文章目录
- 1 理解重点
- 2 背景介绍 假设
- 3 过程及重要组件
- 3.1 嵌入层和加入位置编码
- 3.2 编码器 Encoder
- 3.3.1 EncoderLayer编码层
- 3.3.2 LayerNorm归一化层
- 3.3 解码器 Decoder
- 3.4 整合连接Encoder和Decoder
- 4 完整可运行代码
1 理解重点
在之前一节我们已经介绍了Transformer的位置编码Position_encoder,
接下来我们就要完整的实现Transformer的结构了,Transformer实际上可以看做一个完整的武器(比如一支完整的枪),而这只枪具有如枪管、扳机、弹匣、瞄准器、枪托、枪机等大的“组件” 每个组件有一定的功能,比如枪管负责引导子弹直线发射出去,比如扳机负责激活等等,这些大组件如枪管,又进一步由膛线,枪口,冷却槽等小的组件组成(当然这些小的组件有可能有更小的组成)
对应Transformer也是如此,Transformer由很多大组件组成,比如Encoder,Decoder等等,而这些大组件又由更小的组件组成,比如Encoder编码器由六个Encoder layer组成等等
这些组件在代码中常常是用类来实现的,大类包含小类,而功能往往是通过函数来实现的,大的功能包括小的功能
因而我觉得对于理解Transformer的代码而言,最重要的是理清楚
- 这些类和函数的组成和包含关系是什么,即组件之间的包含关系
- 理解原始数据从最初进入网络结构到最后出去的过程
和以往的各类Transformer的教程不同,我会注重给大家结合代码讲解原始数据从最初进入网络结构到最后出来之后的全过程
2 背景介绍 假设
首先Transformer最初被用在NLP的任务上,我们从经典的翻译任务上入手
首先介绍翻译任务的背景,翻译任务是从一种语言到另一种语言,本质上是一个序列到一个序列的过程
比如“I like apples”到“我喜欢苹果”的过程,是英语到中文
那么每一种语言都有一个词表,比如英语(有300万个单词)那么词表大小就是300万,中文有九千多个汉字,那么词表大小就是九千多,从英语到中文的过程,英语是源语言(src),中文是目标语言(tgt),反之中文到英文的过程,中文是源语言,英文是目标语言
为了方便讲解,我们假设存在一种目标语言的词表大小是2000,另一种目标语言词表大小是1000
OK,然后我们训练的时候往往是批量训练,多个句子,每个句子是多个单词,这里我们假设每个批次是10个句子,每个句子8个单词,这里我们可以给每一个字符 编一个码,使得字符转换为数字方便计算,因为计算机直接处理不了汉字
基于以上的背景假设
最终我们给模型的输入是两个
一个是给编码器的源码语言数据 形状是(10,8)
一个是给解码器输入的目标语言数据 形状是(10,8)
我们要训练从源语言到目标语言的翻译
整体结构
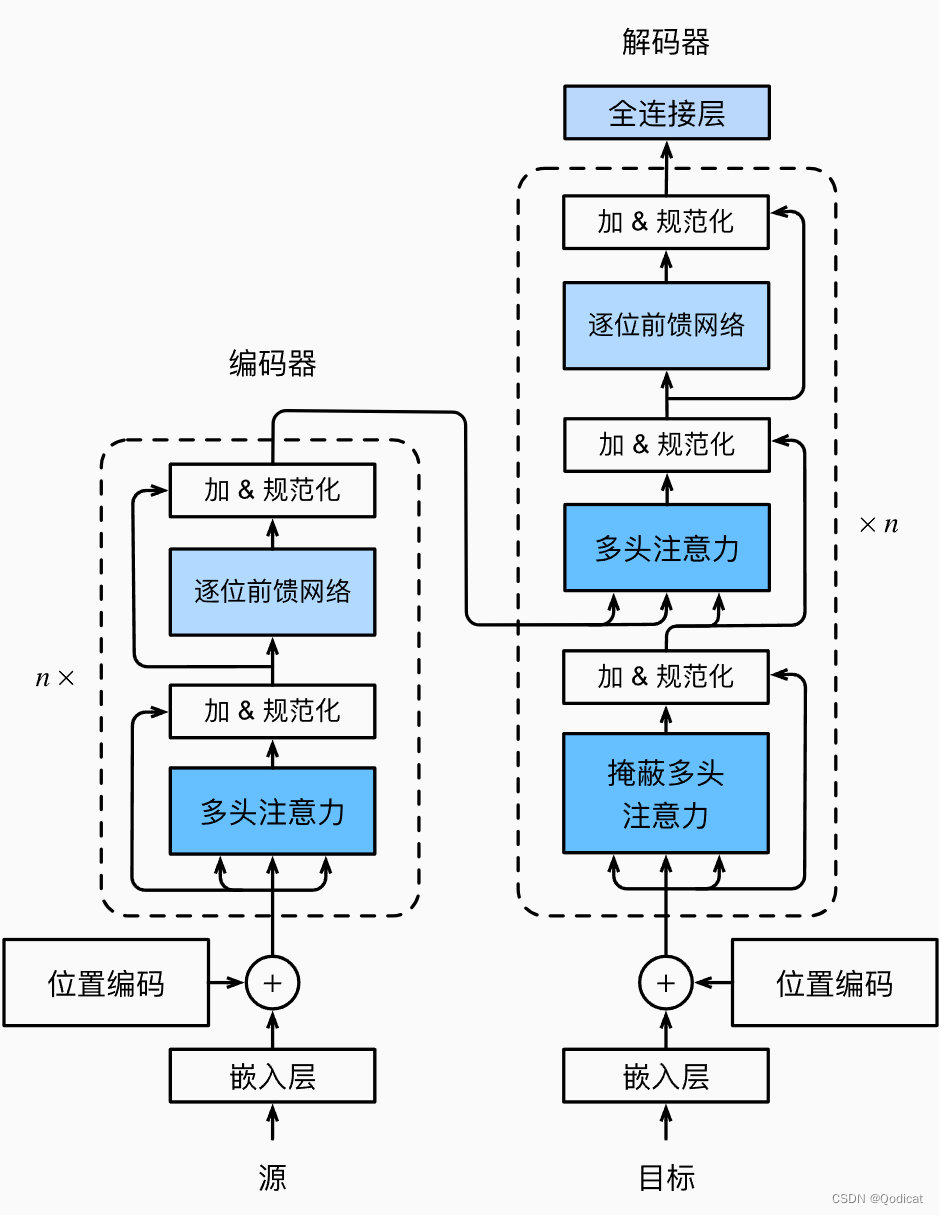
3 过程及重要组件
3.1 嵌入层和加入位置编码
目前的数据都还是离散的,我们要把这些离散的转换为连续的方便计算的,之前的处理方式比如转换为独热编码(就是根据词表大小进行编码的方式,具体可以看机器学习:数据预处理之独热编码(One-Hot)详解-CSDN博客)现在不用这种方式(有缺陷)往往通过嵌入层来实现
这就需要embedding层
实际代码中用到了这个Embeddings这个组件,用到了nn.Embedding这个函数
两个参数,一个是vocab,就是我们前面说的词表大小,另一个是d_model,是嵌入维度,这个嵌入维度是之后Transformer模型的最重要的维度了,同时在这个基础上进行了缩放乘了根号下的嵌入维度
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
我们测试模拟一下,src代表最初的语言序列转换的向量(十个句子,每个句子八个单词)
tgt_vocab = 1000
src = torch.ones(10, 8).long() # Convert to Long scalar type
tgt = torch.ones(10, 8).long()
embeddings = Embeddings(512, 2000)
src_embeddings = embeddings(src)
print(src_embeddings.shape)
输出
torch.Size([10, 8, 512])
同时由于Transformer本身没有位置信息,需要加上位置编码,这里需要实现Positional_Encoding这个组件
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
x = x + self.pe[:, :x.size(1)].detach()
return self.dropout(x)
这一部分实现的细节具体可以看我的这篇博客手撕Transformer(一)| 经典Positional_encoding 用法and代码详解-CSDN博客,不关注细节的话我们只需要知道加上位置编码后形状不变
综上先经过嵌入层,再进入位置编码层
3.2 编码器 Encoder
经过处理后,可以通过Encoder进行相关的处理了,Encoder实际上是由相同layer组件叠加而成的
有一个参数N,N这里代表复制几次layer,通过clones函数实现层的复制,进而实现层堆叠
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
这个Encoder大组件由两个更小的组件组成,分别是EncoderLayer编码层和layerNorm归一化层
可以看到处理后的数据先通过for循环经过N次编码层,最后经过一次norm归一化层
接下来我们看具体每一层的实现
3.3.1 EncoderLayer编码层
其实这里叫层并不是很正确,因为这一层实际上又由很多层组成
主要有多头注意力组件,前馈神经网络组件,残差结构实现组件
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
观察上面的forward函数,可以看到先计算注意力及其分数,然后经过一次残差,对应sublayer[0]
再计算前馈网络,再经过一次残差,对应sublayer[1]
同时我们发现传给self_attn的是三个x,这里的不同位置的x从左到右依次为Q,K,V。
Q,K,V是一样(都是x),也就是所谓的自注意力
我们先来看注意力层计算注意力的相关实现
(1)MultiHeadAttention 多头注意力组件
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
观察上面的forward函数,我们可以看到多头注意力的前向过程
核心第一步得到通过线性层映射得到三个矩阵Q,K,V,然后计算Q,K,V的自注意力,然后最后返回计算后的x,这期间形状不变
这里我们用到的注意力机制是点积注意力,我们来看这个点积注意力机制的实现
def attention(query,key,value,mask=None,dropout=None):
d_k=query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1))/math.sqrt(d_k)
if mask is not None:
scores=scores.masked_fill(mask==0,-1e9)
p_attn=F.softmax(scores,dim=-1)
if dropout is not None:
p_attn=dropout(p_attn)
return torch.matmul(p_attn,value),p_attn
这里用到了masked,关于masked部分,想要详细了解可以看我这篇博客手撕Transformer(二)| Transformer掩码机制的两个功能,三个位置的解析及其代码-CSDN博客
(2)feed_forward 前馈神经网络组件
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
在类的构造函数__init__中,我们可以看到以下几个重要的成员变量的初始化:
self.w_1是一个线性层(nn.Linear),它将输入的维度d_model映射到一个更高维度d_ff。self.w_2也是一个线性层,它将维度为d_ff的输入映射回维度为d_model的输出。self.dropout是一个丢弃层(nn.Dropout),它可以随机地将输入中的一些元素置为零,以减少过拟合。
在类的前向传播函数forward中,输入x首先通过线性层self.w_1进行映射,然后经过ReLU激活函数(F.relu)进行非线性变换,接着通过丢弃层self.dropout进行随机丢弃,最后再经过线性层self.w_2进行映射得到输出。
这个类的作用是实现一个位置前馈神经网络,用于对输入进行非线性变换和降维。它常用于自然语言处理中的编码器模块,用于提取输入序列的特征表示。
(3)残差结构组件
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
SublayerConnection类定义了一个forward方法,用于执行前向传播操作。该方法接受两个参数x和sublayer,其中x表示输入张量,sublayer表示子层的操作。在前向传播过程中,首先对输入张量x进行归一化处理,然后通过sublayer对归一化后的张量进行子层操作。最后,将子层操作的结果与输入张量x相加,并使用self.dropout对结果进行随机失活操作。最终,返回加和后的结果作为前向传播的输出。
3.3.2 LayerNorm归一化层
层归一化,和批归一化可能略有不同
批量归一化:(batch Normalization) 批量归一化是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息。
层归一化(Layer Normalization)是和批量归一化非常类似的方法。和批量归一化不同的是,层归一化是对某一层的所有神经元进行归一化。
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
这段代码定义了一个名为LayerNorm的类,它继承自nn.Module类。LayerNorm类用于实现层归一化(Layer Normalization)操作。
在LayerNorm类的构造函数__init__中,有两个参数:features和eps。features表示输入张量的特征维度,eps表示一个小的常数,用于防止除以零的情况发生。
构造函数创建了两个可学习的参数a_2和b_2,它们分别用于缩放和平移输入张量。a_2和b_2都是通过nn.Parameter函数创建的,它们会被自动注册为模型的可训练参数。a_2被初始化为一个全为1的张量,b_2被初始化为一个全为0的张量。最后,构造函数将eps保存为类的一个属性。
LayerNorm类还定义了一个forward方法,用于执行层归一化操作。在方法中,首先计算输入张量在最后一个维度上的均值mean和标准差std。然后,通过使用保存的参数a_2和b_2对输入张量进行缩放和平移,得到归一化后的张量。最后,返回归一化后的张量作为输出。
通过使用LayerNorm类,可以将层归一化操作应用于神经网络模型中的某一层,以提高模型的训练效果和泛化能力。
3.3 解码器 Decoder
编码器组件基本和解码器相同,很多组件都是通用的,比如点积注意力机制计算组件,比如前馈神经网络组件,比如残差结构组件。因而我们主要介绍解码器和编码器的最重要的不同点
先看Decoder大组件,会发现他Encoder不同,多了一个memory,memory其实就Encoder编码好后的结果~
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
最重要的不同点就是计算注意力的时候,可以看到解码器有三层残差结构(不同于编码器的两层)
第一层做自注意力,对应sublayer[0]
第二层做交叉注意力,其中Q来自解码器之前的内容,K,V来自编码器,对应sublayer[1]
第三层还是前馈,对应sublayer[2]
3.4 整合连接Encoder和Decoder
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
return model
我觉得从顶端到底,从宏观到微观的方式分析是非常Nice的一种方式
4 完整可运行代码
完整代码中我们进行了测试
import torch
from torch import nn
import math
from torch.nn import functional as F
import copy
from torch.nn.functional import log_softmax
import torch
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def attention(query,key,value,mask=None,dropout=None):
d_k=query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1))/math.sqrt(d_k)
if mask is not None:
scores=scores.masked_fill(mask==0,-1e9)
p_attn=F.softmax(scores,dim=-1)
if dropout is not None:
p_attn=dropout(p_attn)
return torch.matmul(p_attn,value),p_attn
#为什么是四维度的?
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
x = x + self.pe[:, :x.size(1)].detach()
return self.dropout(x)
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
return model
src_vocab = 2000
tgt_vocab = 1000
src = torch.ones(10, 8).long() # Convert to Long scalar type
tgt = torch.ones(10, 8).long()
""" embeddings = Embeddings(512, 2000)
src_embeddings = embeddings(src)
print(src_embeddings.shape)
"""
# Create masks for the input and target sequences
src_mask = torch.ones(10,8,8)
tgt_mask = torch.ones(10,8,8)
# Create the model
model = make_model( src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1)
# Forward pass through the model
output = model(src, tgt, src_mask, tgt_mask)
# Print the output shape
print(output.shape)
参考
详解深度学习中的注意力机制(Attention) - 知乎 (zhihu.com)
Transformer源码详解(Pytorch版本) - 知乎 (zhihu.com)

![[嵌入式系统-33]:RT-Thread -18- 新手指南:三种不同的版本、三阶段学习路径](https://img-blog.csdnimg.cn/direct/8f13e2ae00a346afaf1720ea4c921455.png)


![Python算法题集_实现 Trie [前缀树]](https://img-blog.csdnimg.cn/direct/5a897d6e99aa4f639286febc56714d68.png#pic_left)