关联查询优化
1.准备工作
CREATE TABLE IF NOT EXISTS `type`(
id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE IF NOT EXISTS book(
bookid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(bookid)
)
INSERT INTO TYPE(card) VALUES (FLOOR (1+(RAND()*20)));
INSERT INTO book(card) VALUES (FLOOR (1+(RAND()*20)));
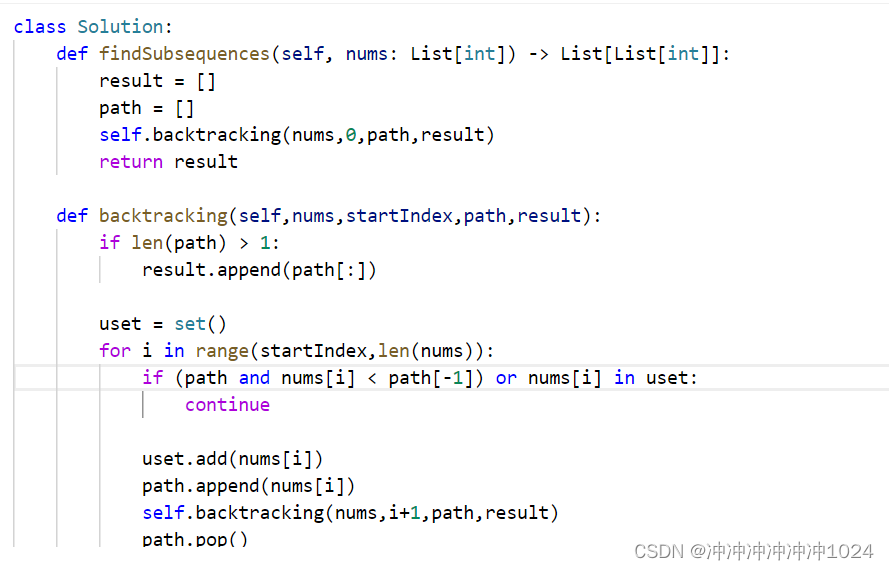
情况1:左外连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card=book.card;

添加索引后
CREATE INDEX Y ON book(card);
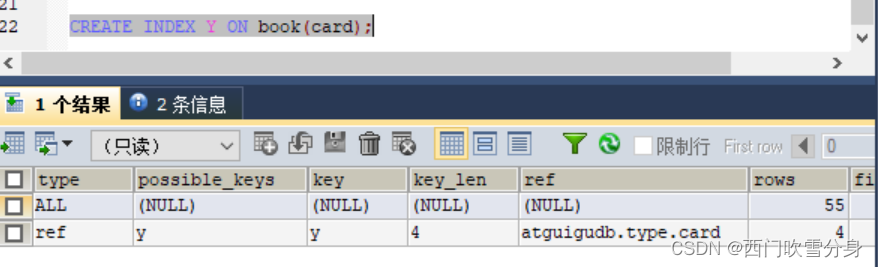
内连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;
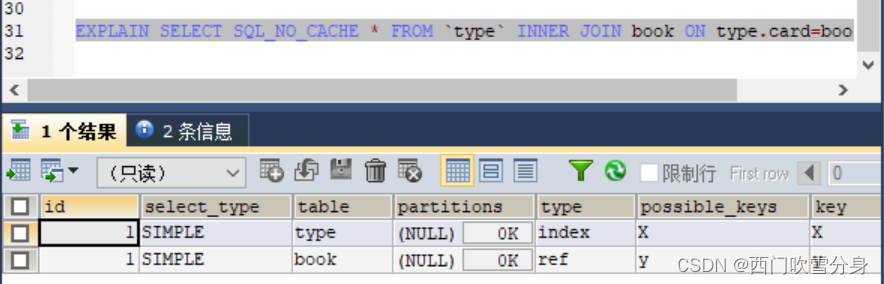
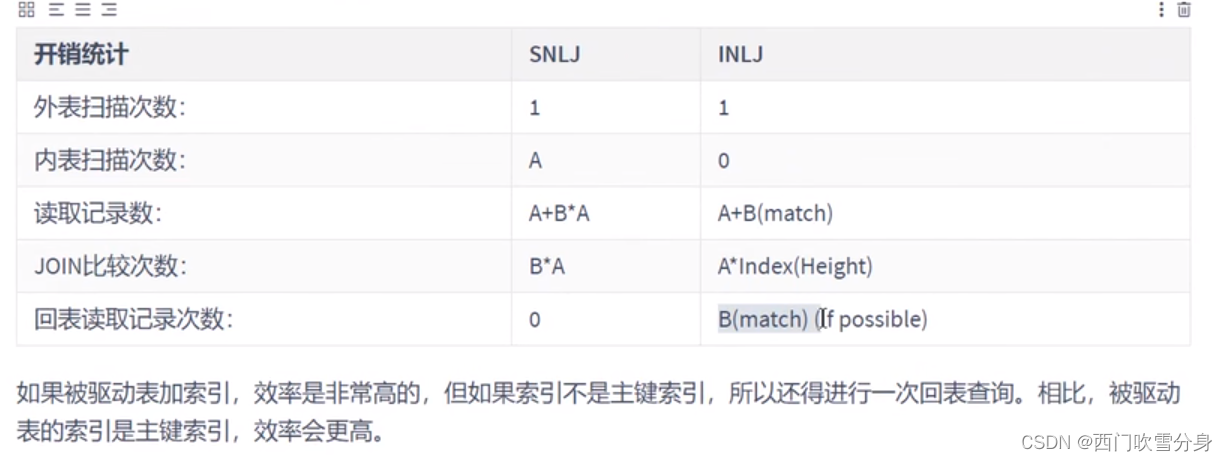
对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的
删除被驱动表book的index后
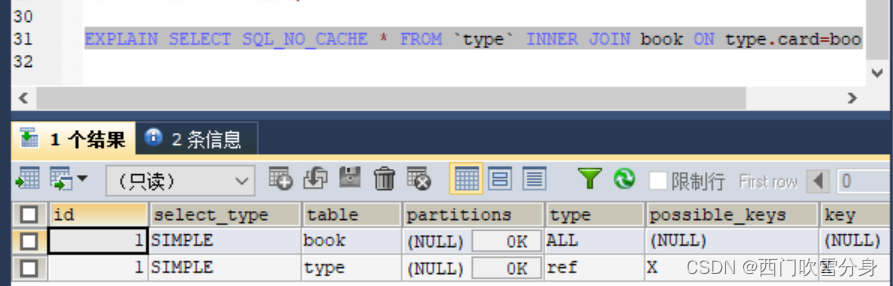
对于内连接来说,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现
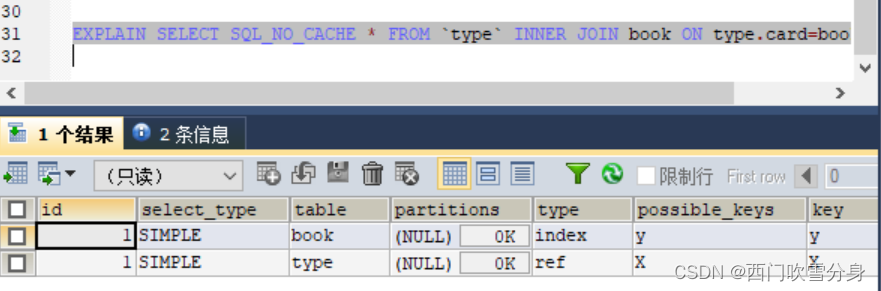
对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。“小表驱动大表”
join语句的原理
驱动表和被驱动表
驱动表是主表,被驱动表是从表,非驱动表。
对于内连接来说:
SELECT * FORM A JOIN B ON...
A一定是驱动表么? 不一定,优化器会根据你查询语句做优化,决定先查那张表,先查询的那张表就是驱动表,反之就是被驱动表。通过explain关键字可以查看。
对于外连接来说:
SELECT * FROM A LEFT JOIN B ON ...
SELECT * FROM B RIGHT JOIN A ON ....
通常会认为A为驱动表,B为被驱动表,但也未必
Simple Nested-Loop Join(简单嵌套循环连接)
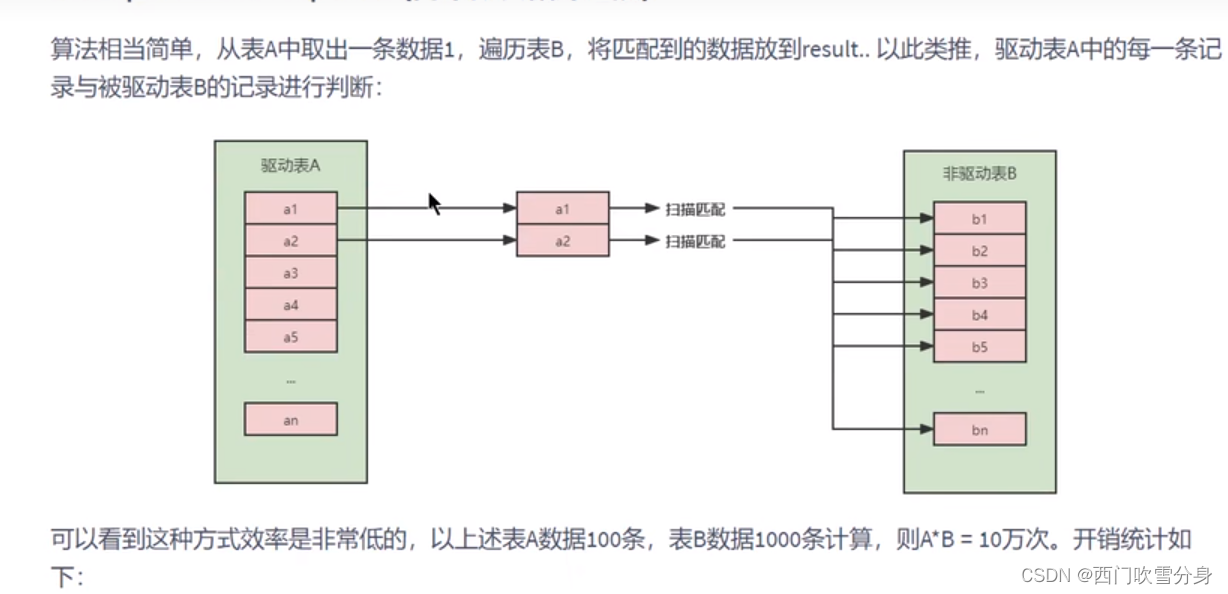
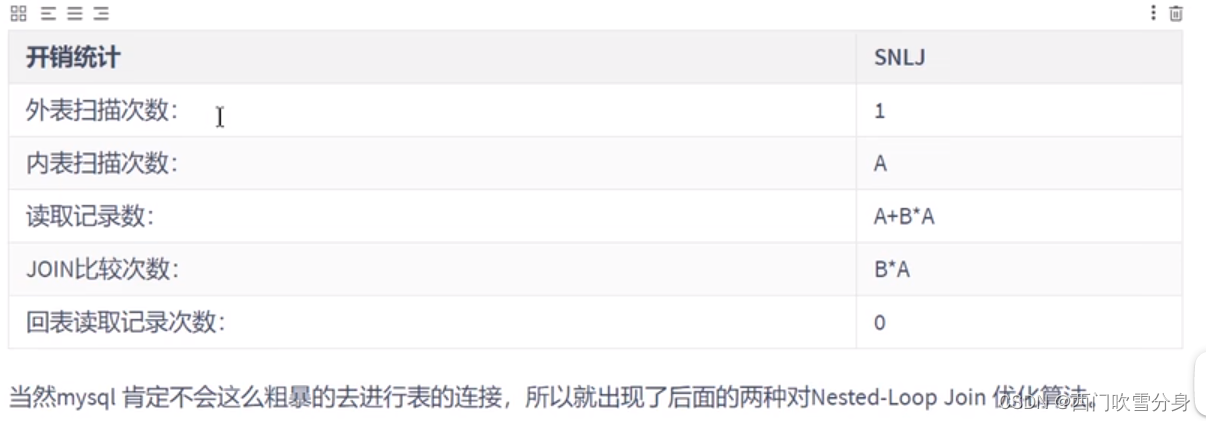
**
Index Nested-Loop join (索引嵌套循环连接)
**
index nested-loop join其优化的思路主要是为了减少内层表数据的匹配次数,所以要求·被驱动表上必须有索引才行。通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
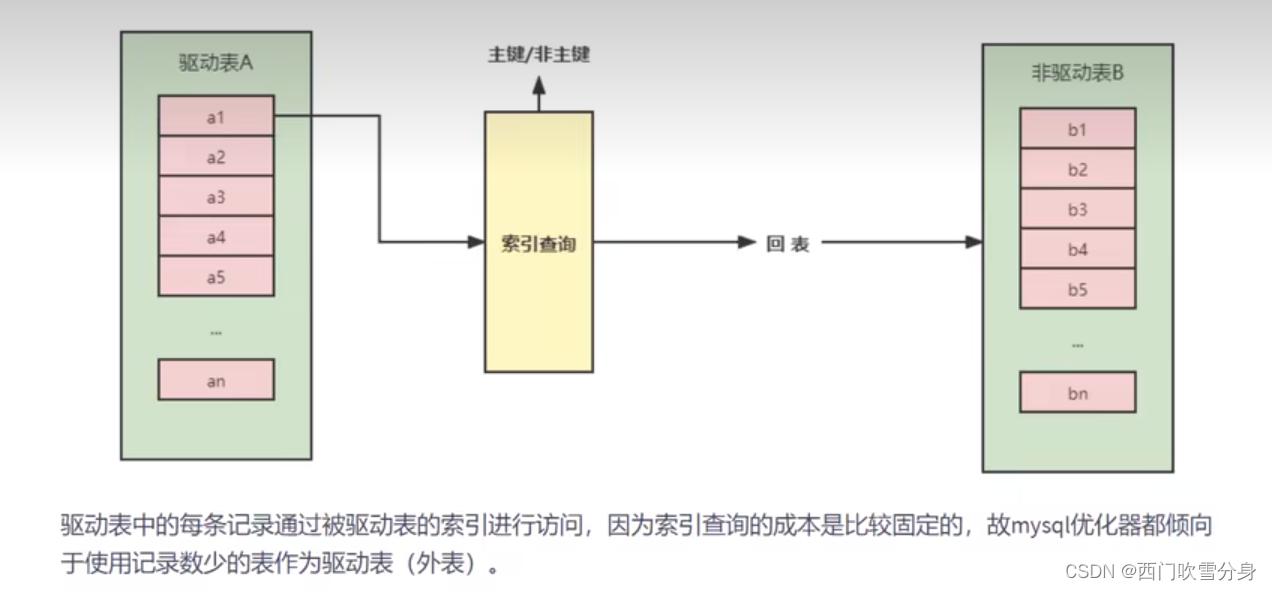
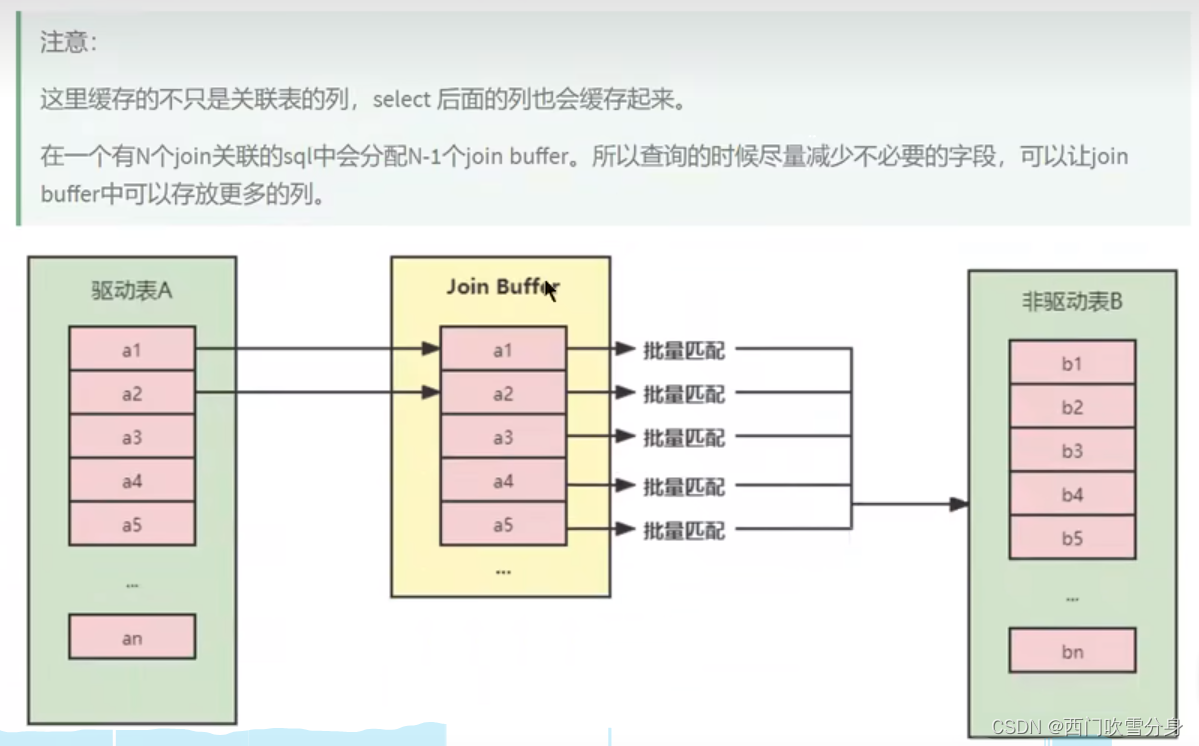
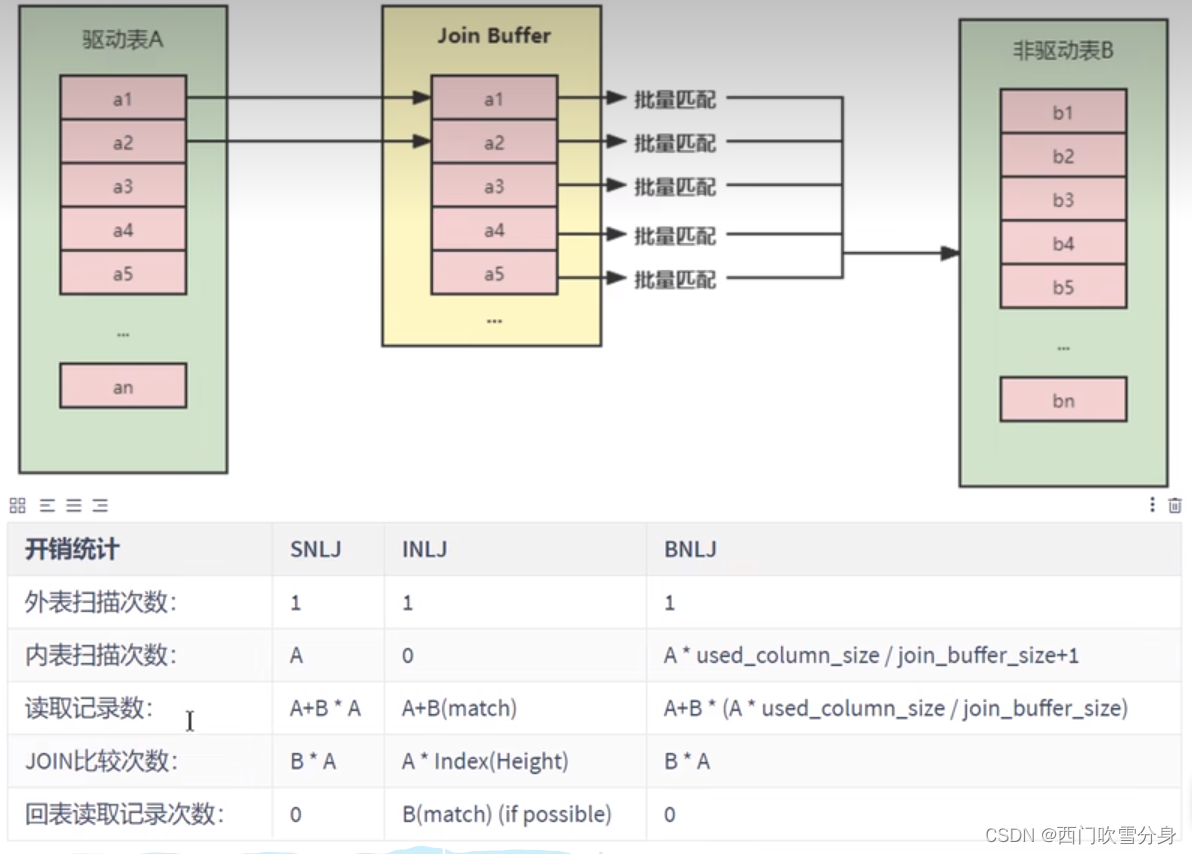
Block Nested Loop Join(块嵌套循环连接)

JOIN BUFFER缓冲区缓存的不只是关联表的列,select后面的列也会缓存起来
参数设置
block_nested_loop=on
SHOW VARIABLES LIKE '%optimizer_switch%'
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
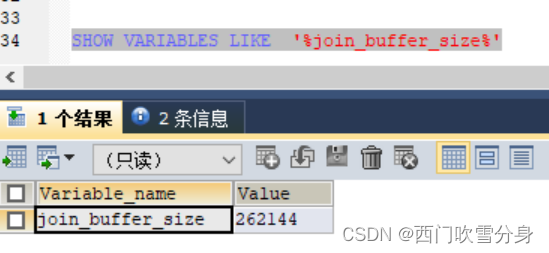
join_buffer_size 默认256K
SHOW VARIABLES LIKE '%join_buffer_size%'
JOIN小结

Hash Join
从Mysql的8.0.20版本开始将废弃BNLJ,因为从Mysql8.0.18版本开始就加入了hash join,默认都是用hash join

JOIN连接 小结
保证被驱动表的JOIN字段已经创建了索引
需要JOIN的字段,数据类型保持绝对的一致
left join时,选择小的作为驱动表,大表作为被驱动表。减少外层循环的次数
inner join 时,mysql会自动将小结果集的表选为驱动表 选择相信mysql优化策略。
能够直接多表关联的尽量直接关联,不用子查询(减少查询的趟数)
不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用JOIN来代替子查询。
衍生表建不了索引
子查询优化
Mysql从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一盒SELECT查询的结果作为另外一个SELECT 语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作
子查询是Mysql的一项重要的功能,可以帮助我们通过一个SQL语句实现比较复杂的查询。但是,子查询的执行效率不高。原因
1.执行子查询时,Mysql需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
2.子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,索引查询的性能会有一定的影响。
对于返回结果集比较大的子查询,其对查询性能的影响也越大。
在Mysql中,可以使用连接(JOIN)查询来代替子查询。连接查询不需要建立临时表,其速度比子查询要快。如果查询中有使用索引的话,性能就会更好。
尽量不要使用NOT IN 或者NOT EXISTS,用LEFT JOIN xxxxx ON xx WHERE xx IS NULL 替代
排序优化
问题:在where条件字段上加索引,但是为什么在Order by字段上还要加索引呢?
回答:
在mysql中,支持两种排序方式,分别是FileSort和Index排序
Index排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。
FileSort排序则一般在内存中进行排序,占用CPU较多,如果待排结果较大,会产生临时文件I/0到磁盘进行排序的情况,效率更低。
优化建议:
1.SQL 中,可以在Where子句和Order子句中使用索引,目的时在WHERE子句中避免全表扫描,Order By子句避免使用FileSort排序。当然在某些情况下,全表扫描或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
2.尽量使用Index完成Order by排序。如果Where和Order by后面是相同的列就使用单索引列;如果不同就使用联合索引。
3.无法使用Index时,需要对FileSort方式进行调优。
select的查询内容没有限制
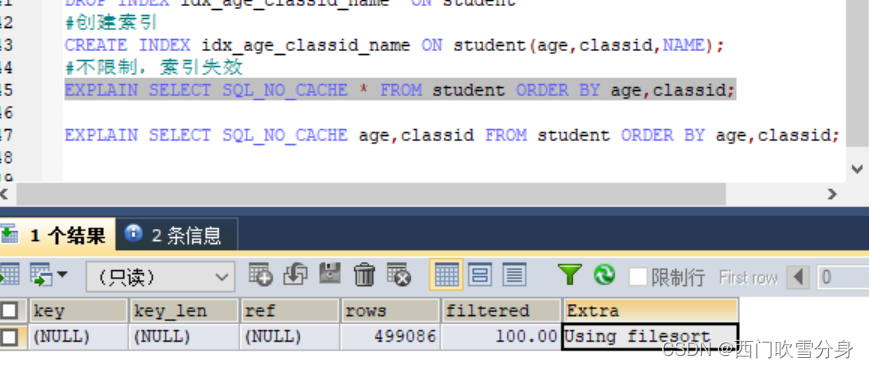
select查询内容与索引保持一致(索引覆盖)
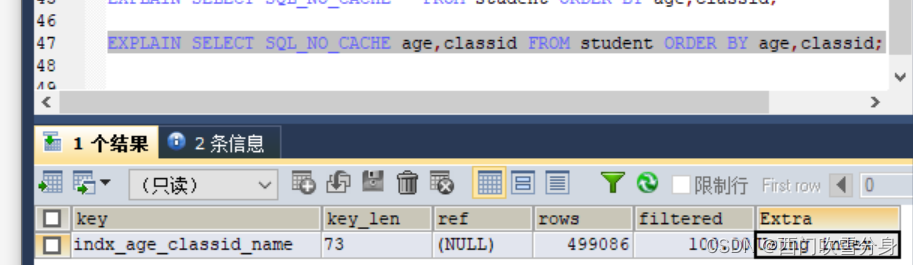
增加limit过滤条件,使用上了索引
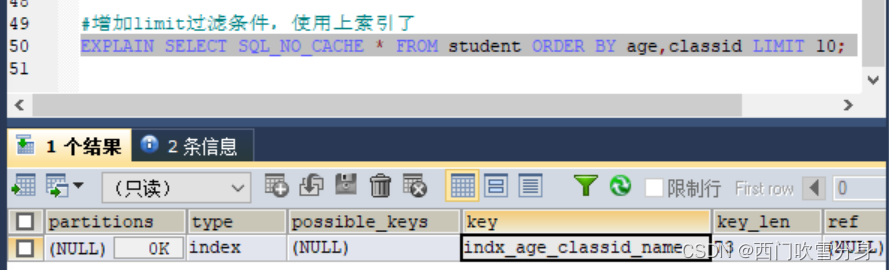
order by时顺序错误,索引失效
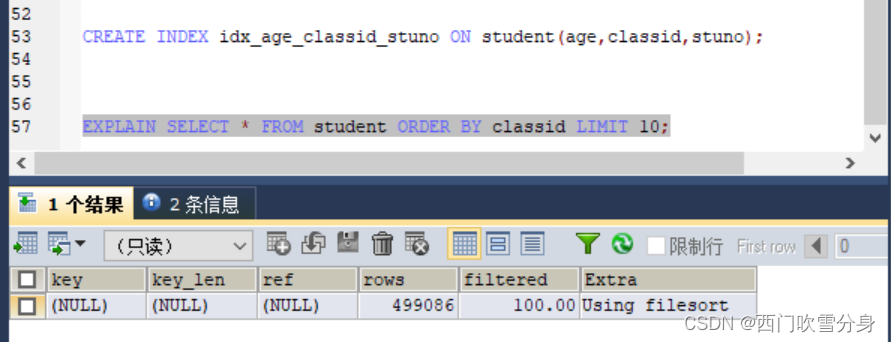
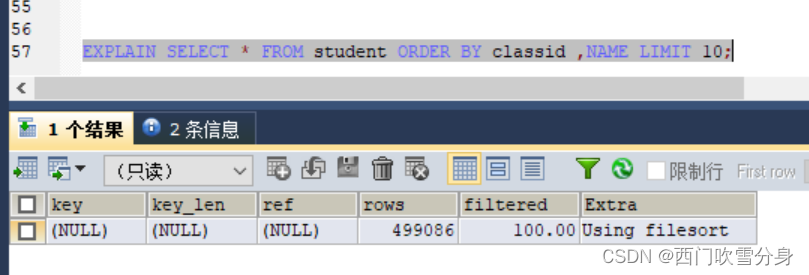
上述案例违反了索引的最左匹配的原则
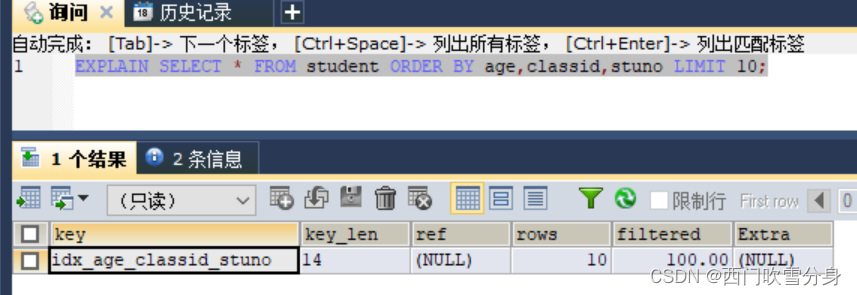
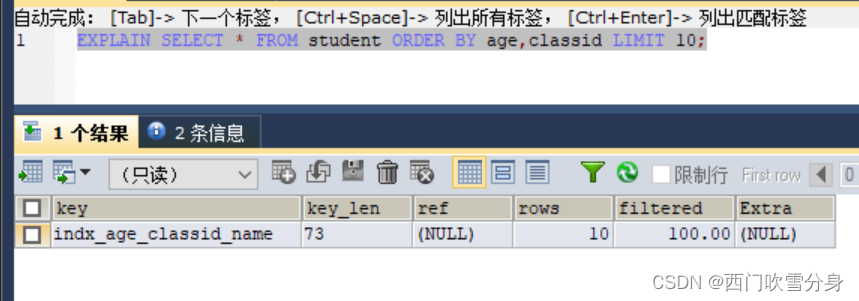
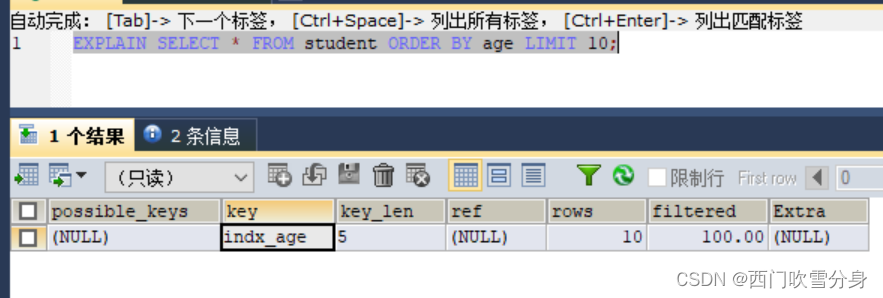
上述三种情况,索引有在使用中
order by 时规则不一致,索引失效(顺序错,不索引;方向反,不索引)
EXPLAIN SELECT * FROM student ORDER BY age DESC,classid ASC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY classid DESC,NAME ASC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age ASC,classid DESC LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age DESC,classid DESC LIMIT 10;
只要最后一种倒着来的使用上了索引
无过滤,不索引
#无过滤,不索引
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid; #先使用where 过滤数据 ken_len=5
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid,NAME; #先使用where 过滤数据 ken_len=5
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age; #没用
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age LIMIT 10; #用了索引
小结


结论:
1.两个索引同时存在,mysql会自动选择最优方案。但是,随着数据量的变化,选择的索引也会随之变化
2.当【范围条件】和【group by或者order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上,反之,亦然。
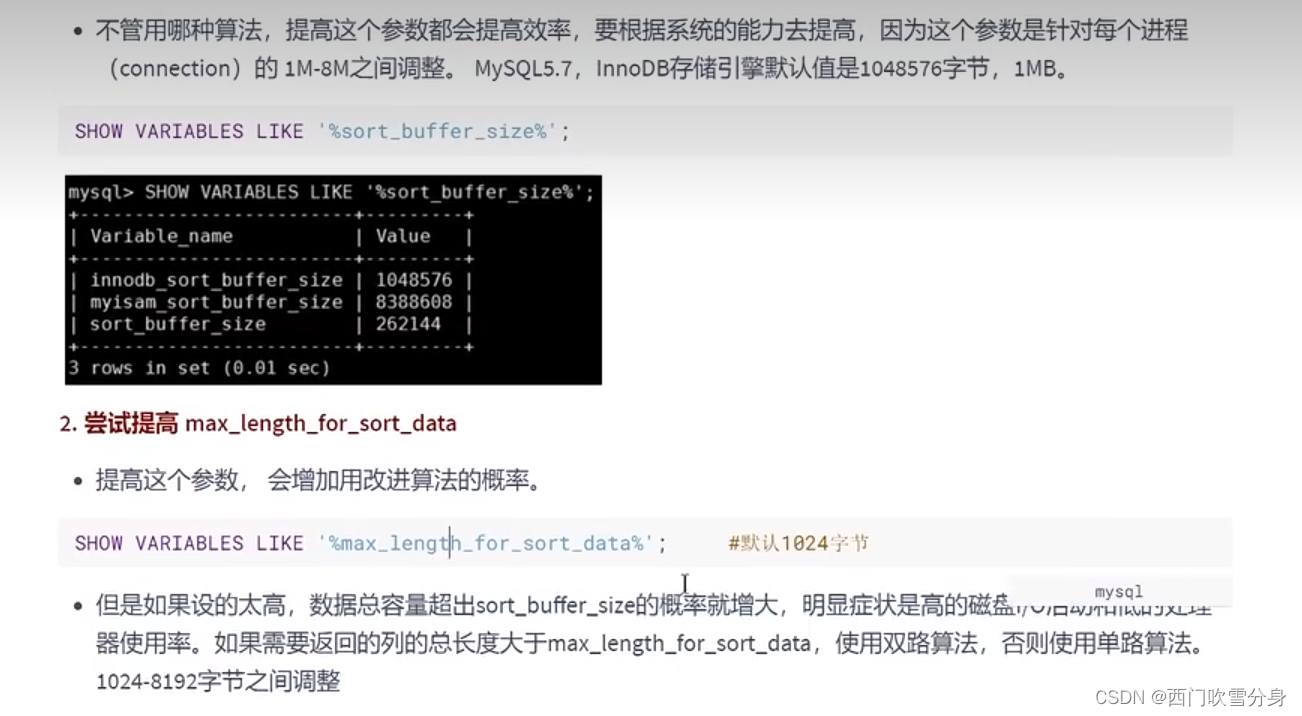
fileSort算法:双路排序和单路排序
排序的字段若如果不在索引列上,则filesort会有两种算法:双路排序和单路排序

Order by时select 是一个大忌,最好只query需要的字段
原因:
当query的字段大小总和小于max_length_for_sort_data*,而且排序的字段不是TEXT|BLOB类型时,会用改进的算法–单路排序,否则用老算法–多路排序.
两种算法的数据都有可能超出sort_buffer_size的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/0,但是用单路排序的风险更大一些,所以要提高sort_buffer_size的容量
Group By优化
group by 使用索引的原则几乎与order by一致,group by即使没有过滤条件使用到索引,也可以直接使用索引。
group by 先排序再分组,遵循索引创建的最佳左前缀法则
当无法使用索引列时,增大max_length_for_sort_data和sort_buffer_size的参数设置
where的效率高于having,能写在where 限定的条件,就不要写在having中了。
减少使用order by,和业务沟通,能不排序就不排序,或者将排序放在程序端去做。
order by\group by\distinct 这些语句比较耗费CPU,数据库的CPU资源是宝贵的。
包含order by\group by\distinct 这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
优化分页查询
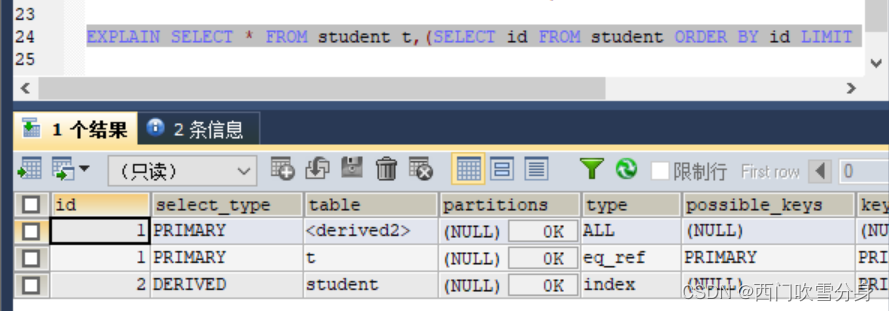
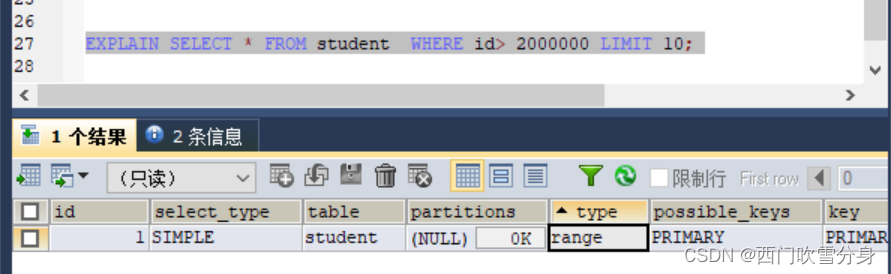
一般分页查询时,通过创建覆盖索引能够比较好的提高性能。一个常见又比较头疼的问题就是limit 2000000,10 此时,需要mysql排序前20000010条记录,仅仅返回2000000-20000010的记录,其他记录丢弃,查询排序的代价非常的大。
EXPLAIN SELECT * FROM student LIMIT 2000000,10;
优化思路1:
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列的内容
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id=a.id;
优化思路二:
改方案适合于主键自增的表,可以把limit查询转换成某个位置的查询
EXPLAIN SELECT * FROM student WHERE id> 2000000 LIMIT 10;
Exists和In的区别
问题:
不太理解哪种情况下应该使用EXISTS,哪种情况应该用IN,选择的标准是看能否使用表的索引么?
回答:
索引是一个前提,其实选择与否还是要看表的大小。可以将选择的标准理解为小表驱动大表。在这种方式下效率是高的。

Count(*)与Count(具体字段)效率
问题: 在mysql中统计数据表的行数,可以使用三种方式:SELECT COUNT(*)\SELECT COUNT(1)和SELECT COUNT(具体字段),使用三者之间的查询效率是怎么样的?
前提: 如果要统计的是某个字段的非空数据行数,则另当别论,毕竟比较执行效率的前提是结果是一样的。

关于SELECT (*)
在表查询中,建议明确字段,不要用作为查询的字段列表,推荐使用SELECT <字段列表> 查询。
原因:
mysql在解析的过程中,会通过查询数据字典将按序转化为所有列名,这样会大大的耗费资源和时间。无法使用覆盖索引
LIMIT 1 对优化的影响
针对的是会扫描全表的SQL语句,如果你可以确定结果集只有一条,那么加上limit 1 时**,当找到结果的时候就不会继续扫描了,这样会加快查询速度**。
如果数据表已经对字段建立了唯一索引,那么可以使用索引进行查询,不会全表扫描的话,就不需要加上limit 1了
多使用COMMIT












![使用 yarn 的时候,遇到 Error [ERR_REQUIRE_ESM]: require() of ES Module 怎么解决?](https://img-blog.csdnimg.cn/direct/ee57608020294fd2968810185d2c706f.png#pic_center)