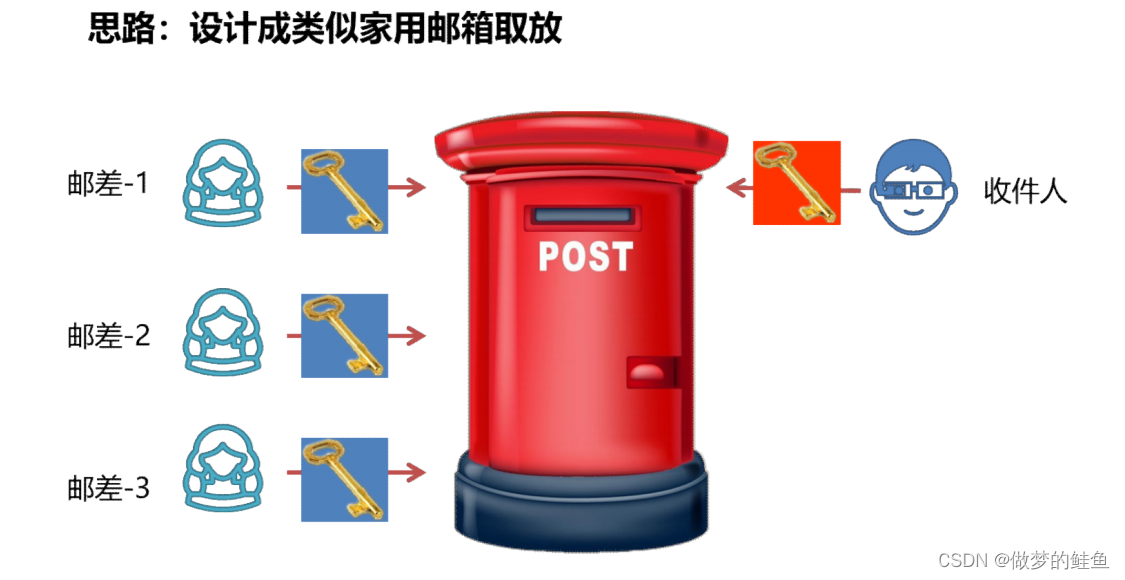
非对称加密算法和对称加密算法的主要区别在于,对称加密算法加解密仅使用同一把密
钥,而非对称加密算法,加密和解密使用的是不同的密钥。
两把密钥 ---一把叫做公钥,另一把叫做私钥。 ---- 这两把钥匙,任意一把钥匙都可以进行加密的操作,然后,需要通过另外一把钥匙来进行解密。

非对称加密算法使用的算法一定是不可逆的,取模运算(求余)

目前常用的非对称加密算法 --- RSA

结论 --- 我们一般采用的做法是,在数据传输的时候,我们会选择使用对称加密算法进行加密,为了保证效率。但是,对称加密算法最主要的问题是密钥传递可能存在安全风
险,所以,我们在传递密钥的时候,可以通过非对称加密算法进行加密,保证密钥传递的安全性。实现二者的互补,达到安全传输的目的。
DH算法 --- Diffie-Hellman算法 --- 密钥交换算法 --- 用来分发对称密钥的。

身份认证以及数据认证技术
对数据进行完整性校验 --- 我们会针对原始数据进行HASH运算,得到摘要值,之后,发送到对端,也进行相同的运算,比对摘要值。如果摘要值相同,则数据完整;如果不同,则数据不完整。
HASH算法 --- 散列函数
1. 不可逆性
2. 相同输入,相同输出。
3. 雪崩效应 --- 原始数据中即使存在细微的区别,也会在结果中呈现出比较明显的变化,方便,我们看出数据是否被篡改。
4. 等长输出 --- 不管原始数据多长,运算之后的摘要值长度是固定。(MD5可以将任意长度的输入,转换成128位的输出。)

我们可以使用私钥对摘要值进行加密,之后传递,这就形成了
数字签名
。


注意:这整个过程只能表示Bob收到的数据,的确是他拥有公钥的这个人发送的数据,但是,你拥有公钥有没有被别人恶意篡改或者替换,这种方法是无法识别出来的,所以,这仅能实现一种数据源的检测,不能进行身份认证。同时,可以完成完整性校验。
数字证书
CA可信机构 --- 提供身份信息证明的第三方机构
通信双方需要完全信任这个第三方机构,之后,让CA为公钥作证。
因为双方都信任该CA机构,所以,实现拥有这个CA机构的公钥信息。
CA机构会使用自己的私钥对A的公钥和一些其他信息一起进行加密,生成
数字证书
。



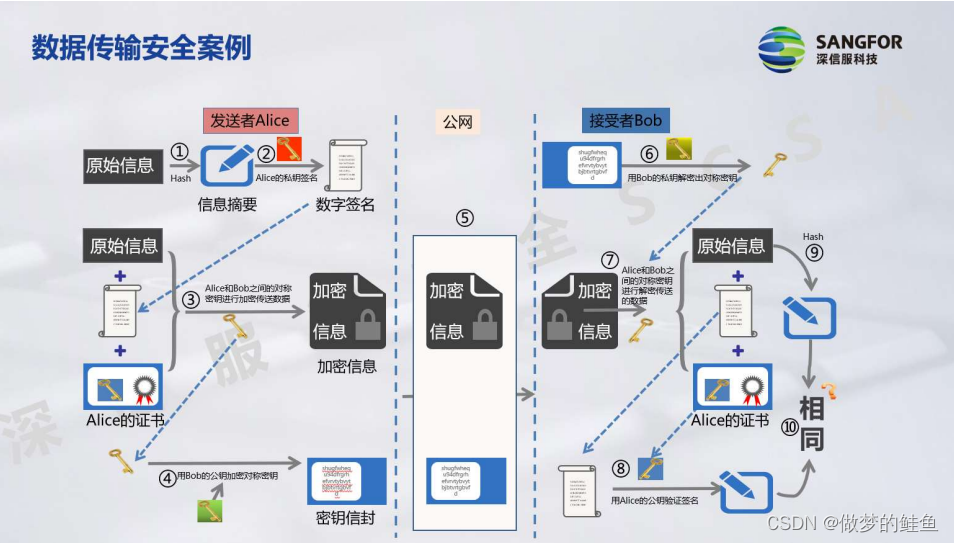
1. 原始信息HASH算法得到摘要值 ---- 为了做完整性校验。为了保证我们的摘要值在传递的过程中,不会被篡改,所以,需要使用私钥进行加密。形成
数字签名
。
2. 针对原始信息,数字签名,数字证书(是用户提前向CA机构申请,获取到的通过CA机构私钥加密后的证书。里面主要包含了Alice的公钥。主要是做身份认证使用)进行加密。使用的是
对称加密算法
。对称机密算法需要使用对应的密钥来进行加密。
3. 将对称加密算法的密钥通过Bob的公钥进行加密,形成密钥信封。(这里是通过非对称加密算法的方式,来传输对称密钥的。也可以使用DH算法,使双方获得对称密钥。)
4. 将加密信息和密钥信封通过公网传递到对端Bob处。
5. Bob首先对密钥信封进行解密。因为这个密钥信封是通过Bob的公钥进行加密的,所以,使用Bob自己的私钥就可以进行解密。解密后,将得到对称密钥。
6. 使用对称密钥去解密加密信息。 ---- 原始数据,数字签名,数字证书
7. 使用CA机构的公钥来解开数字证书。因为数字证书是由CA机构的私钥进行加密的,并且,Bob本身也信任CA机构,所以,自身设备上是拥有CA机构的公钥的。
8. 解开数字证书后将得到
Alice的公钥
,根据Alice的公钥可以解开数字签名。因为数字签名是由Alice自己的私钥来进行加密的,所以,如果可以顺利的使用ALICE的公钥进行解密,则完成了身份认证和数据源鉴别工作。
9. Bob自身需要对原始信息进行HASH运算,并且,数字签名解开后,里面也包含ALice发送时对原始信息进行HASH运算的摘要值,比对两次摘要值,则可完成完整性校验。







![[AutoSar]BSW_Com03 DBC详解 (一)](https://img-blog.csdnimg.cn/direct/418aa8b67bd741d7b04ab4c22a2b5837.png)