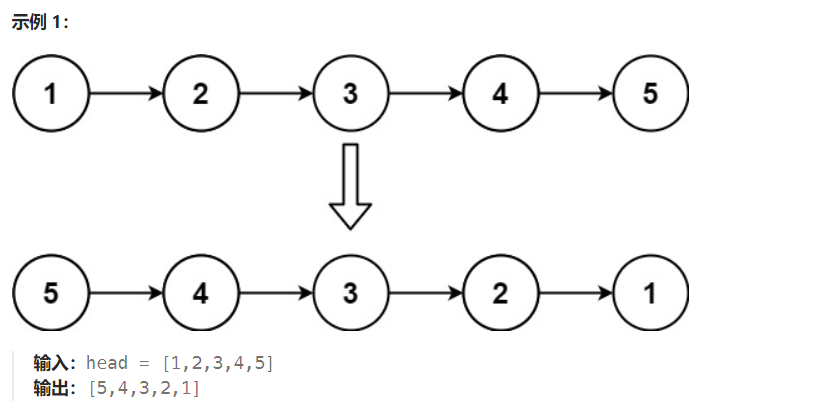
原始(文本、音频、图像、视频、传感器等)数据被转化成结构化且适合机器学习算法或深度学习模型使用的格式。

原始数据转化为结构化且适合机器学习和深度学习模型使用的格式,通常需要经历以下类型的预处理和转换:
-
文本数据:
- 文本清洗:去除特殊字符、标点符号、数字等,并进行大小写统一、去停用词。
- 分词或Tokenization:将文本分割成单词、词语或其他单位。
- 词汇编码:构建词汇表并为每个词分配一个整数ID;或者直接应用预训练的词嵌入(如Word2Vec、GloVe)。
- 序列填充或截断:使所有序列具有相同长度以适应模型输入要求。
-
音频数据:
- 数据加载:读取音频文件并转换为数字信号,如PCM样本。
- 预处理:标准化音频信号幅度、降噪、分帧、提取MFCCs(梅尔频率倒谱系数)或其他特征表示。
- 转换为张量:组织特征矩阵为适合模型输入的张量形式。
-
图像数据:
- 图像读取:使用库如PIL、OpenCV等加载图片文件。
- 大小调整:根据模型需求对图像尺寸进行缩放或裁剪。
- 归一化:将像素值从0-255范围归一化到0-1之间。
- 转换为张量:将图像数据转化为numpy数组后通过
torch.tensor()或tf.convert_to_tensor()将其转换为张量。
-
视频数据:
- 视频解码:读取视频文件并逐帧提取图像。
- 单帧图像处理:对每一帧执行与图像数据相同的预处理步骤。
- 特征提取:可能包括运动特征、光流等高级特征的计算。
- 将连续帧堆叠或串联起来形成三维张量(帧数×高度×宽度×通道数)。
-
传感器数据:
- 读取与解析:获取传感器输出的原始数据,可能是CSV、JSON或其他格式。
- 异常值处理:识别并处理异常或错误的测量值。
- 特征工程:构造有助于描述系统状态的时间序列特征,如移动平均、差分、滑动窗口统计量等。
- 转换为张量:将处理后的数据整理为一维或多维张量,用于时序模型的输入。
经过以上预处理和转换,原始数据可以被有效整合进机器学习或深度学习算法中,作为模型训练和预测的基础。
1.常见的数据类型
-
文本数据(Text Data):
- 文本数据是由字符或单词组成的非结构化数据,可以是电子邮件、文章、社交媒体帖子、书籍、文档等。
- 文本挖掘和自然语言处理技术用于从这种数据中提取信息和洞察。
-
音频数据(Audio Data):
- 音频数据包含声音信号,可以是语音、音乐或其他声波形式,通常以数字音频文件的形式存储,表示为时间序列信号。
- 在语音识别、语音合成、音乐信息检索等领域广泛应用。
-
视频数据(Video Data):
- 视频数据是一种复杂的数据类型,它结合了图像帧序列与音频流,包含了时间和空间两个维度的信息。
- 用于视频分析、行为识别、动作捕捉、实时监控等多个领域。
-
网络/图数据(Network/Graph Data):
- 图数据由节点(顶点)和边组成,描述实体之间的关系。例如社交网络中的用户关系、网页间的链接结构等。
- 社交网络分析、推荐系统、知识图谱构建等工作都会用到图数据。
-
传感器数据(Sensor Data):
- 来自各种物理设备(如温度计、运动传感器、GPS等)连续测量并记录的数据,通常表现为时间序列。
- 应用于物联网(IoT)、工业自动化、健康监测等多种场景。
-
地理位置数据(Geospatial Data):
包括经纬度坐标、地理编码、地图数据等,用于地理信息系统(GIS)、导航、位置服务等方面。 -
多模态数据(Multimodal Data):
同时包含两种或多种不同类型的数据,例如文本+图像(带有说明的图片)、视频+音频(电影片段)等。 -
元数据(Metadata):
描述其他数据的数据,例如文件创建日期、作者信息、文件大小等,有助于管理和理解底层数据。
每种数据类型都有其特定的处理方法和技术,根据应用场景选择合适的分析工具和算法进行处理和分析。
2.常见的序列数据类型
序列数据是指由一个或多个元素按照特定顺序排列的数据结构,每个元素在序列中都有其唯一的位置(索引)。在不同的编程语言和应用领域中,序列数据广泛存在,并且有多种具体表现形式。以下是几种常见的序列数据类型:
-
列表 (List):
在Python中,列表是可变的有序集合,可以包含任意类型的元素,并通过索引访问。 -
元组 (Tuple):
同样在Python中,元组也是有序的,但它是不可变的,一旦创建就不能修改。 -
数组:
许多编程语言如C、Java、JavaScript等提供数组数据类型,它是一个固定大小的、相同数据类型元素的集合,可以通过索引进行访问。 -
字符串 (String):
字符串本质上是一种字符序列,在大多数编程语言中被视为一种特殊的有序序列。 -
时间序列数据:
在数据分析领域,时间序列是一系列按时间排序的数据点,通常用于表示某种度量随时间的变化情况,例如股票价格、气温记录、网页点击流等。 -
向量和矩阵:
在数学和机器学习中,向量和矩阵是数值型数据的有序集合,它们具有线性和空间维度的概念。 -
队列 (Queue) 和 栈 (Stack):
这两种数据结构也是一种特殊类型的序列,队列遵循先进先出(FIFO)原则,而栈遵循后进先出(LIFO)原则。 -
序列化数据:
在数据存储和传输过程中,将对象转换成一连串的比特或字节序列的过程也产生序列数据。 -
音频信号 和 视频帧:
在多媒体处理领域,音频信号是由一系列采样点构成的,视频则是由连续的图像帧组成的序列。
这些序列数据结构和概念在算法设计、数据处理、机器学习模型训练等诸多方面都扮演着重要角色。
3.将不同类型的原始数据结构化处理
将不同类型的原始数据转化为适合深度学习模型使用的结构化格式,会因数据类型的不同而采取不同的处理方式。以下是一些常见数据类型的转化方法:
-
文本数据:
- 预处理:如前所述,包括清洗、分词、去除停用词等。
- 编码:构建词汇表并进行词索引编码,或者直接应用预训练的词嵌入模型。
- 序列填充或截断以适应固定长度。
-
数值数据:
- 标准化/归一化:对连续数值特征进行标准化(Z-score标准化)或归一化(Min-Max归一化),使得所有特征在同一尺度上,并消除量纲影响。
- 处理缺失值:可以使用平均值、中位数或众数填充缺失数值,或者采用插值、多重插补等更复杂的方法。
-
分类数据:
- 独热编码(One-hot Encoding):对于类别变量,将其转换为一组二进制向量,其中只有一个元素为1,代表当前类别。
- 整数编码(Label Encoding):对于有序类别或离散类别,也可以直接映射为整数。
-
图像数据:
- 数据加载:读取图像文件并转换为数组形式,常用的是三维张量(宽度、高度、通道数)。
- 预处理:包括尺寸调整(统一输入大小)、色彩空间转换(RGB到灰度或RGB到BGR等)、归一化(通常将像素值缩放到0-1之间)。
-
时间序列数据:
- 重采样与填充:处理不规则的时间间隔,可能需要通过插值等方式转换为均匀时间步长的序列。
- 特征提取:根据时序特性构造滑动窗口、统计特征(如移动平均、方差等)。
-
多模态数据:
- 各模态数据单独预处理后,再进行融合,例如联合文本和图像特征进行处理。
最终的目标是将所有这些预处理后的数据整合成深度学习模型所需的输入格式,通常是张量(Tensor)形式,以便在神经网络中进行高效计算。
4.原始文本数据的结构化处理(具体步骤)
将原始文本数据转化成适合深度学习模型使用的结构化格式通常涉及以下几个关键步骤:
-
预处理:
- 文本清洗:去除无关字符(如特殊符号、标点符号等),转换为统一的大小写,以及删除停用词(在自然语言处理中常见但不携带过多语义信息的词汇)。
- 分词/Tokenization:将文本分割成单词或子词单位。对于一些语言可能还需要进行分词。
-
编码:
- 将词语映射到整数索引:构建一个词汇表,并为每个唯一的词分配一个整数ID。这样文本就变成了整数序列。
- 词嵌入(Word Embedding):进一步将这些整数索引转化为固定维度的稠密向量表示,例如可以使用预先训练好的词向量模型(如Word2Vec、GloVe)或在训练过程中自动生成(如通过神经网络模型训练得到)。
-
填充与截断:
对于深度学习中的序列模型(如RNN、LSTM或Transformer),需要确保所有输入序列具有相同的长度。对于过长的序列,可以选择截断;对于过短的序列,则可以通过添加特殊填充token(如<pad>标记)来填充至相同长度。 -
构建批次:
将预处理并编码后的文本数据组织成批量样本,用于后续模型训练和预测。 -
标签处理:
如果是分类任务,需要对类别标签进行编码,如独热编码(one-hot encoding)或者整数编码;如果是序列标注任务,则需将标签序列也进行同样的预处理和编码。
完成以上步骤后,原始文本数据就转化成了深度学习模型能够直接接受和处理的结构化数值形式。
5.深度学习中原始数据转换成张量数据(代码操作示例)
在深度学习中,原始数据通常需要经过预处理并转换为张量(Tensor)格式,以便于在诸如PyTorch或TensorFlow等框架中进行训练和推断。以下是几种常见类型原始数据转换成张量的步骤:
图像数据
- 读取图像:使用
PIL、OpenCV等库加载图片文件。 - 转换颜色空间(如果必要):将图像从RGB或其他颜色模式转换为模型期望的颜色空间,例如灰度或RGB。
- 尺寸调整:根据模型要求对图像进行缩放或裁剪到合适的大小。
- 归一化:将像素值标准化至0-1之间(除以255),或者按需应用其他类型的归一化方法。
- 转换为张量:使用如
torchvision.transforms中的ToTensor()函数将numpy数组形式的图像数据转换为PyTorch张量。
Python
1import torch
2from torchvision import transforms
3
4# 转换器
5transform = transforms.Compose([
6 transforms.Resize((224, 224)),
7 transforms.ToTensor(),
8 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 对于ImageNet数据集常见的均值和标准差归一化
9])
10
11# 加载图像并转换为张量
12image = Image.open('path_to_image.jpg')
13image_tensor = transform(image)数值型数据(如CSV)
- 读取数据:使用
pandas读取CSV文件,并可能进行缺失值填充、离群值处理等操作。 - 特征提取与编码:将分类变量进行独热编码或其他形式的数值化处理。
- 数据归一化:对数值特征进行标准化或归一化。
- 转换为张量:将处理后的numpy数组通过
torch.from_numpy()或直接构造torch.tensor()来创建张量。
Python
1import pandas as pd
2import torch
3
4# 读取数据
5data = pd.read_csv('dataset.csv')
6
7# 数据预处理...
8# 假设 data_processed 是已经预处理好的数值型数据
9numpy_data = data_processed.values
10
11# 创建张量
12tensor_data = torch.from_numpy(numpy_data)
13
14# 或者对于多维数据,比如序列数据
15# 可能需要添加维度,例如时间步长维度
16tensor_sequence_data = torch.tensor(numpy_data).unsqueeze(1) # 添加一个维度表示序列序列数据(如文本)
- 分词或编码:将文本转换为单词索引或嵌入向量(如使用
Tokenizer类,如Hugging Face Transformers库中的BertTokenizer)。 - 填充或截断:确保所有序列长度相同,对于过短的序列进行填充(padding),过长的序列进行截断(truncation)。
- 构建张量:将编码后的序列作为张量的一维或多维元素。
Python
1from transformers import BertTokenizer
2
3tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
4
5# 分词并转换为ID列表
6inputs = tokenizer("This is a text sequence", return_tensors='pt')
7
8# 输入已经是张量形式了
9input_ids = inputs['input_ids']
10attention_mask = inputs['attention_mask'] # 对于BERT模型,还需要注意mask总的来说,无论是哪种类型的数据,最终的目标都是将其组织成适合神经网络输入的形式——即具有正确维度、数据类型和结构的张量。
附:具有正确维度、数据类型和结构的张量:
在深度学习和机器学习中,张量(Tensor)是表示多维数据的数据结构。为了使原始数据能够被机器学习或深度学习算法有效地处理,需要将数据转换为具有正确维度、数据类型和结构的张量。
-
正确维度:张量的维度反映了数据的结构,例如:
- 一维张量可以代表一个序列,如文本中的单词索引序列。
- 二维张量通常用于表示图像数据,其中第一维对应高度,第二维对应宽度,第三维(如果存在)则可能表示颜色通道(对于RGB图像有3个通道)。
- 高维张量可用于表示更复杂的数据结构,如视频数据(时间步长×高度×宽度×通道数),或者多个样本组成的批量数据(样本数×特征数)。
-
数据类型:张量中的元素应具有适合模型训练和预测的数据类型,常见的包括:
- 浮点型(float32或float64):用于存储数值型特征或权重等。
- 整型(int32或int64):常用于表示类别标签或词索引等离散值。
- 布尔型(bool):在某些情况下用于标记位或二元分类结果。
-
结构:张量的结构必须与所使用的模型架构相匹配。例如,在使用卷积神经网络处理图像时,输入张量的形状应该是
(batch_size, channels, height, width);而在处理文本任务时,输入通常是经过编码的词嵌入张量,其形状可能是(batch_size, sequence_length, embedding_size)。
通过上述步骤对原始数据进行预处理,并将其转化为正确的张量形式后,这些数据就能直接作为深度学习模型的输入,进行后续的学习和推理过程。




![[LWC] Components Communication](https://img-blog.csdnimg.cn/direct/3975290d87c448639f50f870db02817a.png)