文章目录
- 激活函数
- Sigmoid 激活函数
- Tanh激活函数
- ReLU激活函数
- Leaky ReLU激活函数
- Parametric ReLU激活函数 (自适应Leaky ReLU激活函数)
- ELU激活函数
- SeLU激活函数
- Softmax 激活函数
- Swish 激活函数
- Maxout激活函数
- Softplus激活函数
激活函数
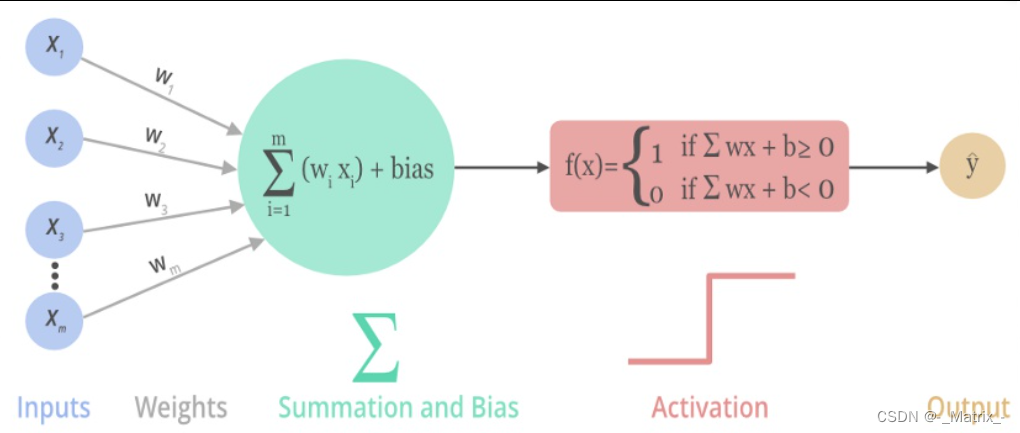
一般来说,在神经元中,激活函数是很重要的一部分,为了增强网络的表示能力和学习能力,神经网络的激活函数都是非线性的,通常具有以下几点性质:
- 连续并可导(允许少数点上不可导),可导的激活函数可以直接利用数值优化的方法来学习网络参数;
- 激活函数及其导数要尽可能简单一些,太复杂不利于提高网络计算率;
- 激活函数的导函数值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
Sigmoid 激活函数
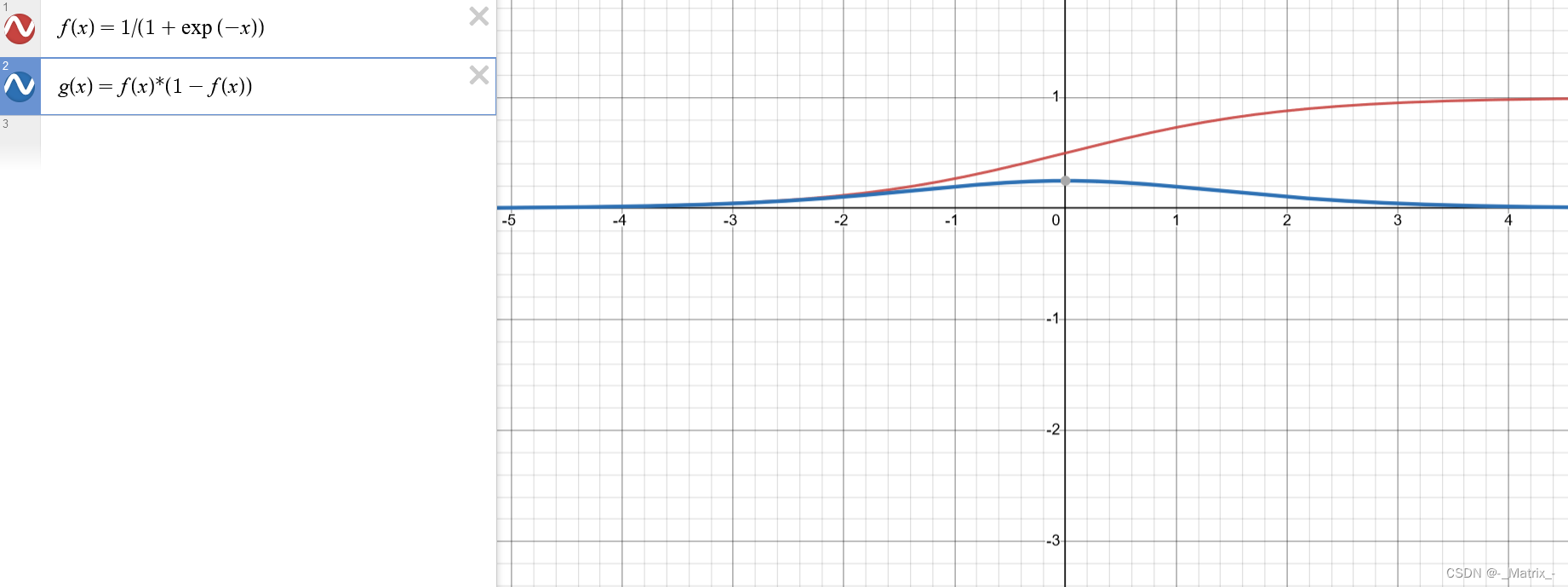
Sigmoid函数,也称为Logistic函数,是一种常用的激活函数之一。它将输入值映射到一个介于0和1之间的连续输出值。
Sigmoid函数的数学表达式为:
数学推导:
对Sigmoid函数f(x) = 1 / (1 + exp(-x)),我们可以通过链式法则对其求导。
首先,我们计算Sigmoid函数的导数f'(x):
f'(x) = d/dx(1 / (1 + exp(-x)))
接下来,我们将求导式进行变形,以便更方便地计算:
f'(x) = 1 / (1 + exp(-x))^2 * exp(-x)
因此,Sigmoid函数的导数f'(x)的表达式为:
f'(x) = f(x) * (1 - f(x))
这个表达式可以用于计算任意输入x处的Sigmoid函数的导数。
C++实现Sigmoid函数的示例代码:
#include <cmath>
// Sigmoid函数的实现
double sigmoid(double x) {
return 1.0 / (1.0 + exp(-x));
}
// Sigmoid函数的导数实现
double sigmoidDerivative(double x) {
double fx = sigmoid(x);
return fx * (1.0 - fx);
}
int main() {
double x = 2.0; // 示例输入值
// 调用Sigmoid函数计算输出
double result = sigmoid(x);
// 调用Sigmoid函数的导数计算输出
double derivative = sigmoidDerivative(x);
// 输出结果
printf("Sigmoid(%f) = %f\n", x, result);
printf("Sigmoid的导数(%f) = %f\n", x, derivative);
return 0;
}
其中,exp表示自然常数e(约等于2.71828)的指数函数。
Sigmoid函数的特点是在输入值较大或较小时,输出接近于1或0,而在输入值接近0时,输出接近于0.5。这种S型曲线形状使得Sigmoid函数在二分类问题中常被用作输出层的激活函数,将输出解释为概率值,表示正类的概率。
Sigmoid函数具有以下优点和缺点:
优点:
- 可以将输入映射到介于0和1之间的概率值,适用于二分类问题中将输出解释为概率的情况。
- Sigmoid函数在输入接近0时,输出接近于0.5,具有平滑的、连续的特性。
- Sigmoid函数具有可导性,这对于使用梯度下降等基于梯度的优化算法进行模型训练是重要的。
缺点:
- Sigmoid函数在输入较大或较小的情况下,输出接近于0或1,导致梯度饱和,使得反向传播时梯度变得非常小,造成梯度消失的问题。这限制了Sigmoid函数在深度神经网络中的应用。
- Sigmoid函数的指数计算较为复杂,相比于其他激活函数,计算代价较高。
- Sigmoid函数输出的值不是以0为中心的,即其输出均值不为0,这可能导致网络在训练过程中的收敛速度变慢。
综上所述,尽管Sigmoid函数在过去被广泛应用于神经网络中,但随着深度学习的发展,人们更倾向于使用其他激活函数,如ReLU及其变种,因为它们能够缓解梯度消失问题并提供更好的性能。然而,在某些特定情况下,Sigmoid函数仍然可以有所用处,例如需要将输出解释为概率的二分类问题。
Tanh激活函数
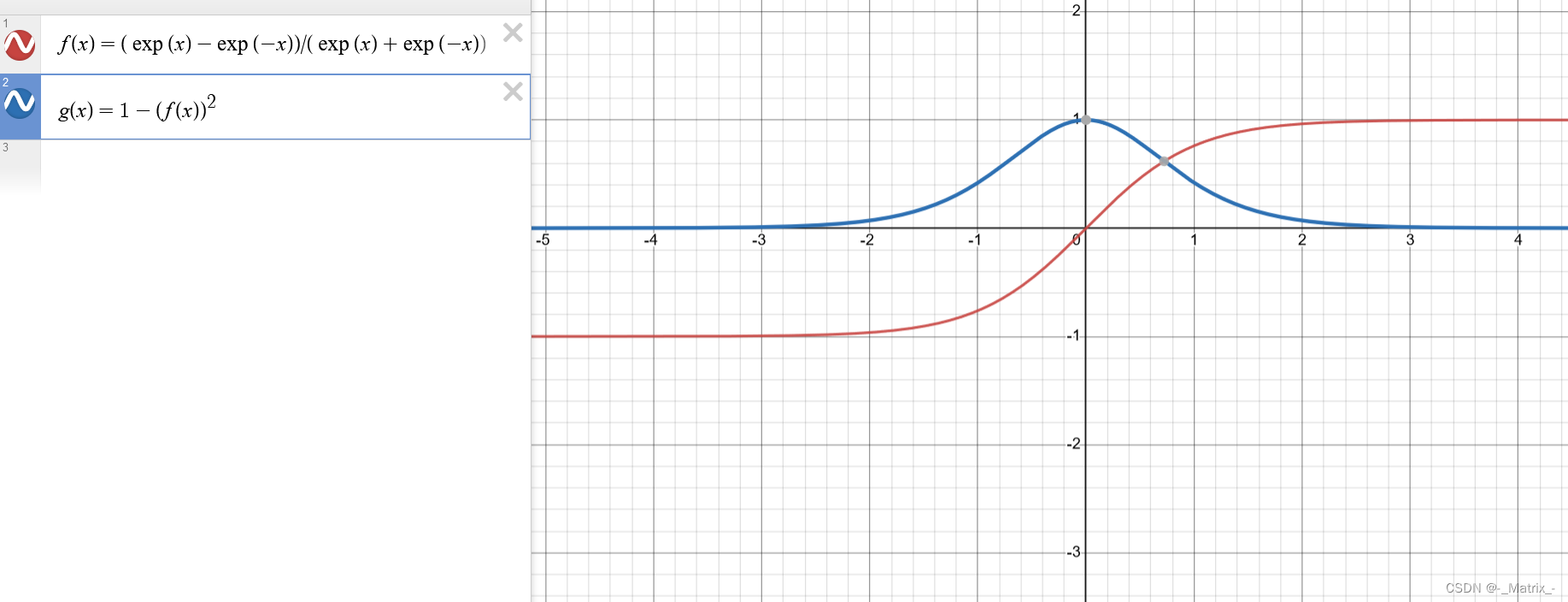
Tanh函数(双曲正切函数)是一种常用的激活函数,它将输入值映射到一个介于-1和1之间的连续输出值。
Tanh函数的数学表达式为:
数学推导:
Tanh函数的数学表达式为:
f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
我们可以通过对Tanh函数进行求导,得到其导数的数学表达式。
首先,我们令y = Tanh(x),则Tanh函数可以表示为:
y = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
对y求导,即计算dy/dx。
使用除法的求导法则和指数函数的求导法则,我们可以得到:
dy/dx = [(exp(x) + exp(-x))(exp(x) + exp(-x)) - (exp(x) - exp(-x))(exp(x) - exp(-x))] / (exp(x) + exp(-x))^2
化简上述表达式,我们可以得到Tanh函数的导数的数学表达式:
dy/dx = 1 - (Tanh(x))^2
因此,Tanh函数的导数为 1 减去其本身的平方。
Tanh函数可以看作是Sigmoid函数的变种,它具有Sigmoid函数的S型曲线形状,但输出范围更广,从-1到1。
Tanh函数的特点包括:
- 在输入接近0时,输出接近于0,具有零中心化的特性。
- Tanh函数的输出在输入为负时接近于-1,在输入为正时接近于1。
- Tanh函数是可导的,对于使用梯度下降等基于梯度的优化算法进行模型训练是可行的。
以下是使用C++实现Tanh函数的示例代码:
#include <cmath>
// Tanh函数的实现
double tanh(double x) {
return (exp(x) - exp(-x)) / (exp(x) + exp(-x));
}
// Tanh函数的导数实现
double tanh_derivative(double x) {
double tanh_x = tanh(x);
return 1 - tanh_x * tanh_x;
}
int main() {
double x = 2.0; // 示例输入值
// 调用Tanh函数计算输出
double result = tanh(x);
// 调用Tanh函数的导数计算输出
double derivative = tanh_derivative(x);
// 输出结果
printf("Tanh(%f) = %f\n", x, result);
printf("Tanh Derivative(%f) = %f\n", x, derivative);
return 0;
}
Tanh函数(双曲正切函数)具有以下优点和缺点:
优点:
- Tanh函数的输出范围是介于-1和1之间,相比于Sigmoid函数,Tanh函数的输出具有零中心化的特性,使得数据在处理时更接近原点。
- Tanh函数在输入接近0时,输出接近于0,可以将数据映射到更接近原点的区域,有助于模型的收敛。
- Tanh函数是可导的,对于使用梯度下降等基于梯度的优化算法进行模型训练是可行的。
缺点:
- Tanh函数在输入较大或较小的情况下,输出接近于1或-1,导致梯度饱和,使得反向传播时梯度变得非常小,造成梯度消失的问题,尤其在深度神经网络中。
- Tanh函数的指数计算较为复杂,相比于其他激活函数,计算代价较高。
- Tanh函数的输出值域为[-1, 1],这使得它对于某些任务而言,可能不是最优的激活函数选择。
综上所述,尽管Tanh函数具有一些优点,但在深度神经网络中,它容易出现梯度消失的问题,因此在实践中,ReLU及其变种等激活函数更常用。然而,Tanh函数仍然可以在特定情况下使用,例如需要将输出值范围控制在[-1, 1]之间的任务,或者在某些循环神经网络(RNN)的隐藏层中使用。
ReLU激活函数
ReLU(Rectified Linear Unit)函数是一种常用的激活函数,它在深度学习中广泛使用,特别是在卷积神经网络(CNN)中。
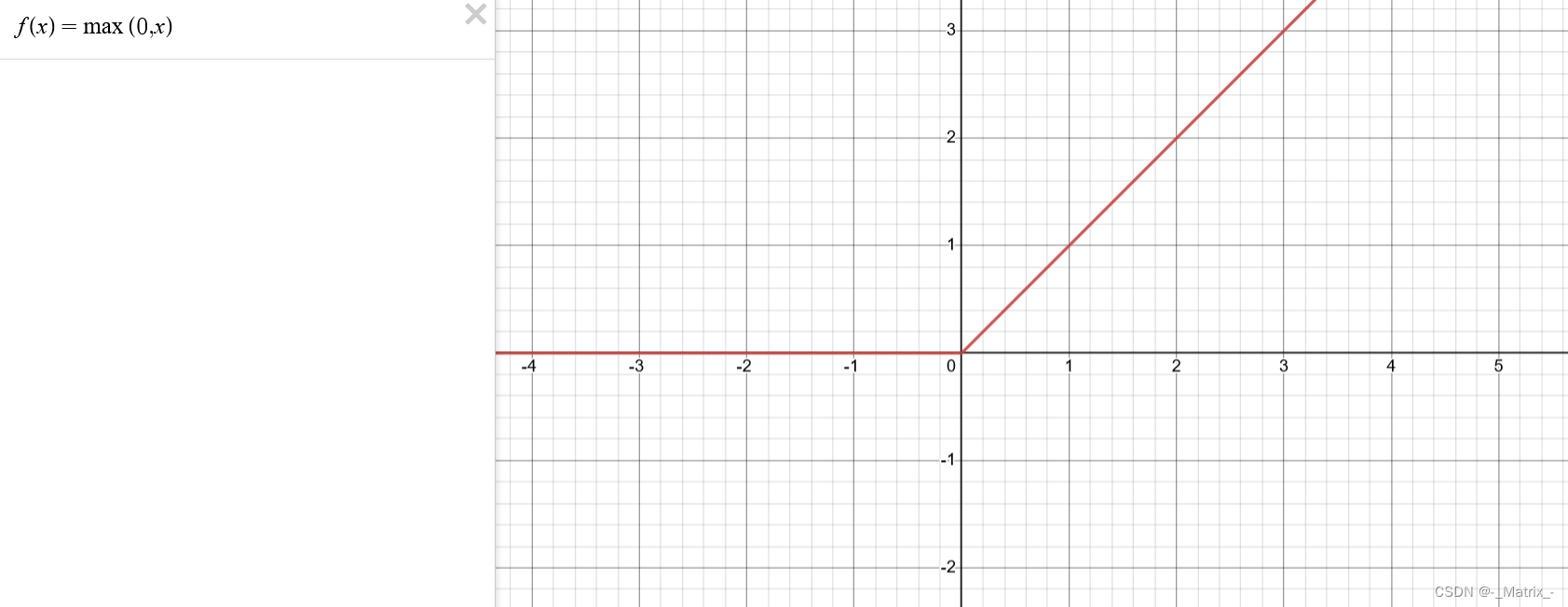
ReLU函数的定义很简单:
ReLU函数的数学表达式为:
f(x) = max(0, x)
ReLU函数在输入大于0时的导数为1,在输入小于等于0时的导数为0。
数学推导如下:
当 x > 0 时,ReLU函数为 f(x) = x。其导数为:
f'(x) = 1
当 x <= 0 时,ReLU函数为 f(x) = 0。其导数为:
f'(x) = 0
以下是使用C++实现ReLU激活函数的示例代码:
// ReLU函数的实现
double relu(double x) {
return (x > 0) ? x : 0;
}
// ReLU函数的导数实现
double relu_derivative(double x) {
return (x > 0) ? 1 : 0;
}
在这个示例代码中,relu()函数接受一个double类型的输入值x,并返回计算得到的ReLU函数的输出值。在函数内部,使用条件运算符(三元运算符)判断x是否大于0,如果是,则返回x,否则返回0。
在main()函数中,我们提供一个示例输入值x,然后调用relu()函数计算输出结果,并使用printf()函数打印结果。
这只是一个简单的示例代码,您可以根据自己的需求进行扩展和修改。
即,对于输入x,如果x大于0,则输出x,否则输出0。
ReLU函数优缺点:
优点:
- 简单有效:ReLU函数的计算非常简单,只需比较输入和0的大小并取最大值。这使得ReLU函数的计算速度非常快,尤其对于大规模深度神经网络而言,具有重要意义。
- 解决梯度消失问题:相对于Sigmoid和Tanh等传统激活函数,ReLU函数在正区间(输入大于0)上具有线性特性,梯度恒定为1,不会出现梯度消失问题。这有助于有效传播梯度,促进模型的收敛。
- 增强稀疏性:ReLU函数在负区间(输入小于0)上的输出值为0,这种“激活稀疏性”可以使得神经网络中的许多神经元处于非激活状态,从而减少参数冗余和计算负载,提高模型的效率和泛化能力。
缺点:
- Dead ReLU问题:当输入小于等于0时,ReLU函数的输出恒为0,这时该神经元对应的权重无法更新,可能会导致神经元“死亡”,不再对任何输入产生响应。这一问题在训练过程中需要特别注意,可以通过使用Leaky ReLU或其他变种来缓解。
- 不是零中心化:ReLU函数的输出范围是从0开始的正半轴,不是以0为中心的。这可能导致某些优化算法对权重的更新过程受到一定影响。
综上所述,ReLU函数由于其简单性、解决梯度消失问题的能力和稀疏性增强的特性,成为了深度学习中最常用的激活函数之一。然而,在使用ReLU函数时,需要注意Dead ReLU问题和零中心化的影响,可能需要采取一些技巧和变种来处理这些问题。
Leaky ReLU激活函数
Leaky ReLU (Rectified Linear Unit) 是一种常用的激活函数,它是对传统的 ReLU 函数的改进。ReLU 函数在输入为负数时输出为零,这可能导致神经元的死亡,即该神经元在训练过程中不再激活。
为了解决这个问题,Leaky ReLU 引入了一个小的斜率(slope)参数,当输入为负数时,它会乘以这个斜率而不是输出零。这样,Leaky ReLU 允许一小部分负值通过,并给神经元提供了一个非零的输出。
Leaky ReLU 函数的数学定义如下:
f(x) = max(ax, x)
其中,a是一个小于1的正数,用来控制负值区域的斜率。
为了计算Leaky ReLU函数的导数,需要分别考虑两个区域:x > 0 和 x <= 0。
当 x > 0 时,函数的导数为1,即 f'(x) = 1。
当 x <= 0 时,函数的导数为 a,即 f'(x) = a。
因此,Leaky ReLU函数的导数可以表示为:
f'(x) = 1, if x > 0
a, if x <= 0
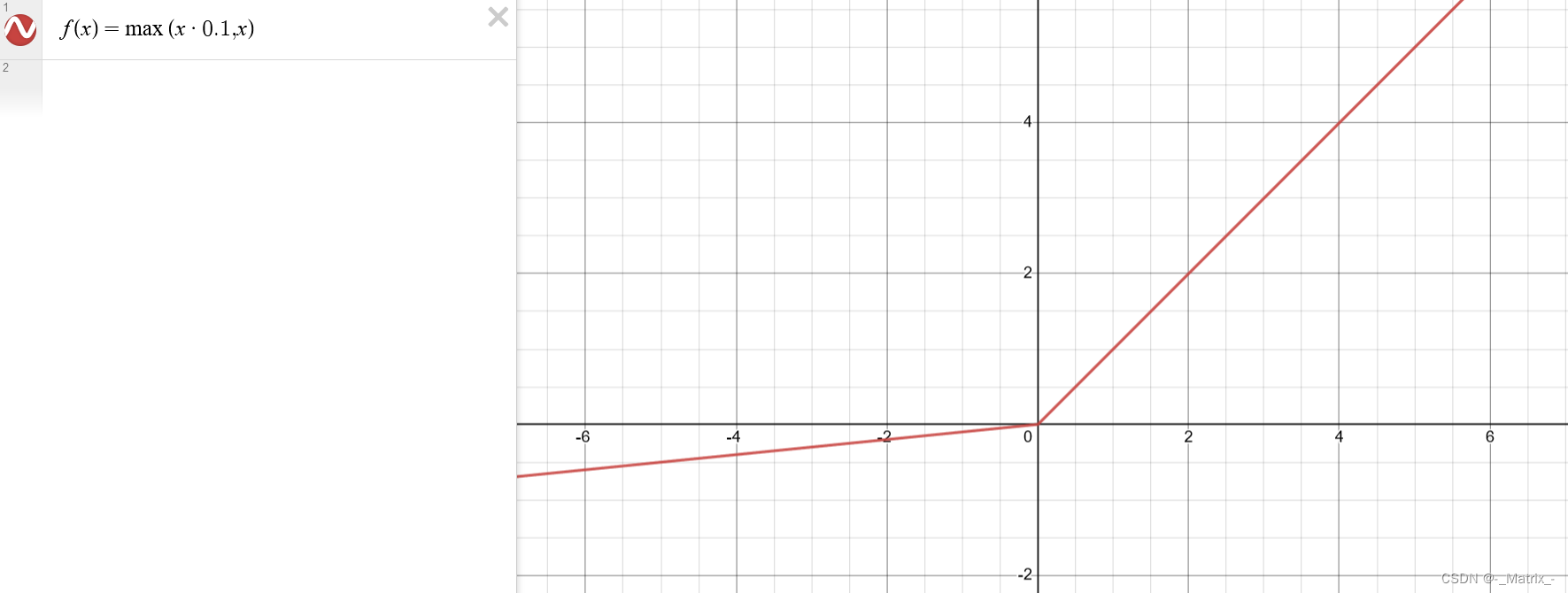
其中,a 是一个小的正数,通常取较小的值,如0.01。当 a = 0 时,Leaky ReLU 退化为传统的 ReLU 函数。
Leaky ReLU 的主要优点是它在解决梯度消失问题方面比传统的 ReLU 函数更有效。由于在负值区域存在斜率,Leaky ReLU 可以传播梯度,使得神经网络的训练更稳定。此外,Leaky ReLU 保留了大部分的稀疏激活性质,即只有少数神经元被激活,这有助于减少模型的复杂性。
然而,Leaky ReLU 也存在一些缺点。由于负值区域的斜率是一个固定的超参数,它需要手动选择,并且可能会对模型的性能产生一定的影响。此外,Leaky ReLU 在解决梯度死亡问题方面仍然不如一些其他激活函数,如 ELU (Exponential Linear Unit) 或 SELU (Scaled Exponential Linear Unit)。
在实践中,Leaky ReLU 经常被用作默认的激活函数之一,并在很多深度学习模型中取得了良好的效果。
Leaky ReLU 的优缺点:
优点包括:
-
解决了梯度消失问题:相对于传统的 ReLU 函数,Leaky ReLU 具有非零的负斜率,这使得它能够传播梯度,有效地缓解了梯度消失的问题。
-
保留稀疏激活性质:Leaky ReLU 仍然保留了传统 ReLU 的稀疏激活性质,即只有少数神经元被激活,从而减少了模型的复杂性。
-
实现简单:Leaky ReLU 的计算简单,只需在传统的 ReLU 函数中引入一个小的斜率参数即可。
缺点:
-
需要手动选择超参数:Leaky ReLU 的性能依赖于负斜率参数的选择,这需要手动调整。选择不当的斜率参数可能会导致模型的性能下降。
-
可能存在神经元死亡问题:尽管 Leaky ReLU 解决了传统 ReLU 中负输入值输出为零的问题,但仍然可能存在神经元死亡问题。当斜率参数选择得过小时,仍有一部分神经元在训练过程中不会被激活。
-
不是最优选择:虽然 Leaky ReLU 在某些情况下表现良好,但并不是最优的激活函数选择。一些其他激活函数,如 ELU 或 SELU,可以在解决梯度消失问题方面更有效,并提供更平滑的激活函数曲线。
以下是使用C++实现Leaky ReLU激活函数的示例代码:
// Leaky ReLU函数的实现
double leakyRelu(double x, double alpha) {
return (x > 0) ? x : alpha * x;
}
// Leaky ReLU函数的导数实现
double leakyReluDerivative(double x, double alpha) {
return (x > 0) ? 1 : alpha;
}
int main() {
double x = -2.0; // 示例输入值
double alpha = 0.1; // Leaky ReLU的负斜率
// 调用Leaky ReLU函数计算输出
double result = leakyRelu(x, alpha);
// 输出结果
printf("Leaky ReLU(%f) = %f\n", x, result);
return 0;
}
Parametric ReLU激活函数 (自适应Leaky ReLU激活函数)
Parametric ReLU (PReLU) 是一种激活函数,它是对传统的 ReLU 函数的改进。与 Leaky ReLU 不同,PReLU 的负斜率不是固定的超参数,而是可以通过学习得到的可训练参数。
PReLU 的数学定义如下:
f(x) = max(ax, x)
其中a是一个可学习的参数,可以根据数据进行训练得到。当a为0时,PReLU函数退化为普通的ReLU函数。
PReLU函数的导数在正区间(x>0)上为1,而在负区间(x<0)上为a。下面我们来推导PReLU函数的导数。
对于x>0,PReLU函数的导数为1:
f'(x) = 1,(x > 0)
对于x<0,PReLU函数的导数为a:
f'(x) = a,(x < 0)
在x=0的位置,PReLU函数的导数存在争议,通常会将其定义为左导数和右导数的平均值,即:
f'(x) = (1 + a) / 2,(x = 0)
这样,PReLU函数的导数就可以在所有实数范围内连续定义。
其中,a 是一个可训练的参数,它可以根据数据进行学习和调整。当 a = 0 时,PReLU 退化为传统的 ReLU 函数。
Parametric ReLU优缺点:
优点:
-
自适应负斜率:PReLU 允许负斜率参数根据数据进行学习,这使得激活函数能够自适应地调整负值区域的斜率。这提供了更大的灵活性和表达能力,适应不同类型的数据分布和模型复杂度。
-
解决了梯度消失问题:与传统的 ReLU 类似,PReLU 仍然能够缓解梯度消失问题,通过保留正值输入的激活性。
缺点:
-
参数学习的复杂性:与固定斜率的 Leaky ReLU 不同,PReLU 需要学习一个额外的参数,这增加了模型的复杂性。参数的学习过程需要更多的计算和存储资源,并且可能需要更多的数据和训练时间。
-
过拟合的风险:PReLU 具有更高的模型灵活性,这也可能导致过拟合的风险增加。过度学习负斜率参数可能使模型对训练数据过度拟合,从而影响泛化能力。
在实践中,PReLU 可以作为一种有效的激活函数,特别适用于深层神经网络和大规模数据集。然而,由于其参数学习的复杂性,需要在具体问题和实验中进行评估和比较,以确定是否使用 PReLU 和如何设置参数。
以下是使用C++实现PReLU激活函数及其导数的示例代码:
#include <cmath>
// PReLU函数的实现
double prelu(double x, double a) {
return (x > 0) ? x : a * x;
}
// PReLU函数的导数实现
double preluDerivative(double x, double a) {
return (x > 0) ? 1 : a;
}
ELU激活函数
ELU (Exponential Linear Unit) 是一种激活函数,它在负输入值区域具有非零斜率,且输出值有指数级的下降。ELU 在解决梯度消失问题的同时,还能够处理负输入值的情况,避免了神经元的死亡现象。
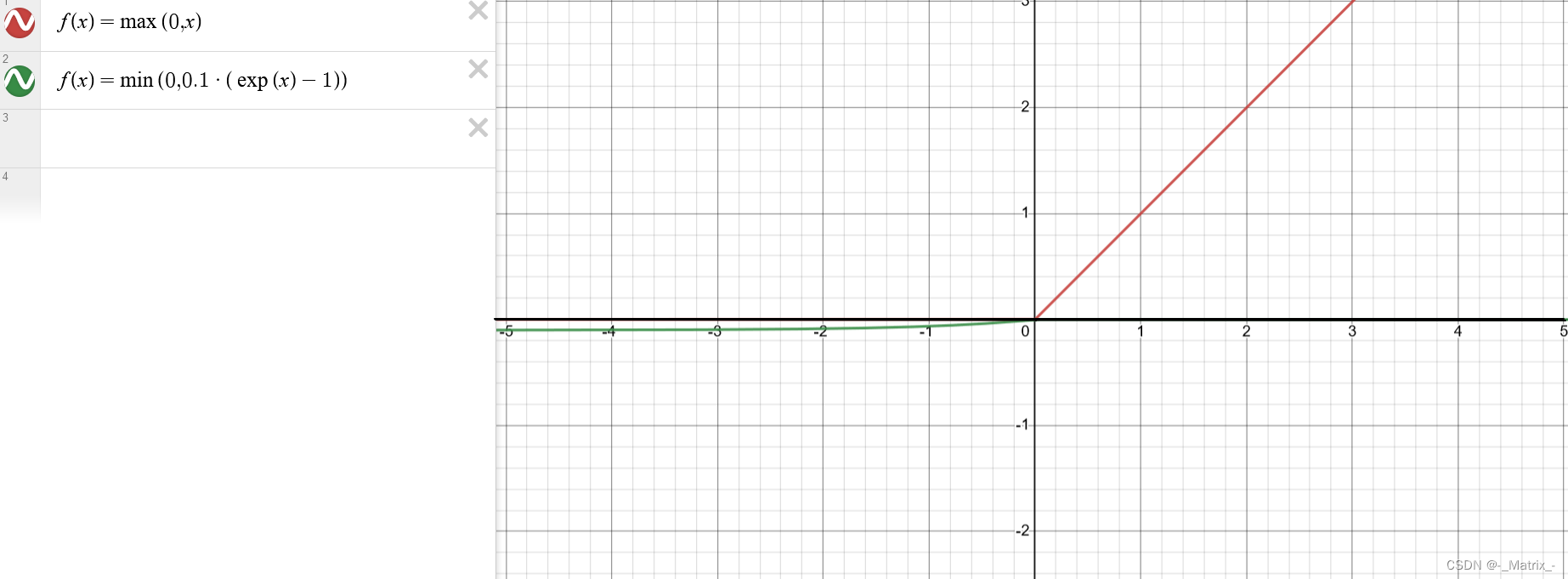
ELU 的数学定义如下:
ELU函数的定义如下:
f(x) =
x, if x >= 0
alpha * (exp(x) - 1), if x < 0
其中,alpha是一个超参数,用于控制负值区域的斜率。通常情况下,alpha取一个较小的正数,如0.1或0.2。
ELU函数的导数计算如下:
f'(x) =
1, if x >= 0
f(x) + alpha, if x < 0
接下来,我们将对ELU函数的导数进行数学推导。
假设y = f(x)是ELU函数的输出,其中x表示输入值,y表示输出值。
1. 对于x >= 0的情况,ELU函数的导数为1。这是因为在x >= 0时,ELU函数是线性的,导数恒定为1。
2. 对于x < 0的情况,我们将f(x) = alpha * (exp(x) - 1)代入导数的定义式中,得到:
f'(x) = d/dx (alpha * (exp(x) - 1))
= alpha * d/dx (exp(x) - 1)
根据指数函数的导数性质,d/dx (exp(x)) = exp(x),则:
f'(x) = alpha * exp(x)
因此,当x < 0时,ELU函数的导数为f(x) + alpha。
这样,我们得到了ELU函数的导数公式。
其中,alpha 是一个超参数,控制负输入值区域的斜率。通常,alpha 的值设置为一个小的正数,如 0.01。
ELU 的优点包括:
-
解决梯度消失问题:ELU 具有非零斜率,可以传播梯度,有效地解决梯度消失的问题。
-
平滑的曲线:ELU 在负输入值区域具有平滑的曲线,相对于 Leaky ReLU 和 PReLU,它更平滑并且具有更好的连续性。
-
处理负输入值:ELU 可以处理负输入值,并且在该区域具有非零斜率。这可以避免神经元的死亡问题,并允许网络学习更多的特征。
-
激活值的范围:ELU 的输出范围是 (-∞, +∞),相比于其他激活函数,如 sigmoid 和 tanh,ELU 不会导致输出值饱和,更有利于模型的学习。
缺点:
-
计算复杂性:ELU 函数的计算相对于传统的激活函数来说较为复杂,特别是在负输入值区域需要进行指数计算,这可能会增加模型的计算成本。
-
非单调性:ELU 在整个输入范围内都是单调递增的,这可能导致网络的收敛速度较慢,特别是在某些优化算法中。
在实践中,ELU 通常被认为是一种有效的激活函数,尤其适用于解决梯度消失问题和处理负输入值的情况。然而,对于特定的任务和数据集,需要根据实验和模型的性能来选择和调整激活函数。
下面是使用C++实现ELU函数及其导数的示例代码:
#include <cmath>
// ELU函数的实现
double elu(double x, double alpha) {
return (x >= 0) ? x : alpha * (exp(x) - 1);
}
// ELU函数的导数实现
double elu_derivative(double x, double alpha) {
return (x >= 0) ? 1 : elu(x, alpha) + alpha;
}
int main() {
double x = -2.0; // 示例输入值
double alpha = 0.1; // ELU的alpha值
// 调用ELU函数计算输出
double result = elu(x, alpha);
// 调用ELU函数的导数计算
double derivative = elu_derivative(x, alpha);
// 输出结果
printf("ELU(%f) = %f\n", x, result);
printf("ELU的导数(%f) = %f\n", x, derivative);
return 0;
}
SeLU激活函数
SeLU (Scaled Exponential Linear Unit) 是一种激活函数,它在负输入值区域具有非零斜率,并且在正输入值区域具有一个大于1的缩放因子。SeLU 在解决梯度消失问题的同时,还能够使得每个神经元的输出接近零均值和单位方差,从而提高神经网络的稳定性和表示能力。
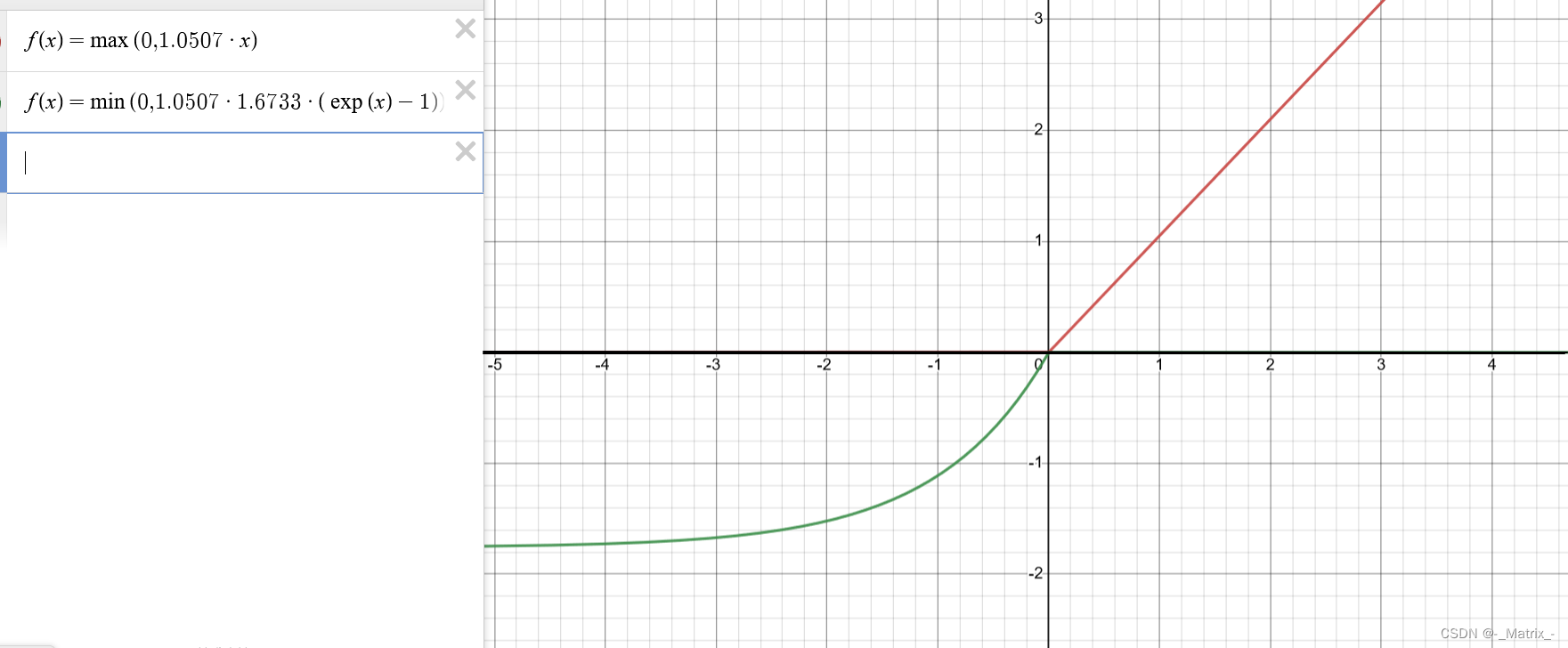
SeLU 的数学定义如下:
f(x) = { scale * x, if x > 0,
scale * alpha * (exp(x) - 1), if x <= 0 }
其中,scale和alpha是可调节的超参数,通常设置为scale = 1.0507和alpha = 1.6733。SeLU函数在输入小于0时,具有指数增长的形式,有助于处理负值。而在输入大于0时,与线性函数相似。
现在,我们将对SeLU激活函数的导数进行推导。
首先,我们计算SeLU函数的一阶导数:
f'(x) = { scale * 1, if x > 0,
scale * alpha * exp(x) , if x <= 0 }
根据SeLU函数的定义,我们可以将输入分为两个区域讨论:
- 当
x > 0时,导数为1,因为在这个区域,SeLU函数的形式与线性函数相似。 - 当
x <= 0时,导数为alpha * exp(x),因为在这个区域,SeLU函数的形式是指数增长的。
对于SeLU函数的导数,我们可以进一步计算二阶导数:
f''(x) = { scale * 0, if x > 0,
scale * alpha * exp(x) , if x <= 0 }
同样地,在 x > 0 的区域,二阶导数为0。而在 x <= 0 的区域,二阶导数为 alpha * exp(x)。
综上所述,SeLU激活函数在 x > 0 的区域具有导数为1的线性形式,在 x <= 0 的区域具有指数增长的形式。
其中,scale 和 alpha 是两个超参数,用于缩放和调整激活函数。通常,scale 的值设置为 1.0507,alpha 的值设置为 1.6733。
SeLU 的优点包括:
-
解决梯度消失问题:SeLU 具有非零斜率,在负输入值区域能够传播梯度,有效地解决梯度消失的问题。
-
零均值和单位方差:SeLU 的设计使得每个神经元的输出在训练过程中接近零均值和单位方差,从而提高神经网络的稳定性和表示能力。
-
自适应性质:SeLU 的缩放因子可以自适应地调整输出值的范围,使得神经网络在不同的数据分布和模型复杂度下都能表现良好。
缺点:
-
不适用于所有情况:SeLU 的设计基于假设输入数据具有零均值和单位方差,因此在某些情况下可能不适用。如果输入数据具有不同的分布特征,可能需要考虑其他激活函数。
-
计算复杂性:SeLU 的计算相对于传统的激活函数来说较为复杂,特别是在负输入值区域需要进行指数计算。这可能会增加模型的计算成本。
在实践中,SeLU 通常被认为是一种有效的激活函数,尤其适用于深层神经网络和大规模数据集。然而,需要根据具体问题和实验进行评估和比较,以确定是否使用 SeLU 和如何设置超参数。
下面是使用C++实现SeLU激活函数及其一阶导数的示例代码:
#include <cmath>
// SeLU激活函数的实现
double selu(double x, double scale = 1.0507, double alpha = 1.6733) {
return (x > 0) ? (scale * x) : (scale * alpha * (exp(x) - 1));
}
// SeLU激活函数的一阶导数实现
double selu_derivative(double x, double scale = 1.0507, double alpha = 1.6733) {
return (x > 0) ? scale : (scale * alpha * exp(x));
}
int main() {
double x = 2.0; // 示例输入值
// 调用SeLU函数计算输出
double result = selu(x);
// 调用SeLU函数的一阶导数计算输出
double derivative = selu_derivative(x);
// 输出结果
printf("SeLU(%f) = %f\n", x, result);
printf("SeLU derivative(%f) = %f\n", x, derivative);
return 0;
}
在这个示例代码中,selu()函数接受一个double类型的输入值x,并返回计算得到的SeLU函数的输出值。selu_derivative()函数计算SeLU函数的一阶导数。scale和alpha分别是SeLU函数的超参数,可以根据需要进行调整。
在main()函数中,我们提供一个示例输入值x,然后调用selu()函数和selu_derivative()函数分别计算输出结果和导数,并使用printf()函数打印结果。
这只是一个简单的示例代码,您可以根据自己的需求进行扩展和修改。
Softmax 激活函数
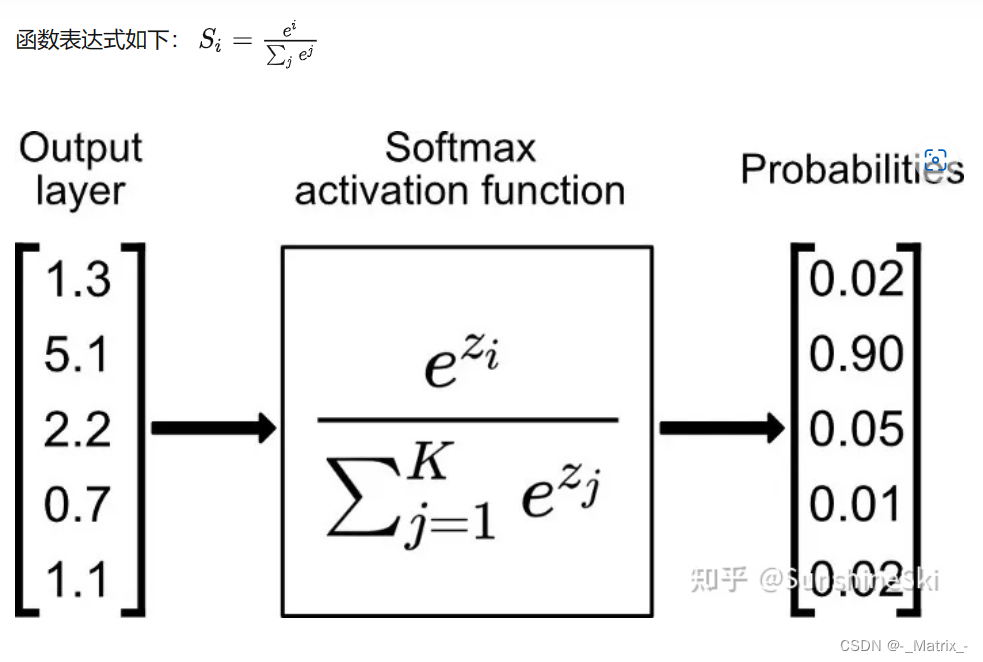
Softmax 是一种常用的激活函数,它常用于多类别分类任务中。Softmax 函数将一组实数转换为表示概率分布的向量,使得所有元素的和等于 1,并将每个元素映射到一个 [0, 1] 的范围内。
Softmax 函数的数学定义如下:
softmax(x_i) = exp(x_i) / sum(exp(x_j))
其中,x_i 表示输入向量的第 i 个元素,exp 表示指数函数,sum 表示对所有元素的指数函数求和。
Softmax 函数的输出可以解释为输入向量中每个元素对应的概率分布,因此在多类别分类任务中非常有用。最大的输出值对应概率最高的类别。
Softmax 函数的优点包括:
-
输出概率分布:Softmax 函数将输入映射到概率分布,使得每个元素都表示了一个类别的概率。这对于多类别分类问题非常有用,可以得到对不同类别的置信度估计。
-
可导性:Softmax 函数是可导的,这意味着可以使用梯度下降等优化算法来训练使用 Softmax 函数的神经网络。
缺点:
-
敏感性:Softmax 函数对输入的绝对大小非常敏感,这可能导致数值不稳定性。在输入中存在很大的差异时,Softmax 可能会输出接近于 0 或接近于 1 的值,使得梯度下降算法更难以收敛。
-
多类别不平衡:在多类别分类问题中,如果存在类别不平衡,Softmax 可能倾向于预测数量较多的类别。
在实践中,Softmax 函数通常与交叉熵损失函数结合使用,用于多类别分类任务中。它在神经网络中广泛应用,并且经常作为输出层的激活函数。
在 C++ 中实现 Softmax 激活函数时,我们可以使用以下代码示例:

当Softmax函数遇到非常大的数值时,可能会导致数值不稳定的问题。这主要是因为Softmax函数的定义涉及指数运算,如果输入值很大,那么指数函数的输出可能会迅速增加到超过计算机可以表示的范围。
Softmax函数的定义如下:
Softmax ( x ) i = e x i ∑ j e x j \text{Softmax}(x)_i = \frac{e^{x_i}}{\sum_j e^{x_j}} Softmax(x)i=∑jexjexi
其中 x x x是输入向量。
为了解决这个问题,可以从输入向量中减去其最大值,然后再应用Softmax。这样做不会改变Softmax的输出,因为分子和分母都被同一个数值除以。但是,通过减去最大值,指数运算的输入范围会减小,从而避免了数值溢出的问题。
下面是应用这种技巧后的Softmax函数定义:
Softmax ( x ) i = e x i − max ( x ) ∑ j e x j − max ( x ) \text{Softmax}(x)_i = \frac{e^{x_i - \max(x)}}{\sum_j e^{x_j - \max(x)}} Softmax(x)i=∑jexj−max(x)exi−max(x)
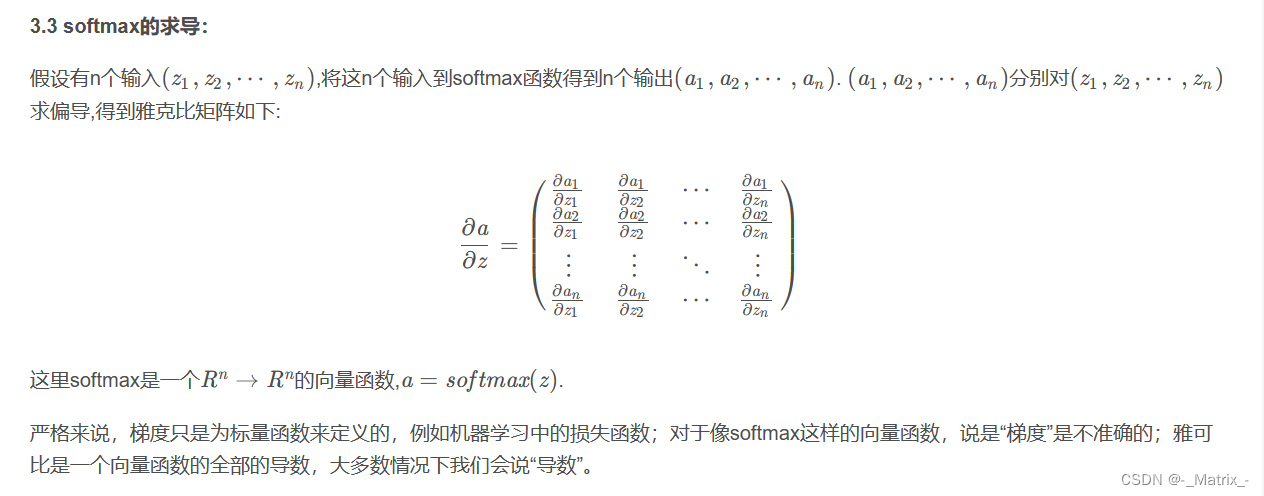
对不起,我之前的回答未涉及减去最大值后的Softmax梯度。这里是经过修改的Softmax函数(减去最大值)的梯度推导。
假设我们先计算了减去最大值后的输入向量:
y i = x i − max ( x ) y_i = x_i - \max(x) yi=xi−max(x)
然后我们计算Softmax:
s i = e y i ∑ j e y j s_i = \frac{e^{y_i}}{\sum_j e^{y_j}} si=∑jeyjeyi
关于原始输入( x )的梯度可以由以下推导得到:
对于 i = j i = j i=j:
∂ s i ∂ x i = s i ⋅ ( 1 − s i ) \frac{\partial s_i}{\partial x_i} = s_i \cdot (1 - s_i) ∂xi∂si=si⋅(1−si)
对于 i ≠ j i \neq j i=j:
∂ s i ∂ x j = − s i ⋅ s j \frac{\partial s_i}{\partial x_j} = -s_i \cdot s_j ∂xj∂si=−si⋅sj
通过减去最大值,我们不会改变Softmax梯度的形式,因为我们只是从输入中减去了一个常数(最大值),并没有改变Softmax函数相对于其输入的梯度。所以,无论是否减去最大值,Softmax梯度的形式都是一样的。
当然,以下是使用C++实现Softmax函数(包括减去最大值以提高数值稳定性)及其梯度的代码:
```cpp
#include <vector>
#include <cmath>
#include <algorithm>
// Softmax function
std::vector<double> softmax(const std::vector<double>& x) {
std::vector<double> result(x.size());
double maxVal = *std::max_element(x.begin(), x.end());
double sum = 0.0;
for (int i = 0; i < x.size(); ++i) {
result[i] = std::exp(x[i] - maxVal);
sum += result[i];
}
for (int i = 0; i < x.size(); ++i) {
result[i] /= sum;
}
return result;
}
// Softmax gradient
std::vector<std::vector<double>> softmax_gradient(const std::vector<double>& x) {
std::vector<double> s = softmax(x);
std::vector<std::vector<double>> gradient(x.size(), std::vector<double>(x.size(), 0.0));
for (int i = 0; i < x.size(); ++i) {
for (int j = 0; j < x.size(); ++j) {
if (i == j) {
gradient[i][j] = s[i] * (1 - s[i]);
} else {
gradient[i][j] = -s[i] * s[j];
}
}
}
return gradient;
}
在这个代码中,softmax函数接受一个包含原始输入的向量,并返回Softmax函数的输出。softmax_gradient函数接受同样的输入,并返回一个包含关于输入的Softmax梯度的二维向量。
请注意,这段代码对于实际应用来说可能还需要进一步优化和测试。在将其用于重要项目之前,请确保进行了充分的验证和测试。
在这个示例代码中,`softmaxDerivative()`函数接受一个`std::vector<double>`类型的Softmax输出向量`softmaxOutput`,并返回计算得到的Softmax函数的导数向量。函数首先计算每个元素的指数值,然后计算所有指数值的总和`sumExp`。接下来,对于每个元素,计算其导数值并进行归一化,得到最终的导数向量。
在这个示例中,我们定义了一个名为 `softmax` 的函数,它接受一个输入向量 `input`,并返回一个经过 Softmax 函数处理的输出向量。在函数内部,我们首先计算输入向量中每个元素的指数值,并累加求和。然后,我们将指数值除以总和,以得到归一化的输出向量。
在 `main` 函数中,我们给定了一个输入向量 `{1.0, 2.0, 3.0}`,然后调用 `softmax` 函数计算输出向量,并将结果打印到控制台上。
Swish 激活函数
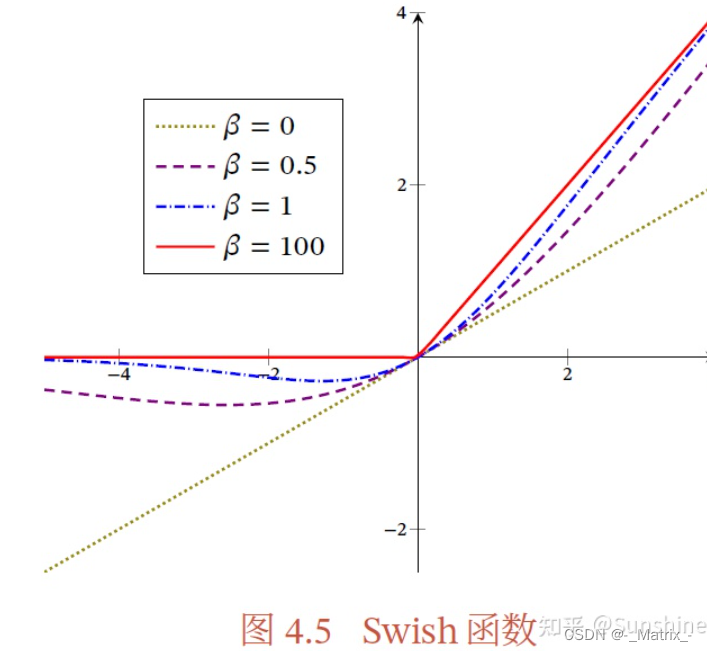
Swish 是一种激活函数,它结合了 Sigmoid 函数和线性函数。Swish 函数在接近零时具有 Sigmoid 函数的饱和性质,并在正无穷时趋近于线性函数。Swish 函数在一些深度学习任务中表现出了很好的性能,并被认为比一些传统激活函数更有效。
Swish 函数的数学定义如下:
f(x) = x * (1.0 / (1.0 + exp(-beta * x))) == Swish(x) = x * sigmoid(-beta * x)
Swish激活函数是一种近年来提出的激活函数,其数学表达式为:
Swish(x) = x * sigmoid(beta * x)
其中,sigmoid函数是常见的Sigmoid函数,beta是一个可调节的参数。
为了计算Swish函数的导数,我们首先计算Swish函数的导数对x的求导:
Swish’(x) = sigmoid(beta * x) + x * sigmoid(beta * x) * (1 - sigmoid(beta * x))
然后,我们可以将Swish函数的导数写为Swish函数本身的形式,得到一个更简洁的表示:
Swish’(x) = Swish(x) + sigmoid(beta * x) * (1 - Swish(x))
这个公式表示了Swish函数对输入x的导数。在实际编程中,可以使用这个公式来计算Swish函数的导数。
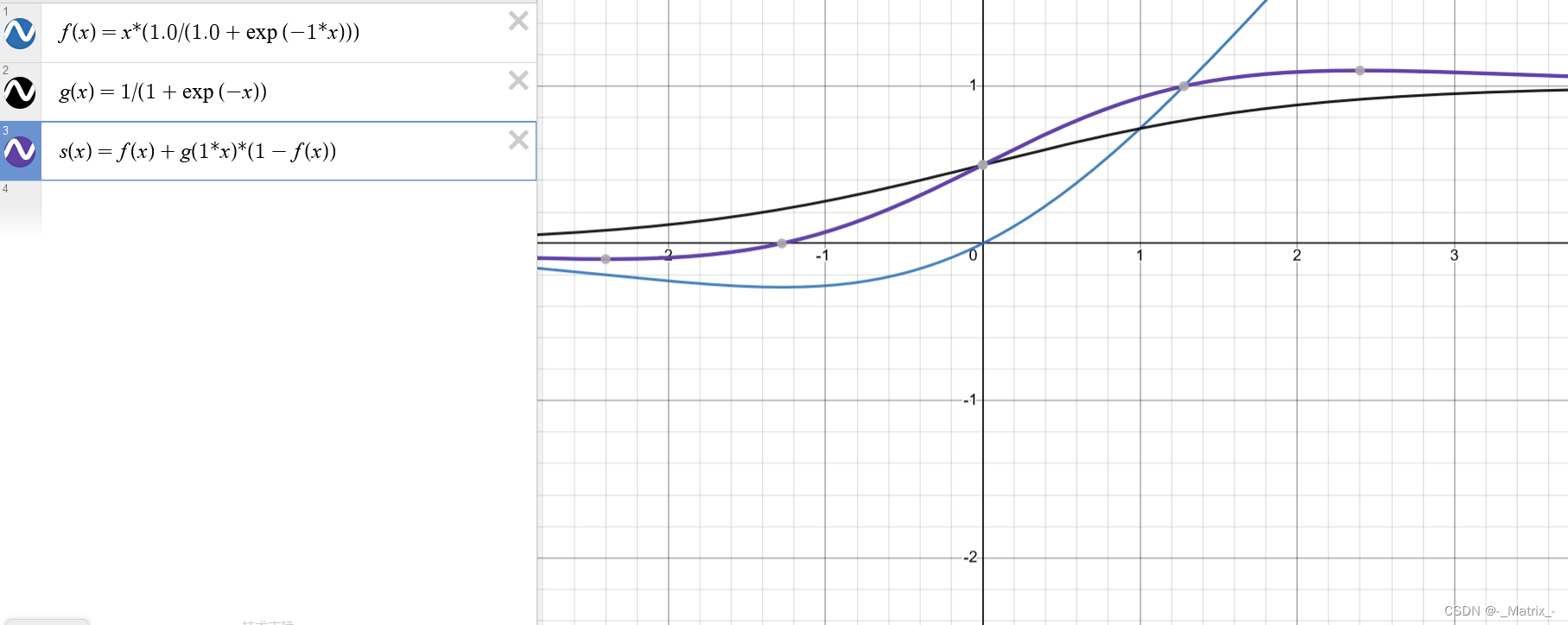
其中,sigmoid(x) 表示 Sigmoid 函数,即 1 / (1 + exp(-beta*x))。
Swish 函数的优点包括:
-
平滑性质:Swish 函数具有平滑的曲线,相比于一些分段线性函数,Swish 更连续并具有更好的可导性。
-
饱和性质:Swish 在接近零时具有 Sigmoid 函数的饱和性质,这可以缓解梯度消失问题。
-
自适应性:Swish 函数具有自适应性质,即在不同的数据分布和模型复杂度下都能表现良好。
然而,Swish 函数也存在一些限制:
-
计算复杂性:Swish 函数的计算相对于一些简单的激活函数来说较为复杂,特别是涉及到 Sigmoid 函数的计算。
-
对梯度消失问题的处理:虽然 Swish 函数可以缓解梯度消失问题,但并没有完全解决。在某些情况下,仍可能存在梯度消失或梯度爆炸的问题。
在实践中,Swish 函数通常用作激活函数应用于神经网络的隐藏层。它可以提供较好的非线性建模能力,并在一些任务中获得较好的性能。然而,对于特定的问题和模型,仍需要根据实验和评估来选择和调整激活函数。
以下是使用C++实现Swish激活函数的示例代码:
#include <cmath>
// Swish激活函数的实现
double swish(double x, double beta) {
return x * (1.0 / (1.0 + exp(-beta * x)));
}
// Swish激活函数的导数实现
double swishDerivative(double x, double beta) {
double sw = swish(x, beta);
return sw + (1.0 - sw) * (1.0 / (1.0 + exp(-beta * x)));
}
int main() {
double x = 2.0; // 示例输入值
double beta = 1.0; // Swish函数的参数
// 调用Swish函数计算输出
double result = swish(x, beta);
// 调用Swish函数的导数计算输出
double derivative = swishDerivative(x, beta);
// 输出结果
printf("Swish(%f) = %f\n", x, result);
printf("Swish'(%f) = %f\n", x, derivative);
return 0;
}
Maxout激活函数
Maxout 是一种激活函数,它通过比较多个线性函数的输出并选择最大的那个来进行非线性建模。Maxout 可以学习多个线性函数的参数,从而增强神经网络的表达能力。
Maxout 函数的数学定义如下:
f(x) = max(w_1 * x + b_1, w_2 * x + b_2, ..., w_k * x + b_k)
其中,w_i 和 b_i 是 Maxout 函数中第 i 个线性函数的权重和偏置,k 是线性函数的个数。Maxout 函数通过选择产生最大输出的线性函数来提供非线性特性。
Maxout 函数的优点包括:
-
多线性函数:Maxout 函数可以学习多个线性函数的参数,从而增强了神经网络的表达能力。每个线性函数可以捕捉不同的特征和模式。
-
非线性性质:Maxout 函数通过选择最大输出来提供非线性特性。这使得神经网络能够更好地适应复杂的数据分布和模式。
-
梯度传播:Maxout 函数在正向传播和反向传播过程中能够有效地传播梯度,从而促进模型的训练和收敛。
缺点:
-
参数量增加:Maxout 函数的参数量随着线性函数的个数增加而增加。这可能导致模型的复杂性增加,需要更多的计算和存储资源。
-
计算复杂性:Maxout 函数的计算相对于一些简单的激活函数来说较为复杂,特别是当线性函数的个数较多时。
在实践中,Maxout 函数通常用作激活函数应用于神经网络的隐藏层。它可以提供较强的非线性建模能力,并在一些任务中获得较好的性能。然而,对于特定的问题和模型,仍需要根据实验和评估来选择和调整激活函数。
Maxout 激活函数在 C++ 中的实现可以如下所示:
#include <iostream>
#include <vector>
#include <algorithm>
double maxout(const std::vector<double>& input, const std::vector<double>& weights, const std::vector<double>& biases) {
std::vector<double> max_values;
// 计算每个线性函数的值
for (size_t i = 0; i < weights.size(); ++i) {
double value = weights[i] * input[i] + biases[i];
max_values.push_back(value);
}
// 选择最大值
double max_output = *std::max_element(max_values.begin(), max_values.end());
return max_output;
}
// Maxout激活函数的导数实现
double maxout_derivative(double x1, double x2) {
return (x1 > x2) ? 1 : 0;
}
int main() {
std::vector<double> input = {1.0, 2.0, 3.0};
std::vector<double> weights = {0.5, 0.8, 1.2};
std::vector<double> biases = {-0.2, 0.1, 0.5};
double output = maxout(input, weights, biases);
std::cout << "Input: ";
for (double val : input) {
std::cout << val << " ";
}
std::cout << std::endl;
std::cout << "Output: " << output << std::endl;
return 0;
}
在上面的代码中,我们定义了一个名为 maxout 的函数,它接受输入向量 input、权重向量 weights 和偏置向量 biases,并返回 Maxout 函数的输出。在函数内部,我们计算了每个线性函数的输出值,并将它们保存在 max_values 向量中。然后,我们选择 max_values 中的最大值作为 Maxout 函数的输出。
在 main 函数中,我们给定了一个输入向量 {1.0, 2.0, 3.0},以及对应的权重向量和偏置向量。然后调用 maxout 函数计算输出值,并将结果打印到控制台上。
Softplus激活函数
Softplus 是一种平滑的激活函数,它在正输入值区域具有非线性特性,并且在负输入值区域趋近于零。Softplus 函数常用于神经网络的隐藏层,可以提供一种非线性建模能力。
Softplus 函数的数学定义如下:
Softplus函数是一种平滑的激活函数,其定义为:
f(x) = log(1 + exp(x))
要计算Softplus函数的导数,我们需要对其进行求导。首先,我们将Softplus函数表示为指数函数的形式:
f(x) = log(1 + exp(x)) = log(exp(0) + exp(x))
然后,我们可以使用链式法则对其进行求导。设g(x) = exp(x),则:
f(x) = log(g(0) + g(x))
对f(x)进行求导,可以得到:
f'(x) = (g'(0) + g'(x)) / (g(0) + g(x))
其中,g'(x)表示指数函数的导数,即g'(x) = exp(x)。
代入g(0) = exp(0) = 1,g'(0) = exp(0) = 1,得到:
f'(x) = (1 + exp(x)) / (1 + exp(0)) = (1 + exp(x)) / 2
因此,Softplus函数的导数为:
f'(x) = (1 + exp(x)) / 2
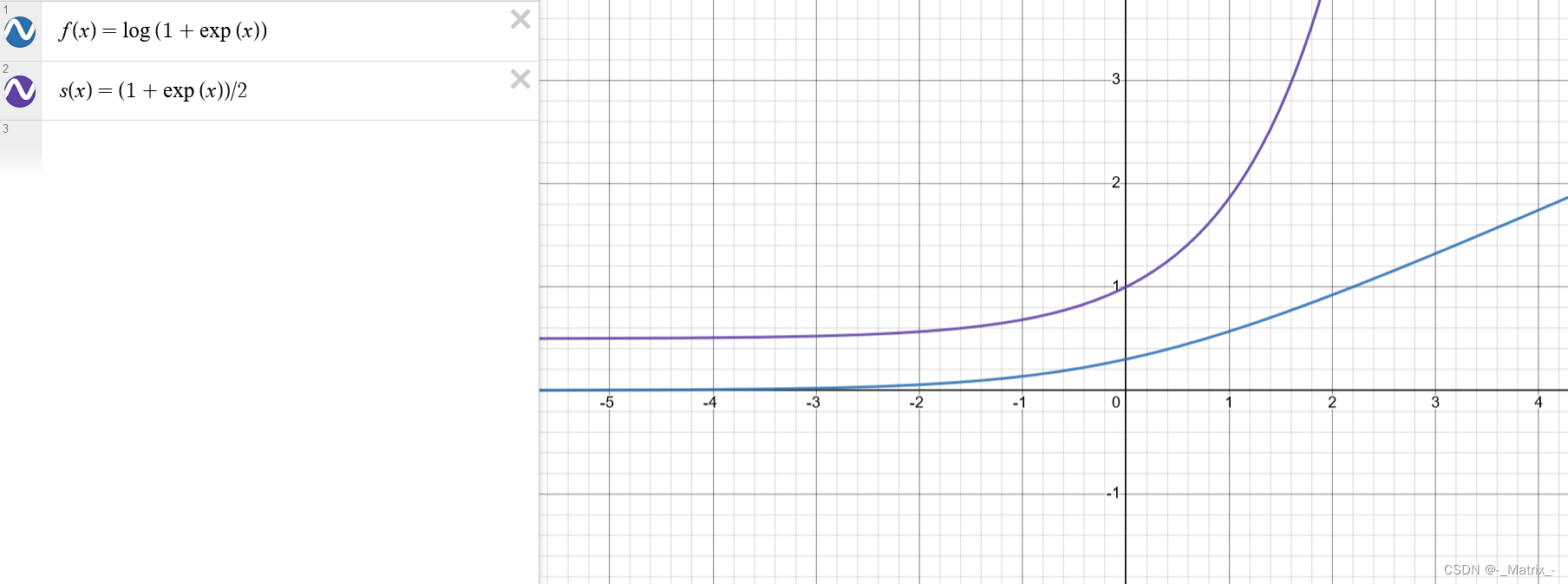
其中,exp 表示指数函数,log 表示自然对数函数。
Softplus 函数的优点包括:
-
非线性性质:Softplus 函数在正输入值区域具有非线性特性,使得神经网络能够对复杂的数据分布进行建模。
-
平滑性质:Softplus 函数是平滑的,具有连续的导数,这有助于优化算法在训练过程中更好地进行梯度传播和参数更新。
-
输出范围:Softplus 函数的输出范围是 (0, +∞),这使得它适用于需要非负输出的任务。
然而,Softplus 函数也存在一些限制:
-
梯度饱和:在输入值非常大的情况下,Softplus 函数的梯度可能会接近于零,导致梯度消失问题。
-
对负输入值的处理:Softplus 函数在负输入值区域趋近于零,可能无法处理负输入值的情况。
在实践中,Softplus 函数通常用作神经网络的隐藏层激活函数。然而,对于特定的问题和模型,仍需要根据实验和评估来选择和调整激活函数。
在 C++ 中实现 Softplus 激活函数,可以使用以下代码示例:
#include <iostream>
#include <cmath>
// Softplus函数的实现
double softplus(double x) {
return log(1 + exp(x));
}
// Softplus函数的导数实现
double softplusDerivative(double x) {
return (1 + exp(x)) / 2;
}
int main() {
double x = 2.0; // 示例输入值
// 调用Softplus函数计算输出
double result = softplus(x);
// 输出结果
printf("Softplus(%f) = %f\n", x, result);
// 调用Softplus函数的导数计算输出
double derivative = softplusDerivative(x);
// 输出导数结果
printf("Softplus Derivative(%f) = %f\n", x, derivative);
return 0;
}