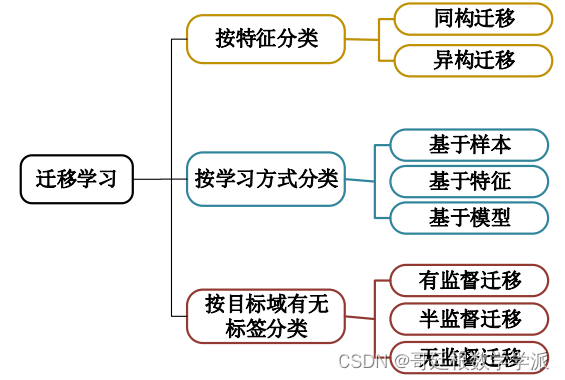
域自适应是指在源域和目标域之间进行相同的迁移学习任务,由于两个领域的数据分布不一致,源域中存在大量的带标签的样本,目标域则没有(或极少)带标签的样本。通过这种方式可以将在源域样本中学到的知识迁移到目标域上,完成迁移学习任务。域自适应方法有多种分类方式,类比于迁移学习的分类方式,可以对域自适应方法做如下的分类。
(1)根据源域和目标域数据情况可以进行分类:同构领域自适应,即数据的特征语义和维度都保持一致;异构领域自适应,即与同构迁移学习相反,数据空间不一致。
(2)根据目标域数据是否带有标签可以分为以下三类:有标签的称为监督领域自适应、有少量标签的称为半监督领域自适应、没有标签的称为无监督领域自适应。针对无监督领域自适应的研究最多,在很多情况下我们很难获得大量带标签的目标域数据,在这种情况下,无监督领域自适应方法可以很好的解决目标域样本标签不足的问题。
(3)按照学习方式进行分类,分为基于样本、基于特征以及基于模型的迁移学习。
代码为Python环境下一种简单的基于域自适应迁移学习的轴承故障诊断方法,压缩包=代码+数据+参考文献。所用模块如下:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Activation, BatchNormalization, Dropout, Conv1D, Flatten, ReLU
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, SGD
import tensorflow.keras.backend as K
版本如下:
tensorflow=2.8.0
keras=2.8.0部分代码如下:
def feature_extractor(x):
h = Conv1D(10, 3, padding='same', activation="relu")(x)
h = Dropout(0.5)(h)
h = Conv1D(10, 3, padding='same', activation="relu")(h)
h = Dropout(0.5)(h)
h = Conv1D(10, 3, padding='same', activation="relu")(h)
h = Dropout(0.5)(h)
h = Flatten()(h)
h = Dense(256, activation='relu')(h)
return h
def clf(x):
h = Dense(256, activation='relu')(x)
h = Dense(10, activation='softmax', name="clf")(h)
return h
def baseline():
input_dim = 512
inputs = Input(shape=(input_dim, 1))
features = feature_extractor(inputs)
logits = clf(features)
baseline_model = Model(inputs=inputs, outputs=logits)
adam = Adam(lr=0.0001)
baseline_model.compile(optimizer=adam,
loss=['sparse_categorical_crossentropy'], metrics=['accuracy'])
return baseline_model出图如下:
程序运行结果如下:
1/1 [==============================] - 0s 238ms/step - loss: 0.3994 - accuracy: 0.8350
Accuracy for the baseline model on target data is 0.8349999785423279
1/1 [==============================] - 0s 165ms/step - loss: 0.2113 - accuracy: 0.9200
Accuracy for the baseline model on target data is 0.9200000166893005
1/1 [==============================] - 0s 163ms/step - loss: 0.4961 - accuracy: 0.8250
Accuracy for the baseline model on target data is 0.824999988079071
1/1 [==============================] - 0s 171ms/step - loss: 0.1986 - accuracy: 0.9350
Accuracy for the baseline model on target data is 0.9350000023841858
1/1 [==============================] - 0s 131ms/step - loss: 0.3333 - accuracy: 0.8850
Accuracy for the baseline model on target data is 0.8849999904632568
ten run mean 0.8819999933242798
1/1 [==============================] - 0s 131ms/step - loss: 0.1110 - accuracy: 0.9850
Final Accuracy 0.9850000143051147
1/1 [==============================] - 0s 127ms/step - loss: 0.1070 - accuracy: 0.9900
Final Accuracy 0.9900000095367432
1/1 [==============================] - 0s 133ms/step - loss: 0.0469 - accuracy: 0.9950
Final Accuracy 0.9950000047683716
1/1 [==============================] - 0s 130ms/step - loss: 0.0788 - accuracy: 0.9900
Final Accuracy 0.9900000095367432
1/1 [==============================] - 0s 131ms/step - loss: 0.1013 - accuracy: 0.9950
Final Accuracy 0.9950000047683716
1/1 [==============================] - 0s 134ms/step - loss: 0.1619 - accuracy: 0.9700
Final Accuracy 0.9700000286102295
1/1 [==============================] - 0s 131ms/step - loss: 0.1083 - accuracy: 0.9650
Final Accuracy 0.9649999737739563
1/1 [==============================] - 0s 130ms/step - loss: 0.0589 - accuracy: 0.9950
Final Accuracy 0.9950000047683716
1/1 [==============================] - 0s 126ms/step - loss: 0.1153 - accuracy: 0.9900
Final Accuracy 0.9900000095367432
1/1 [==============================] - 0s 124ms/step - loss: 0.1381 - accuracy: 0.9950
Final Accuracy 0.9950000047683716
ten run mean 0.9870000064373017
工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任
《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。

![[C#]winform基于opencvsharp结合CSRNet算法实现低光图像增强黑暗图片变亮变清晰](https://img-blog.csdnimg.cn/direct/7e44321dfbb94c7e8bf5dcf7df2b7588.jpeg)






![[word] 怎么把word表格里的字放在正中间? #职场发展#知识分享#知识分享](https://img-blog.csdnimg.cn/img_convert/f35c948dbf16018bd09033216ad272a6.jpeg)