目录
前言
第一章、python介绍和使用pip install下载包
1.python介绍
2.使用vscode编写python
3.pip install的使用
第二章、查看官网是否发布新的内容
第三章、代码实现
目录结构
代码实现
check_new_news.py
files.py
news.py
main.py
file.txt
运行演示
前言
也作为半名新媒体工作者吧,查看学院官网是否发布新闻以安排下一步的工作,想必是新媒体工作者都要做的工作之一吧。于是乎就像使用py来实现上述功能。因为最开始学的C++,对py不太了解,以为需要使用爬虫才能实现,后来随着了解的深入,发现我只是查看官网上是否发布新的内容而已,这都是公开的数据,这不也就是一个简单的自动化嘛,应该在py的能力范围之内。于是又再度尝试去这个功能。
作者能力有限,许多函数都得问GTP用法,主要对py了解到甚少,而且写的py的写法可能也不太规范,希望大家多多指正。这里借用查看学院官网是否发布新的新闻为例,分享一下查看官网是否发布新的内容的一种思路。
第一章、python介绍和使用pip install下载包
第一章的主要简单介绍一下环境,已经有python环境,有一点Python基础的可以直接跳过
1.python介绍
Python 是一种简单而强大的解释型编程语言,具有清晰简洁的语法和丰富的库,广泛应用于 Web 开发、数据分析、人工智能、科学计算等领域。
特点:
- **简洁易读**:Python 的语法非常简单,易于理解和学习,使得代码可读性高。
- **易学易用**:Python 提供了丰富而一致的库,可以轻松完成各种任务,同时有大量的学习资源和社区支持。
- **跨平台**:Python 可以在多个操作系统上运行,包括 Windows、Mac 和 Linux。
- **动态类型**:Python 是一种动态类型语言,不需要显式声明变量类型,可以更快地进行开发和迭代。
可以从官方网站(https://www.python.org)下载 Python 解释器并编写自己的 Python 程序。同时,有许多免费的在线教程和资源可用于学习和提升 Python 编程技能。
下载完python,还需要配置环境变量,关于python下载的,网上已经有许多介绍,当在命令提示符工具输入下列指令,能够正常显示py版本,说明python已经安装完成
python --version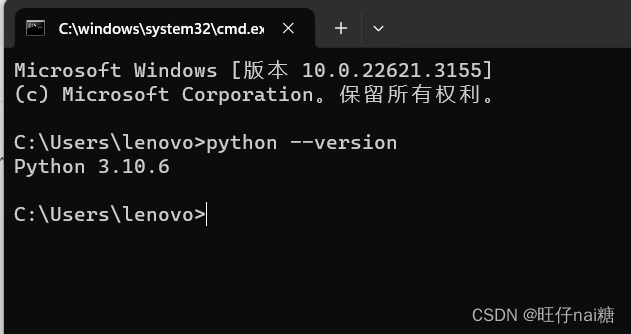
2.使用vscode编写python
VS Code(Visual Studio Code)是一个免费且功能强大的源代码编辑器,它支持多种编程语言,包括 Python。使用 VS Code 写 Python 对于日常开发非常方便,我再写py代码时,使用的就是vscode。
以下是如何在 VS Code 中写 Python 的简要步骤:
-
安装 VS Code:
首先,你需要在计算机上安装 VS Code。你可以从官方网站(https://code.visualstudio.com)下载适合你操作系统的安装程序,并按照安装向导进行安装。 -
安装 Python 扩展:
打开 VS Code,点击侧边栏的「扩展」图标(四个方块组成的图标),搜索并安装名为 “Python” 的扩展。这个扩展提供了与 Python 相关的功能,例如代码补全、调试等。 -
打开 Python 文件夹或创建一个新的 Python 文件:
在 VS Code 中,你可以打开包含 Python 文件的文件夹,或者创建一个新的 Python 文件。点击「文件」菜单中的「打开文件夹」选项,选择你的 Python 项目所在的文件夹;或者点击「文件」菜单中的「新建文件」选项,然后将文件保存为.py扩展名的文件。 -
编写 Python 代码:
在 VS Code 编辑区域中,开始编写你的 Python 代码。VS Code 提供了许多代码编辑功能,例如自动缩进、代码补全、语法高亮等,可以提高编辑的效率和舒适度。 -
运行 Python 代码:
在 VS Code 中,你可以通过按下Ctrl+Shift+(在 Windows 上)或Cmd+Shift+(在 macOS 上)来打开集成终端。在终端中输入以下命令来运行 Python 代码:python 文件名.py其中,
文件名.py是你所写的 Python 文件的文件名,运行命令将会执行该文件中的代码。
3.pip install的使用
pip可以快速安装py包,在完成本次任务重,有一些包是电脑上没有的,可以在命令提示符使用pip下载,总之就是运行时提示哪个包没有,就用pip下载哪个包就对了。
要使用 `pip` 安装 Python 包,可以按照以下步骤:
1. 打开终端或命令提示符(Windows 用户可以按下 `Win + R` 键,输入 `cmd` 并按回车键)。
2. 在终端中输入以下命令:
pip install package_name
将 `package_name` 替换为你要安装的包的名称。
例如,如果你想安装 `requests` 包,你可以输入:
pip install requests如果你想安装特定版本的包,可以使用 `==` 符号指定版本号。例如:
pip install requests==2.25.1
3. 按下回车键执行命令。 `pip` 将会连接到 Python 包索引(PyPI),下载并安装指定的包及其依赖项。
安装完成后,就可以在你的 Python 脚本或解释器中导入并使用安装的包了。
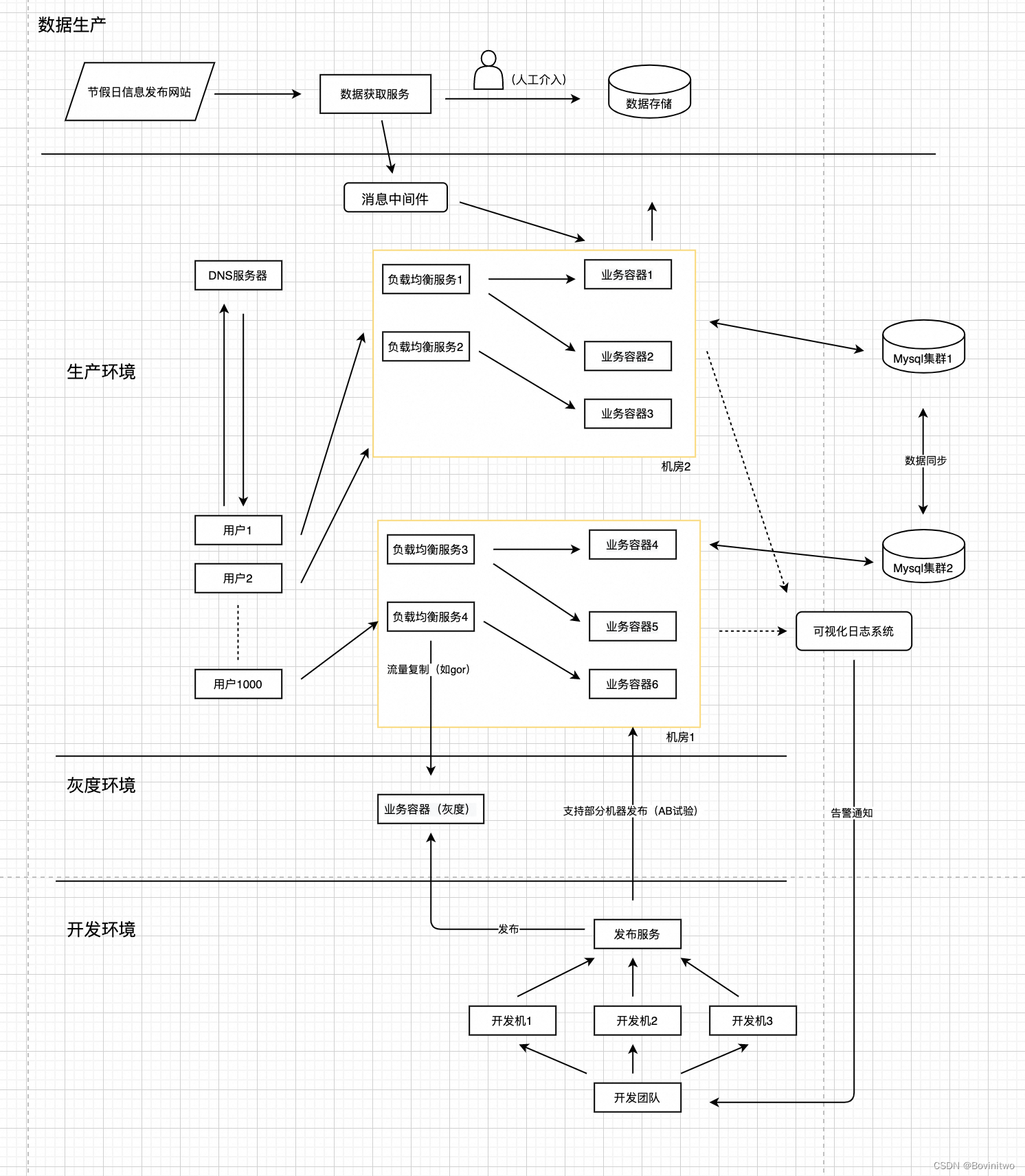
第二章、查看官网是否发布新的内容
其实,这里的“新内容”可以看做是官网上是否发布了“新的网页”,以我们学院的官网链接为例,学院的官网都有许多个栏目,每个栏目下又有许多篇新闻,同一个栏目下的新闻的链接,除了最后一串数字不一样之外,其他都一样;不同栏目下的新闻除了最后一串数字不一样之外,倒数第二串数字也不一样,也就是说,我们如果把最后一串数字记为新闻编号,除了最后一位数字之前的链接,记为链接头部,显然,对于同一个栏目来说,新闻头部都是一样的。那么,我们只需要知道新闻编号,就知道新闻的完整链接了。
如下:
http://phye.henu.edu.cn/info/1054/6370.htm
学院领导走访慰问退休老同志-河南大学物理与电子学院
站在整个官网的角度,所有栏目的新闻拼凑起来,最后一串数字是一个连续的数字,但是由于这些新闻分处在不同的栏目,所以同一个栏目下的新闻编号,大部分情况都不会连续的,但至少可以保证,新的新闻的新闻编号一定比旧新闻的新闻编号大。
因此,检查新内容就可以由检查新发布的网页转化为检查链接头部相同,新闻编号比当前记录的新闻编号大的新闻链接,是否是有效网页来实现。具体写代码时也很简单,只是会用到一些函数,这些函数对于初学者可能都不太了解用法。
第三章、代码实现
代码实现中,主要使用data文件夹下的file.txt来存储新闻编号数据,tools文件夹中实现新闻读取,新闻检查。然后在大目录下设置了main.py以运行整个程序。
目录结构
目录结构如下:

如果你修改目录结构的话,可能需要修改代码里的部分地址。
如果你希望读取其他网站的话,需要在check_new_news.py文件中,修改对应的链接头部,在file.txt内设置当前最新网站的编号(链接的最后一串数字)。当然,这串代码只适用于部分网站,只是提供一个思路。
代码实现
运行时只运行main.py即可
check_new_news.py
from os import system
import requests
from . import files
from . import news
def check_new_news():
num=files.read_integer_data(files.file_path)#从文件中读取新闻编号
url_front="http://phye.henu.edu.cn/info/1054/"#新闻链接的“头部”根据需要修改成对应的链接
url = f"http://phye.henu.edu.cn/info/1054/{num}.htm"#合成第一个新闻的链接=链接"头部"+新闻编号
response = requests.get(url)#读取新闻
if response.status_code == 200:#如果读取到了有效的网页
print("当前的新闻链接是:"+news.get_news_title(url))#显示当前新闻的题目
print(f"{url_front}{num}.htm\n")#显示新闻的链接
new_num=num#更新新闻编号数据
count_new_news=0#用于记录从上次记录到现在总共有多少新新闻
last_num=0
for i in range(100):#总共读取从当前记录的新闻编号到当前新闻编号+100的新闻
new_num+=1
new_url="".join([url_front,str(new_num),".htm"])#合成新的新闻链接
new_reponse=requests.get(new_url)#再次读取新闻
if(new_reponse.status_code==200):#如果读取到有效的网页
count_new_news+=1
last_num=new_num
print("有新新闻:"+news.get_news_title(new_url))
print(f"{url_front}{new_num}.htm\n")
print(f"共有{count_new_news}篇新新闻\n")
while count_new_news:#询问是否更新数据
is_up_data=str(input("是否需要更新数据(Y/N):"))
is_up_data=is_up_data.upper()
if is_up_data=="Y":
files.update_data(files.file_path,last_num)
print(f"更新数据成功,当前data=[{files.read_integer_data(files.file_path)}]")#更新数据到file.txt
break
elif is_up_data=="N":
print(f"数据未更新当前data=[{files.read_integer_data(files.file_path)}]")#更新数据到file.txt
break
else:
print("无效的数据,请重新输入")
return new_num
else:
print(f"error code={num}")#如果没读取到有效的网页,说明:
print("无法连接到网页,请检查网络或者files.txt内的默认数据是否有误")
return 0files.py
import os
# 获取当前文件所在的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 拼接文件的路径
file_path = os.path.join(current_dir,"..", "data", "file.txt")
# print("文件路径:", file_path)
def read_integer_data(file_path):
with open(file_path, 'r') as file:
data = file.read()
# 将文件中的数据转换为整数列表
integer_data = [int(num) for num in data.split()]
if len(integer_data)==0:
print("初始化失败,请检查data/file.txt内的数据是否正常")
return 0
else:
return integer_data[0]
def update_data(file_path, new_data):
with open(file_path, 'w') as file:
file.write(str(new_data))
print("数据已更新并写入文件.")
# update_data(file_path,6273)news.py
from os import system
import requests
from bs4 import BeautifulSoup
def get_news_title(url):
response = requests.get(url)
response.encoding ="utf_8"
html_content = response.text
if response.status_code == 200:
# 使用 Beautiful Soup 解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
# 找到新闻标题元素并提取标题文本
news_titles = soup.select_one('div.detail_main_content > h3')#选择新闻在网页中的位置,可能需要自己通过调试查看
return "".join(news_titles)
else:
return "没有找到"from os import system
from tools import check_new_news
check_new_news.check_new_news()
system("pause")main.py
from os import system
from tools import check_new_news
check_new_news.check_new_news()
system("pause")file.txt
6370
这是第一次使用python来实现自己的需求,之前也从没系统地学过python,更不懂python代码书写的规范,因此一定有写的不好的地方,希望大家多多指教。
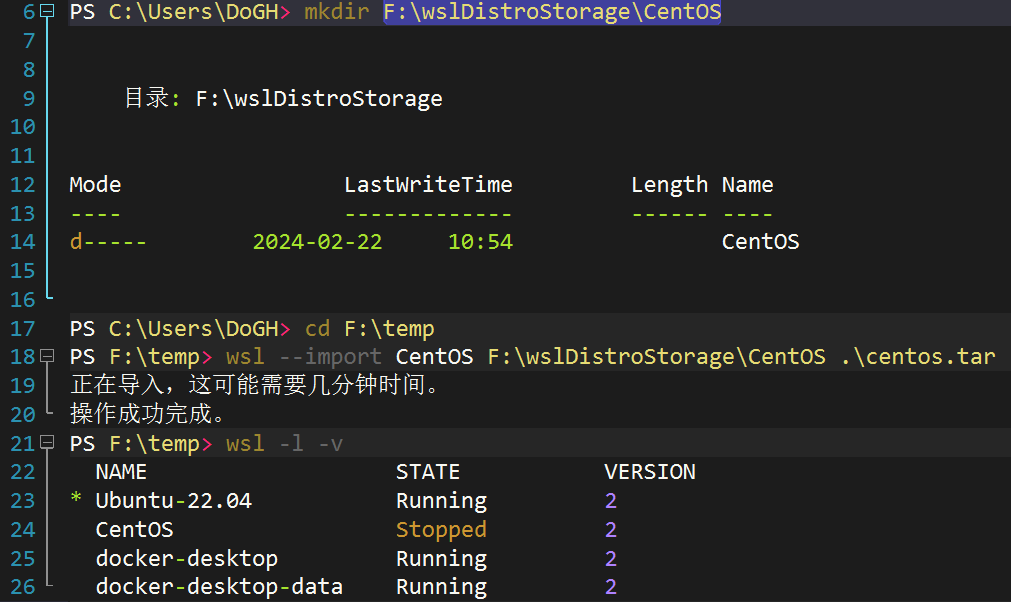
运行演示
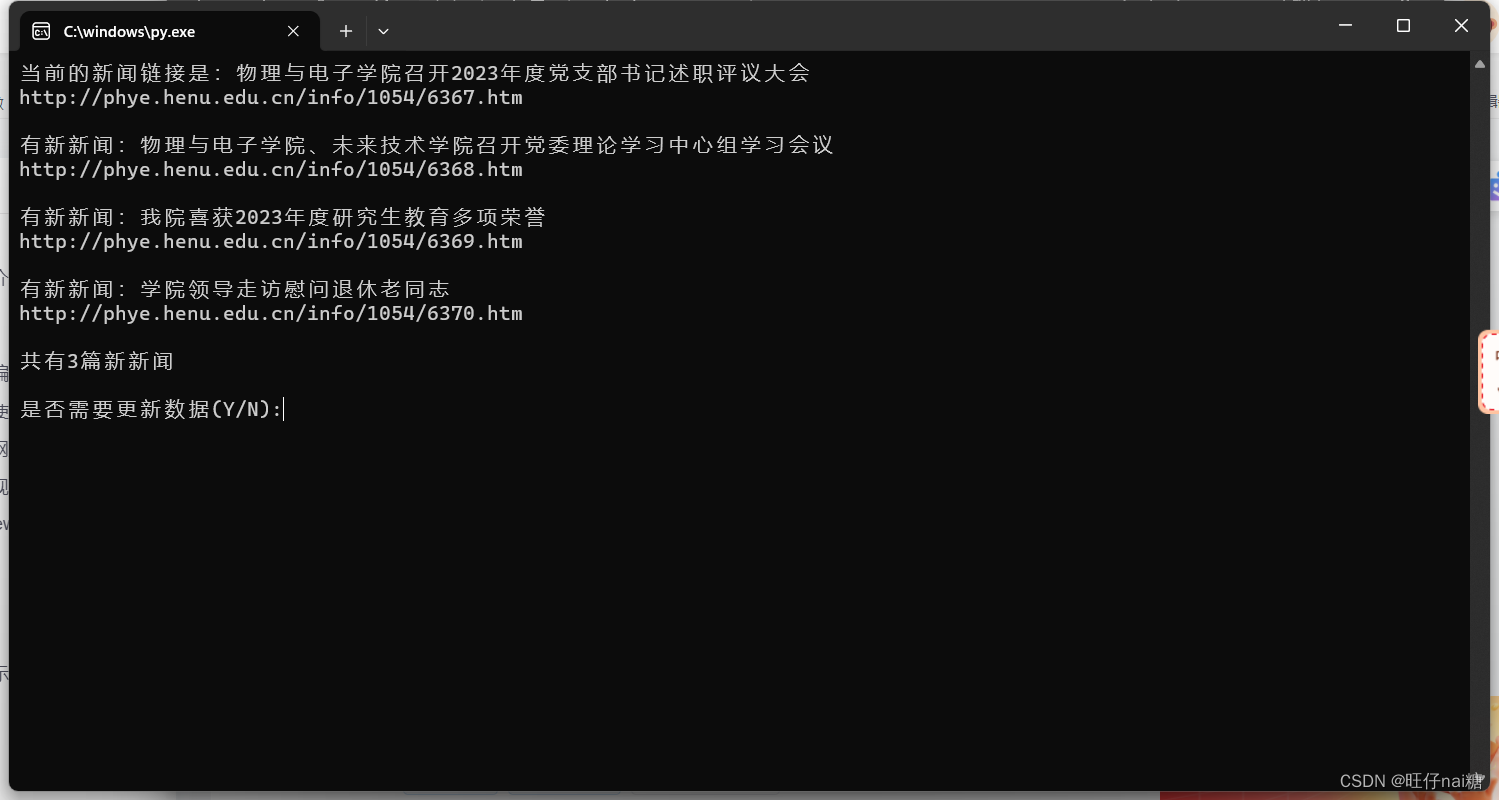
![python[6]](https://img-blog.csdnimg.cn/direct/6a2c46b73f214b358be7b65e527cb3ae.png)



![Sqli-labs靶场第8关详解[Sqli-labs-less-8]](https://img-blog.csdnimg.cn/direct/a75945bb611847b3b87435df0900f064.png)