UidGenerator(百度)
一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下:

- sign(1bit):符号位(标识正负),始终为 0,代表生成的 ID 为正数。
- delta seconds (28 bits):当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约 8.7 年
- worker id (22 bits):机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
- sequence (13 bits):每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的组成不太一样。并且,上面这些参数我们都可以自定义。
自 18 年后,UidGenerator 就基本没有再维护了

Leaf(美团)
美团开源的一个分布式 ID 解决方案 ,提供了 号段模式 和 Snowflake(雪花算法) 这两种模式来生成分布式 ID。
支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId)
Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段
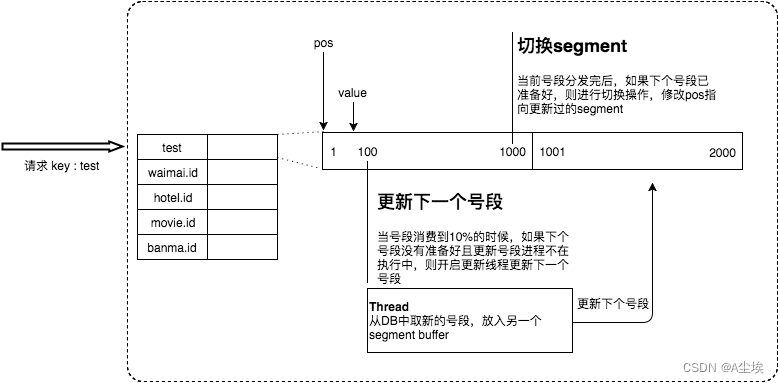
Tinyid(滴滴)
滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
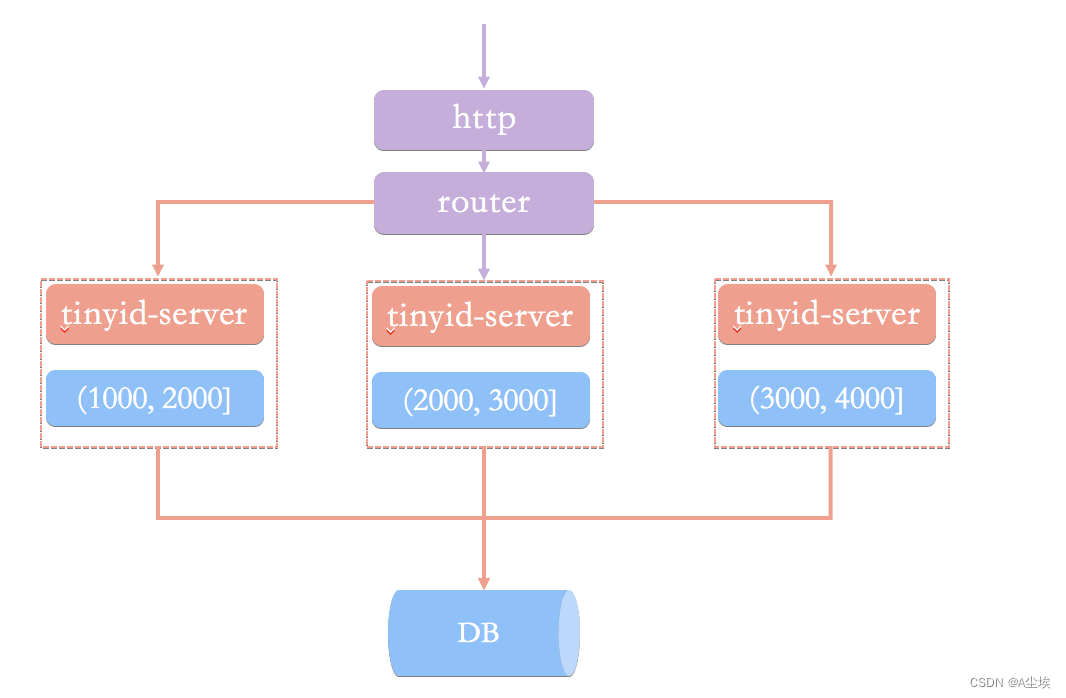
在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
这种方案有什么问题呢?在我看来(Tinyid 官方 wiki 也有介绍到),主要由下面这 2 个问题:
- 获取新号段的情况下,程序获取唯一 ID 的速度比较慢。
- 需要保证 DB 高可用,这个是比较麻烦且耗费资源的。
除此之外,HTTP 调用也存在网络开销。
Tinyid 的原理比较简单,其架构如下图所示:
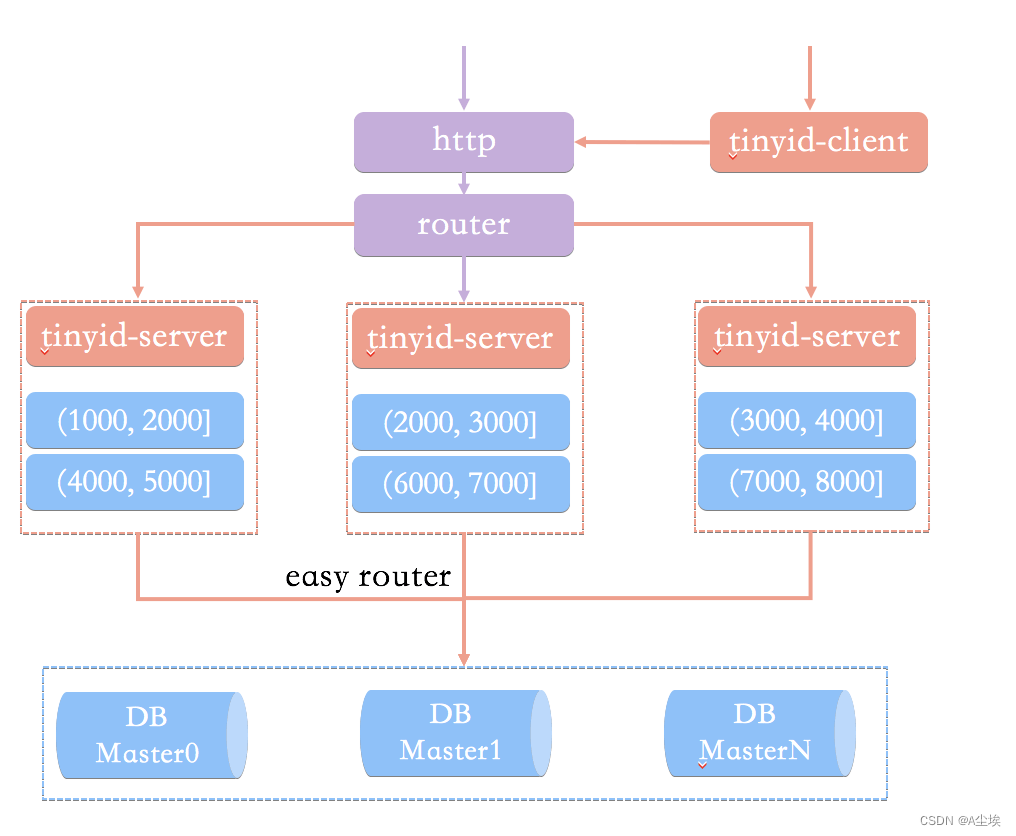
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
- 双号段缓存:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
- 增加多 db 支持:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
- 增加 tinyid-client:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
IdGenerator(个人)
和 UidGenerator、Leaf 一样,IdGenerator[16] 也是一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
IdGenerator 有如下特点:
- 生成的唯一 ID 更短;
- 兼容所有雪花算法(号段模式或经典模式,大厂或小厂);
- 原生支持 C#/Java/Go/C/Rust/Python/Node.js/PHP(C 扩展)/SQL/ 等语言,并提供多线程安全调用动态库(FFI);
- 解决了时间回拨问题,支持手工插入新 ID(当业务需要在历史时间生成新 ID 时,用本算法的预留位能生成 5000 个每秒)
- 不依赖外部存储系统;
- 默认配置下,ID 可用 71000 年不重复。
IdGenerator 生成的唯一 ID 组成如下:

- timestamp (位数不固定):时间差,是生成 ID 时的系统时间减去 BaseTime(基础时间,也称基点时间、原点时间、纪元时间,默认值为 2020 年) 的总时间差(毫秒单位)。初始为 5bits,随着运行时间而增加。如果觉得默认值太老,你可以重新设置,不过要注意,这个值以后最好不变。
- worker id (默认 6 bits):机器 id,机器码,最重要参数,是区分不同机器或不同应用的唯一 ID,最大值由 WorkerIdBitLength(默认 6)限定。如果一台服务器部署多个独立服务,需要为每个服务指定不同的 WorkerId。
- sequence (默认 6 bits):序列数,是每毫秒下的序列数,由参数中的 SeqBitLength(默认 6)限定。增加 SeqBitLength 会让性能更高,但生成的 ID 也会更长。